




Von Wörtern zu Vektoren: Das Verständnis von Word2Vec in der natürlichen Sprachverarbeitung (NLP)
Von Wörtern zu Vektoren: Das Verständnis von Word2Vec in der natürlichen Sprachverarbeitung (NLP)
Was ist Word2Vec?
Word2Vec ist ein Modell für maschinelles Lernen, das Wörter in numerische Vektordarstellungen umwandelt, um ihre Bedeutungen auf der Grundlage des Kontexts, in dem sie erscheinen, zu erfassen. Es wurde von Tomas Mikolov und seinem Team bei Google entwickelt und verwendet große Textdatensätze, um Beziehungen zwischen Wörtern zu verstehen und semantische und syntaktische Ähnlichkeiten darzustellen. Im Gegensatz zu traditionellen Ansätzen wie der One-Hot-Codierung erstellt Word2Vec dichte, aussagekräftige Einbettungen, bei denen ähnliche Wörter in einem kontinuierlichen Vektorraum näher beieinander liegen. Word2Vec wird häufig in Anwendungen der natürlichen Sprachverarbeitung wie Stimmungsanalysen und Empfehlungssystemen eingesetzt.
Warum brauchen wir Word2Vec?
Das Verständnis der Beziehungen und Bedeutungen von Wörtern ist eine zentrale Herausforderung in der Natürlichen Sprachverarbeitung (NLP). Herkömmliche Methoden, wie die One-Hot-Codierung, stellen Wörter als spärliche, hochdimensionale Vektoren dar, bei denen jedes Wort unabhängig von den anderen ist. Bei diesem Ansatz werden die semantischen oder syntaktischen Beziehungen zwischen den Wörtern nicht erfasst. Bei der One-Hot-Codierung würden beispielsweise die Vektoren für "König" und "Königin" völlig unverbunden erscheinen, obwohl ihre Bedeutungen eng miteinander verbunden sind.
Darüber hinaus sind diese spärlichen Repräsentationen rechnerisch ineffizient, insbesondere bei großen Vokabularen, und lassen sich nicht gut auf unbekannte Wörter oder Kontexte verallgemeinern. Diese Einschränkung erschwert es Maschinen, Sprache wirklich zu verstehen, und behindert Fortschritte bei Aufgaben wie maschineller Übersetzung, Stimmungsanalyse und Such-Ranking.
Word2Vec löst diese Herausforderungen, indem es kompakte, dichte Worteinbettungen erstellt, die Beziehungen zwischen Wörtern auf der Grundlage ihres Auftretens im Text darstellen. Durch die Erfassung sowohl der Bedeutung von Wörtern als auch ihres Kontexts hat Word2Vec die Art und Weise, wie Maschinen menschliche Sprache interpretieren und verarbeiten, verändert und sie effizienter und aussagekräftiger gemacht.
Wie funktioniert Word2Vec?
Das Herzstück von Word2Vec sind Worteinbettungen, d.h. niedrigdimensionale [dichte Vektoren] (https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning), die die semantischen und syntaktischen Eigenschaften von Wörtern erfassen. Word2Vec analysiert große Mengen an Text, um die Beziehungen zwischen den Wörtern zu erlernen. Im Kern handelt es sich um ein flaches neuronales Netzwerk, das Vektordarstellungen für Wörter erzeugt, die ihre semantischen und syntaktischen Bedeutungen erfassen. Das Modell erkennt Muster in der Art und Weise, wie Wörter in Sätzen gemeinsam vorkommen, und nutzt diese Informationen, um verwandte Wörter in einem kontinuierlichen Vektorraum näher aneinander zu positionieren.
Das Hauptkonzept besteht darin, dass ähnliche Vektoren Wörter mit ähnlichen Bedeutungen oder Verwendungskontexten darstellen. Zum Beispiel haben die Wörter "König" und "Königin" eng verwandte Vektoren, mit Unterschieden, die spezifische semantische Unterscheidungen wie das Geschlecht kodieren.
