




10 Open-Source LLM-Frameworks, die Entwickler im Jahr 2025 nicht ignorieren können
2024 war ein hervorragendes Jahr für große Sprachmodelle (LLM)), und auch 2025 gibt es keine Anzeichen dafür, dass die Dynamik nachlässt. Von GPT-4 und Geminis multimodalen Fähigkeiten bis hin zu adaptiven Echtzeit-KI-Systemen sind LLMs nicht mehr nur innovativ - sie sind unverzichtbar. Sie treiben Chatbots, Suchmaschinen und Tools zur Erstellung von Inhalten an und automatisieren sogar Arbeitsabläufe, von denen wir einst dachten, dass nur Menschen sie bewältigen könnten.
Die Sache ist jedoch die: Ein leistungsstarkes LLM ist nur die halbe Miete. Die Erstellung skalierbarer, effizienter und produktionsreifer LLM-Anwendungen kann eine Herausforderung sein - hier kommen LLM-Frameworks ins Spiel. Sie vereinfachen Arbeitsabläufe, verbessern die Leistung und lassen sich nahtlos in bestehende Systeme integrieren, so dass Entwickler mit weniger Aufwand das volle Potenzial dieser Modelle ausschöpfen können.
In diesem Beitrag stellen wir 10 Open-Source-LLM-Frameworks vor, die KI-Entwickler auf dem Weg ins Jahr 2025 nicht ignorieren dürfen. Diese Frameworks sind die Geheimwaffen, die Entwicklern helfen, schneller als je zuvor zu skalieren, zu optimieren und zu innovieren. Wenn Sie bereit sind, Ihre KI-Projekte auf ein höheres Niveau zu bringen, lassen Sie uns eintauchen!
LangChain: Kontextabhängige, mehrstufige KI-Workflows
[LangChain] (https://github.com/langchain-ai/langchain) ist ein Open-Source-Framework, das die Entwicklung von Anwendungen, die auf großen Sprachmodellen (LLMs) basieren, vereinfachen soll. Es vereinfacht die Erstellung von Workflows, die LLMs mit externen Datenquellen, APIs oder Berechnungslogik kombinieren, und ermöglicht es Entwicklern, dynamische, kontextbewusste Systeme für Aufgaben wie Konversationsagenten, Dokumentenanalyse und Zusammenfassungen zu erstellen.
Schlüssel-Fähigkeiten
Kompatible Pipelines**: LangChain erleichtert die Verkettung mehrerer LLM-Aufrufe und externer Funktionen und ermöglicht so komplexe mehrstufige Arbeitsabläufe.
Ketten von der Stange: LangChain bietet vorkonfigurierte Ketten, organisierte Zusammenstellungen von Komponenten, die für die Ausführung bestimmter übergeordneter Aufgaben entwickelt wurden. Diese vorgefertigten Ketten vereinfachen die Initiierung von Projekten.
Prompt Engineering Dienstprogramme: Enthält Werkzeuge zum Erstellen, Verwalten und Optimieren von Prompts, die auf bestimmte Aufgaben zugeschnitten sind.
Speicherverwaltung: Bietet integrierte Funktionen zur Speicherung des Konversationskontexts über Interaktionen hinweg und ermöglicht so personalisierte Anwendungen.
LangChain hat sich mit APIs von Drittanbietern, Vektordatenbanken, LLMs und verschiedenen Datenquellen verbunden. Insbesondere die Integration von LangChain mit [Vektordatenbanken] (https://zilliz.com/learn/what-is-vector-database) wie [Milvus] (https://zilliz.com/what-is-milvus) und [Zilliz Cloud] (https://zilliz.com/cloud) erweitert das Potenzial von LangChain. Milvus ist eine quelloffene, hochleistungsfähige Vektordatenbank zur Verwaltung und Abfrage von Einbettungsvektoren in Milliardengröße. Sie ergänzt die Fähigkeiten von LangChain, indem sie eine schnelle und genaue Abfrage relevanter Daten ermöglicht. Entwickler können diese Integration nutzen, um skalierbare Retrieval-Augmented Generation (RAG) Systeme aufzubauen, in denen Milvus kontextuell relevante Dokumente abruft. LangChain verwendet ein generatives Modell, um genaue und aufschlussreiche Ergebnisse zu erzeugen. Weitere Informationen finden Sie in den nachstehenden Ressourcen:
Zilliz Cloud Integration mit LangChain für fortgeschrittene RAG](https://zilliz.com/product/integrations/langchain)
RAG aufbauen mit LangChainJS, Milvus und Strapi ](https://zilliz.com/blog/build-rag-with-langchain-milvus-and-strapi)
Wie man eine mehrsprachige RAG mit Milvus, LangChain und OpenAI erstellt](https://zilliz.com/blog/building-multilingual-rag-milvus-langchain-openai)
Retrieval Augmented Generation auf Notion Docs über LangChain ](https://zilliz.com/blog/retrieval-augmented-generation-on-notion-docs-via-langchain)
LlamaIndex: Verbindung von LLMs zu verschiedenen Datenquellen
[LlamaIndex] (https://github.com/run-llama/llama_index) ist ein Open-Source-Framework, das es großen Sprachmodellen (LLMs) ermöglicht, effizient auf verschiedene Datenquellen zuzugreifen und diese zu nutzen. Es vereinfacht die Aufnahme, Strukturierung und Abfrage unstrukturierter Daten und erleichtert so die Entwicklung fortschrittlicher KI-Anwendungen wie Dokumentensuche, Zusammenfassungen und wissensbasierte Chatbots.
Schlüssel-Fähigkeiten
Datenkonnektoren: Bietet eine Reihe von robusten Konnektoren für die Aufnahme strukturierter und unstrukturierter Daten aus verschiedenen Quellen wie PDFs, SQL-Datenbanken, APIs und Vektorspeichern.
Indizierungswerkzeuge**: Ermöglicht Entwicklern die Erstellung benutzerdefinierter Indizes, einschließlich Baum-, Listen- und Graphenstrukturen, um die Abfrage und den Abruf von Daten zu optimieren.
Abfrage-Optimierung: Bietet fortschrittliche Abfragemechanismen, die präzise und kontextabhängige Antworten ermöglichen.
Erweiterbarkeit: Hochgradig modular, was die Integration mit externen Bibliotheken und Tools zur Erweiterung der Funktionalität erleichtert.
LLM-optimiertes Framework: Entwickelt für die Arbeit mit LLMs, um eine effiziente Nutzung von Rechenressourcen für umfangreiche Aufgaben zu gewährleisten.
LlamaIndex wurde mit verschiedenen speziell entwickelten Vektordatenbanken wie Milvus und Zilliz Cloud integriert, um skalierbare und effiziente RAG-Workflows zu unterstützen. In diesem Setup fungiert Milvus als hochleistungsfähiges Backend für die Speicherung und Abfrage von Einbettungsvektoren, während LlamaIndex die abgerufenen Daten für die Verarbeitung durch LLMs strukturiert und organisiert. Diese Kombination erlaubt es Entwicklern, die relevantesten Datenpunkte abzurufen und ermöglicht es LLMs, genauere, kontextbezogene Ergebnisse zu liefern. Weitere Informationen finden Sie in den nachstehenden Ressourcen:
Haystack: Rationalisierung von RAG-Pipelines für produktionsreife KI-Anwendungen
[Haystack] (https://haystack.deepset.ai/) ist ein Open-Source-Python-Framework, das die Entwicklung von LLM-gestützten Anwendungen erleichtern soll. Es ermöglicht Entwicklern die Erstellung von End-to-End-KI-Lösungen durch die Integration von LLMs mit verschiedenen Datenquellen und Komponenten, wodurch es sich für Aufgaben wie RAG, Dokumentensuche, Beantwortung von Fragen und Generierung von Antworten eignet.
Schlüssel-Fähigkeiten
Flexible Pipelines: Haystack ermöglicht die Erstellung modularer Pipelines für Aufgaben wie Dokumentenrecherche, Fragenbeantwortung und Zusammenfassung. Entwickler können verschiedene Komponenten kombinieren, um Workflows auf ihre spezifischen Anforderungen zuzuschneiden.
Retriever-Reader Architektur: Kombiniert Retriever für eine effiziente Dokumentenfilterung mit Readern (z.B. LLMs), um präzise und kontextbezogene Antworten zu generieren.
Backend-unabhängig: Unterstützt mehrere Vektordatenbank-Backends, einschließlich Milvus und FAISS, und gewährleistet so Flexibilität beim Einsatz.
LLM-Integration: Bietet eine nahtlose Integration mit Sprachmodellen, die es Entwicklern ermöglicht, vortrainierte und fein abgestimmte Modelle für verschiedene Aufgaben zu nutzen.
Skalierbarkeit und Leistung: Optimiert für die Verarbeitung großer Datensätze und Abfragen mit hohem Durchsatz, geeignet für Unternehmensanwendungen.
Im März 2024 veröffentlichte Haystack 2.0, das eine flexiblere und anpassbare Architektur einführt. Dieses Update ermöglicht die Erstellung komplexer Pipelines mit Funktionen wie parallelen Verzweigungen und Schleifen und verbessert die Unterstützung für LLMs und agentenbasiertes Verhalten. Das neue Design betont eine gemeinsame Schnittstelle für die Datenspeicherung und bietet Integrationen mit verschiedenen Datenbanken und Vektorspeichern, einschließlich Milvus und Zilliz Cloud. Diese Flexibilität stellt sicher, dass Daten innerhalb von Haystack-Pipelines einfach abgerufen und verwaltet werden können, was die Entwicklung von skalierbaren und leistungsstarken KI-Anwendungen unterstützt. Weitere Informationen finden Sie in den unten stehenden Ressourcen:
Haystack GitHub: https://github.com/deepset-ai/haystack
Integration: Haystack und Milvus
Tutorial: Retrieval-Augmented Generation (RAG) mit Milvus und Haystack
Tutorial: Aufbau einer RAG-Pipeline mit Milvus und Haystack 2.0
Dify: Vereinfachung der LLM-gestützten App-Entwicklung
[Dify] (https://github.com/langgenius/dify) ist eine Open-Source-Plattform für die Entwicklung von KI-Anwendungen. Sie kombiniert Backend-as-a-Service mit LLMOps, unterstützt Mainstream-Sprachmodelle und bietet eine intuitive Prompt-Orchestrierungsschnittstelle. Dify bietet hochwertige RAG-Engines, ein flexibles KI-Agenten-Framework und einen intuitiven Low-Code-Workflow, mit dem sowohl Entwickler als auch technisch nicht versierte Benutzer innovative KI-Lösungen erstellen können.
Schlüssel-Fähigkeiten
Backend-as-a-Service für LLMs: Verwaltet die Backend-Infrastruktur, so dass sich die Entwickler auf die Entwicklung von Anwendungen konzentrieren können, anstatt Server zu verwalten.
Prompt Orchestration: Vereinfacht das Erstellen, Testen und Verwalten von Prompts, die auf bestimmte Aufgaben zugeschnitten sind.
Echtzeit-Analytik: Bietet Einblicke in die Modellleistung, Benutzerinteraktionen und das Anwendungsverhalten, um Arbeitsabläufe zu optimieren.
Umfassende Integrationsmöglichkeiten: Verbindet sich mit APIs von Drittanbietern, externen Tools und gängigen LLMs und bietet Flexibilität für benutzerdefinierte Workflows.
Dify lässt sich gut mit Vektordatenbanken wie Milvus integrieren, wodurch die Fähigkeit zur Bewältigung komplexer, umfangreicher Datenabfragen verbessert wird. Durch die Kopplung von Dify mit Milvus können Entwickler Systeme erstellen, die Einbettungen für Aufgaben wie RAG effizient speichern, abrufen und verarbeiten.
Letta (ehemals MemGPT): Aufbau von RAG-Agenten mit erweitertem LLM-Kontextfenster
Letta ist ein Open-Source-Framework, das LLMs mit einem Langzeitgedächtnis ausstattet. Im Gegensatz zu traditionellen LLMs, die Eingaben statisch verarbeiten, erlaubt Letta dem Modell, sich an vergangene Interaktionen zu erinnern und darauf zu verweisen, was dynamischere, kontextbewusste und personalisierte Anwendungen ermöglicht. Es integriert Speicherverwaltungstechniken zum Speichern, Abrufen und Aktualisieren von Informationen im Laufe der Zeit und ist damit ideal für die Entwicklung intelligenter Agenten und Konversationssysteme, die sich mit den Benutzerinteraktionen weiterentwickeln.
Abbildung - Wie Letta mit verschiedenen KI-Tools zusammenarbeitet] (https://assets.zilliz.com/Figure_How_Letta_works_with_various_AI_tools_05d96d2548.png)
Schlüsselfähigkeiten
Selbsteditierendes Gedächtnis: Letta führt ein selbsteditierendes Gedächtnis ein, das es Agenten ermöglicht, ihre Wissensbasis autonom zu aktualisieren, aus Interaktionen zu lernen und sich mit der Zeit anzupassen.
