




Ähnlichkeitsmetriken für die Vektorsuche
Vektorähnlichkeitsmetriken für die Suche - Zilliz Blog
Man kann nicht Äpfel mit Birnen vergleichen. Oder doch? Mit Vektordatenbanken wie Milvus können Sie jede Daten, die Sie vektorisieren können vergleichen. Sie können dies sogar direkt in Ihrem Jupyter Notebook tun. Aber wie funktioniert die Vektorähnlichkeitssuche?
Die Vektorsuche hat zwei entscheidende konzeptionelle Komponenten: Indizes und Abstandsmetriken. Einige beliebte Vektorindizes sind HNSW, IVF und ScaNN. Es gibt drei primäre Abstandsmetriken: L2 oder euklidischer Abstand, Kosinus-Ähnlichkeit und inneres Produkt. Der Manhattan-Abstand berechnet den Abstand zwischen Punkten durch Summierung der absoluten Differenzen in jeder Dimension und ist in Szenarien von Vorteil, in denen die Empfindlichkeit gegenüber Ausreißern minimiert werden muss. Andere Metriken für binäre Vektoren sind die Hamming-Distanz und der Jaccard-Index.
In diesem Artikel werden wir uns mit folgenden Themen befassen:
Vektorähnlichkeitsmetriken
L2 oder Euklidisch
Wie funktioniert der L2-Abstand?
Wann sollten Sie den euklidischen Abstand verwenden?
Kosinusähnlichkeit
Wie funktioniert die Kosinusähnlichkeit?
Wann sollten Sie die Cosinus-Ähnlichkeit verwenden?
Inneres Produkt
Wie funktioniert das innere Produkt?
Wann sollten Sie das Innere Produkt verwenden?
Andere interessante Vektorähnlichkeits- oder Abstandsmetriken
Hamming-Distanz
Jaccard-Index
Zusammenfassung der Metriken für die Vektorähnlichkeitssuche
Vektoren können als Listen von Zahlen oder als eine Orientierung und ein Betrag dargestellt werden. Am einfachsten ist es, sich Vektoren als Liniensegmente vorzustellen, die in bestimmte Richtungen im Raum zeigen.
Die L2 oder euklidische Metrik ist die "Hypotenusen"-Metrik zweier Vektoren. Sie misst die Größe des Abstands zwischen den Endpunkten der Linien Ihrer Vektoren.
Die Kosinusähnlichkeit ist der Winkel zwischen den Linien, in dem sie sich treffen.
- Das innere Produkt** ist die "Projektion" eines Vektors auf den anderen. Intuitiv misst es sowohl den Abstand als auch den Winkel zwischen den Vektoren.
Die intuitivste Abstandsmetrik ist L2 oder der euklidische Abstand. Wir können uns dies als die Menge an Raum zwischen zwei Objekten vorstellen. Zum Beispiel, wie weit Ihr Bildschirm von Ihrem Gesicht entfernt ist.
Wir haben uns also vorgestellt, wie der L2-Abstand im Raum funktioniert; wie funktioniert er in der Mathematik? Stellen wir uns zunächst beide Vektoren als eine Liste von Zahlen vor. Legen Sie die Listen übereinander und subtrahieren Sie von oben nach unten. Dann quadrieren Sie alle Ergebnisse und addieren sie. Zum Schluss ziehst du die Quadratwurzel.
Milvus überspringt die Quadratwurzel, da die Rangfolge der Quadratwurzel und der nicht-quadratischen Wurzel gleich ist. Auf diese Weise können wir eine Operation überspringen und erhalten das gleiche Ergebnis, was die Latenzzeit und die Kosten senkt und den Durchsatz erhöht. Nachfolgend ein Beispiel für die Funktionsweise der euklidischen oder L2-Distanz.
d(Dame, König) = √(0.3-0.5)2 + (0.9-0.7)2
= √(0.2)2 + (0.2)2
= √0.04 + 0.04
= √0.08 ≅ 0.28
Einer der Hauptgründe für die Verwendung des euklidischen Abstands ist, wenn Ihre Vektoren unterschiedliche Größen haben. Sie interessieren sich in erster Linie dafür, wie weit Ihre Wörter im Raum oder semantisch voneinander entfernt sind.
Wir verwenden den Begriff "Kosinusähnlichkeit" oder "Kosinusabstand", um den Unterschied zwischen der Ausrichtung zweier Vektoren zu bezeichnen. Wie weit würden Sie sich zum Beispiel drehen, um zur Haustür zu schauen?
Spaßige und anwendbare Tatsache: Obwohl "Ähnlichkeit" und "Abstand" für sich genommen unterschiedliche Bedeutungen haben, bedeutet die Hinzufügung des Kosinus vor beiden Begriffen fast das Gleiche! Dies ist ein weiteres Beispiel für die [semantische Ähnlichkeit] (https://zilliz.com/glossary/semantic-similarity) im Spiel.
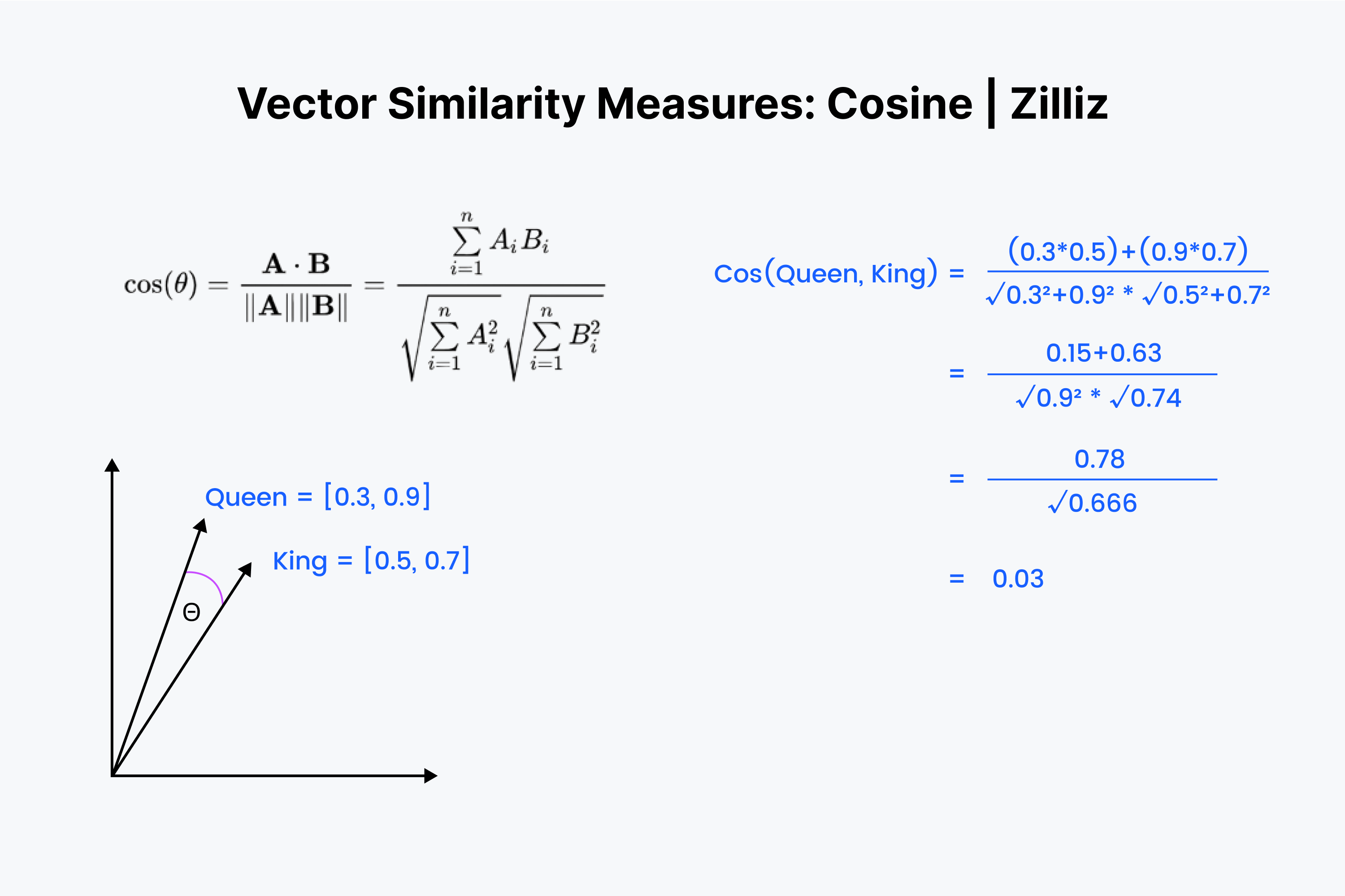
Wir wissen also, dass die Kosinusähnlichkeit den Winkel zwischen zwei Vektoren misst. Auch hier stellen wir uns unsere Vektoren als eine Liste von Zahlen vor. Diesmal ist der Prozess allerdings etwas komplexer.