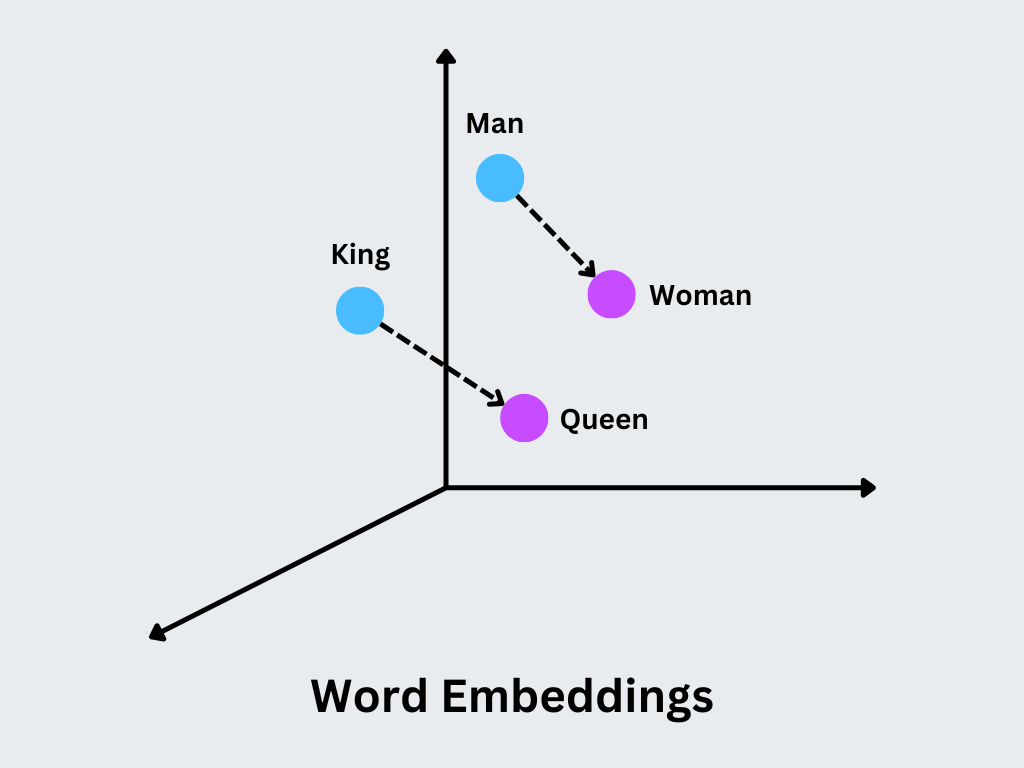 Abbildung- Worteinbettungen.png
Abbildung- Worteinbettungen.png
Abbildung: Worteinbettungen
Word2Vec bietet zwei Ansätze zur Erzeugung von Einbettungen, je nachdem, wie der Kontext behandelt wird:
Kontinuierlicher Wortsack (CBOW)
Continuous bag of words konzentriert sich auf die Vorhersage eines Zielwortes auf der Grundlage der umgebenden Wörter. In dem Satz "Äpfel sind süß und saftig" zum Beispiel verwendet CBOW die Kontextwörter ("Äpfel", "sind", "und" und "saftig"), um das Zielwort, wie "süß", vorherzusagen.
CBOW ist rechnerisch effizient, weil es den Durchschnitt der Kontextwörter bildet, um das Zielwort vorherzusagen. Es schneidet jedoch bei häufigen Wörtern besser ab und kann bei seltenen Begriffen Schwierigkeiten haben.
Anwendungsfall: CBOW wird häufig in Anwendungen wie der automatischen Vervollständigung und der Rechtschreibprüfung verwendet, wo die Vorhersage eines fehlenden oder nächsten Wortes erforderlich ist.
Skip-Gram Modell
Skip-Gram kehrt den Vorhersageprozess um. Anstatt ein Zielwort aus seinem Kontext vorherzusagen, sagt es die Kontextwörter auf der Grundlage eines Zielworts voraus. Wenn das Zielwort zum Beispiel "süß" ist, sagt Skip-Gram die Kontextwörter "Äpfel", "sind", "und" und "saftig" voraus.
Skip-Gram kommt besser mit seltenen Wörtern zurecht und ist besonders effektiv bei der Erfassung nuancierterer Beziehungen, wenn mit großen Datensätzen gearbeitet wird.
Anwendungsfall: Skip-Gram ist wertvoll bei Aufgaben wie dem Aufbau von Empfehlungssystemen oder dem Clustering ähnlicher Begriffe in Spezialgebieten.
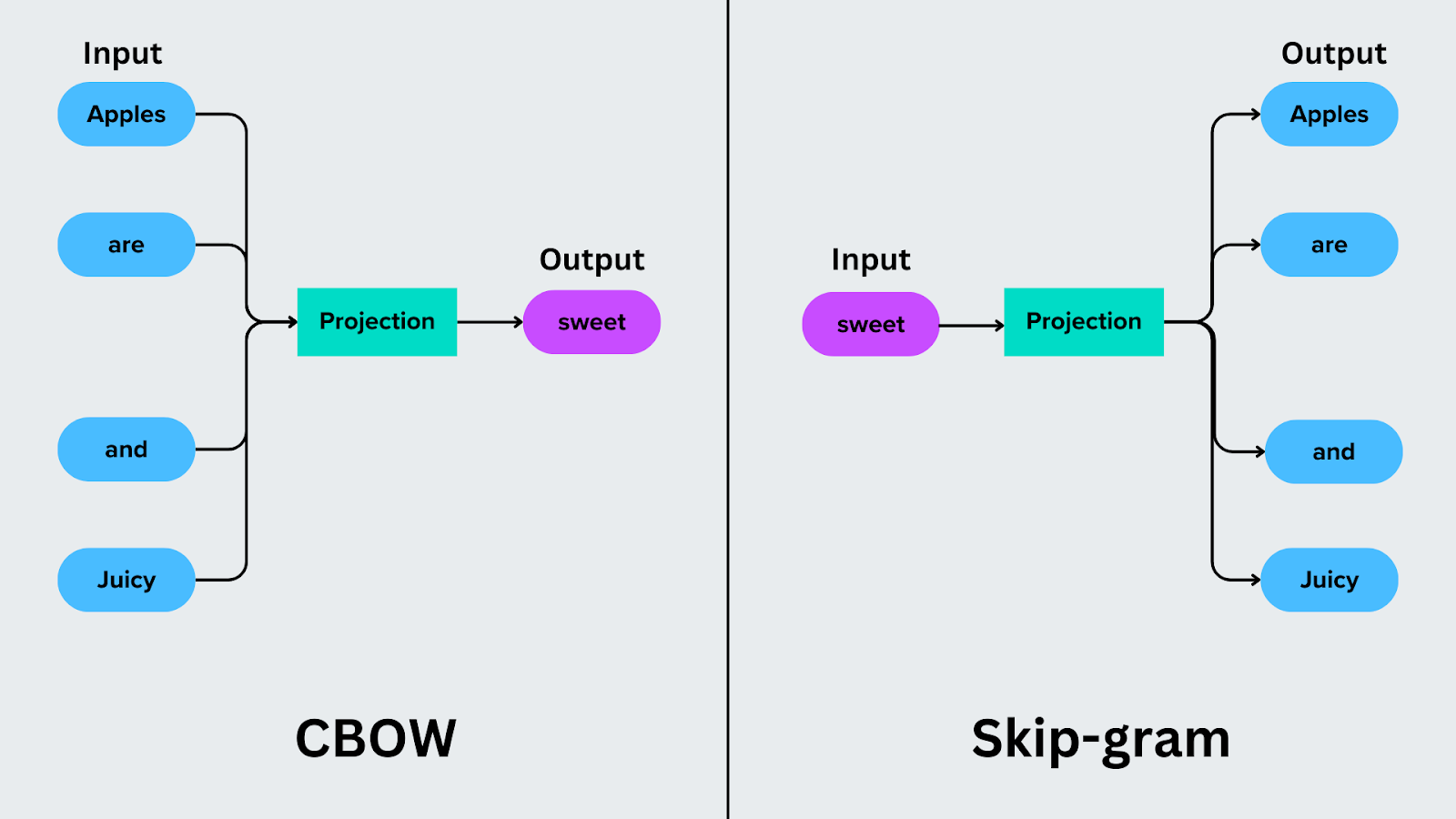 Abbildung- CBOW vs Skip-gram.png
Abbildung- CBOW vs Skip-gram.png
Abbildung: CBOW vs. Skip-gram
Unterschied zwischen CBOW und Skip-Gram Modell
Obwohl sowohl CBOW als auch Skip-Gram darauf abzielen, Wörter auf sinnvolle Weise darzustellen, unterscheiden sie sich in der Art und Weise, wie sie Wörter basierend auf dem Kontext verarbeiten und vorhersagen. Im Folgenden werden die Hauptunterschiede zwischen diesen beiden Ansätzen verglichen:
| Feature | Continuous Bag of Words (CBOW) | Skip-Gram |
|---|---|---|
| Zielsetzung | Bestimmt das Zielwort anhand des umgebenden Kontexts. | Prädiktiert Kontextwörter auf der Grundlage des Zielworts. |
| Effizienz | Schneller zu trainieren. | Langsamer zu trainieren. |
| Fokus | Arbeitet gut mit häufigen Wörtern. | Behandelt seltene Wörter effektiv. |
| Komplexität | Einfacher und rechnerisch effizient. | Komplexer und rechenintensiv. |
| Anwendungsfall | Geeignet für Aufgaben wie Wortvorhersage und Autokorrektur. | Ideal für spezialisierte Aufgaben wie Empfehlungssysteme. |
| Kontextfenster | Berücksichtigt den Durchschnitt aller Kontextwörter. | Einzelne Kontextwörter separat auswerten. |
| Anforderungen an die Datenmenge | Gute Leistung bei kleinen Datenmengen. | Bessere Leistung bei großen Datensätzen. |
| Beispiel | Sagt "Bellen" aus "Der Hund ist ___" voraus. | Sagt "der", "Hund" und "ist" aus "bellen" voraus. |
Tabelle: CBOW vs. Skip-Gram
Word2Vec-Implementierung in Python
Nachfolgend sehen Sie die Python-Implementierung von Word2Vec unter Verwendung der Methoden CBOW und Skip-Gram. Dieser Code trainiert auf einem kleinen benutzerdefinierten Datensatz, um Worteinbettungen zu lernen, und demonstriert, wie beide Methoden funktionieren, um Beziehungen zwischen Wörtern basierend auf ihrem Kontext zu erfassen. Beide Abschnitte des Codes wurden entwickelt, um zu vergleichen, wie CBOW und Skip-Gram die Beziehungen zwischen Wörtern auf unterschiedliche Weise lernen, aber sie haben die gleichen Parameter, um einen fairen Vergleich zu ermöglichen. Die Implementierung finden Sie unten in diesem [Kaggle notebook] (https://www.kaggle.com/code/fariba999/word2vec-implementation).
