




Mejorar su GAR con gráficos de conocimiento mediante KnowHow
La Retrieval Augmented Generation (RAG) es una técnica popular que proporciona al LLM conocimientos adicionales y memorias a largo plazo a través de una base de datos vectorial como Milvus y Zilliz Cloud (el Milvus totalmente gestionado). Un GAR básico puede resolver muchos quebraderos de cabeza del LLM, pero resulta insuficiente si se tienen requisitos más avanzados como la personalización o un mayor control de los resultados recuperados.
En nuestro reciente Unstructured Data Meetup, Chris Rec, el cofundador de WhyHow, compartió cómo incorpora Knowledge Graphs (KG) en la canalización de RAG para mejorar el rendimiento y la precisión. El blog cubrirá los puntos clave de su charla, incluyendo una visión general de los grafos de conocimiento, RAG, y cómo integrar los grafos de conocimiento en los sistemas RAG para un mejor rendimiento.
Si quiere saber más sobre este tema, le recomendamos que vea la charla completa en YouTube.
>.Una visión general del GAR y sus retos
La GAR es un método que aprovecha los puntos fuertes de los sistemas basados en la recuperación y en la inteligencia artificial generativa. Un RAG convencional suele constar de una base de datos vectorial como Milvus, un modelo de incrustación y un gran modelo lingüístico (LLM).
Un sistema RAG utiliza primero el modelo de incrustación para transformar los documentos en incrustaciones vectoriales y almacenarlos en una base de datos vectorial. A continuación, recupera la información de consulta pertinente de esta base de datos vectorial y proporciona los resultados recuperados al LLM. Por último, el LLM utiliza la información recuperada como contexto para generar resultados más precisos.
Flujo de trabajo RAG (https://assets.zilliz.com/RAG_chatbot_2f1ff9ec07.png)
Fig. 1: Funcionamiento del GAR
Aunque un RAG de vainilla es maravilloso a la hora de generar resultados más actualizados y precisos, sigue teniendo varias limitaciones.
**Por ejemplo, el término "capacidad vehicular" puede referirse tanto al número de pasajeros que puede llevar un coche como al número de coches que caben en una carretera, lo que crea ambigüedad.
**Por ejemplo, responder a consultas basadas en la ubicación, como "Quiero ir a Londres", difiere mucho de responder a consultas más abstractas relacionadas con el bienestar, como "Estoy estresado en el trabajo y quiero tomarme unas vacaciones".
En tercer lugar, no es fácil distinguir entre similitud y relevancia. Por ejemplo, puede ser difícil diferenciar entre una "casa en la playa" a una milla de la orilla y una "casa en primera línea de playa" directamente sobre la arena.
**Recuperar toda la información relevante para preguntas exhaustivas puede resultar complicado, especialmente en el caso de consultas complejas, como la lista de todos los socios comanditarios (LP) de un fondo que hayan invertido al menos 10 millones de dólares y tengan derechos especiales de acceso a los datos.
Por último, las consultas multisalto añaden otro nivel de complejidad, ya que requieren combinar con precisión múltiples datos. Este enfoque requiere dividir una consulta en varias subconsultas, cada una con condiciones específicas, para garantizar que la respuesta final sea precisa y completa.
Aunque soluciones como la mejora de las consultas, las estrategias avanzadas de fragmentación, la mejora de los modelos de incrustación y la reordenación pueden abordar muchos de los retos asociados a la GAR, WhyHow adopta un enfoque diferente al incorporar grafos de conocimiento a la canalización de la GAR.
¿Qué son los grafos de conocimiento?
Un grafo de conocimiento (KG) es un tipo de estructura de datos que no sólo almacena datos, sino que también vincula datos similares o disímiles en función de su relación. Este enfoque conduce a tener una colección de cosas (que pueden ser cualquier tipo de datos) vinculadas de manera que puedan proporcionar información relacionada o relevante.
Un grafo de conocimiento consta de nodos, aristas y propiedades.
Fig. 2 - Elementos constitutivos de un grafo de conocimiento (https://assets.zilliz.com/Fig_2_Building_Blocks_of_a_Knowledge_Graph_3a3c13c822.png)
Fig. 2: Componentes de un grafo de conocimiento
Nodos:
Representan las entidades u objetos del grafo.
Almacenar valores de estas entidades puede ser cualquier tipo de datos.
Bordes:
Representan las relaciones entre las entidades.
Contienen información sobre la naturaleza de la relación entre los nodos conectados.
Propiedades: Características o rasgos asociados a entidades individuales.
A diferencia de las bases de datos tabulares tradicionales, los grafos de conocimiento utilizan una estructura de grafos para una representación flexible de las relaciones y se centran en la comprensión semántica. Este enfoque permite realizar consultas complejas y facilitar la extracción de información específica.
Ventajas de integrar grafos de conocimiento en los sistemas RAG
Al incorporar los grafos de conocimiento a la cadena de producción de GAR, podemos mejorar significativamente la capacidad de recuperación del sistema y la calidad de las respuestas, lo que se traduce en un mayor rendimiento, precisión, trazabilidad y exhaustividad. Estas son las principales ventajas de un sistema GAR basado en grafos de conocimiento:
Mayor comprensión contextual
Los grafos de conocimiento proporcionan una representación rica e interconectada de la información, lo que permite al sistema GAR comprender relaciones complejas entre entidades. Esta comprensión contextual más profunda conduce a respuestas más matizadas y pertinentes.
Mayor precisión y coherencia factual
La naturaleza estructurada de los gráficos de conocimiento ayuda a mantener la coherencia factual en todo el contenido generado. Al anclar las respuestas a información verificada dentro del gráfico, el sistema puede reducir los errores y las alucinaciones habituales en los modelos lingüísticos tradicionales.
Capacidades de razonamiento multisalto
Los grafos de conocimiento permiten al sistema RAG realizar razonamientos multisalto, conectando piezas dispares de información a través de vías lógicas. Esta capacidad permite responder a consultas y generar inferencias de forma más sofisticada.
Recuperación eficiente de la información
La estructura de grafos facilita una recuperación rápida y precisa de la información, incluso para consultas complejas. Esta eficiencia se traduce en tiempos de respuesta más rápidos y en la generación de contenidos más relevantes. Además, los sistemas RAG basados en grafos de conocimiento permiten un enfoque de recuperación híbrido, que combina el recorrido por los grafos con búsquedas vectoriales y por palabras clave, capacidades proporcionadas por bases de datos vectoriales como Milvus y Zilliz Cloud.
Más concretamente, este enfoque híbrido permite:
Comparación precisa de entidades y relaciones mediante el recorrido de grafos
Semantic similarity mediante vector embeddings
Búsqueda tradicional basada en palabras clave para contenidos con mucho texto
Esta estrategia de recuperación polifacética mejora la capacidad del sistema para encontrar la información más relevante entre distintos tipos y estructuras de datos, lo que permite obtener respuestas más completas y precisas.
Resultados transparentes y rastreables
Con los gráficos de conocimiento, el sistema puede proporcionar una procedencia clara de la información utilizada en la generación de respuestas. Esta trazabilidad aumenta la confianza del usuario y facilita la comprobación y verificación de los hechos.
Síntesis de conocimientos entre dominios
Al representar diversos ámbitos dentro de una única estructura gráfica, los sistemas RAG basados en grafos de conocimiento pueden sintetizar más fácilmente información de distintos campos, lo que permite obtener conocimientos más completos e interdisciplinarios.
Mejor gestión de la ambigüedad
La estructura relacional de los grafos de conocimiento ayuda a desambiguar entidades y conceptos, reduciendo la confusión en situaciones en las que los términos o nombres pueden tener múltiples significados o referencias.
Al aprovechar estas ventajas, las aplicaciones RAG mejoradas con grafos de conocimiento pueden proporcionar respuestas más precisas, contextualmente relevantes y completas a las consultas de los usuarios.
¿Qué es WhyHow? ¿Cómo mejora RAG con grafos de conocimiento?
WhyHow es una plataforma que permite construir y gestionar grafos de conocimiento para facilitar la recuperación de datos complejos. Construir grafos de conocimiento exhaustivos es complicado y requiere mucho tiempo. WhyHow resuelve este problema creando pequeños grafos de conocimiento e iterando sobre ellos varias veces hasta obtener un grafo satisfactorio para un dominio específico. Este enfoque ayuda a que sea altamente específico del dominio, más simple y fácil de trabajar, ya que los KG son complejos.
WhyHow también proporciona a los desarrolladores los bloques de construcción para organizar, contextualizar y recuperar de forma fiable datos no estructurados para realizar RAG complejas. Mediante la integración de WhyHow en sus pipelines RAG existentes alimentados por una base de datos vectorial, puede hacer que su sistema RAG tenga una mejor estructura, consistencia y control. El siguiente diagrama muestra cómo funciona una GAR mejorada con Knowledge Graph.
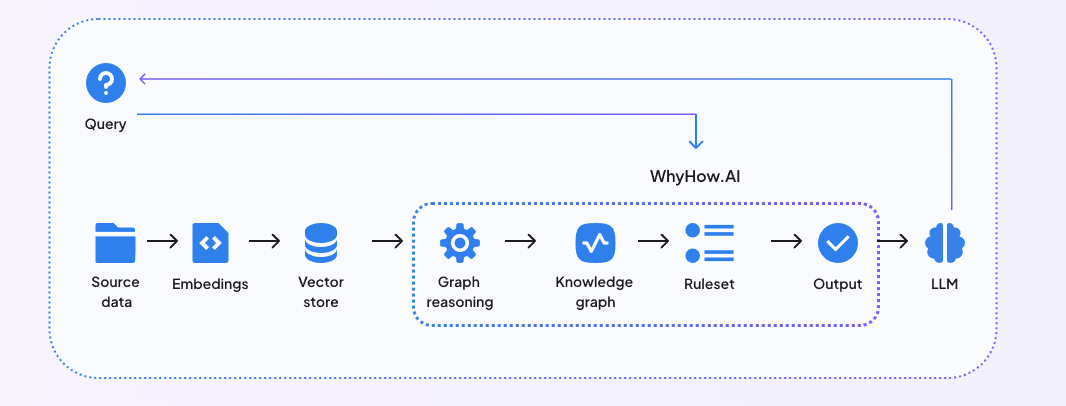 Fig 3- Integración de RAG con WhyHow
Fig 3- Integración de RAG con WhyHow
Fig 3: Integración del GAR con WhyHow
Al incorporar WhyHow en su flujo de trabajo RAG, puede adoptar un enfoque híbrido de grafos y vectores aprovechando lo mejor de los grafos de conocimiento y de las capacidades de búsqueda vectorial que ofrecen las bases de datos vectoriales.
Para obtener una guía más detallada sobre cómo crear un GAR mejorado con gráficos de conocimiento con WhyHow, te recomendamos que veas la demostración en directo compartida por Chris durante el encuentro sobre datos no estructurados organizado por Zilliz.
Tener más control sobre sus flujos de trabajo de recuperación dentro de RAG usando WhyHow y Zilliz Cloud
Además de hacer las aplicaciones RAG más performantes y rastreables, muchos desarrolladores también esperan tener un mayor control sobre lo que su RAG recupera. Esto se debe a que las aplicaciones RAG a veces no recuperan de forma consistente los fragmentos de datos correctos cuando los usuarios envían consultas mal formuladas o cuando los usuarios necesitan incluir datos contextualmente relevantes pero semánticamente diferentes en las respuestas.
Para resolver estos problemas, WhyHow crea un Paquete de recuperación basado en reglas mediante la integración con Zilliz Cloud. Este paquete de Python permite a los desarrolladores crear flujos de trabajo de recuperación más precisos con capacidades de filtrado avanzadas, lo que les proporciona un mayor control sobre el flujo de trabajo de recuperación dentro de las canalizaciones RAG. Este paquete se integra con OpenAI para la generación de texto y Zilliz Cloud para el almacenamiento y la eficiente búsqueda de similitud vectorial con filtrado de metadatos.
La solución de recuperación basada en reglas realiza estas tareas:
Creación del almacén de vectores: Crea una colección Milvus para almacenar incrustaciones de trozos.
División, Chunking, e Incrustación: Divide, fragmenta y crea automáticamente incrustaciones para documentos cargados usando PyPDFLoader y RecursiveCharacterTextSplitter de LangChain, y soporta el modelo de incrustación de texto-3-pequeño de OpenAI.
Inserción de datos: Carga incrustaciones y metadatos a Milvus o Zilliz Cloud.
Auto-filtrado: Construye un filtro de metadatos basado en reglas definidas por el usuario para refinar las consultas contra el almacén de vectores.
El flujo de trabajo es el siguiente:
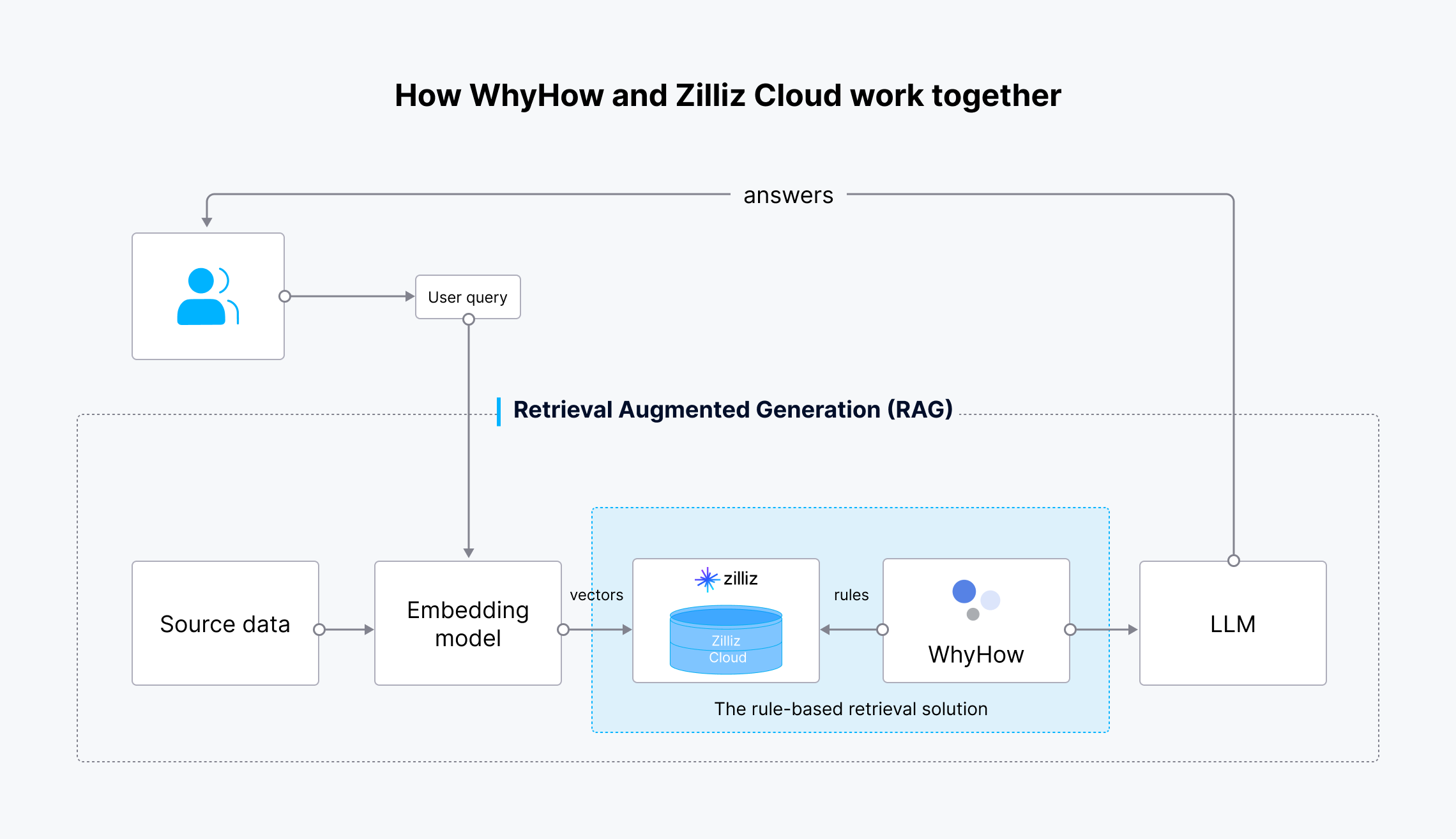 Cómo trabajan juntos WhyHow y Zilliz Cloud
Cómo trabajan juntos WhyHow y Zilliz Cloud
Fig 4: Flujo de trabajo de la solución de recuperación basada en reglas
Los datos de origen se transforman en incrustaciones vectoriales utilizando el modelo de incrustación de OpenAI y se introducen en Zilliz Cloud para su almacenamiento y recuperación. Cuando el usuario realiza una consulta, también se transforma en incrustaciones vectoriales y se envía a Zilliz Cloud para buscar los resultados más relevantes. WhyHow establece reglas y añade filtros a la búsqueda vectorial. Los resultados recuperados, junto con la consulta original del usuario, se envían al LLM, que genera resultados más precisos y los envía al usuario.
Conclusión
Los LLM realmente nos han aliviado la carga a la hora de encontrar respuestas a diversos problemas. Son lo bastante inteligentes como para entender la consulta proporcionada, pero alucinan, y es difícil mantenerlos actualizados debido a la limitación de recursos. De ahí que la técnica de generación aumentada de recuperación (RAG) les otorgue poder al proporcionar contexto a la consulta; sin embargo, los sistemas RAG también tienen limitaciones, como ya se ha comentado.
WhyHow identificó esas limitaciones, destacando que la solución radica en incorporar grafos de conocimiento a las canalizaciones RAG. Al mejorar la RAG con grafos de conocimiento, sus sistemas RAG pueden recuperar información más relevante y contextual y generar respuestas más determinables, con menos alucinaciones y una gran precisión.
Si quiere profundizar en este tema, vea la presentación de Chris en YouTube.
Más recursos
¿Qué es el GAR? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Cómo mejorar el rendimiento de su red GAR](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Optimización de la GAR con rederanqueadores: función y ventajas y desventajas](https://zilliz.com/learn/optimize-rag-with-rerankers-the-role-and-tradeoffs)
RAG completa: una arquitectura moderna para la hiperpersonalización](https://zilliz.com/blog/full-rag-modern-architecture-for-hyperpersonalization)
Creación de aplicaciones RAG inteligentes con LangServe, LangGraph y Milvus](https://zilliz.com/blog/build-intelligent-rag-with-langserve-langgraph-and-milvus)
Building RAG with Self-Deployed Milvus and Snowpark Container Services](https://zilliz.com/blog/build-rag-with-self-deployed-milvus-vector-database-and-snowpark-container-service)
Exploring DSPy and Its Integration with Milvus for Crafting Highly Efficient RAG Pipelines](https://zilliz.com/blog/exploring-dspy-and-its-integration-with-milvus-vector-database-for-RAG) Explorando DSPy y su integración con Milvus para la creación de tuberías RAG altamente eficientes

Sigue leyendo

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.