Agent Development Environment (ADE): Bietet eine grafische Oberfläche für die Erstellung, den Einsatz, die Interaktion mit und die Beobachtung von KI-Agenten, wodurch der Entwicklungs- und Fehlerbehebungsprozess rationalisiert wird.
Persistenz- und Zustandsverwaltung: Stellt sicher, dass Agenten die Kontinuität über Sitzungen hinweg aufrechterhalten, indem ihr Zustand, einschließlich Erinnerungen und Interaktionen, persistiert wird, was kohärentere und kontextbezogene Antworten ermöglicht.
Tool-Integration: Unterstützt die Einbindung benutzerdefinierter Tools und Datenquellen, so dass Agenten eine breite Palette von Aufgaben durchführen und bei Bedarf auf externe Informationen zugreifen können.
Modellunabhängige Architektur: Entwickelt, um mit verschiedenen LLMs und RAG-Systemen zu arbeiten, und bietet Flexibilität bei der Auswahl und Integration verschiedener Modellanbieter
Letta hat sich in gängige Vektordatenbanken integriert, um seine Speicher- und Abrufmöglichkeiten für fortgeschrittene RAG-Workflows zu verbessern. Durch die Nutzung skalierbarer Vektorspeicher und einer effizienten Ähnlichkeitssuche ermöglicht Letta den KI-Agenten den Zugriff auf langfristiges kontextbezogenes Wissen und gewährleistet so einen schnellen und präzisen Datenabruf. Diese Integration ermöglicht es Entwicklern, intelligentere, kontextbezogene Anwendungen zu erstellen, die auf bestimmte Bereiche zugeschnitten sind, wie z. B. Kundensupport oder personalisierte Empfehlungen, und gleichzeitig einen persistenten und skalierbaren Speicher zu erhalten. Weitere Informationen finden Sie in den nachstehenden Ressourcen.
- Tutorial | MemGPT mit Milvus-Integration
Vanna: Ermöglichung KI-gestützter SQL-Generierung
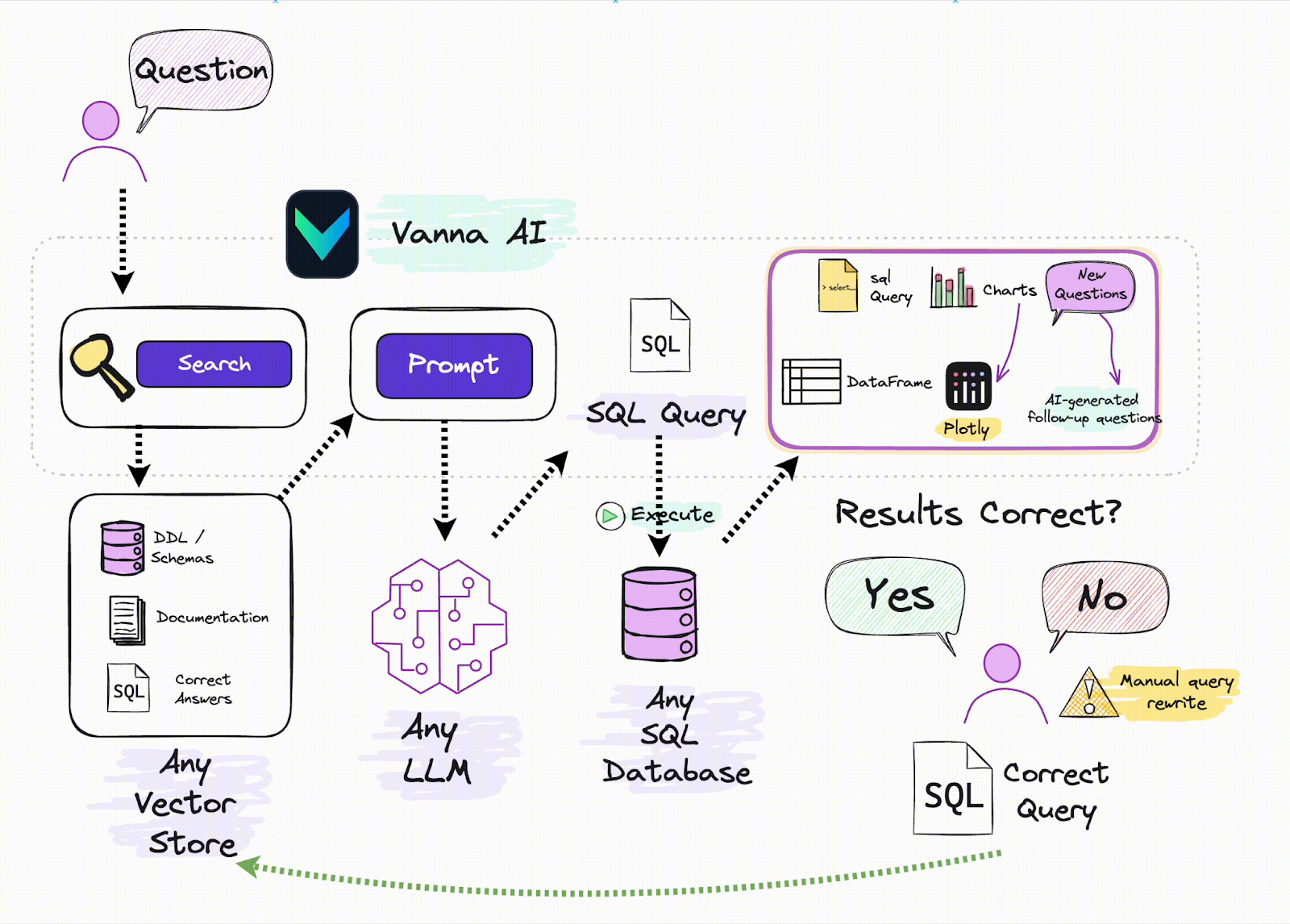
Vanna ist ein quelloffenes Python-Framework, das die Generierung von SQL-Abfragen durch natürlichsprachliche Eingaben vereinfachen soll. Durch den Einsatz von RAG-Techniken ermöglicht es Vanna den Benutzern, Modelle auf ihren spezifischen Daten zu trainieren, so dass sie Fragen stellen können und genaue SQL-Abfragen erhalten, die auf ihre Datenbanken zugeschnitten sind. Dieser Ansatz rationalisiert den Prozess der Interaktion mit Datenbanken und macht ihn für Benutzer ohne umfassende SQL-Kenntnisse leichter zugänglich.
 Vanna
Vanna
Schlüssel-Fähigkeiten
Konvertierung von natürlicher Sprache in SQL**: Vanna ermöglicht es Benutzern, Fragen in natürlicher Sprache einzugeben, die dann in präzise SQL-Abfragen umgewandelt werden, die in der angeschlossenen Datenbank ausgeführt werden können.
Unterstützung für mehrere Datenbanken: Das Framework bietet Out-of-the-Box-Unterstützung für verschiedene Datenbanken, darunter Snowflake, BigQuery, Postgres und andere. Es ermöglicht auch die einfache Integration mit jeder Datenbank durch benutzerdefinierte Konnektoren.
Flexibilität der Benutzeroberfläche: Vanna bietet mehrere Optionen für die Benutzeroberfläche, wie z.B. Jupyter Notebooks, Slackbot, Web-Apps und Streamlit-Apps, so dass die Benutzer das Frontend wählen können, das am besten zu ihrem Workflow passt.
Vanna und Vektordatenbanken sind eine großartige Kombination für den Aufbau effektiver RAG-Systeme. Wenn ein Benutzer eine natürlichsprachliche Abfrage eingibt, verwendet Vanna eine Vektordatenbank, um relevante Daten auf der Grundlage von vorgespeicherten Vektoreinbettungen abzurufen. Diese Daten werden dann verwendet, um Vanna dabei zu helfen, eine genaue SQL-Abfrage zu generieren, wodurch es einfacher wird, strukturierte Daten aus einer relationalen Datenbank abzurufen. Durch die Kombination der Leistungsfähigkeit der Vektorsuche mit der SQL-Generierung vereinfacht Vanna die Arbeit mit unstrukturierten Daten und ermöglicht Benutzern die Interaktion mit komplexen Datensätzen, ohne dass sie über fortgeschrittene SQL-Kenntnisse verfügen müssen. Weitere Informationen finden Sie in den nachstehenden Ressourcen:
Kotaemon: KI-unterstützte Dokumenten-Qualitätssicherung
[Kotaemon] (https://github.com/Cinnamon/kotaemon) ist eine quelloffene, anpassbare RAG-Oberfläche zum Chatten mit Ihren Dokumenten. Es bietet eine saubere, Multi-User-QA-Web-Schnittstelle für Dokumente, die lokale und API-basierte Sprachmodelle unterstützt. kotaemon bietet eine hybride RAG-Pipeline mit Volltext- und Vektor-Retrieval-Fähigkeiten, die eine multimodale QA für Dokumente mit Abbildungen und Tabellen ermöglicht.
kotaemon ist sowohl für Endanwender als auch für Entwickler konzipiert und unterstützt komplexe Reasoning-Methoden wie ReAct und ReWOO. Es bietet erweiterte Zitierfunktionen mit Dokumentenvorschau, konfigurierbare Einstellungen für die Suche und Generierung sowie ein erweiterbares Framework für die Erstellung eigener RAG-Pipelines.
 Kotaemon
Kotaemon
Schlüssel-Fähigkeiten
Einfache Bereitstellung: Kotaemon bietet einfache Schnittstellen für die Bereitstellung von LLMs in der Produktion mit minimaler Einrichtung und ermöglicht eine schnelle Skalierung und Integration.
Anpassbare Pipelines: Es ermöglicht Entwicklern, KI-Workflows einfach anzupassen und LLMs mit externen APIs, Datenbanken und anderen Tools zu kombinieren.
Erweitertes Prompting: Integrierte Tools für Prompt-Engineering und -Optimierung erleichtern die Feinabstimmung der Modellausgaben für bestimmte Aufgaben.
Performance-Optimierung: Kotaemon wurde für Hochleistungsoperationen entwickelt und gewährleistet niedrige Latenzzeiten und eine effiziente Nutzung der Ressourcen.
Multi-Modell-Unterstützung: Das Framework unterstützt verschiedene LLM-Architekturen und gibt Entwicklern die Flexibilität, das beste Modell für ihren spezifischen Anwendungsfall zu wählen.
Kotaemon lässt sich in Vektordatenbanken wie Milvus integrieren und ermöglicht den schnellen Abruf relevanter Daten für Aufgaben wie Retrieval-Augmented Generation (RAG). Durch die Nutzung der effizienten Vektorsuchfunktionen von Milvus kann Kotaemon den Kontext und die Relevanz von KI-generierten Ergebnissen verbessern. Diese Integration ermöglicht es Entwicklern, KI-Systeme zu erstellen, die Inhalte generieren und relevante Informationen aus großen Datensätzen abrufen, wodurch die Gesamtleistung und Genauigkeit verbessert wird.
vLLM: Leistungsstarke LLM-Inferenz für Echtzeit-KI-Anwendungen
vLLM ist eine Open-Source-Bibliothek, die vom SkyLab der UC Berkeley entwickelt wurde, um LLM-Inferenz und -Serving zu optimieren. Mit dem Schwerpunkt auf Leistung und Skalierbarkeit führt vLLM Innovationen wie PagedAttention ein, die die Serving-Geschwindigkeit um das bis zu 24-fache erhöht und gleichzeitig die GPU-Speicherauslastung im Vergleich zu herkömmlichen Ansätzen halbiert. Dies macht sie zu einem entscheidenden Faktor für Entwickler, die anspruchsvolle KI-Anwendungen entwickeln, die eine effiziente Nutzung von Hardware-Ressourcen erfordern.
Schlüssel-Funktionen:
PagedAttention-Technologie: Verbessert die Speicherverwaltung, indem sie eine nicht zusammenhängende Speicherung von Aufmerksamkeitsschlüsseln und -werten ermöglicht, die Speicherverschwendung reduziert und den Durchsatz um das bis zu 24-fache erhöht.
Continuous Batching: Aggregiert eingehende Anfragen in Echtzeit, maximiert die GPU-Auslastung und minimiert Leerlaufzeiten, was zu höherem Durchsatz und geringerer Latenz führt.
Streaming Outputs: Ermöglicht die Generierung von Token in Echtzeit, sodass Anwendungen sofort Teilergebnisse liefern können - ideal für Echtzeit-Benutzerinteraktionen wie Chatbots.
Breit gefächerte Modellkompatibilität: Unterstützt gängige LLM-Architekturen wie GPT und LLaMA und gewährleistet so Flexibilität für viele Anwendungsfälle und eine nahtlose Integration in bestehende Workflows.
OpenAI-kompatibler API-Server: Bietet eine API-Schnittstelle, die die von OpenAI widerspiegelt und Entwicklern, die mit OpenAI-APIs vertraut sind, die Bereitstellung und Integration in bestehende Systeme erleichtert.
vLLM wird in Kombination mit Vektordatenbanken wie Milvus zu einem Eckpfeiler für den Aufbau leistungsstarker RAG-Systeme. Vektordatenbanken speichern und rufen hochdimensionale Einbettungen effizient ab, die für das Abrufen kontextbezogener Informationen entscheidend sind. vLLM ergänzt dies durch optimierte LLM-Inferenz, die sicherstellt, dass die abgerufenen Informationen nahtlos in präzise, kontextbezogene Antworten verarbeitet werden. Diese Integration verbessert die Anwendungsleistung und bewältigt Herausforderungen wie KI-Halluzinationen, indem sie die Ausgaben auf die abgerufenen Daten stützt. Weitere Informationen finden Sie in den nachstehenden Ressourcen.
Erstellung von RAG-Anwendungen mit Milvus, Qwen und vLLM](https://zilliz.com/blog/build-rag-app-with-milvus-qwen-and-vllm)
Effiziente Speicherverwaltung für große Sprachmodelle mit PagedAttention](https://zilliz.com/learn/efficient-memory-management-for-llm-serving-pagedattention)
Aufbau von RAG mit Milvus, vLLM und Meta's Llama 3.1 ](https://zilliz.com/blog/building-rag-milvus-vllm-llama-3-1)
Unstructured: Unstrukturierte Daten für GenAI zugänglich machen
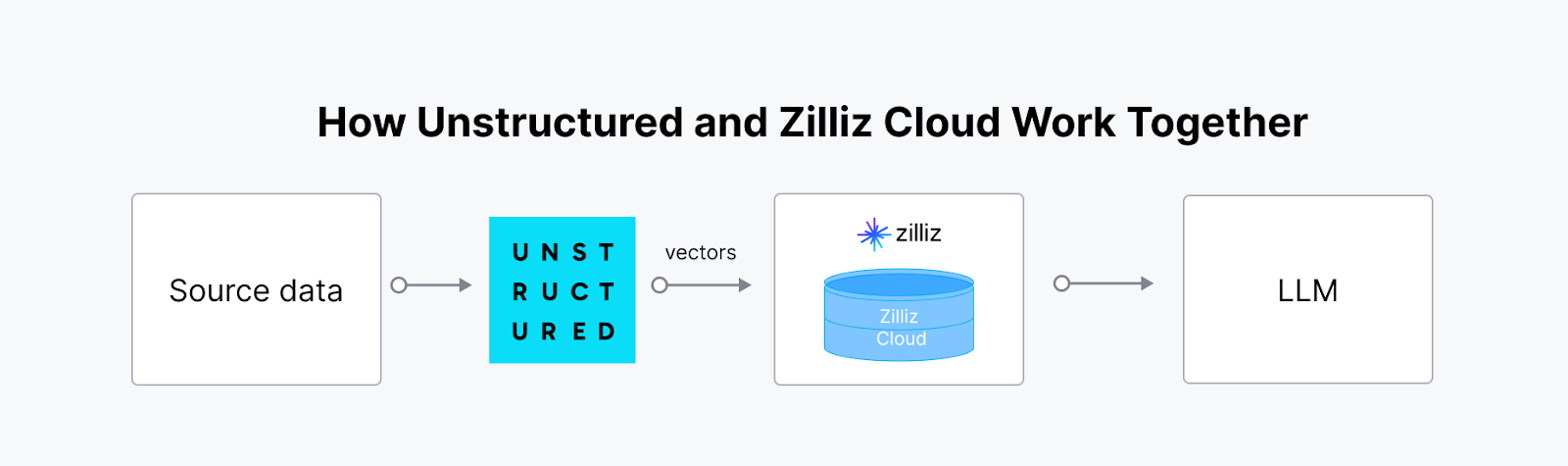
Unstructured ist eine Open-Source-Bibliothek, die die Aufnahme und Vorverarbeitung unstrukturierter Daten in verschiedenen Datenformaten wie PDFs, HTML, Word-Dokumenten und Bildern vereinfacht. Sie bietet modulare Funktionen zum Partitionieren, Bereinigen, Extrahieren, Staging und Chunking von Dokumenten und erleichtert so die Umwandlung von unstrukturierten Daten in strukturierte Formate. Dieses Toolkit ist für die Optimierung von Daten-Workflows in Large Language Model (LLM)-Anwendungen von Vorteil.
Durch die Integration von Unstructured mit einer Vektordatenbank wie [Milvus] (https://zilliz.com/what-is-milvus) entsteht eine leistungsstarke, skalierbare Lösung für die Verwaltung und Nutzung unstrukturierter Daten in KI-Anwendungen. Die Unstructured-Plattform nimmt unstrukturierte Daten aus verschiedenen Dateitypen auf, verarbeitet sie und wandelt sie in KI-fähige Vektoreinbettungen um. Diese Einbettungen sind für fortgeschrittene KI-Workflows von entscheidender Bedeutung, doch ihre effektive Speicherung, Indizierung und Abfrage erfordert eine [spezialisierte Vektordatenbank] (https://zilliz.com/blog/what-is-a-real-vector-database). Die Synergie zwischen Unstructured und Milvus (oder Zilliz Cloud) ermöglicht eine rationalisierte End-to-End-Pipeline, die besonders wertvoll für Retrieval-Augmented Generation (RAG) und andere KI-gesteuerte Anwendungen wie intelligente Chatbots und personalisierte Empfehlungssysteme ist.
 Unstructured
Unstructured
Langfuse: Bessere Beobachtbarkeit und Analyse für LLM-Anwendungen
Langfuse ist eine quelloffene LLM-Engineering-Plattform, die Teams beim gemeinsamen Debuggen, Analysieren und Iterieren ihrer LLM-Anwendungen unterstützt. Sie bietet Funktionen wie Beobachtbarkeit, Prompt-Management, Auswertungen und Metriken, die alle nativ integriert sind, um den Entwicklungsablauf zu beschleunigen.
Schlüssel-Fähigkeiten
Ende-zu-Ende-Beobachtbarkeit**: Verfolgt LLM-Interaktionen, einschließlich Aufforderungen, Antworten und Leistungsmetriken, um Transparenz und Zuverlässigkeit zu gewährleisten.
Prompt-Verwaltung: Bietet Tools zur Versionierung, Optimierung und zum Testen von Prompts, um die Entwicklung von robusten KI-Anwendungen zu rationalisieren.
Flexible Integration: Arbeitet nahtlos mit gängigen Frameworks wie LangChain und LlamaIndex zusammen und unterstützt eine breite Palette von LLM-Architekturen.
Echtzeit-Debugging: Bietet verwertbare Einblicke in Fehler und Engpässe und ermöglicht Entwicklern eine schnelle Iteration.
Die Integration von Langfuse mit Vektordatenbanken verbessert die RAG-Workflows, indem sie die Qualität und Relevanz der Einbettung sichtbar macht. Diese Integration ermöglicht es Entwicklern, die Leistung und Genauigkeit der Vektorsuche mit Hilfe detaillierter Analysen zu überwachen und zu optimieren, um sicherzustellen, dass die Abrufprozesse fein abgestimmt und auf die Bedürfnisse der Benutzer ausgerichtet sind. Sehen Sie sich das folgende Tutorial an, um den Einstieg zu finden.
Schlussfolgerung
Zu Beginn des Jahres 2025 ist es klar, dass Open-Source-Frameworks nicht mehr nur hilfreiche Add-Ons sind - sie sind die Grundlage für den Aufbau robuster LLM-Anwendungen. Frameworks wie LangChain und LlamaIndex haben die Art und Weise verändert, wie wir Daten integrieren und abfragen, während vLLM und Haystack neue Maßstäbe für Geschwindigkeit und Skalierbarkeit setzen. Aufstrebende Frameworks wie Langfuse und Letta bringen einzigartige Stärken in Bezug auf Beobachtbarkeit und Speicher mit und öffnen die Türen zu intelligenteren, reaktionsschnelleren KI-Systemen.
Diese Frameworks versetzen Entwickler in die Lage, komplexe Herausforderungen zu meistern, mit kühnen Ideen zu experimentieren und die Grenzen des Machbaren zu erweitern. Mit diesen Frameworks in der Hand ist 2025 Ihr Jahr, um intelligentere, schnellere und wirkungsvollere GenAI-Anwendungen zu entwickeln.

Weiterlesen

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.