Code
from gensim.models import Word2Vec
# Kleiner, fokussierter Korpus
corpus = [
["Katze", "Hund", "bellte"],
["Hund", "gejagt", "Katze"],
["Katze", "saß", "Matte"],
["Hund", "lief", "schnell"],
["Katze", "rannte", "schnell"],
["Hund", "saß", "Matte"]
]
# Trainieren eines CBOW-Modells
cbow_model = Word2Vec(
sentences=corpus,
vector_size=10, # Kleinere Vektorgröße der Einfachheit halber
window=2, # Größe des Kontextfensters
min_count=1, # Alle Wörter einbeziehen
sg=0 # Setzt sg=0 für CBOW
)
# Trainieren eines Skip-Gram-Modells
skipgram_model = Word2Vec(
sentences=corpus,
vector_size=10, # Kleinere Vektorgröße der Einfachheit halber
window=2, # Größe des Kontextfensters
min_count=1, # Alle Wörter einbeziehen
sg=1 # Setzt sg=1 für Skip-Gram
)
# Funktion zur Anzeige von Wortvektoren und ähnlichen Wörtern
def display_model_results(model, model_name):
print(f"\n--- {model_name} ---")
for word in ["Katze", "Hund"]:
print(f "Word Vector for '{word}': {model.wv[word][:5]}...") # Anzeige der ersten 5 Werte des Vektors
similar_words = model.wv.most_similar(wort, topn=3)
print(f "Am ähnlichsten zu '{Wort}': {[(w, round(sim, 2)) for w, sim in similar_words]}")
# Anzeige der CBOW-Modellergebnisse
display_model_results(cbow_model, "CBOW-Modell")
# Anzeige der Ergebnisse des Skip-Gram-Modells
display_model_results(skipgram_model, "Skip-Gram Modell")
Ausgabe:
--- CBOW Modell ---
Wortvektor für 'Katze': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Am ähnlichsten zu 'Katze': [('dog', 0.54), ('fast', 0.33), ('barked', 0.23)] Wortvektor für 'dog': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Am ähnlichsten zu 'dog': [('cat', 0.54), ('fast', 0.3), ('ran', 0.1)]
--- Skip-Gram Modell ---
Wortvektor für 'cat': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Am ähnlichsten zu 'Katze': [('dog', 0.54), ('fast', 0.33), ('barked', 0.23)] Wortvektor für 'dog': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Am ähnlichsten zu 'dog': [('cat', 0.54), ('fast', 0.3), ('ran', 0.1)]
Im CBOW-Teil des Codes:
Das Modell wird mit dem Parameter sg=0 trainiert, der Word2Vec anweist, die Methode Continuous Bag of Words zu verwenden.
CBOW bestimmt ein Wort anhand des Kontexts der umliegenden Wörter. In dem Satz ["Hund", "gejagt", "Katze"] könnte das Modell zum Beispiel "Hund" und "Katze" verwenden, um "gejagt" vorherzusagen.
Mit vector_size=10 wird die Größe der Worteinbettungen festgelegt (wie viele Zahlen jedes Wort repräsentieren).
window=2 legt das context window fest, d.h. es werden bis zu 2 Wörter vor und nach dem Zielwort berücksichtigt.
Im Skip-Gram-Teil des Codes:
Das Modell wird mit dem Parameter sg=1 trainiert, der Word2Vec auf die Skip-Gram-Methode umstellt.
Bei der Skip-Gram-Methode werden umliegende Wörter anhand eines bestimmten Zielworts identifiziert. Wenn das Zielwort zum Beispiel "gejagt" ist, sagt das Modell "Hund" und "Katze" als seine Nachbarn voraus.
Ähnlich wie bei CBOW:
vector_size=10 legt die Größe der Worteinbettungen fest.
window=2 legt den Bereich der zu berücksichtigenden Kontextwörter fest.
Vorteile von Word2Vec
Im Folgenden werden einige wichtige Vorteile aufgeführt, die Word2Vec zu einer grundlegenden Technik im NLP machen:
Erfasst semantische Zusammenhänge: Word2Vec erzeugt Einbettungen, bei denen semantisch ähnliche Wörter (z.B. "König" und "Königin") im Vektorraum nahe beieinander liegen, um diese Beziehungen in NLP-Aufgaben zu analysieren und zu nutzen.
Kontextuelles Verstehen: Durch die Analyse des gemeinsamen Vorkommens von Wörtern in großen Korpora erfasst Word2Vec kontextabhängige Beziehungen, die es den Modellen ermöglichen, die Bedeutung von Wörtern in bestimmten Kontexten besser zu verstehen.
Effiziente Repräsentation: Worteinbettungen sind dicht und niedrigdimensional im Vergleich zu spärlichen Repräsentationen wie der One-Hot-Codierung, was sie zu einer effizienten Technik in Bezug auf Speicher- und Rechenkosten macht.
Verarbeitet große Vokabularien: Im Gegensatz zu älteren Techniken lässt sich Word2Vec effektiv auf große Datensätze und Vokabulare skalieren, was es für reale Anwendungen praktisch macht.
Unterstützt Transfer Learning: Vorgefertigte Word2Vec-Einbettungen können für mehrere Aufgaben wiederverwendet werden, was Zeit und Rechenressourcen spart und die Ergebnisse verbessert.
Arithmetik auf Wörtern: Word2Vec unterstützt sinnvolle Vektorarithmetik, so dass Analogien wie "König - Mann + Frau = Königin" direkt mit Einbettungen berechnet werden können.
Anwendungsfälle von Word2Vec
Word2Vec hat eine breite Palette von Anwendungen für NLP-Aufgaben. Im Folgenden werden einige praktische und wirkungsvolle Anwendungsfälle vorgestellt:
Maschinelle Übersetzung: Verbessert die Zuordnung von Wörtern zwischen Sprachen durch die Verwendung von Einbettungen, um Wörter mit ähnlichen Bedeutungen auszurichten und so die Übersetzungsgenauigkeit zu erhöhen.
Gefühlsanalyse: Identifiziert den Ton eines Textes durch die Analyse von Wortbeziehungen und Kontext, um positive, negative oder neutrale Stimmungen zu klassifizieren.
Such-Ranking: Verbessert Suchmaschinen durch das Verständnis der Ähnlichkeit zwischen Suchanfragen und indizierten Inhalten, was zu relevanteren Ergebnissen führt.
Produktempfehlungen: Bringt Benutzerpräferenzen mit Produkten oder Dienstleistungen zusammen, indem es Textbeschreibungen analysiert und ähnliche Artikel findet.
Topic Modeling: Organisiert und analysiert große Textdatensätze durch Gruppierung von Dokumenten in Clustern auf der Grundlage der Ähnlichkeit von Worteinbettungen.
Autovervollständigung von Texten: Schlägt relevante Wörter oder Phrasen vor, indem es kontextuell ähnliche Wörter vorhersagt und so die Benutzererfahrung bei der Eingabe oder bei Codierungswerkzeugen verbessert.
Chatbots: Ermöglicht ein besseres Verständnis der Benutzereingaben und des Kontexts und hilft Chatbots dabei, genaue und relevante Antworten zu generieren.
Einschränkungen von Word2Vec
Trotz seiner Vorteile hat Word2Vec auch seine Grenzen:
Mangel an Kontextbewusstsein: Word2Vec erzeugt eine einzige Einbettung für jedes Wort, unabhängig von seinem Kontext. Zum Beispiel wird das Wort "Bank" die gleiche Vektordarstellung haben, egal ob es sich auf ein Flussufer oder ein Finanzinstitut bezieht.
Datenabhängigkeit: Für ein effektives Training sind große, qualitativ hochwertige Textdatensätze erforderlich. Unzureichend kuratierte oder kleine Datensätze können zu suboptimalen Einbettungen führen.
Handhabung seltener Wörter: Probleme mit seltenen Wörtern oder Begriffen, die nicht im Vokabular enthalten sind, da diese in den Trainingsdaten möglicherweise nicht ausreichend vorkommen, um sinnvolle Einbettungen zu erzeugen.
Keine Repräsentation auf Satzebene: Word2Vec konzentriert sich auf Einbettungen auf Wortebene und stellt keine Repräsentationen für ganze Sätze oder Dokumente zur Verfügung, was seinen Anwendungsbereich auf spezifische NLP-Aufgaben beschränkt.
Ignoriert die Wortreihenfolge: Das Modell berücksichtigt Wörter innerhalb eines Kontextfensters, aber nicht ihre Reihenfolge, was das Verständnis von Grammatik oder Satzstruktur beeinträchtigen kann.
Veraltet im Vergleich zu modernen Modellen: Word2Vec wurde größtenteils durch fortschrittliche Modelle wie BERT, GLoVE und GPT ersetzt, die kontextbezogene und robustere Einbettungen bieten.
Überbrückung der Lücke: Von Word2Vec zu GloVe, BERT, und GPT
Vorhersagemodelle wie Word2Vec erstellen Worteinbettungen, indem sie sich mit Hilfe neuronaler Netze auf den lokalen Kontext konzentrieren. Ihre Abhängigkeit von nahegelegenen Wortpaaren bringt jedoch eine Einschränkung mit sich: Sie versäumen es, umfassendere, globale Beziehungen in einem gesamten Textkorpus zu erfassen. So ist Word2Vec zwar hervorragend in der Lage, Wortassoziationen in der Nähe zu erkennen, verpasst aber oft umfassendere semantische Verbindungen.
Um hier Abhilfe zu schaffen, verwendet GloVe (Global Vectors for Word Representation) globale Co-Occurrence-Statistiken, um Worteinbettungen zu erstellen. Es wird analysiert, wie oft Wörter im gesamten Korpus zusammen vorkommen, um sowohl den lokalen Kontext als auch umfassendere semantische Beziehungen zu erfassen und so eine vollständigere Darstellung der Sprache zu erhalten.
In jüngerer Zeit sind Modelle wie BERT (Bidirectional Encoder Representations from Transformers) und GPT (Generative Pre-trained Transformer) über statische Einbettungen hinausgegangen. BERT führte kontextuelle Einbettungen ein, die Wörter je nach ihrer Verwendung in einem Satz unterschiedlich darstellen, während GPT sich darauf konzentrierte, kohärenten Text durch das Verständnis des sequenziellen Kontexts zu erzeugen. Diese Modelle haben NLP weiter verändert, indem sie dynamische, kontextabhängige Darstellungen einführten und die Grenzen früherer Methoden wie Word2Vec und GloVe aufhoben.
Word2Vec mit Milvus: Effiziente Vektorsuche für NLP-Anwendungen
Word2Vec bietet eine Möglichkeit, Worteinbettungen zu erstellen, die für Aufgaben wie [semantische Suche] (https://zilliz.com/glossary/semantic-search), Dokumentenähnlichkeit und Empfehlungssysteme, bei denen das Verständnis von Wortbeziehungen entscheidend ist, unerlässlich sind. Es kann jedoch eine Herausforderung sein, umfangreiche Sammlungen von Einbettungen effizient zu verwalten und abzufragen.
Hier setzt Milvus, die von Zilliz entwickelte Open-Source-Vektordatenbank, an. Milvus bietet eine robuste Lösung für die Speicherung, Indizierung und Abfrage von Word2Vec-Einbettungen oder jeder anderen Art von Einbettungen in großem Umfang für eine nahtlose Integration in NLP-Workflows. Hier sehen Sie, wie Word2Vec und Milvus zusammenarbeiten:
Effizientes Management von Worteinbettungen: Word2Vec generiert hochdimensionale Einbettungen für Vokabeln, die bei größeren Datensätzen erheblich an Größe zunehmen können. Milvus verwaltet diese Einbettungen effizient durch:
Skalierbarer Speicher: Speicherung von Millionen von Worteinbettungen ohne Leistungseinbußen.
Schneller Abruf: Optimierte Algorithmen gewährleisten eine schnelle Suche nach ähnlichen Einbettungen, die für Echtzeit-NLP-Anwendungen wie Empfehlungssysteme oder Chatbots entscheidend sind.
Erweiterte semantische Suche: Word2Vec-Einbettungen zeichnen sich durch die Erfassung von Wortbeziehungen aus. In Kombination mit Milvus können diese Einbettungen eine erweiterte semantische Suche ermöglichen. Zum Beispiel:
Die Suche nach Synonymen oder verwandten Begriffen (z. B. die Suche nach "König" ergibt Einbettungen wie "Königin" oder "Prinz").
Implementierung von robusten Suchsystemen wie [Retrieval Augmented Generation (RAG)] (https://zilliz.com/learn/Retrieval-Augmented-Generation), die auf Wortähnlichkeit beruhen, um bessere Ergebnisse zu erzielen.
Stromlinienförmige NLP-Workflows: Milvus vereinfacht NLP-Workflows mit Word2Vec durch:
Vorgefertigte Word2Vec-Embeddings können gespeichert und effizient abgefragt werden.
Unterstützung der Integration mit Frameworks für maschinelles Lernen für Clustering, Dokumentenähnlichkeit und Echtzeitsuche.
Schlussfolgerung
Word2Vec hat die Art und Weise, wie wir mit Sprachdaten arbeiten, durch die Einführung von Worteinbettungen, die die Bedeutungen und Beziehungen von Wörtern erfassen, verändert. Es löste viele Probleme herkömmlicher Methoden, wie die Unfähigkeit, semantische und syntaktische Ähnlichkeiten zu erfassen. Es wird in Anwendungen wie Stimmungsanalyse, Übersetzung und Empfehlungssystemen eingesetzt. Trotz seiner Einschränkungen hat Word2Vec den Grundstein für viele Fortschritte in diesem Bereich gelegt und die Entwicklung von anspruchsvolleren Modellen wie GLoVE, BERT und GPT beeinflusst.
FAQs zu Word2Vec
- Was ist Word2Vec und warum ist es wichtig?
Word2Vec ist ein maschinelles Lernmodell, das dichte Vektordarstellungen von Wörtern, so genannte Worteinbettungen, auf der Grundlage ihres Kontexts erstellt. Es ist wichtig, weil es die Beziehungen und Bedeutungen von Wörtern für NLP-Aufgaben wie Stimmungsanalyse, Übersetzung und Suche erfasst.
- Wie unterscheidet sich Word2Vec von traditionellen Wortrepräsentationsmethoden?
Im Gegensatz zu traditionellen Methoden wie der One-Hot-Codierung, die Wörter als spärliche Vektoren ohne inhärente Beziehungen darstellen, erzeugt Word2Vec dichte Einbettungen, die semantische und syntaktische Ähnlichkeiten zwischen Wörtern erfassen, was es viel effizienter und aussagekräftiger macht.
- Welche sind die wichtigsten Architekturen, die in Word2Vec verwendet werden?
Word2Vec hat zwei Hauptarchitekturen: Continuous Bag of Words (CBOW) und Skip-Gram. CBOW bestimmt ein Zielwort aus dem umgebenden Kontext, während Skip-Gram Kontextwörter anhand eines gegebenen Zielwortes identifiziert. Jede hat ihre Stärken, je nach Anwendungsfall und Datensatz.
- Was sind die wichtigsten Anwendungsfälle für Word2Vec?
Word2Vec wird in Anwendungen wie Sentimentanalyse, maschinelle Übersetzung, Empfehlungssysteme, Suchranking, Themenmodellierung und Chatbot-Entwicklung eingesetzt. Seine Fähigkeit, Wortbeziehungen zu verstehen, macht es vielseitig für verschiedene NLP-Aufgaben einsetzbar.
- Was sind die Grenzen von Word2Vec?
Word2Vec hat mehrere Einschränkungen, darunter das fehlende Kontextbewusstsein (z. B. unterscheidet es nicht zwischen verschiedenen Bedeutungen desselben Wortes), die Abhängigkeit von großen Datensätzen für das Training und die Unfähigkeit, die Wortfolge oder die Bedeutung auf Satzebene zu erfassen. Diese Nachteile haben zur Entwicklung von fortschrittlicheren Modellen wie GloVe, BERT und GPT geführt.
Verwandte Ressourcen
Die 10 wichtigsten NLP-Techniken, die jeder Datenwissenschaftler kennen sollte](https://zilliz.com/learn/top-10-nlp-techniques-every-data-scientist-should-know)
Die 10 besten Tools und Plattformen für natürliche Sprachverarbeitung](https://zilliz.com/learn/top-10-natural-language-processing-tools-and-platforms)
Training Ihres eigenen Text-Einbettungsmodells](https://zilliz.com/learn/training-your-own-text-embedding-model)
20 beliebte offene Datensätze für die Verarbeitung natürlicher Sprache](https://zilliz.com/learn/popular-datasets-for-natural-language-processing)
Die Macht der natürlichen Sprachverarbeitung enthüllen: Die 10 wichtigsten Anwendungen aus der Praxis](https://zilliz.com/learn/top-5-nlp-applications)
GloVe: Ein Algorithmus für maschinelles Lernen zur Entschlüsselung von Wortverbindungen](https://zilliz.com/glossary/glove)
- Was ist Word2Vec?
- Warum brauchen wir Word2Vec?
- Wie funktioniert Word2Vec?
- Word2Vec-Implementierung in Python
- Vorteile von Word2Vec
- Anwendungsfälle von Word2Vec
- Einschränkungen von Word2Vec
- Überbrückung der Lücke: Von Word2Vec zu GloVe, BERT, und GPT
- Word2Vec mit Milvus: Effiziente Vektorsuche für NLP-Anwendungen
- Schlussfolgerung
- FAQs zu Word2Vec
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren