




Data Lakehouse: Scalable Storage with Warehouse-Level Performance
Data Lakehouse: Scalable Storage with Warehouse-Level Performance
Are you struggling to choose between the flexibility of data lakes and the performance of data warehouses? What if you didn't have to choose at all? The data lakehouse emerges as an impressive approach to data management that greatly improves how organizations store, process, and analyze their most valuable asset. As businesses generate increasingly diverse data types—from structured transaction records to unstructured IoT sensor data—traditional architectures are reaching their limits. The data lakehouse emerges as the solution that bridges this gap, offering unprecedented flexibility without sacrificing performance.
What is a Data Lakehouse?
A data lakehouse is a modern, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management capabilities and ACID transactions of data warehouses. This hybrid approach enables both business intelligence (BI) and machine learning (ML) operations on all data types within a single, unified platform.
Unlike traditional two-tier architectures that require separate systems for different data types, a data lakehouse creates a single source of truth where structured, semi-structured, and unstructured data coexist. The architecture leverages low-cost cloud object storage (similar to data lakes) while implementing data structures and management features (similar to data warehouses) directly on top of this storage layer.
Key defining characteristics include:
Unified storage: All data types stored in open formats on low-cost object storage
ACID transactions: Ensuring data reliability and consistency
Schema enforcement: Maintaining data quality and structure when needed
Multi-workload support: Enabling BI, analytics, data science, and ML on the same platform
Open standards: Using formats like Parquet and technologies like Apache Iceberg
How Does a Data Lakehouse Work?
Core Technology Stack
The data lakehouse architecture relies on several key technological advancements that make this unified approach possible:
Metadata Layers: Technologies like Delta Lake, Apache Iceberg, and Apache Hudi sit on top of open file formats (such as Parquet) and track which files belong to different table versions. These layers provide rich management features including ACID-compliant transactions, time travel capabilities, schema enforcement and evolution, and data validation.
High-Performance Query Engines: Modern query engines enable high-performance SQL execution directly on data lakes through various optimizations including caching hot data in RAM/SSDs, data layout optimizations that cluster frequently accessed data together, auxiliary data structures like statistics and indexes, and vectorized execution on modern CPUs.
Open Data Formats: The use of open formats like Parquet and ORC makes it easy for data scientists and machine learning engineers to access data using popular tools such as pandas, TensorFlow, PyTorch, and Spark DataFrames without complex data movement or transformation processes.
Medallion Architecture
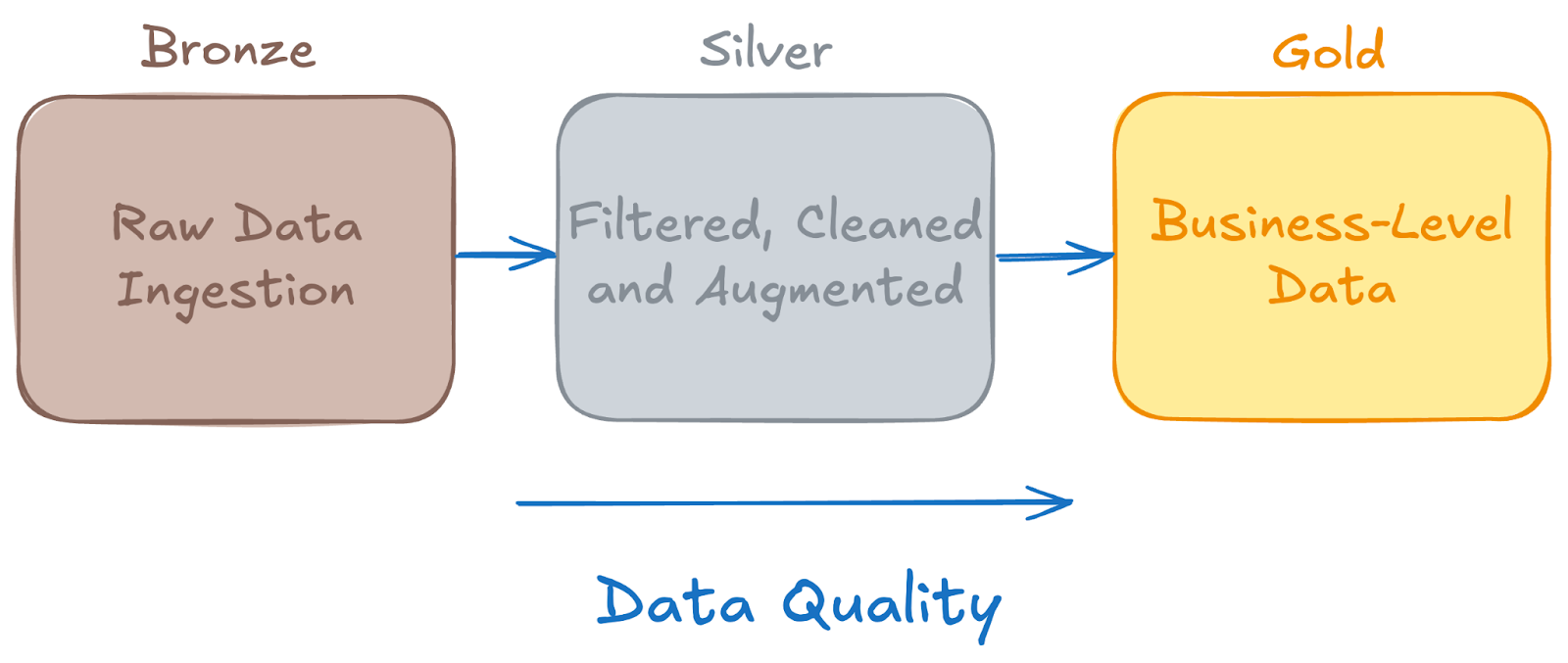
A typical data lakehouse implements a medallion architecture with three distinct layers:
Bronze Layer (Raw Data): This ingestion layer receives batch or streaming data from various sources in multiple formats. Data is stored in its raw, unprocessed form, maintaining complete fidelity to the original source while enabling schema-on-read flexibility.
Silver Layer (Cleaned and Conforming): The processing layer applies data quality rules, standardizes formats, and performs initial transformations. This creates clean, validated datasets while maintaining detailed audit trails and data lineage information.
Gold Layer (Business-Ready): The final layer serves clean, enriched data optimized for specific use cases. Tables are designed with appropriate data layouts and optimizations to serve both analytical queries and machine learning workloads efficiently.
Data Processing Capabilities
Real-Time Processing: Data lakehouses support streaming data ingestion and processing, enabling real-time analytics and immediate insights. This eliminates the need for separate message buses like Kafka in many scenarios.
Batch Processing: Traditional batch processing capabilities handle large-scale historical data analysis and complex transformations that don't require real-time execution.
Interactive Analytics: Users can perform ad-hoc queries and exploratory data analysis directly on the lakehouse without moving data to separate analytical systems.
Delta Lake: The Foundation of Modern Data Lakehouses
Delta Lake has emerged as one of the most critical technologies powering modern data lakehouse architectures. As an open-source storage framework, Delta Lake bridges the gap between data lakes and data warehouses by bringing reliability, performance, and governance to data lake storage.
What is Delta Lake?
Delta Lake is an open-source storage layer that runs on top of existing data lakes and provides ACID transactions, scalable metadata handling, and unified streaming and batch data processing. Built originally by Databricks and now maintained by the Linux Foundation, Delta Lake transforms unreliable data lakes into reliable data lakehouses by adding a transaction log layer on top of cloud object storage.
At its core, Delta Lake stores data in Parquet format while maintaining a transaction log that tracks all changes made to the data. This transaction log is the key innovation that enables ACID properties, time travel, and other advanced features that were previously only available in traditional data warehouses.
Key Features and Capabilities
ACID Transactions: Delta Lake provides full ACID transaction support, ensuring data reliability even with concurrent reads and writes. This eliminates the data corruption issues that can occur in traditional data lakes when multiple processes access the same data simultaneously.
Time Travel and Versioning: Every operation on a Delta table creates a new version, allowing users to access historical versions of their data. This capability enables data recovery, auditing, reproducing experiments, and rolling back problematic changes—features that are crucial for data governance and compliance.
Schema Enforcement and Evolution: Delta Lake prevents bad data from being written by enforcing schema validation. When schemas need to change, Delta Lake supports controlled schema evolution, allowing tables to adapt to changing business requirements while maintaining data quality.
Unified Batch and Streaming: Delta Lake enables both batch and streaming workloads to read from and write to the same tables simultaneously. This eliminates the need for separate systems and complex data synchronization processes, enabling real-time analytics on continuously updated data.
Scalable Metadata Handling: Unlike traditional file-based storage that becomes slow with large numbers of files, Delta Lake efficiently handles metadata for tables with millions of files and billions of objects, maintaining fast query performance at scale.
Data Quality Features: Delta Lake supports expectations and constraints that automatically validate data quality during writes, preventing corrupt or invalid data from entering the lakehouse.
How Delta Lake Powers Data Lakehouse Architecture
Delta Lake serves as the storage foundation that makes the data lakehouse concept practical and reliable:
Reliability Layer: Traditional data lakes suffer from consistency issues, failed writes, and data corruption. Delta Lake's transaction log ensures that all operations are atomic and consistent, providing the reliability that enterprise workloads require.
Performance Optimization: Delta Lake includes built-in optimization features like data skipping, Z-ordering, and automatic file compaction that dramatically improve query performance. These optimizations happen transparently without requiring manual intervention.
Governance and Compliance: With features like audit trails, time travel, and schema enforcement, Delta Lake enables organizations to meet regulatory requirements and maintain proper data governance—something that was difficult or impossible with traditional data lakes.
Multi-Engine Support: Delta Lake tables can be accessed by multiple processing engines including Apache Spark, Apache Flink, Trino, and others, providing flexibility in tool choice while maintaining data consistency.
Data Lakehouse vs. Data Lake vs. Data Warehouse
Understanding the distinctions between these three architectures helps clarify when to choose a data lakehouse approach:
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Data Structure | Schema-on-write | Schema-on-read | Schema-on-read and schema-on-write |
| Data Types | Structured only | All types | All types |
| Transaction Support | Limited | Full (ACID) | Full (ACID) |
| Performance | Fast SQL queries | Variable performance | Near-warehouse speed |
| Cost | High at scale | Low storage, variable compute | Low storage, optimized compute |
Benefits and Challenges of Data Lakehouse
Benefits of Data Lakehouse
Simple Architecture: Eliminates the complexity of maintaining separate data warehouse and data lake systems, reducing operational overhead and the need for multiple ETL processes that can introduce data inconsistencies.
Optimized Cost: Leverages low-cost object storage while providing high-performance query capabilities, significantly reducing total cost of ownership compared to traditional data warehouse scaling.
Enhanced Data Quality: Implements schema enforcement and ACID transactions to maintain data integrity while preserving the flexibility to handle diverse data types and evolving schemas.
Improved Collaboration: Enables data engineers, analysts, and data scientists to work on the same platform with the same data, breaking down traditional silos between different data teams.
Real-Time Capabilities: Supports both batch and streaming workloads, enabling real-time analytics and immediate insights without complex data movement between systems.
Reduced Data Duplication: Provides a single source of truth that eliminates the need to maintain multiple copies of data across different systems, improving consistency and reducing storage costs.
Challenges of Data Lakehouse
Technical Complexity: Building and maintaining a data lakehouse requires expertise in multiple technologies and careful architecture planning to avoid performance bottlenecks and ensure proper governance.
Vendor Lock-In Considerations: While built on open standards, some managed lakehouse solutions may create dependencies on specific cloud providers or technology vendors.
Performance Tuning: Achieving optimal performance requires careful attention to data partitioning, file sizing, indexing strategies, and query optimization techniques.
Migration Complexity: Organizations with existing data infrastructure face complex migration paths that require careful planning to avoid business disruption.
Use Cases of Data Lakehouse
With its ability to combine the scalability of data lakes with the performance of data warehouses, data lakehouses are making an impact across various industries, including:
Healthcare: data lakehouses integrate diverse data sources—such as electronic health records, medical imaging, and wearable devices—to provide a comprehensive view of patient health. This integration enables predictive analytics for early disease detection, personalized treatment plans, and efficient resource allocation.
Financial Services: financial institutions utilize data lakehouses to aggregate and analyze data from transactions, market feeds, and customer interactions. This comprehensive data analysis enhances risk assessment models, improves fraud detection algorithms, and supports regulatory compliance efforts, strengthening overall financial operations.
Retail: retailers leverage data lakehouses to consolidate data from point-of-sale systems, e-commerce platforms, and customer loyalty programs. This unified data approach enables personalized marketing strategies, dynamic pricing models, and inventory optimization, enhancing customer experiences and operational efficiency.
Manufacturing: in manufacturing, data lakehouses integrate data from sensors, production lines, and supply chains. This integration supports predictive maintenance by identifying equipment wear patterns and scheduling timely interventions, reducing downtime and optimizing production processes.
…and many more.
By providing a unified platform that supports diverse data types and analytics workloads, data lakehouses enable organizations to derive actionable insights, enhance decision-making, and drive innovation.
The Next Evolution: Vector Data Lake
What is Vector Data Lake?
As organizations increasingly adopt AI and machine learning workflows, they face an unprecedented challenge: massive amounts of unstructured data are generated daily, monthly, and annually—from documents and images to audio files and sensor data. To unlock insights from this unstructured data, organizations must transform it into vector embeddings that capture semantic meaning and enable similarity-based analysis.
Vector Data Lake is specifically optimized for storing and processing vector embeddings at massive scale and low cost. As organizations generate terabytes and petabytes of unstructured data that must be transformed into vectors to unlock AI insights, Vector Data Lake provides a cost-effective alternative to purpose-built vector databases for large-scale, offline analytics workloads. While vector databases provide excellent performance for real-time use cases, storing and processing terabytes of vectors becomes extremely expensive. Vector Data Lake solves this by providing a cost-optimized solution for organizations that can tolerate higher latency in exchange for dramatically lower costs.
Key Capabilities of Vector Data Lake
Unified Data Stack: Vector Data Lake seamlessly connects online and offline data layers with consistent formats and efficient storage. This means you can move data between hot and cold tiers without reformatting or complex migrations, creating a truly unified approach to vector data management.
Compatible Compute Ecosystem: Built to work natively with frameworks like Spark and Ray, Vector Data Lake supports everything from vector search to traditional ETL and analytics. This compatibility means your existing data teams can work with vector data using tools they already know, eliminating the need for specialized vector database expertise.
Cost-Optimized Architecture: The system intelligently manages data placement—hot data stays on SSD or NVMe for fast access, while cold data automatically moves to object storage like S3. Smart indexing and storage strategies keep I/O fast when needed while making storage costs predictable and affordable.
Data Lakehouse vs. Vector Data Lake vs Vector Database
While data lakehouses, vector data lakes and vector databases all handle massive datasets and analytics, they're built for completely different needs—Data Lakehouses focus on flexibility and governance, Vector Data Lakes prioritize cheap storage at scale, and Vector Databases are all about speed:
| Feature | Data Lakehouse | Vector Data Lake | Vector Database |
|---|---|---|---|
| Primary Data Types | Structured, semi-structured, unstructured | Vector embeddings + all traditional data types | Vector embeddings primarily |
| Query Types | SQL analytics, BI reporting, ML training | Semantic search, similarity analysis, vector analytics | Real-time similarity search, nearest neighbor |
| Latency | Near real-time to batch | Batch-optimized, higher latency acceptable | Ultra-low latency (ms) |
| Cost Model | Optimized for general analytics workloads | Ultra-low cost for massive vector storage | Higher cost for performance |
| Compute Frameworks | Spark, SQL engines, ML frameworks | Spark, Ray, vector-aware processing | Specialized vector engines (FAISS, Pinecone, etc.) |
| Use Cases | Business intelligence, data science, reporting | Historical document analysis, batch similarity, trend analysis | Real-time recommendations, chatbots, live search |
| Storage Tiers | Hot/warm/cold for all data types | Hot vectors (SSD/NVMe), cold vectors (object storage) | Primarily hot storage, optimized indexes |
| Scaling | Horizontal scaling, multi-cloud | Massive horizontal scaling, cloud-native | Vertical + horizontal, purpose-built |
| ACID Properties | Full ACID compliance support | Limited ACID, eventual consistency | Limited ACID, focus on availability |
| Data Governance | Comprehensive catalog, lineage tracking | Basic governance, metadata heavy | Minimal governance capabilities |
FAQs
1. What is the primary advantage of a data lakehouse over a data lake?
A data lakehouse provides ACID transaction support and schema enforcement, ensuring data reliability and performance for analytics, which are typically lacking in traditional data lakes.
2. Can a data lakehouse replace a data warehouse?
While a data lakehouse can handle many of the same workloads as a data warehouse, some organizations may choose to use both systems to meet specific needs.
3. What tools are commonly used with data lakehouses?
Common tools include Delta Lake for metadata management, Apache Spark for data processing, and various BI and machine learning platforms for analytics.
4. Are data lakehouses suitable for real-time analytics?
Yes, data lakehouses support real-time data ingestion and querying, making them suitable for real-time analytics applications.
5. How do data lakehouses handle data governance?
Data lakehouses incorporate metadata layers that enforce schema, track data lineage, and support access controls, ensuring robust data governance.
- **What is a Data Lakehouse?**
- **How Does a Data Lakehouse Work?**
- **Delta Lake: The Foundation of Modern Data Lakehouses**
- **Data Lakehouse vs. Data Lake vs. Data Warehouse**
- **Benefits and Challenges of Data Lakehouse**
- **Use Cases of Data Lakehouse**
- **The Next Evolution: Vector Data Lake**
- **FAQs**
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free