Wir beginnen damit, die Vektoren wieder übereinander zu legen. Multiplizieren Sie zunächst die Zahlen nach unten und addieren Sie dann alle Ergebnisse. Speichern Sie nun diese Zahl; nennen Sie sie "x". Als nächstes müssen wir jede Zahl quadrieren und die Zahlen in jedem Vektor addieren. Stellen Sie sich vor, Sie quadrieren jede Zahl horizontal und addieren sie für beide Vektoren zusammen.
Ziehen Sie die Quadratwurzel aus beiden Summen, multiplizieren Sie sie und nennen Sie dieses Ergebnis "y". Wir finden den Wert unseres Kosinusabstands als "x" geteilt durch "y".
Die Kosinusähnlichkeit wird hauptsächlich in [NLP-Anwendungen] (https://zilliz.com/learn/top-5-nlp-applications) verwendet. Die Cosinus-Ähnlichkeit misst in erster Linie den Unterschied in der semantischen Orientierung. Wenn man mit normalisierten Vektoren arbeitet, ist die Kosinusähnlichkeit gleichbedeutend mit dem inneren Produkt.
Das innere Produkt ist die Projektion des einen Vektors auf den anderen. Der Wert des inneren Produkts ist die gestreckte Länge des Vektors. Je größer der Winkel zwischen den beiden Vektoren ist, desto kleiner ist das innere Produkt. Es skaliert auch mit der Länge des kleineren Vektors. Wir verwenden also das innere Produkt, wenn es um Orientierung und Abstand geht. Zum Beispiel müsstest du eine gerade Strecke durch die Wände zu deinem Kühlschrank laufen.
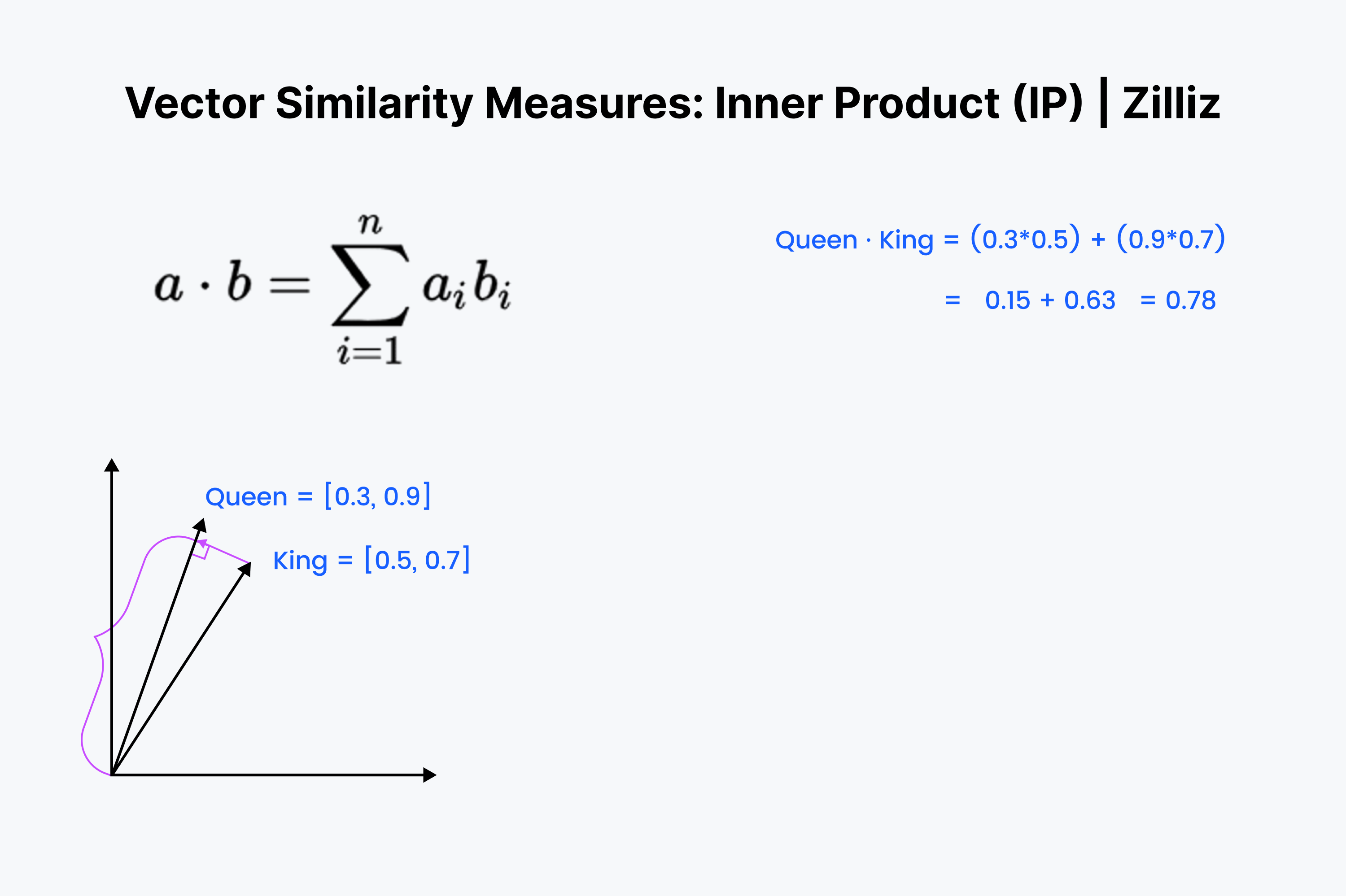
Das innere Produkt sollte Ihnen bekannt vorkommen. Es ist nur das erste ⅓ der Kosinusberechnung. Stellen Sie diese Vektoren in Ihrem Kopf auf und gehen Sie die Reihe hinunter, indem Sie abwärts multiplizieren. Dann addiere sie. Dies misst den geradlinigen Abstand zwischen Ihnen und der nächstgelegenen Dim-Summe.
Das innere Produkt ist eine Art Kreuzung aus euklidischem Abstand und Kosinusähnlichkeit. Bei normalisierten Datensätzen ist es dasselbe wie die Kosinusähnlichkeit, so dass IP sowohl für normalisierte als auch für nicht normalisierte Datensätze geeignet ist. Es ist eine schnellere Option als die Kosinusähnlichkeit und eine flexiblere Option.
Beim Inneren Produkt ist zu beachten, dass es nicht der Dreiecksungleichung folgt. Größere Längen (große Beträge) werden bevorzugt behandelt. Das bedeutet, dass wir vorsichtig sein sollten, wenn wir IP mit Inverted File Index oder einem Graph-Index wie HNSW verwenden.
Die drei oben genannten Vektormetriken sind die nützlichsten in Bezug auf Vektoreinbettungen. Sie sind jedoch nicht die einzigen Möglichkeiten, um den Abstand zwischen zwei Vektoren zu messen. Hier sind zwei weitere Möglichkeiten zur Messung des Abstands oder der Ähnlichkeit zwischen Vektoren.
 Gruppe 13401.png
Gruppe 13401.png
Der Hamming-Abstand kann auf Vektoren oder Zeichenketten angewendet werden. Für unseren Anwendungsfall bleiben wir bei den Vektoren. Die Hamming-Distanz misst die "Differenz" in den Einträgen zweier Vektoren. Zum Beispiel haben "1011" und "0111" einen Hamming-Abstand von 2.
Im Hinblick auf Vektoreinbettungen ist die Messung der Hamming-Distanz nur für binäre Vektoren sinnvoll. [Float-Vektor-Einbettungen] (https://youtube.com/shorts/d_XNrd8PrTc?feature=share), die Ausgaben der vorletzten Schicht neuronaler Netze, bestehen aus Fließkommazahlen zwischen 0 und 1. Beispiele hierfür sind [0.24, 0.111, 0.21, 0.51235] und [0.33, 0.664, 0.125152, 0.1].
Wie Sie sehen, beträgt der Hamming-Abstand zwischen zwei Vektoreinbettungen fast immer nur die Länge des Vektors selbst. Es gibt einfach zu viele Möglichkeiten für jeden Wert. Aus diesem Grund kann die Hamming-Distanz nur auf binäre oder spärliche Vektoren angewendet werden. Die Art von Vektoren, die durch ein Verfahren wie TF-IDF, BM25 oder SPLADE erzeugt werden.
Die Hamming-Distanz ist gut geeignet, um z. B. den Unterschied im Wortlaut zwischen zwei Texten, den Unterschied in der Schreibweise von Wörtern oder den Unterschied zwischen zwei beliebigen binären Vektoren zu messen. Sie ist jedoch nicht geeignet, um den Unterschied zwischen Vektoreinbettungen zu messen.
Hier ist eine lustige Tatsache. Die Hamming-Distanz ist gleichbedeutend mit der Summierung des Ergebnisses einer XOR-Operation für zwei Vektoren.
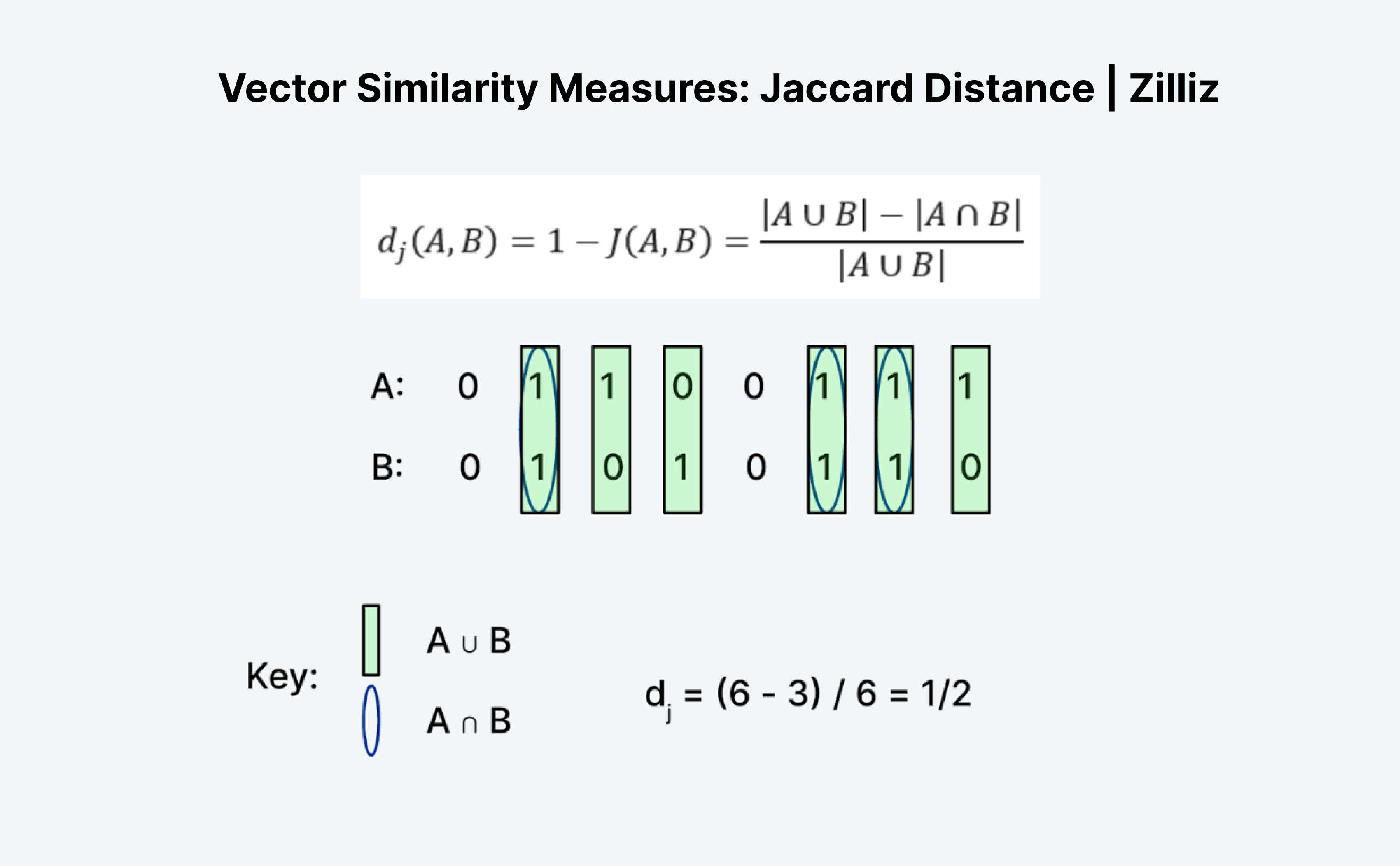
Der Jaccard-Abstand ist eine weitere Möglichkeit, die Ähnlichkeit oder den Abstand zweier Vektoren zu messen. Das Interessante an Jaccard ist, dass es sowohl einen Jaccard Index als auch eine Jaccard Distanz gibt. Der Jaccard-Abstand ist 1 minus dem Jaccard-Index, der Abstandsmetrik, die Milvus implementiert.
Die Berechnung der Jaccard-Distanz oder des Jaccard-Indexes ist eine interessante Aufgabe, da sie auf den ersten Blick nicht unbedingt Sinn macht. Wie die Hamming-Distanz funktioniert auch Jaccard nur bei binären Daten. Ich finde die traditionelle Bildung von "Vereinigungen" und "Kreuzungen" verwirrend. Ich stelle mir das so vor, wie in der Logik. Es ist im Wesentlichen A "ODER" B minus A "UND" B geteilt durch A "ODER" B.
Wie in der Abbildung oben dargestellt, zählen wir die Anzahl der Einträge, bei denen entweder A oder B 1 ist, als "Vereinigung" und die Anzahl der Einträge, bei denen sowohl A als auch B 1 sind, als "Schnittmenge". Der Jaccard-Index für A (01100111) und B (01010110) ist also ½. In diesem Fall ist der Jaccard-Abstand, 1 minus Jaccard-Index, ebenfalls ½.
In diesem Beitrag haben wir die drei nützlichsten Metriken für die Suche nach Vektorähnlichkeit kennengelernt: L2-Abstand (auch bekannt als euklidischer Abstand), Kosinusabstand und inneres Produkt. Jede dieser Metriken hat unterschiedliche Anwendungsfälle. Der euklidische Abstand wird verwendet, wenn es auf den Größenunterschied ankommt. Der Kosinus ist für die Unterschiede in der Ausrichtung gedacht. Das innere Produkt wird verwendet, wenn der Unterschied in der Größe und der Ausrichtung wichtig ist.
Schauen Sie sich diese Videos an, um mehr über Vektorähnlichkeitsmetriken zu erfahren, oder lesen Sie die Dokumentation, um zu lernen, wie man diese Metriken in Milvus konfiguriert.
Einführung in die Ähnlichkeitsmetrik
Ähnlichkeitsmetriken sind ein entscheidendes Werkzeug bei verschiedenen Datenanalysen und Aufgaben des maschinellen Lernens. Sie ermöglichen es uns, die Ähnlichkeit zwischen verschiedenen Daten zu vergleichen und zu bewerten, was Anwendungen wie Clustering, Klassifizierung und Empfehlungen erleichtert. Angesichts der zahlreichen verfügbaren Ähnlichkeitsmetriken, die jeweils ihre Stärken und Schwächen haben, kann die Auswahl der richtigen Metrik für eine bestimmte Aufgabe eine Herausforderung darstellen. In diesem Abschnitt werden wir das Konzept der Ähnlichkeitsmetriken und ihre Bedeutung vorstellen und einen Überblick über die am häufigsten verwendeten Metriken geben.
Kosinus-Ähnlichkeit
Die Cosinus-Ähnlichkeit ist eine weit verbreitete Ähnlichkeitsmetrik, die den Cosinus des Winkels zwischen zwei Vektoren misst. Sie wird häufig bei der Verarbeitung natürlicher Sprache und bei Information Retrieval Aufgaben verwendet. Die Kosinus-Ähnlichkeitsmetrik ist besonders nützlich, wenn es um hochdimensionale Daten geht, da sie rechnerisch effizient ist und spärliche Daten verarbeiten kann. Die Kosinus-Ähnlichkeit zwischen zwei Vektoren lässt sich berechnen, indem das Punktprodukt der Vektoren durch das Produkt ihrer Größen geteilt wird.
Euklidischer Abstand
Der euklidische Abstand, auch bekannt als geradliniger Abstand, ist eine weit verbreitete Abstandsmetrik, die den Abstand zwischen zwei Punkten im n-dimensionalen Raum misst. Sie wird als Quadratwurzel aus der Summe der quadrierten Differenzen zwischen den entsprechenden Elementen der beiden Vektoren berechnet. Der euklidische Abstand wird häufig in verschiedenen Anwendungen verwendet, darunter Clustering, Klassifizierung und Regressionsanalyse. Er kann jedoch empfindlich auf Ausreißer reagieren und ist bei hochdimensionalen Daten möglicherweise nicht sehr leistungsfähig.
Auswahl der richtigen Ähnlichkeitsmetrik
Die Wahl der richtigen Ähnlichkeitsmetrik hängt von verschiedenen Faktoren ab, u. a. von der Art der Daten, den Analysezielen und der Beziehung zwischen den Variablen. So eignet sich beispielsweise die Kosinusähnlichkeit für hochdimensionale Daten und Aufgaben der natürlichen Sprachverarbeitung, während die euklidische Distanz häufig für Clustering- und Klassifizierungsaufgaben verwendet wird. Der Manhattan-Abstand, auch L1-Abstand genannt, eignet sich für Daten mit Ausreißern, während der Hamming-Abstand für binäre Daten verwendet wird. Es ist wichtig, die Eigenschaften und Grenzen der einzelnen Ähnlichkeitsmetriken zu kennen, um die für eine bestimmte Aufgabe am besten geeignete Metrik auszuwählen.
Real-World Applications
Ähnlichkeitsmetriken haben zahlreiche reale Anwendungen in verschiedenen Bereichen, darunter:
Verarbeitung natürlicher Sprache: Die Cosinus-Ähnlichkeit wird häufig bei der Textklassifizierung, der Stimmungsanalyse und der Informationsbeschaffung verwendet.
Empfehlungssysteme: Ähnlichkeitsmetriken wie die Kosinusähnlichkeit und der euklidische Abstand werden verwendet, um Produkte oder Dienstleistungen auf der Grundlage von Nutzerverhalten und -präferenzen zu empfehlen.
Bild- und Videoanalyse: Ähnlichkeitsmetriken wie der euklidische Abstand und der Manhattan-Abstand werden bei der Klassifizierung von Bildern und Videos, der [Objekterkennung] (https://zilliz.com/learn/what-is-object-detection) und der Verfolgung von Objekten verwendet.
Clustering und Klassifizierung: Ähnlichkeitsmetriken wie der euklidische Abstand und die Kosinusähnlichkeit werden bei Clustering- und Klassifizierungsaufgaben verwendet, um ähnliche Datenpunkte zusammenzufassen.
Zusammenfassend lässt sich sagen, dass Ähnlichkeitsmetriken ein wichtiges Instrument für verschiedene Datenanalysen und Aufgaben des maschinellen Lernens sind. Ein Verständnis der Merkmale und Grenzen der einzelnen Ähnlichkeitsmetriken ist unerlässlich, um die am besten geeignete Metrik für eine bestimmte Aufgabe auszuwählen. Durch die Auswahl der richtigen Ähnlichkeitsmetrik können wir die Genauigkeit und Relevanz unserer Ergebnisse verbessern, was zu besseren Entscheidungen und Erkenntnissen führt.

Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.