




Fonctions d’activation dans les réseaux neuronaux

Fonctions d’activation dans les réseaux neuronaux
 Activation Functions.png
Activation Functions.png
Les avancées récentes en intelligence artificielle (IA ) ont été incroyables, en particulier dans la reconnaissance d’images, le traitement du langage naturel (NLP) et les voitures autonomes. Un facteur clé contribuant à ces réussites est la capacité des réseaux neuronaux artificiels à estimer des fonctions complexes et non linéaires souvent présentes dans les données du monde réel. Cette capacité est principalement attribuée aux fonctions d’activation, qui introduisent de la non-linéarité dans les réseaux neuronaux, leur permettant de modéliser des relations et des motifs complexes.
Comprenons en profondeur les fonctions d’activation, leur objectif, leur fonctionnement et pourquoi elles sont importantes pour les réseaux neuronaux.
Que sont les fonctions d’activation ?
Les fonctions d’activation sont des fonctions mathématiques utilisées dans les réseaux neuronaux pour déterminer la sortie d’un neurone, en introduisant de la non-linéarité dans le modèle. Elles sont appliquées aux entrées des nœuds (neurones), les unités fondamentales d’un réseau neuronal, afin de produire la sortie du nœud. Un réseau neuronal calcule la somme pondérée des entrées, ajoute un biais, puis fait passer cette somme par la fonction d’activation, qui produit une valeur modifiée. Cette valeur est transmise à la couche suivante du réseau ou devient la sortie finale.
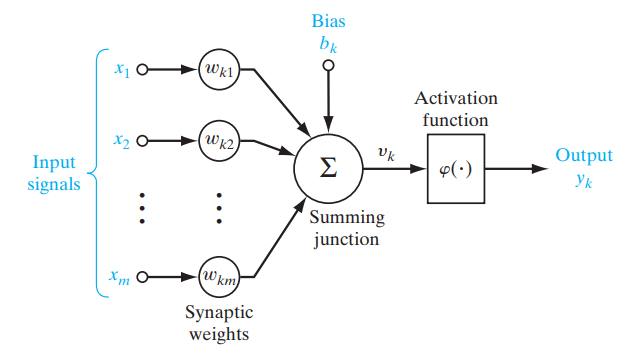 Figure- Role of an activation function in a neural network. .png
Figure- Role of an activation function in a neural network. .png
Figure : Rôle d’une fonction d’activation dans un réseau neuronal. | Source
Pourquoi la non-linéarité est-elle importante ?
Pour comprendre pourquoi les fonctions d’activation sont essentielles, il est important de savoir pourquoi les modèles linéaires ont des limites. Un modèle linéaire représente une relation en ligne droite entre les entrées et les sorties. Il fonctionne bien dans les tâches simples, mais échoue lorsque les données sont plus complexes et présentent des motifs non linéaires.
La non-linéarité permet aux réseaux neuronaux de créer des frontières de décision qui ne sont pas des lignes droites. Par conséquent, les réseaux neuronaux peuvent comprendre des motifs non linéaires dans les données qui ne peuvent pas être représentés par des modèles linéaires.
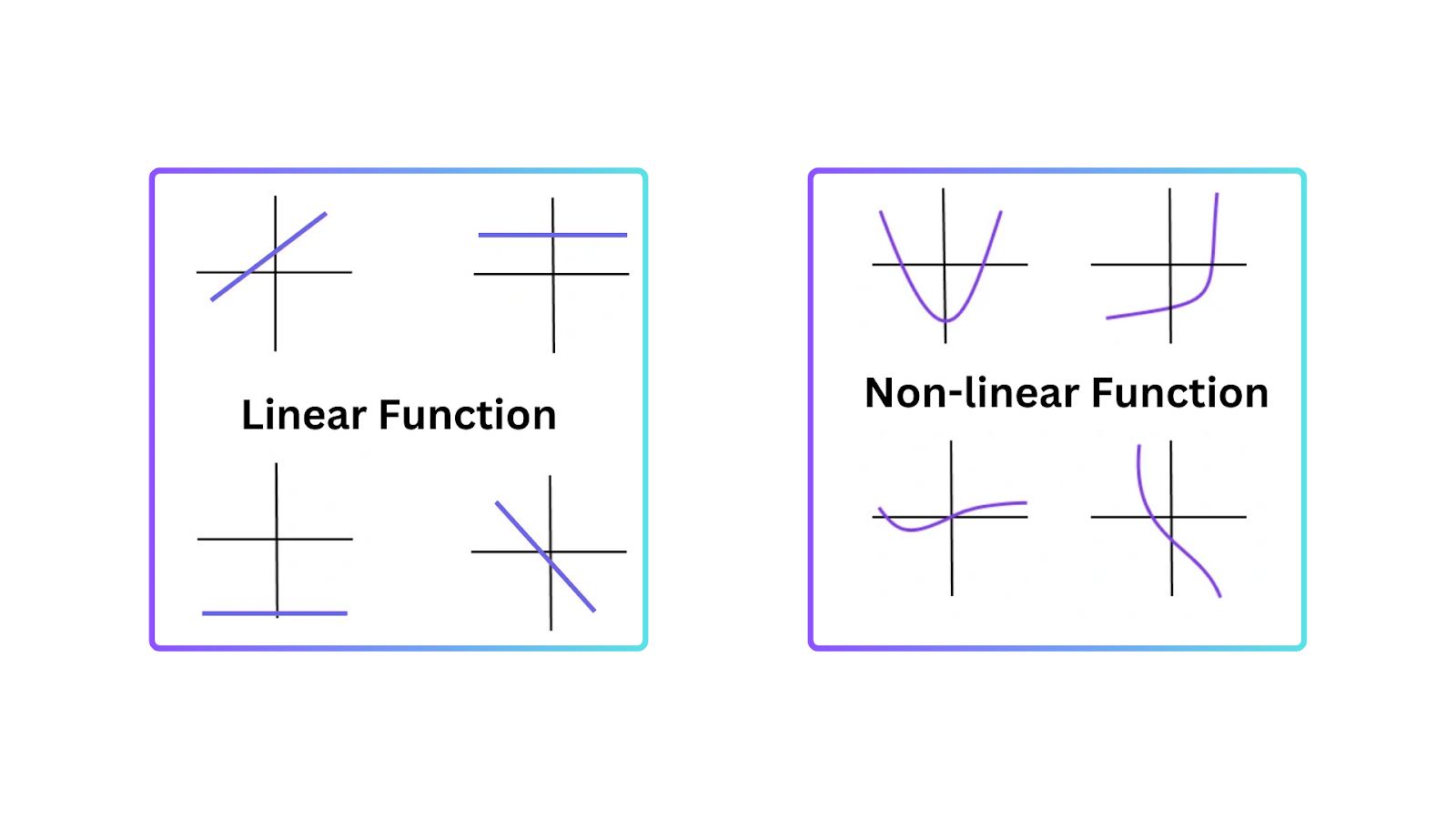 Figure- Types of Functions.png
Figure- Types of Functions.png
Figure : Types de fonctions
Fonctionnement des fonctions d’activation
Maintenant que nous avons introduit les fonctions d’activation, voyons comment ces fonctions fonctionnent mathématiquement pour convertir le signal d’entrée en signal de sortie, une plage souvent comprise entre 0 et 1 ou entre -1 et 1. Dans chaque neurone d’un réseau neuronal, les données circulent selon les étapes suivantes :
Entrée : Chaque neurone d’un réseau neuronal reçoit une ou plusieurs entrées. Ces entrées peuvent provenir des données d’origine alimentant le réseau (dans le cas de la couche d’entrée) ou des sorties des neurones de la couche précédente.
Calcul de la somme pondérée : Les entrées sont multipliées par des poids correspondants pour déterminer leur importance. Ensuite, les entrées pondérées sont additionnées, et une valeur unique est renvoyée, appelée somme pondérée.
Application de la fonction d’activation : Une fois la somme pondérée calculée, elle est passée par une fonction d’activation, et le résultat de la fonction d’activation devient la sortie du neurone.
Ce processus se répète dans chaque neurone à travers les couches du réseau afin de transformer les données de manière plus complexe.
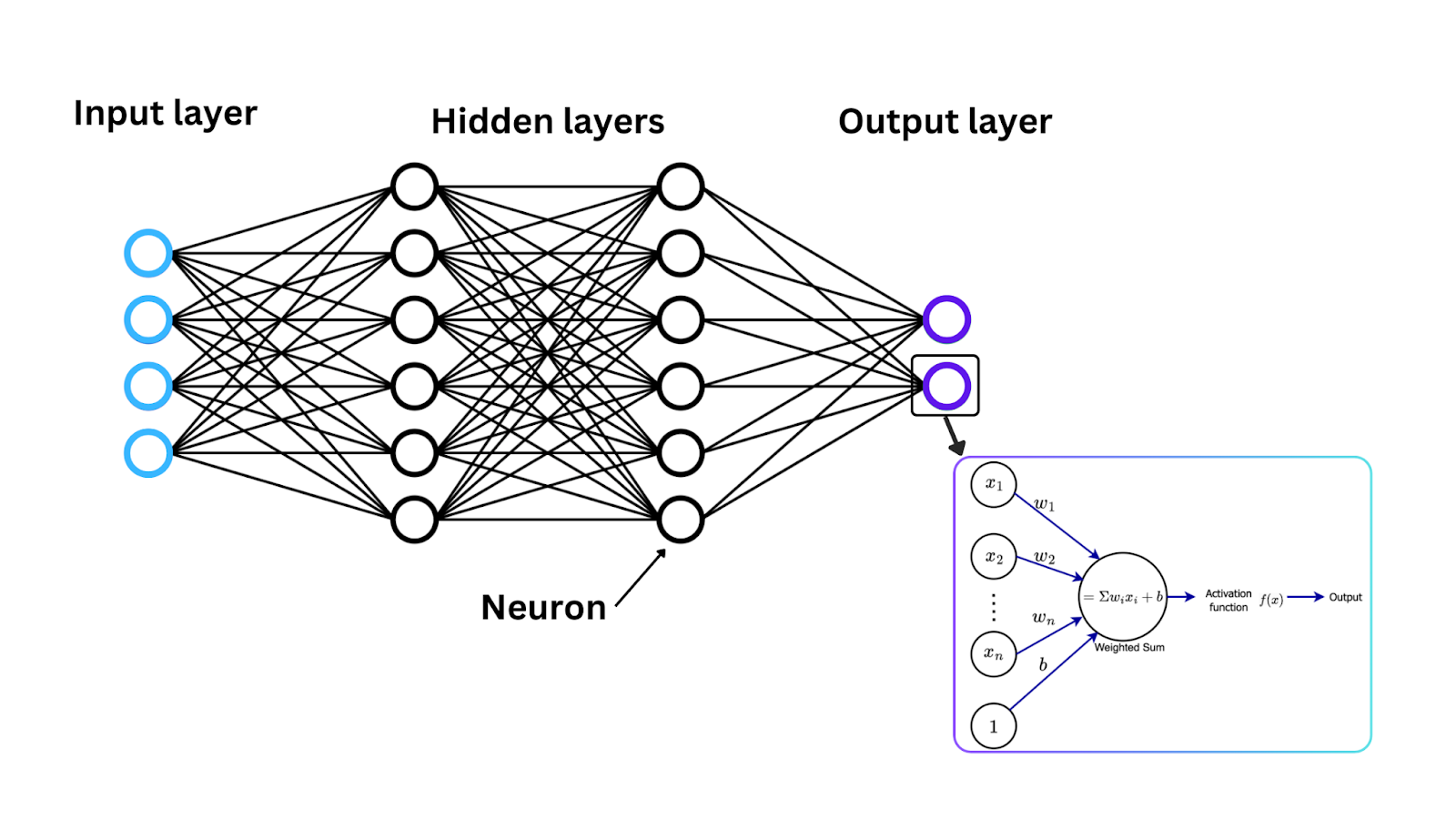 Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figure : Architecture d’un réseau neuronal, fonction d’activation et mises à jour des poids des neurones.
Les réseaux neuronaux utilisent différents types de fonctions d’activation. Chaque fonction a ses propres forces et convient mieux à des tâches spécifiques. Par exemple, la fonction sigmoïde est optimale pour les problèmes de classification binaire, softmax est utile pour la prédiction multi-classes, et ReLU aide à surmonter le problème du gradient évanescent.
Choisir la bonne fonction d’activation accélère l’entraînement et améliore les performances. Maintenant, examinons quelques-unes des fonctions d’activation courantes :
Activation sigmoïde
Activation ReLU (Rectified Linear Unit)
Activation Tanh (Tangente hyperbolique)
Activation Leaky ReLU
Activation sigmoïde
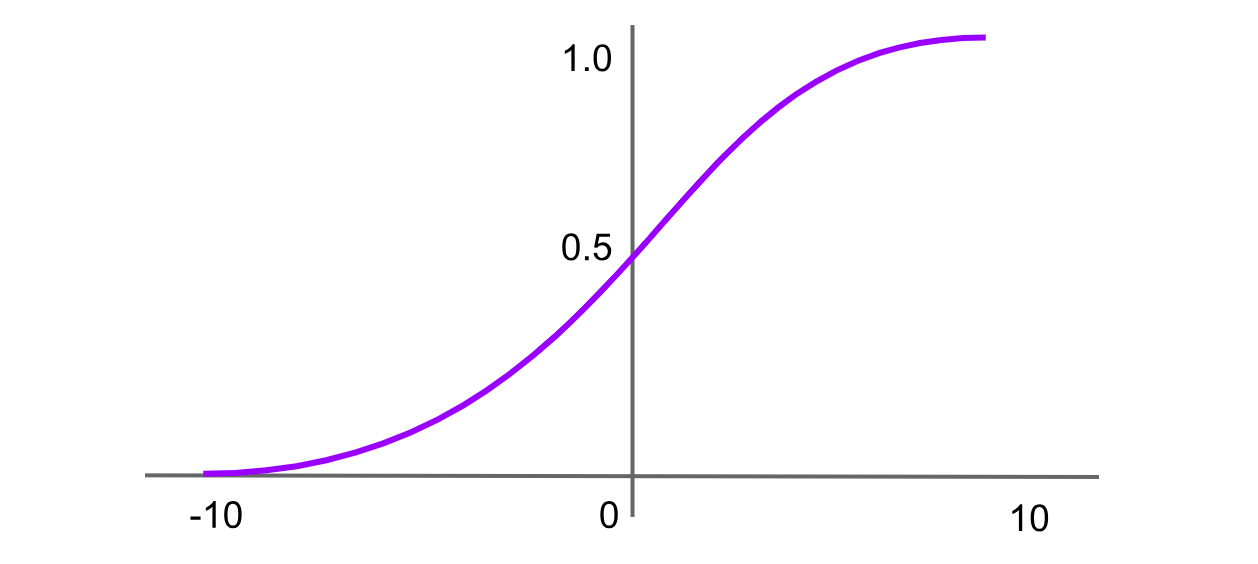 Figure- Fonction d’activation sigmoïde.png
Figure- Fonction d’activation sigmoïde.png
Figure : Fonction d’activation sigmoïde
La fonction sigmoïde, également appelée fonction logistique, est l’une des fonctions d’activation les plus anciennes et les plus largement connues. Elle projette toute valeur d’entrée dans une plage comprise entre 0 et 1, produisant une courbe en forme de « S ». La formule de la fonction sigmoïde est :
Sigmoïde = σ(x) = 1 / (1 + exp(-x))
Voici le code pour définir la fonction sigmoïde en Python.
import numpy as np
def sigmoid_function(x):
z = (1/(1 + np.exp(-x)))
return z
Les fonctions sigmoïdes sont utiles pour les modèles où nous devons prédire une probabilité en sortie. Par exemple, dans les problèmes de classification binaire, nous voulons que la sortie soit interprétée comme une probabilité entre 0 et 1.
Cependant, la sigmoïde présente un problème de gradient évanescent. Pendant la rétropropagation (lorsque le réseau apprend en mettant à jour les poids), les gradients sigmoïdes deviennent très petits, ce qui entraîne un apprentissage lent pour les couches plus profondes.
Activation Softmax
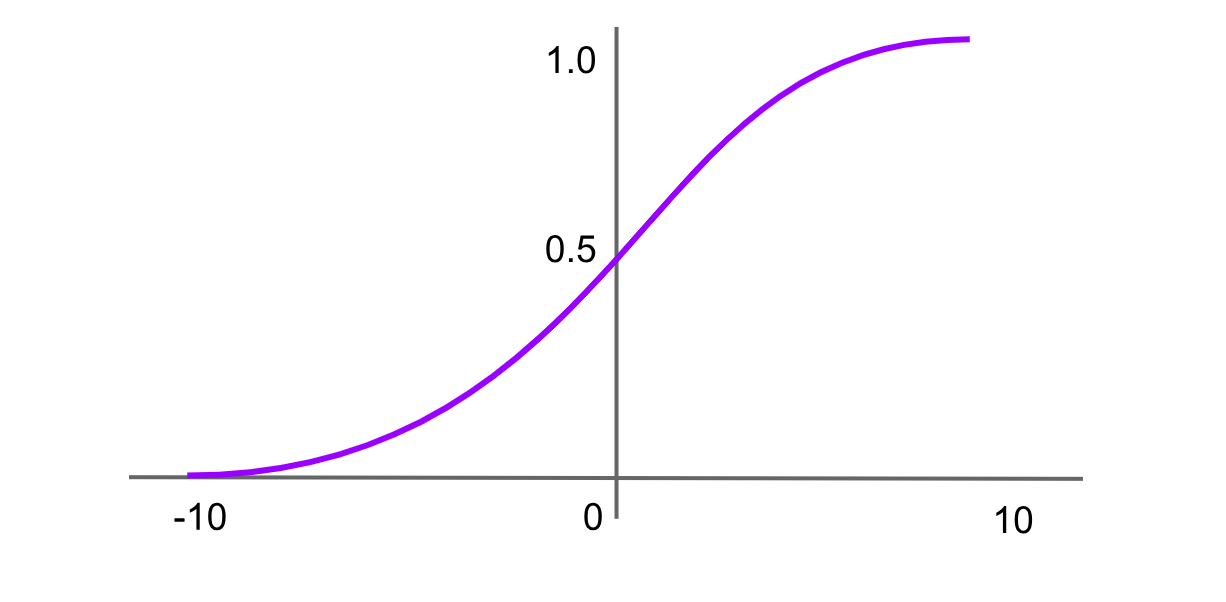 Figure- Fonction d’activation Softmax.png
Figure- Fonction d’activation Softmax.png
Figure : Fonction d’activation Softmax
La fonction softmax est couramment utilisée dans la couche de sortie des réseaux neuronaux pour les problèmes de classification multi-classes. Elle prend en entrée un vecteur de nombres réels et le normalise en une distribution de probabilité sur les classes. Chaque sortie est comprise entre 0 et 1, et la somme de toutes les sorties est égale à 1. La formule de la fonction softmax est :
Softmax(x)=f(xi)= exp(x) / sum(exp(x))
Codons cela en Python.
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_
Cependant, Softmax peut être coûteuse en calcul, en particulier dans les grands réseaux, car elle nécessite de calculer des exponentielles et de les normaliser sur toutes les sorties.
Activation ReLU (Rectified Linear Unit)
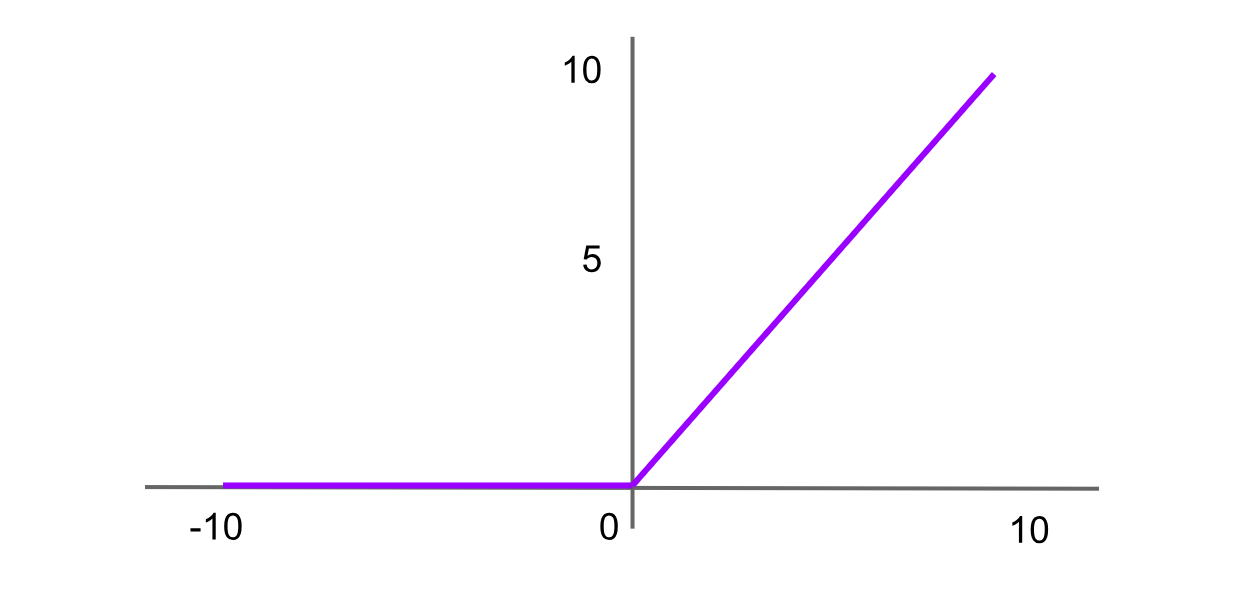 Figure- Fonction d’activation ReLU.png
Figure- Fonction d’activation ReLU.png
Figure : Fonction d’activation ReLU
ReLU est l’une des fonctions d’activation les plus utilisées dans les réseaux neuronaux avancés. Elle renvoie 0 pour toute entrée négative, et pour les valeurs positives, elle renvoie la valeur elle-même. La formule de la fonction ReLU est :
ReLU = f(x) = max(0,x)
Voici la fonction Python pour ReLU :
def relu_function(x):
if x<0:
return 0
else:
return x
ReLU est utilisée dans les couches cachées des réseaux neuronaux, en particulier dans les tâches de vision par ordinateur. Elle est efficace sur le plan computationnel, car elle ne comporte pas d’opérations exponentielles ni de division. Comparée à la sigmoïde, elle est également moins affectée par le problème du gradient évanescent. Cependant, ReLU présente un inconvénient, à savoir le problème du « dying ReLU ». Si un neurone produit constamment zéro pour toutes les entrées, il devient inactif et ne peut plus contribuer à l’apprentissage.
Activation Tanh (Tangente hyperbolique)
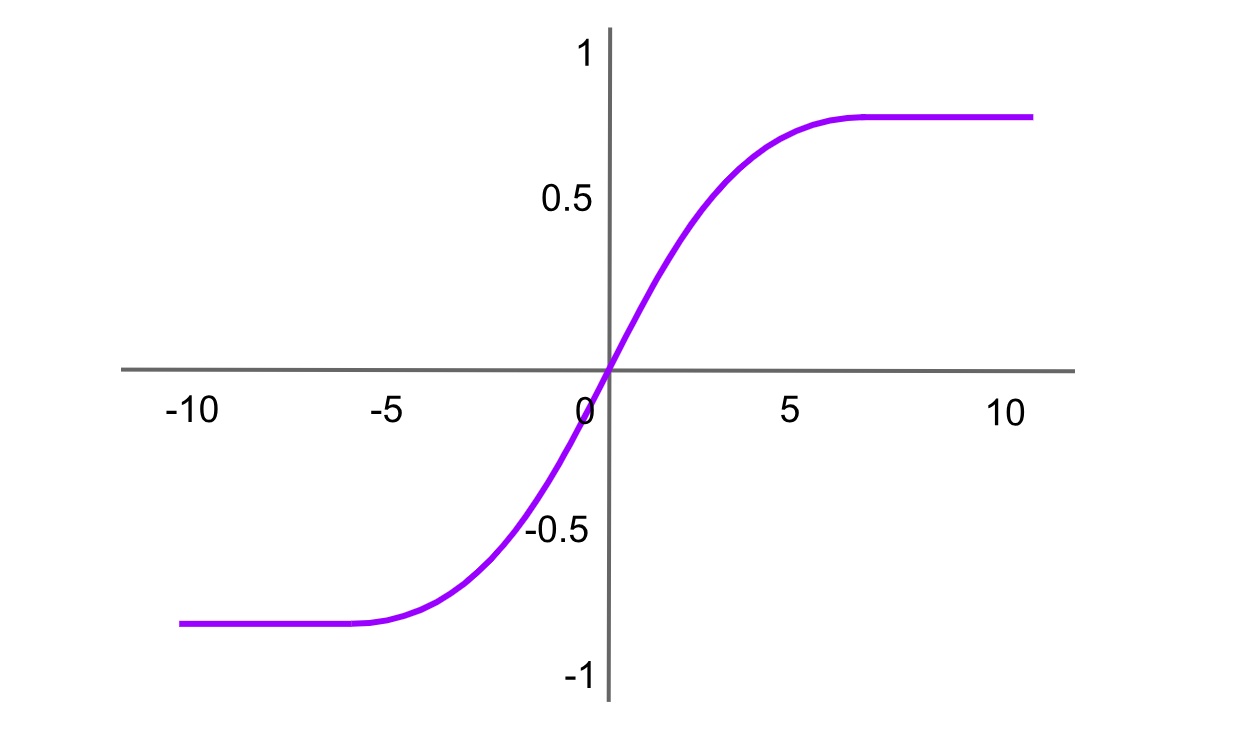 Figure- Fonction d’activation Tanh .png
Figure- Fonction d’activation Tanh .png
Figure : Fonction d’activation Tanh
La fonction tangente hyperbolique est similaire à la fonction sigmoïde, mais produit des valeurs comprises entre -1 et 1. La formule de la fonction Tanh est :
tanh(x)= f(x)= 2 / (1+exp (−2x ))−1
Ou
tanh(x)= f(x)=2sigmoid(2x)-1
Voici le code Python correspondant :
def tanh_function(x):
z = (2/(1 + np.exp(-2*x))) -1
return z
La tangente hyperbolique est utilisée dans les couches cachées des réseaux de neurones, en particulier dans les tâches de traitement du langage naturel (NLP). Elle partage certaines similitudes avec la fonction sigmoïde, mais présente l’avantage d’être centrée sur zéro, ce qui peut accélérer l’apprentissage dans certains réseaux. Cependant, comme la fonction sigmoïde, tanh est également affectée par le problème de disparition du gradient.
Activation Leaky ReLU
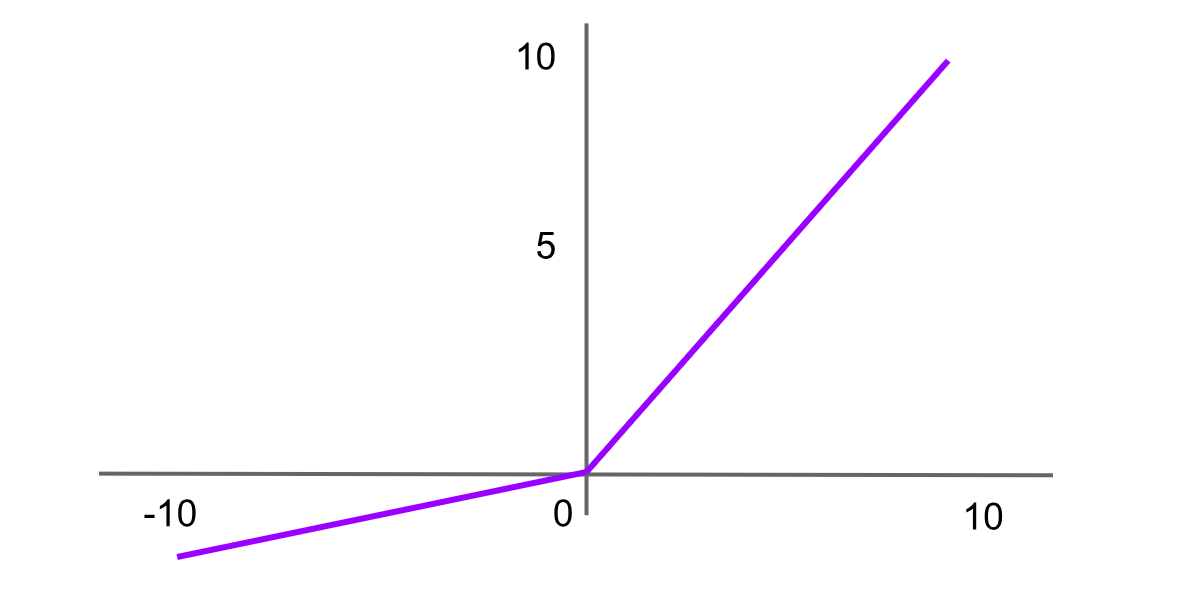 Figure- Fonction d’activation Leaky ReLU .png
Figure- Fonction d’activation Leaky ReLU .png
Figure : Fonction d’activation Leaky ReLU
Leaky Rectified Linear Unit, ou Leaky ReLU, est une variante de ReLU conçue pour résoudre le problème du « ReLU mourant » en introduisant une petite pente pour les valeurs négatives au lieu d’une pente plate. Cela aide les neurones à continuer à apprendre au lieu de devenir définitivement inactifs. La formule de la fonction Leaky ReLU est :
Leaky ReLU = f(x)=max(αx,x)
Ici, 𝛼 α est une petite constante positive (par exemple, 0,01) afin de garantir que le neurone produit une petite valeur négative au lieu de zéro pour les entrées négatives. Étant donné que Leaky ReLU est une variante de ReLU, le code Python peut être implémenté avec une modification mineure.
def leaky_relu_function(x):
if x<0:
return 0.01*x
else:
return x
Comparaison
Pour obtenir une meilleure compréhension des fonctions d’activation, il est utile de les comparer à d’autres composants clés des réseaux de neurones :
Fonctions d’activation vs. fonctions de perte
Les fonctions d’activation définissent la manière dont les neurones d’un réseau réagissent aux signaux entrants. Elles sont appliquées aux sorties des neurones (ou des couches) pour introduire de la non-linéarité, ce qui aide le réseau à comprendre les motifs et les relations dans les données.
D’autre part, les fonctions de perte sont utilisées pour déterminer dans quelle mesure les prédictions du réseau de neurones correspondent aux valeurs cibles réelles (la vérité terrain). Elles calculent l’erreur entre la sortie prédite et les résultats réels. De plus, les algorithmes d’optimisation ajustent les poids du réseau pendant l’entraînement afin de minimiser cette erreur. Les fonctions de perte incluent :
Erreur quadratique moyenne (MSE) est couramment utilisée pour les tâches de régression.
Perte d’entropie croisée est utilisée pour les tâches de classification.
Fonctions d’activation vs. normalisation
Les fonctions d’activation contrôlent la manière dont les données se déplacent d’une couche à une autre et comment les neurones « s’activent » en fonction des entrées.
Cependant, la normalisation, comme la normalisation par lots, aide à rendre l’entraînement plus efficace. Elle fonctionne en modifiant la distribution des entrées d’une couche afin d’accélérer l’apprentissage du réseau et de prévenir la disparition ou l’explosion des gradients. La normalisation par lots normalise l’entrée de chaque couche afin d’avoir une moyenne et une variance cohérentes et aide la convergence du réseau à être plus facile. Les autres techniques de normalisation incluent :
Normalisation par couche** :** Normalise à travers chaque couche.
Normalisation d’instance : Généralement utilisée dans le traitement d’images, elle normalise chaque instance séparément.
Avantages et défis des fonctions d’activation
Les fonctions d’activation offrent plusieurs avantages aux réseaux neuronaux, mais elles présentent également des défis qui doivent être relevés. Commençons par discuter des avantages des fonctions d’activation.
Non-linéarité : L’avantage le plus important des fonctions d’activation est qu’elles introduisent de la non-linéarité dans le réseau. Cela aide les réseaux à capturer des motifs non linéaires dans les données et est idéal pour des tâches telles que la reconnaissance d’images et la compréhension du langage naturel.
Plage de sortie : Les fonctions d’activation comme sigmoid et softmax bornent les sorties dans une plage spécifique (0-1 pour sigmoid et entre -1 et 1 pour tanh). Cela rend les sorties beaucoup plus simples à comprendre, en particulier dans les tâches de classification.
Calcul efficace : Certaines fonctions, comme ReLU, sont efficaces sur le plan computationnel, ce qui permet aux réseaux de passer à l’échelle et d’être appliqués à de grands ensembles de données.
Maintenant, discutons des défis des fonctions d’activation.
Problème du gradient évanescent : il est courant dans les réseaux neuronaux profonds, principalement lors de l’utilisation de fonctions d’activation comme sigmoid et tanh. Pendant la rétropropagation, les gradients peuvent devenir très faibles lorsqu’ils se propagent à travers plusieurs couches du réseau, entraînant une convergence lente du réseau et l’empêchant d’apprendre efficacement.
Gradients explosifs : Les gradients explosifs sont un problème dans lequel de grands gradients d’erreur s’accumulent, entraînant de très grandes mises à jour des poids des modèles de réseaux neuronaux pendant le processus d’entraînement. Cela rend le modèle instable et incapable d’apprendre à partir des données d’entraînement.
Choix de la fonction : Choisir la fonction d’activation optimale pour une tâche ou un réseau neuronal peut être difficile et nécessite généralement quelques expérimentations. Cela dépend du type de problème que nous essayons de résoudre.
Cas d’utilisation des fonctions d’activation
Les fonctions d’activation sont des composants importants de diverses architectures de réseaux neuronaux qui effectuent différentes tâches. Voici quelques applications clés :
Classification d’images : Les Convolutional Neural Networks (CNNs) utilisent l’activation ReLU dans leurs couches cachées pour traiter les données de pixels et softmax dans la couche de sortie pour la classification multiclasse.
Traitement du langage naturel (NLP) : Les Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) et Transformers utilisent les activations tanh ou ReLU dans leurs couches cachées pour traiter des données séquentielles.
Modèles génératifs : Les Generative Adversarial Networks (GANs) utilisent généralement ReLU ou LeakyReLU dans le réseau générateur pour introduire de la non-linéarité et générer des sorties réalistes, et sigmoid dans le réseau discriminateur.
Plusieurs frameworks de deep learning, notamment TensorFlow et PyTorch, fournissent un large éventail de fonctions d’activation intégrées et d’implémentations pour créer vos propres fonctions personnalisées.
FAQ sur les fonctions d’activation
- Qu’est-ce que la fonction d’activation ?
Les fonctions d’activation sont des blocs de base fondamentaux des réseaux neuronaux qui leur permettent d’apprendre des motifs complexes dans les données d’entrée. Elles convertissent le signal d’entrée d’un nœud (neurone) en un signal de sortie, qui est ensuite transmis à la couche suivante du réseau neuronal.
- Pourquoi la fonction d’activation ReLU est-elle utilisée ?
La fonction d’activation ReLU introduit de la non-linéarité dans un réseau neuronal, ce qui aide à réduire le problème du gradient évanescent pendant l’entraînement du modèle de machine learning.
- Quelles sont les fonctions d’activation les plus couramment utilisées ?
ReLU, Leaky ReLU, Softmax et Swish sont des fonctions d’activation populaires.
- À quoi sert la fonction d’activation ?
L’objectif principal d’une fonction d’activation est de transformer l’entrée pondérée sommée provenant d’un nœud en une valeur de sortie, qui est ensuite transmise à la couche cachée suivante ou utilisée comme sortie finale.
- Peut-on avoir plusieurs fonctions d’activation ?
Oui, il est courant d’avoir différentes fonctions d’activation dans différentes couches d’un réseau neuronal. Par exemple, une configuration standard pourrait utiliser l’activation ReLU dans les couches cachées et softmax dans la couche de sortie pour un problème de classification multiclasse.
Ressources complémentaires
- Que sont les fonctions d’activation ?
- Fonctionnement des fonctions d’activation
- Comparaison
- Avantages et défis des fonctions d’activation
- Cas d’utilisation des fonctions d’activation
- FAQ sur les fonctions d’activation
- Ressources complémentaires
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement