




RAG-Bewertung mit Ragas
*Dieser Beitrag wurde von Christy Bergman, Shahul Es und Jithin James verfasst.
Retrieval ist eine entscheidende Komponente von generativen KI-Systemen, und seine Herausforderungen sind besonders offensichtlich in Retrieval Augmented Generation (RAG). Retrieval Augmented Generation verbessert KI-gestützte Chatbots durch die Generierung von Antworten auf der Grundlage umfangreicher Daten, für die große Sprachmodelle (LLM trainiert wurden. Trotz der Ausgereiftheit von RAG-Systemen bleibt die Abfragegenauigkeit eine große Hürde, wie die niedrigen Ergebnisse von Benchmarks wie WikiEval zeigen. Um diese Herausforderungen zu überwinden, ist es wichtig, einen umfassenden Bewertungsrahmen zu schaffen und gründliche Experimente durchzuführen, um die RAG-Parameter fein abzustimmen und eine optimale Leistung zu erzielen.
**Bevor man jedoch mit RAG experimentieren kann, braucht man einen Weg, um auszuwerten, welche Experimente die besten Ergebnisse erzielt haben.
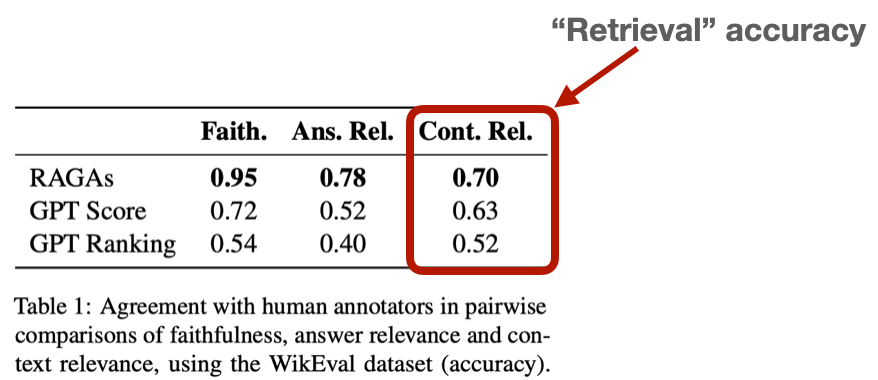
Bildquelle: https://arxiv.org/abs/2309.15217
Was sind Ragas?
Ragas ist ein spezieller Evaluierungsrahmen, der für die Bewertung der Leistung von Retrieval Augmented Generation (RAG) Systemen entwickelt wurde. Es bietet einen strukturierten Ansatz, um die Effektivität von RAG-Implementierungen zu bewerten, indem fortschrittliche Large Language Models (LLMs) als Beurteiler eingesetzt werden. Ragas konzentriert sich auf die Automatisierung des Bewertungsprozesses und bietet skalierbare und kostengünstige Lösungen für die Bewertung von KI-generierten Antworten. Das Framework zielt darauf ab, Verzerrungen zu beseitigen und kontinuierliche, erklärbare Bewertungen für natürliche Sprachausgaben anzubieten. Ragas vereinfacht die Bewertung komplexer RAG-Systeme, indem es intuitive Metriken bereitstellt und den Prozess der Bewertung der Abfragequalität rationalisiert.
Bedeutung der Bewertung von RAG-Systemen
Die effektive Evaluierung von RAG-Systemen ist für die Verfeinerung von KI-Antworten unerlässlich. Ein robuster Evaluierungsrahmen stellt sicher, dass die Experimente zuverlässige Ergebnisse liefern und dass die KI genaue und kontextgerechte Antworten liefert. Die Automatisierung des Evaluierungsprozesses kann diese Aufgabe rationalisieren und beschleunigen und macht sie kostengünstiger und skalierbar.
Nutzung von LLMs als Juroren
Die Verwendung von Large Language Models (LLMs) wie GPT-4 für die [Evaluierung] (https://arxiv.org/pdf/2306.05685) hat aufgrund ihrer Fähigkeit, verschiedene Aspekte der Retrievalqualität, einschließlich Relevanz und Präzision, zu bewerten, an Bedeutung gewonnen. Obwohl es ungewöhnlich erscheinen mag, ein LLM ein anderes bewerten zu lassen, zeigen Untersuchungen, dass GPT-4 in etwa 80% der Zeit mit menschlichen Bewertungen übereinstimmt, was der "Bayes'schen Grenze " der menschlichen Übereinstimmung entspricht. Diese Methode automatisiert den Evaluierungsprozess, bietet Skalierbarkeit und senkt die Kosten im Vergleich zu manueller menschlicher Beschriftung.
Ansätze zur LLM-basierten Evaluierung
Es gibt zwei Hauptansätze für die Verwendung von LLMs als Richter für die [RAG-Evaluation] (https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications):
MT-Bench verwendet ein LLM, um nur Frage-Antwort-Paare zu bewerten, die als menschliche Grundwahrheit verifiziert sind. Der Mensch prüft zunächst die Fragen und Antworten, um sicherzustellen, dass die Fragen ausreichend komplex sind, um würdige Tests durchzuführen, bevor der LLM die 80 Frage-Antwort-Paare verwendet, um verschiedene Decoder (generative KI-Komponenten) zu bewerten. [Papier, Code, Rangliste] (https://huggingface.co/spaces/lmsys/mt-bench).
Ragas basiert auf der Idee, dass LLMs natürliche Sprachausgaben effektiv bewerten können, indem sie Paradigmen bilden, die die Voreingenommenheit der LLMs als Richter überwinden und kontinuierliche Bewertungen liefern, die erklärbar und intuitiv zu verstehen sind). Paper, Code, Docs.
Im weiteren Verlauf dieses Blogs wird Ragas vorgestellt, das den Schwerpunkt auf Automatisierung und Skalierbarkeit für RAG-Bewertungen legt.
Benötigte Evaluationsdaten für Ragas
Gemäß der [Ragas-Dokumentation] (https://docs.ragas.io/en/stable/howtos/applications/data_preparation.html) benötigt Ihre RAG-Pipeline-Evaluierung vier wichtige Datenpunkte.
Frage: Die gestellte Frage.
Kontexte: Textabschnitte aus Ihren Daten, die der Bedeutung der Frage am besten entsprechen.
Antwort: Die von Ihrem RAG-Chatbot generierte Antwort auf die Frage.
Wahrheitsgemäße Antwort: Erwartete Antwort auf die Frage.
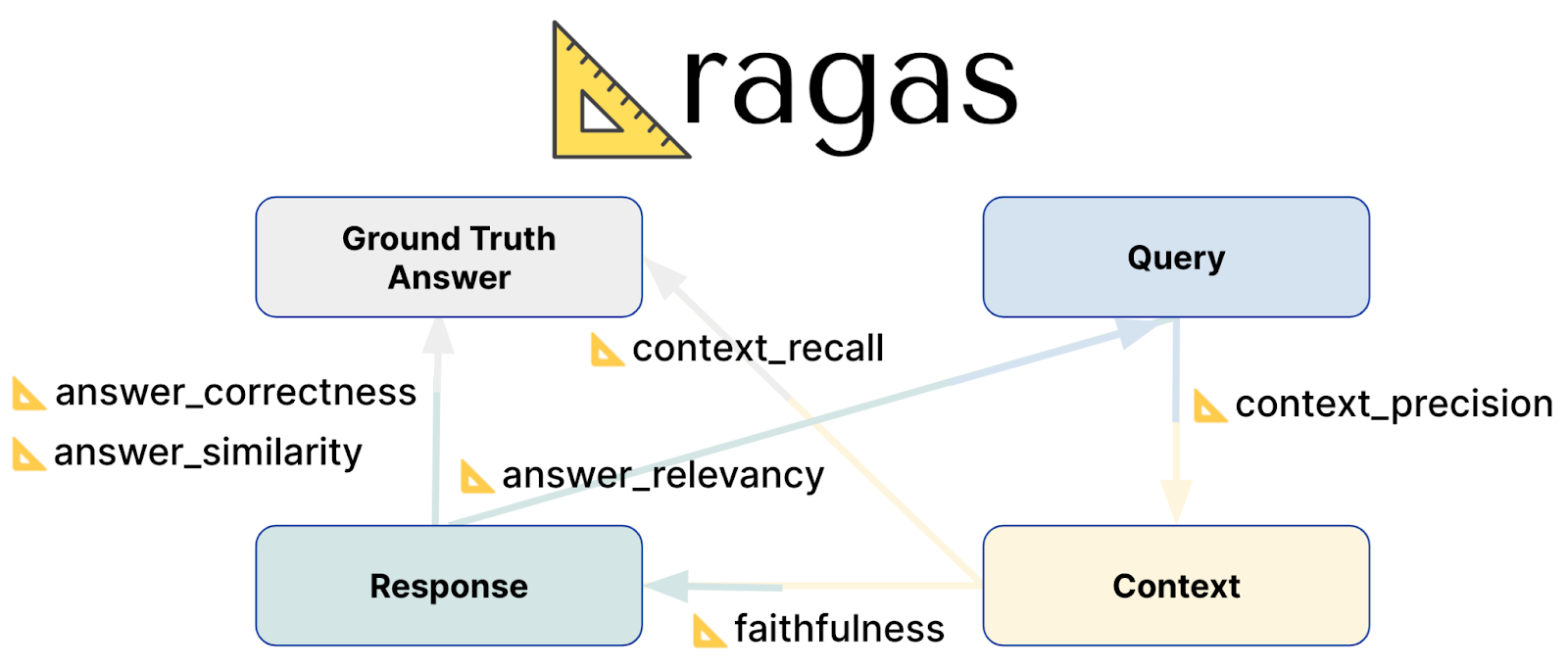 Ragas Bewertungsmetrik
Ragas Bewertungsmetrik
Wichtige Bewertungsmetriken
In der Dokumentation finden Sie Erklärungen zu den einzelnen Bewertungsmaßstäben, einschließlich der ihnen zugrunde liegenden Formeln. Zum Beispiel, Treue. Ragas bietet eine Reihe von Bewertungskennzahlen, um die Effektivität von RAG-Systemen zu beurteilen:
- Glaubwürdigkeit: Diese Punktzahl bewertet, wie genau die generierte Antwort die Informationen im angegebenen Kontext wiedergibt. Er misst die sachliche Richtigkeit der Antwort und stellt sicher, dass sie mit dem Kontext übereinstimmt, aus dem sie abgeleitet wurde. Die Punktzahl reicht von 0 bis 1, wobei höhere Werte eine größere Genauigkeit und Konsistenz anzeigen.
Antwortrelevanz: Mit dieser Metrik zur Relevanz der Antwort wird bewertet, wie gut die generierte Antwort auf die Aufforderung reagiert. Sie konzentriert sich auf die Vollständigkeit und Relevanz der Antwort und benachteiligt unvollständige oder redundante Antworten. Der Relevanzwert wird aus der Frage, dem Kontext und der Antwort abgeleitet, wobei höhere Werte eine bessere Übereinstimmung mit der Aufforderung widerspiegeln.
Kontextabruf: Der Context Recall misst, wie gut der abgerufene Kontext mit der wahren Antwort übereinstimmt. Er berechnet den Anteil der relevanten Teile, die erfolgreich abgerufen wurden, im Vergleich zu dem, was erwartet wurde. Die Werte reichen von 0 bis 1, wobei höhere Werte anzeigen, dass ein größerer Teil des relevanten Kontexts abgerufen wurde.
Kontextgenauigkeit: Mit dieser Metrik wird bewertet, ob die relevantesten Kontextelemente höher eingestuft werden als weniger relevante. Es wird geprüft, ob alle relevanten Kontextteile an der Spitze der Liste erscheinen. Die Kontextpräzision wird anhand der Frage, der Grundwahrheit und der Kontexte ermittelt, wobei höhere Werte eine bessere Einstufung der relevanten Informationen anzeigen.
Kontextrelevanz: Dieser Wert für die Kontextrelevanz bewertet, wie relevant der abgerufene Kontext für die Frage ist. Er misst das Ausmaß, in dem der Kontext mit der Absicht der Anfrage übereinstimmt. Die Metrik reicht von 0 bis 1, wobei höhere Werte anzeigen, dass der Kontext für die Frage relevanter ist.
Context Entity Recall: Mit dieser Metrik wird berechnet, wie gut der abgerufene Kontext die in der Basiswahrheit erwähnten Entitäten erfasst. Sie misst den Anteil der Entitäten, die sowohl im Kontext als auch in der Grundwahrheit gefunden wurden, im Verhältnis zur Gesamtzahl der Entitäten in der Grundwahrheit. Höhere Punktzahlen bedeuten eine bessere Erfassung wichtiger Entitäten im Kontext.
Einzelheiten zur Berechnung dieser Metriken finden Sie in ihrem [Papier] (https://arxiv.org/abs/2309.15217).
RAG Evaluation Code Beispiel
Dieser Evaluierungscode setzt voraus, dass Sie bereits eine RAG-Demo haben. Für meine Demo habe ich einen RAG-Chatbot erstellt, der die Milvus Technische Dokumentation und die Milvus Vektordatenbank für den Abruf verwendet. Den vollständigen Code für meine Demo RAG notebook und Eval notebooks finden Sie auf GitHub.
Unter Verwendung dieser RAG-Demo habe ich ihr Fragen gestellt, die RAG-Kontexte von Milvus erhalten und Bot-Antworten von einem LLM generiert (siehe die letzten beiden Spalten unten). Zusätzlich habe ich "Ground-Truth"-Antworten auf dieselben Fragen bereitgestellt (Spalte "Kontexte" unten).
Sie müssen OpenAI, (HuggingFace) dataset, ragas, langchain und pandas installieren.
# ! pip install openai dataset ragas langchain pandas
importiere pandas als pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

Konvertiert den Pandas Dataframe in einen HuggingFace Dataset.
from datasets import Dataset
def assemble_ragas_dataset(input_df):
question_list, truth_list, context_list = [], [], []
frage_liste = input_df.Frage.to_list()
wahrheits_liste = eval_df.ground_truth_answer.to_list()
kontext_liste = input_df.Custom_RAG_context.to_list()
kontext_liste = [[kontext] for kontext in kontext_liste]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# Erstellen Sie einen HuggingFace-Datensatz aus den Grundwahrheitslisten.
ragas_ds = Dataset.from_dict({"Frage": question_list,
"Kontexte": kontext_liste,
"Antwort": rag_answer_list,
"ground_truth": truth_list
})
return ragas_ds
# Erstellen eines Ragas HuggingFace-Datensatzes aus dem Pandas df.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

Das Standard-LLM-Modell, das Ragas verwendet, ist OpenAIs gpt-3.5-turbo-16k und das Standard-Einbettungsmodell ist text-embedding-ada-002. Sie können beide Modelle ändern, wie Sie möchten.
Ich ändere das LLM-als-Richter Modell in das gepinnte gpt-3.5-turbo, da OpenAIs letzter Blog ankündigte, dass dies das billigste ist. Ich habe auch das Einbettungsmodell zu text-embedding-3-small geändert, da im Blog erwähnt wurde, dass diese neuen Einbettungen den Kompressionsmodus unterstützen.
Im folgenden Code verwende ich nur die RAG-Kontext-Bewertungsmetrik, um mich auf die Messung der Retrieval-Qualität der relevanten Dokumente zu konzentrieren.
os, openai, pprint importieren
von openai importieren OpenAI
# Den Api-Schlüssel in einer env-Variablen speichern.
openai_api_key=os.environ['OPENAI_API_KEY']
# Wählen Sie die Metriken, die Sie sehen wollen.
from ragas.metrics import ( context_recall, context_precision, faithfulness, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# Ändern Sie die llm-as-critic.
from ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=LLM_NAME)
# Ändern Sie auch die Einbettungen.
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Ändern Sie die Standardmodelle, die für jede Metrik verwendet werden.
for metric in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Evaluieren Sie den Datensatz.
from ragas import evaluate
ragas_result = evaluate( ragas_input_ds,
metrics=[ context_precision, context_recall, faithfulness, ],
llm=ragas_llm,
)
# Auswertungen anzeigen.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

Sie können den vollständigen Code für meine Demo RAG notebook und Eval notebooks auf GitHub sehen.
Schlussfolgerung
Dieser Blog befasste sich mit den aktuellen Herausforderungen des Retrievals in der generativen KI, mit besonderem Schwerpunkt auf Retrieval Augmented Generation (RAG) Techniken für die Weiterentwicklung natürlichsprachlicher KI-Systeme. Effektive Experimente sind für die Optimierung von RAG-Parametern zur Anpassung an spezifische Daten und Anwendungsfälle unerlässlich, um die beste Leistung zu gewährleisten. Die Evaluierung von RAG-Systemen kann nun durch die Automatisierung mit LLMs als Evaluatoren erheblich verbessert werden. Wir haben die wichtigsten RAG-Evaluierungsmetriken und ihre Berechnungsmethoden behandelt und Einblicke in ihre praktischen Anwendungen gegeben. Darüber hinaus wurde ein Implementierungsbeispiel unter Verwendung der Milvus-Vektordatenbank zusammen mit dem Ragas-Paket hervorgehoben, um zu zeigen, wie diese Werkzeuge effektiv zur Verbesserung und Skalierung Ihres RAG-Evaluierungsrahmens eingesetzt werden können. Dieser Ansatz rationalisiert nicht nur den Evaluierungsprozess, sondern steigert auch die Gesamteffektivität der Kontextsuche in KI-gesteuerten Lösungen. Für weitere Untersuchungen sollten Sie reale Anwendungen untersuchen, Herausforderungen angehen, zukünftige Richtungen erforschen, sich an bewährte Verfahren halten und auf zusätzliche Ressourcen zugreifen, um Ihr Verständnis für die Bewertung von RAG-Systemen zu vertiefen und Ihre RAG-Pipeline zu verfeinern.

Weiterlesen

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.