




Comprendre l'intelligence artificielle multimodale
Comprendre l'intelligence artificielle multimodale
Le lancement de ChatGPT et de nombreux autres grands modèles de langage (LLM a marqué une étape cruciale dans le développement de l'IA. Au cours de cette période, les modèles d'IA sont passés d'applications de niche à des utilisations quotidiennes telles que l'écriture, le codage, le service à la clientèle et la création de contenu. Cependant, la plupart de ces progrès se sont limités à une seule modalité : le texte.
Se concentrer sur une seule modalité n'est pas suffisant pour atteindre la vision d'une intelligence artificielle générale (IAG). Par sa définition même, l'IAG requiert la capacité de comprendre, de raisonner et d'agir dans de multiples domaines, du langage et de la vision à l'audition et aux entrées sensorielles. C'est ainsi qu'est née la multimodalité ; cet article vous guidera dans l'utilisation de cette technique.
Qu'est-ce que l'IA multimodale ?
Les systèmes d'intelligence artificielle sont multimodaux s'ils traitent et analysent des informations provenant de plusieurs modalités, telles que le texte, les images, le son et les vidéos. En revanche, l'intelligence artificielle qui ne peut traiter qu'un seul type de modalité est unimodale.
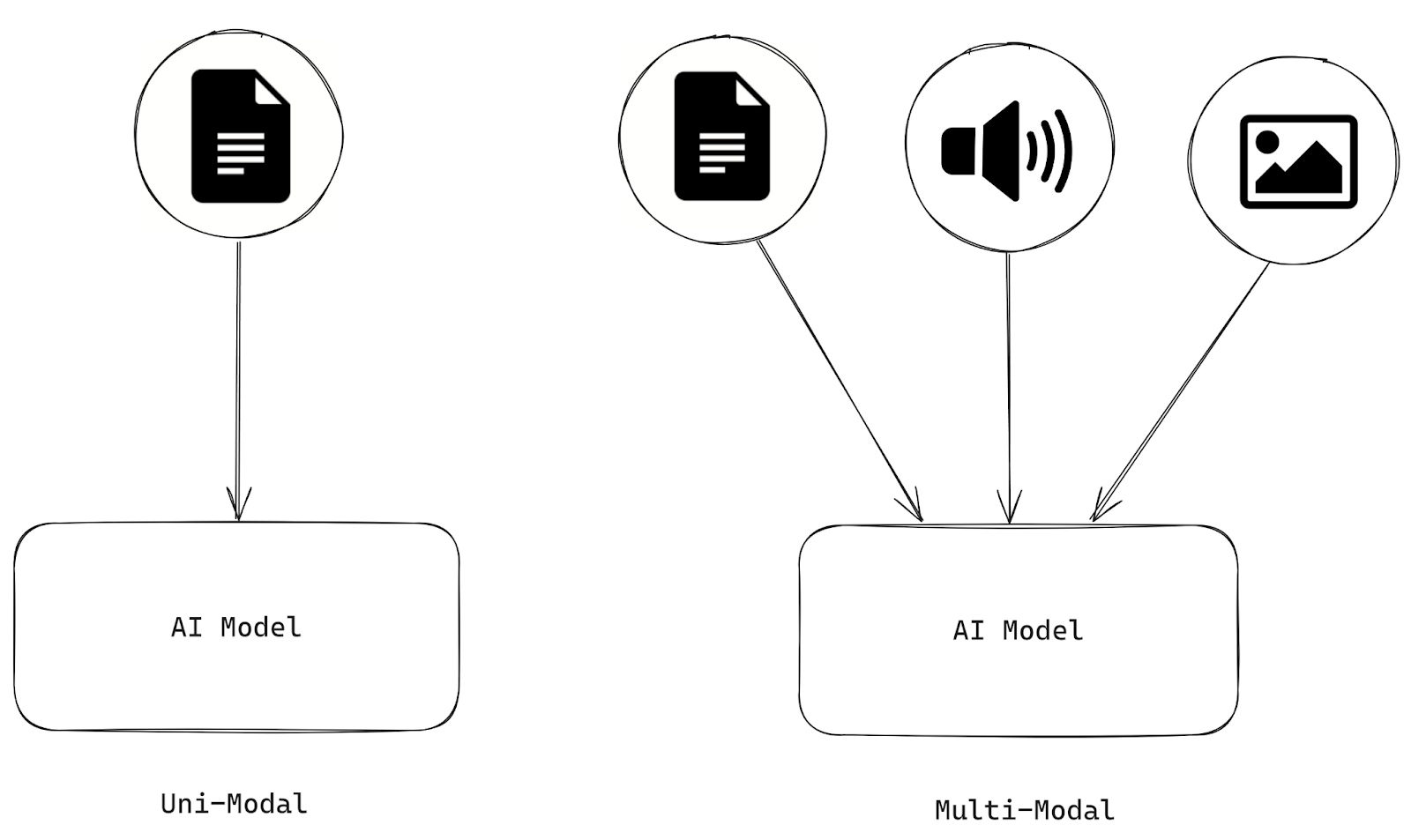 Figure 1- Différences entre l'IA unimodale et l'IA multimodale.png
Figure 1- Différences entre l'IA unimodale et l'IA multimodale.png
Figure 1 : Différences entre l'IA unimodale et l'IA multimodale
Il est important de clarifier la distinction entre deux termes souvent confondus : multimodale et multimodèle. Le terme multimodal fait référence aux systèmes qui intègrent et traitent des informations provenant de plusieurs types de données. En revanche, multimodèle décrit l'utilisation de plusieurs modèles indépendants qui fonctionnent en parallèle ou en combinaison pour accomplir une tâche. Ces modèles peuvent fonctionner sur le même type de données ou sur des types de données différents, mais restent séparés plutôt qu'intégrés.
L'IA multimodale peut avoir un impact significatif sur de nombreuses applications. Par exemple, un système d'IA multimodale pour les soins de santé peut utiliser des images médicales, des enregistrements vocaux de patients et des notes cliniques pour établir un diagnostic plus précis que ne l'aurait fait un système ne s'appuyant que sur une seule source de données. À cet égard, les systèmes d'IA multimodale se rapprochent beaucoup plus de la cognition humaine et sont très efficaces dans les tâches nécessitant impérativement une compréhension globale.
Le terme multimodal peut désigner un ou plusieurs des éléments suivants :
L'entrée et la sortie se font selon des modalités différentes, par exemple de texte à image ou d'image à texte.
Les entrées sont multimodales (par exemple, texte et images).
Les sorties sont multimodales, par exemple un système qui fournit du texte et des images.
Dans la section suivante, nous examinerons le fonctionnement des systèmes multimodaux.
Comment fonctionne l'IA multimodale ?
Différents éléments fonctionnent ensemble dans un modèle multimodal. Voici les éléments les plus importants et leur fonctionnement :
Types de données : L'IA multimodale intègre plusieurs types de données, y compris le texte, les images, le son et les vidéos, ce qui permet une compréhension globale et la génération de contenu à travers différentes modalités.
Représentation** : Les représentations multimodales dans l'apprentissage automatique combinent des données provenant de différentes modalités en des caractéristiques plus significatives que les modèles peuvent utiliser. Deux approches différentes sont utilisées pour y parvenir.
Représentations conjointes** : Les données provenant de différentes modalités sont transformées en un espace de représentation unifié, adapté lorsque des données multimodales sont disponibles lors de la formation et de l'inférence. Les techniques standard comprennent les [réseaux neuronaux] (https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) et les modèles graphiques probabilistes. Bien que ces méthodes puissent améliorer les performances, elles se heurtent à des difficultés en cas de données manquantes.
Représentations coordonnées** : Chaque modalité est traitée séparément, des contraintes étant imposées pour les aligner dans un espace partagé.
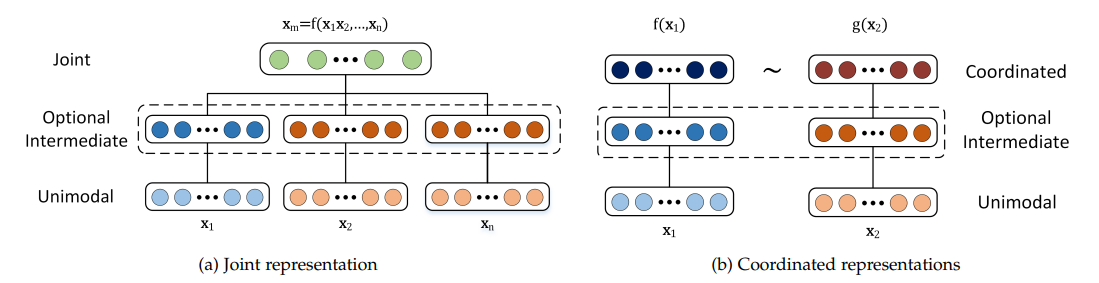 Figure 2- Structure des représentations conjointes et coordonnées.png
Figure 2- Structure des représentations conjointes et coordonnées.png
Figure 2 : Structure des représentations conjointes et coordonnées Source
Extraction de caractéristiques : Des techniques spécialisées sont utilisées pour extraire les caractéristiques de chaque type de données, comme le traitement du langage naturel (NLP) pour le texte, la vision par ordinateur pour les images et le traitement du signal pour l'audio.
Fusion de données : La fusion combine des informations provenant de deux ou plusieurs modalités pour une tâche de prédiction. Les approches sont les suivantes :
Fusion précoce : Les données sont intégrées avant l'analyse, généralement dans un sous-espace de faible dimension à l'aide de méthodes telles que l'ACP (analyse en composantes principales) ou l'ICA (analyse en composantes indépendantes). Cette approche nécessite la synchronisation des modalités, ce qui peut s'avérer difficile en raison de la diversité des formats de données et des taux d'échantillonnage. Bien qu'elle soit efficace pour l'extraction des caractéristiques, elle peut entraîner des pertes de données et des problèmes de synchronisation.
Fusion tardive : Les résultats de chaque modalité sont combinés au niveau de la décision à l'aide de méthodes d'ensemble telles que le bagging, le boosting ou des approches basées sur des règles (par exemple, Bayes, max, ou fusion moyenne). Cette méthode excelle lorsque les modalités ne sont pas corrélées, offrant une flexibilité proche de la cognition humaine.
Modélisation** : Les réseaux neuronaux capables de traiter plusieurs modalités, tels que les transformateurs ou les réseaux neuronaux convolutifs (CNN), sont utilisés pour apprendre à partir de diverses entrées. Il existe des modèles plus sophistiqués qui donnent des résultats supérieurs et sont souvent appelés LMM (Large Multimodal Models).
Modèles multimodaux populaires et leurs architectures
De nombreux modèles multimodaux sont disponibles sur le marché. Les modèles et architectures les plus courants sont présentés ci-dessous.
Transformateur vidéo-audio-texte (VATT)
Le Transformateur Vidéo-Audio-Texte (VATT) est une architecture sans convolution conçue pour traiter plusieurs modalités (vidéo, audio et texte) à l'aide d'un Transformateur unifié. VATT commence par introduire chaque modalité dans une couche de symbolisation, où l'entrée brute est projetée dans un vecteur d'intégration qu'un transformateur traite par la suite.
Il existe deux configurations principales : l'une dans laquelle des transformateurs distincts avec des poids uniques sont utilisés pour chaque modalité et l'autre dans laquelle une seule colonne vertébrale de transformateurs avec des poids partagés traite toutes les modalités.
Quelle que soit la configuration, le transformateur extrait les représentations spécifiques à chaque modalité et les met en correspondance avec un espace partagé pour les tâches ultérieures. L'architecture suit le pipeline de transformation standard, couramment utilisé dans [NLP] (https://zilliz.com/learn/nlp-technologies-in-deep-learning) et [Vision Transformers (ViT)] (https://zilliz.com/learn/understanding-vision-transformers-vit), en utilisant des jetons d'entrée.
En outre, VATT incorpore un biais relatif apprenable pour le texte, ce qui le rend compatible avec des modèles tels que T5. Cette approche permet à VATT de modéliser efficacement des données multimodales pour des tâches telles que la [classification] (https://zilliz.com/glossary/classification).
Figure 3- Vision Transformers for Multimodal Learning.png](https://assets.zilliz.com/Figure_3_Vision_Transformers_for_Multimodal_Learning_46cc680e45.png)
Figure 3 : Transformateurs de vision pour l'apprentissage multimodal Source
Autoencodeur variationnel multimodal (MVAE)
L'architecture [Multimodal Variational Autoencoder (MVAE)] (https://dl.acm.org/doi/10.1145/3308558.3313552) est conçue pour apprendre une représentation unifiée du texte et des images. Le MVAE se compose de trois éléments principaux : un encodeur, un décodeur et un module d'application (un détecteur de fausses nouvelles, dans le cas présent).
 Figure 4- Multimodal Variational Autoencoder Architecture.png
Figure 4- Multimodal Variational Autoencoder Architecture.png
Figure 4 : Architecture d'autoencodeur variationnel multimodal | Source
Encoder : Ce composant traite les entrées texte et image pour générer une représentation latente partagée. Il se compose de deux sous-codeurs :
Encodeur textuel : Il convertit une séquence de mots provenant d'un message en encodements de mots à l'aide d'un réseau profond pré-entraîné.
Encodeur visuel : Ce processus extrait les caractéristiques visuelles des images à l'aide de [CNN] (https://zilliz.com/glossary/convolutional-neural-network) (comme VGG-19) pour capturer la sémantique spatiale et la sémantique des objets.
Décodeur : Le décodeur reconstruit le texte et l'image d'origine à partir de la représentation latente partagée. Il reflète la structure de l'encodeur et se divise en deux parties :
Décodeur textuel : Ce décodeur reconstruit le texte en faisant passer la représentation latente par des unités [LSTM] (https://zilliz.com/glossary/recurrent-neural-networks) bidirectionnelles et une couche entièrement connectée, prédisant la probabilité de chaque mot.
Décodeur visuel : Inverse l'encodage visuel en reconstruisant les caractéristiques de l'image VGG-19 à travers des couches entièrement connectées.
Détecteur de fausses nouvelles : Ce composant prédit si un article est vrai ou faux en utilisant la représentation latente multimodale partagée.
CLIP (Contrastive Language-Image Pretraining)
Le modèle CLIP (Contrastive Language-Image Pretraining) est conçu pour apprendre les représentations conjointes des images et du texte en s'entraînant sur un vaste ensemble de paires image-texte. CLIP utilise deux réseaux neuronaux distincts : un pour les images (souvent un transformateur de vision ou un CNN) et un pour le texte (généralement un transformateur).
Ces réseaux codent les images et le texte en vecteurs de longueur fixe dans un espace d'intégration commun. Pendant la formation, CLIP s'appuie sur un objectif d'apprentissage contrastif, qui rapproche les encastrements des paires image-texte appariées et écarte ceux des paires non appariées.
Grâce à ce processus, CLIP apprend à corréler les informations visuelles et textuelles. Cette approche permet au modèle d'effectuer une classification d'images à partir de zéro, ce qui lui permet de reconnaître des objets dans des images sur la base de descriptions en langage naturel sans avoir besoin d'une formation spécifique à la tâche. Cette architecture puissante peut être utilisée dans des tâches basées sur des images textuelles afin d'améliorer la capacité de généralisation.
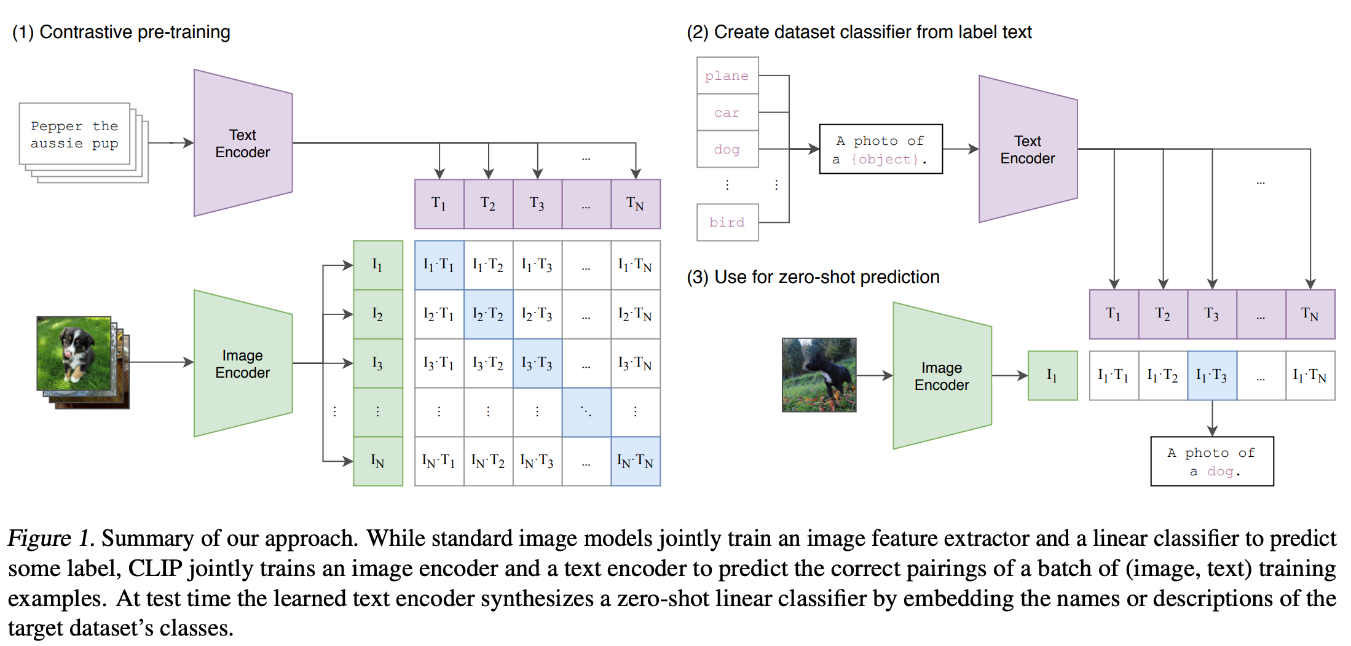 Figure 4- Architecture du modèle CLIP.png
Figure 4- Architecture du modèle CLIP.png
Figure 4 : Architecture du modèle CLIP
Parmi les modèles fermés de ces architectures, on peut citer
Google Gemini : Un LLM multimodal excellant dans le texte, les images, la vidéo et l'audio, surpassant GPT-4 sur de nombreux benchmarks.
ChatGPT (GPT-4V) : Prend en charge le texte, la voix et les images, permettant aux utilisateurs d'interagir avec des voix générées par l'IA et de générer des images via DALL-E 3.
Inworld AI : Crée des PNJ intelligents pour les mondes numériques, permettant la communication par le biais du langage naturel, de la voix et des émotions.
Meta ImageBind** : Traite six modalités, combinant des données pour des tâches telles que la création d'images à partir de données audio et permettant aux machines de percevoir leur environnement.
Runway Gen-2** : Génère et édite des vidéos à partir de textes, d'images ou de vidéos existantes, offrant ainsi des capacités de création de contenu polyvalentes.
Consultez cet article pour en savoir plus sur les [modèles multimodaux] (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know).
RAG multimodal : au-delà du texte
La génération augmentée de récupération (RAG) est une méthode permettant de récupérer des informations contextuelles pour de grands modèles de langage à partir de sources externes et de générer des résultats plus précis. Elle permet également d'atténuer les hallucinations de l'IA et de répondre à certaines préoccupations en matière de sécurité des données. Le RAG traditionnel s'est avéré très efficace pour améliorer le résultat du LLM, mais il reste limité aux données textuelles. Dans de nombreuses applications du monde réel, les connaissances vont au-delà du texte, incorporant des images, des graphiques et d'autres modalités qui fournissent un contexte critique.
Vous trouverez ci-dessous une vue d'ensemble d'un flux de travail typique de RAG basé sur du texte :
L'utilisateur soumet une requête textuelle au système.
La requête est transformée en un vector embedding, qui est ensuite utilisé pour rechercher une base de données vectorielles , telle que Milvus, où les passages de texte sont stockés sous forme d'embeddings. La base de données vectorielle extrait les passages qui correspondent étroitement à la requête sur la base de la similarité vectorielle.
Les passages de texte pertinents sont transmis au LLM en tant que contexte supplémentaire, ce qui enrichit sa compréhension de la requête.
Le LLM traite la requête avec le contexte fourni, générant ainsi une réponse plus informée et plus précise.
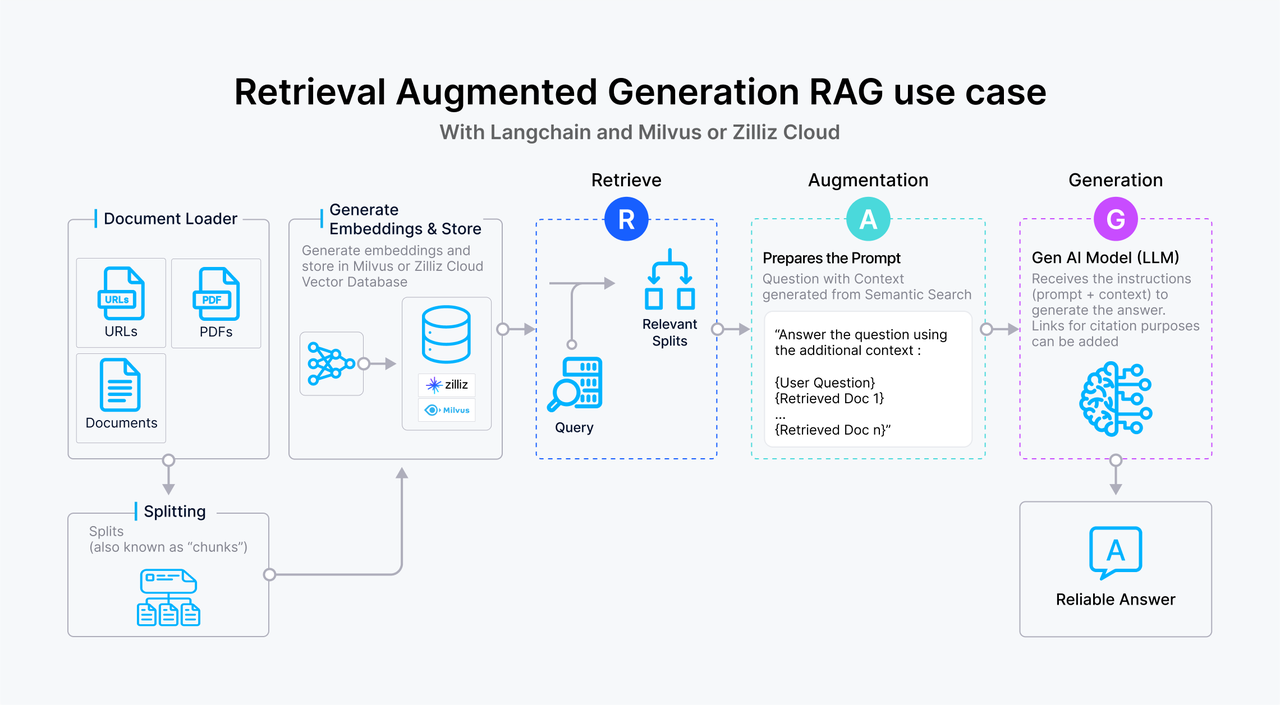 Figure 1- Comment fonctionne le RAG.png
Figure 1- Comment fonctionne le RAG.png
Figure 1- Comment fonctionne le RAG ? Comment fonctionne le RAG
Le système RAG multimodal s'attaque à la limitation susmentionnée en permettant l'utilisation de différents types de données et en fournissant un meilleur contexte aux MFR. En d'autres termes, dans un système RAG multimodal, la composante d'extraction recherche des informations pertinentes dans différentes modalités de données, et la composante de génération génère des résultats plus précis sur la base des informations extraites.
Pour construire un tel système, nous devons utiliser des modèles multimodaux pour générer des embeddings et des LLM avec des capacités multimodales, telles que LLAVA, GPT4-V, Gemini 1.5, Claude 3.5 Sonnet, etc. pour générer des réponses.
Il existe plusieurs façons d'implémenter le RAG multimodal :
Utiliser un modèle d'intégration multimodale comme CLIP pour transformer les textes et les images en intégrations. Ensuite, récupérer le contexte pertinent en effectuant une recherche de similarité entre l'interrogation et l'intégration du texte ou de l'image. Enfin, transmettre le texte brut et/ou l'image du contexte le plus pertinent à notre LLM multimodal.
Utiliser un LLM multimodal pour produire des résumés textuels d'images ou de tableaux. Ensuite, transformez ces résumés textuels en enchâssements à l'aide d'un modèle d'enchâssement basé sur le texte. Ensuite, effectuez une recherche de similarité textuelle entre la requête et les résumés intégrés. Enfin, nous transmettons l'image brute du résumé le plus pertinent à notre LLM pour la génération de réponses.
Pour en savoir plus sur la manière de construire une application RAG multimodale, consultez nos tutoriels utilisant les différentes approches présentées ci-dessous :
[Construire un RAG multimodal avec Gemini, BGE-M3, Milvus et LangChain] (https://zilliz.com/learn/build-multimodal-rag-gemini-bge-m3-milvus-langchain)
Construire de meilleurs pipelines RAG multimodaux avec FiftyOne, LlamaIndex et Milvus
RAG multimodal : aller au-delà du texte pour une IA plus intelligente
Comparaison entre unimodal et multimodal
Les systèmes multimodaux se distinguent des systèmes traditionnels (unimodaux) par le fait qu'ils traitent et intègrent simultanément des données provenant de plusieurs types de modalités d'entrée (texte, images et son, par exemple).
Les systèmes multimodaux ont un avantage dans la compréhension du contexte parce qu'ils extraient des informations de deux sources : la vision et le langage. Les approches traditionnelles sont plus simples et se concentrent sur des domaines d'application spécifiques. Le tableau suivant illustre certaines différences essentielles entre les systèmes unimodaux et multimodaux.
| Aspect | Aspect traditionnel | Aspect multimodal | Aspect multimodal | Aspect traditionnel | Aspect multimodal | **Aspect multimodal |
| Les systèmes multimodaux sont des systèmes qui utilisent un seul type d'entrée (par exemple, uniquement du texte, uniquement des images) et qui traitent plusieurs types d'entrée (par exemple, du texte, des images, du son). | ||||||
| Traitement d'informations multiples (par ex. texte, images, audio) - Traitement d'informations multiples (par ex. texte, images, audio) - Traitement d'informations multiples (par ex. texte, images, audio) - Traitement d'informations multiples (par ex. texte, images, audio) | ||||||
| Les données sont plus complexes en raison de la nécessité d'intégrer divers types de données. | ||||||
| La compréhension du contexte est limitée à l'information disponible dans une seule modalité. | ||||||
| Les applications sont nombreuses : classification de textes, détection d'objets, reconnaissance de la parole, etc. | Interaction homme-machine, robotique, véhicules autonomes, réalité augmentée, etc. |
Avantages et défis de l'IA multimodale
Cette section énumère les avantages essentiels et les défis associés à la construction et à l'évaluation de systèmes multimodaux.
Avantages
Certains des avantages de l'utilisation de l'IA multimodale sont énumérés ci-dessous :
**Les systèmes multimodaux saisissent un contexte plus large en intégrant des informations complémentaires provenant de différentes sources, par exemple en combinant des indices visuels avec le langage pour une meilleure interprétation.
Amélioration des performances: En intégrant des données provenant de modalités multiples, l'IA multimodale peut faire des prédictions et prendre des décisions plus précises. Par exemple, un système de diagnostic médical peut être plus fiable s'il prend en compte les images et les dossiers médicaux des patients.
Polyvalence: L'IA multimodale peut être appliquée à diverses tâches complexes, notamment le sous-titrage d'images, la réponse à des questions visuelles, les diagnostics médicaux, la conduite autonome, etc.
Une compréhension plus proche de l'humain : L'IA multimodale peut mieux imiter la cognition humaine et permettre une meilleure interaction homme-machine dans les applications en temps réel en traitant les données provenant de différents sens (modalités).
Défis
Les défis liés à l'utilisation de l'IA multimodale sont les suivants :
**La méthode ou le format dans lequel les modalités sont représentées permet d'extraire les informations complémentaires ou redondantes entre les modalités multiples. La représentation des données multimodales est très importante mais difficile en raison de leur nature hétérogène. Par exemple, le son est un signal et l'image est une représentation 3D avec des échelles et des dimensions variables. La manière de les intégrer dans le même espace de représentation commun est un point essentiel de la mise en œuvre.
**La procédure peut expliquer comment convertir ou transformer des données d'une modalité à l'autre lorsqu'elles sont hétérogènes. La relation entre les différentes modalités est principalement subjective. Par exemple, la traduction d'une vidéo en sa description textuelle correspondante.
**La fusion : elle consiste à combiner des données provenant de plusieurs modalités afin d'améliorer les prédictions. Par exemple, dans la reconnaissance vocale audiovisuelle, la description visuelle du mouvement des lèvres est intégrée au signal vocal pour prédire les mots prononcés. Les informations peuvent provenir de différentes modalités et avoir différents niveaux de force prédictive, d'importance, de contribution et de topologie du bruit. Il manque des données dans au moins une des modalités.
Explicabilité : Un terme récent, l'IA explicable (XAI), vise à fournir des explications et des raisonnements significatifs sur un modèle. Dans le cas de modalités multiples, il est plus difficile de comprendre comment les modèles parviennent à des conclusions avec différentes sources de données.
FAQ sur l'IA multimodale
- **Qu'est-ce que l'IA multimodale ?
L'IA multimodale est un type de système d'intelligence artificielle capable de traiter et d'analyser des informations provenant de différentes modalités, notamment le texte, les images, l'audio et la vidéo.
- **Quels types de données l'IA multimodale peut-elle utiliser ?
L'IA multimodale utilise différents types de données, notamment des textes, des images, des sons, des vidéos, des capteurs et des données graphiques.
- **L'IA multimodale remplace-t-elle l'IA traditionnelle ?
L'IA multimodale ne remplace pas l'IA traditionnelle, mais étend ses capacités en intégrant de multiples modalités de données. Il s'agit d'une extension. Les méthodes traditionnelles restent essentielles, tandis que l'IA multimodale fournit des capacités supplémentaires.
- **Quelles sont les applications typiques de l'IA multimodale ?
Les applications typiques de l'IA multimodale comprennent le sous-titrage d'images, la réponse à des questions visuelles, la reconnaissance des émotions et la conduite autonome.
- **Quels sont les avantages de l'IA multimodale ?
L'IA multimodale présente plusieurs avantages, notamment la robustesse, l'efficacité, la prise en compte du contexte, la diversité des domaines d'application et l'amélioration de l'interaction homme-machine.
Ressources connexes
Qu'est-ce qu'une base de données vectorielle et comment fonctionne-t-elle ?](https://zilliz.com/learn/what-is-vector-database)
Qu'est-ce que la vision par ordinateur ?] (https://zilliz.com/learn/what-is-computer-vision)
Construire des applications d'IA avec Milvus : Tutoriels et carnets de notes
Modèles d'IA les plus performants pour vos applications GenAI | Zilliz
- Qu'est-ce que l'IA multimodale ?
- Comment fonctionne l'IA multimodale ?
- Modèles multimodaux populaires et leurs architectures
- RAG multimodal : au-delà du texte
- Comparaison entre unimodal et multimodal
- Avantages et défis de l'IA multimodale
- FAQ sur l'IA multimodale
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement