




How a Globally Leading GPU and AI Platform Uses Milvus to Scale Multimodal Data Mining for Its Autonomous Driving System

-30% Cost
Reduced memory and storage footprint via disk-based primary keys and optimized segment layout in Milvus 2.5.
10× Scale
Proven headroom to scale an order of magnitude further without redesign or cost surprises.y without architectural changes or unexpected costs.
Enterprise Reliability
Continuous production at a massive scale with no major incidents.
Hybrid Search
Unified vector search and metadata filtering to support complex queries.
From a system stability perspective, it's really quite good. Over the year-plus that we've been using it—from version 2.4.3 to now 2.5.8—I honestly haven't encountered many issues. The system can just run there for months, with new data being written every day and users searching every day, without any problems. I don't need to worry about it.
Team Lead
About the Company
The customer is a global leader in accelerated computing and artificial intelligence, with decades of experience building GPUs and software platforms used across gaming, robotics, data centers, and automotive applications. One of its flagship initiatives is an end-to-end platform for advanced driver-assistance and autonomous driving. This platform supports the full lifecycle of self-driving development—from large-scale data collection and AI model training to in-vehicle inference and real-time decision-making.
Behind this platform is the company’s Autonomous Vehicle (AV) Data Engineering organization, which is responsible for the data infrastructure that powers its self-driving technology. Each hour of real-world driving produces terabytes of multimodal sensor data, including synchronized camera streams, LiDAR point clouds, radar measurements, high-precision localization data, and detailed vehicle-state metadata. The team’s mission is to make this massive and constantly growing dataset searchable, discoverable, and operationally usable by hundreds of engineers who must surface long-tail scenarios, identify rare edge cases, and validate model behavior under real-world conditions.
To meet these requirements, the team built a multimodal data mining system capable of searching tens of billions of indexed sensor data points collected from test fleets. The system converts raw sensor data into vector embeddings so engineers can run deep, context-aware queries—for example: “vehicles merging from the right in heavy rain,” “pedestrians crossing at dusk in unmarked intersections,” or “two-lane roundabouts with occluded visibility.”
The system initially ran on FAISS, but as data volume and operational demands grew, the team migrated to Milvus to achieve higher scalability, lower maintenance effort, and stronger production reliability. Milvus provided a clean path to support an order of magnitude more data, reduce operational overhead, and improve clustering, indexing, and storage efficiency as the autonomous driving fleet continued to expand.
The Challenge: FAISS Couldn’t Scale
The Data Management Bottleneck
The early design of this data mining system was intentionally simple. Each autonomous driving session—typically an hour-long trip—was processed into frames, transformed into vector embeddings through the company’s proprietary models, and grouped into FAISS index files, usually one per day.
While that structure worked well initially, it didn’t scale. As the dataset ballooned, so did the number of index files—eventually reaching hundreds of thousands. Each represented a small, isolated pocket of information. Searching across them introduced significant complexity: daily indexes often contained overlapping data, requiring intricate logic to filter and merge metadata. In practice, this meant that while searching within a single day worked fine, most users wanted to query broader conditions—like specific driving scenarios spanning multiple days or regions. Those searches had to access many separate index files at once, which was computationally expensive. Engineers often had to manually narrow their scope, guessing which files might contain the relevant data before running a query. This guesswork made the search process slow and unreliable.
The Flexibility Gap
FAISS isn’t a database—it’s a library. It’s fine for finding the nearest neighbors for a given vector, but production-grade search systems require far more than just fast similarity matching.
In practice, engineers didn’t want to search the entire corpus at once. They needed contextual filtering—to find, for example, “front-facing camera frames captured in light rain on urban roads,” or “nighttime drives from California highways.” Achieving that level of precision required combining vector search with metadata filters such as camera type, time, location, weather, and model version. But FAISS didn’t provide these capabilities out of the box. To bridge the gap, the team had to build a complex stack of custom logic: separate metadata databases, bespoke query planners to decide which FAISS indices to scan, and manual post-filtering of results after retrieval.
Over time, these customizations created a major scaling problem. Different camera angles, multiple embedding models, and versioned preprocessing pipelines all demanded distinct management strategies. There was no built-in concept of collections, partitions, or logical data grouping—only index files. Every layer of organization, from data versioning to query filtering, had to be written and maintained in custom code. The system worked—but at the cost of flexibility, maintainability, and long-term scalability.
The Scalability Problem
The system was already straining under billions of vectors, and the company’s test vehicles were generating new data every day. Meanwhile, research teams were introducing new embedding models, each requiring large-scale re-indexing of historical data. It was only a matter of time before workloads grew tenfold, but the file-based FAISS setup had no practical way to scale to that level.
What’s worse, every new dataset meant more index files and more manual updates to metadata storage. There was no automatic sharding, no built-in load balancing, and no way to add capacity on demand. The architecture had become antiquated —static, labor-intensive, and resistant to growth.
The Hidden Engineering Costs
Beyond cloud costs, the biggest challenge was the hidden engineering overhead of maintaining FAISS. Engineers had to manage complex metadata systems, design custom logic for distributing data, and manually update millions of index files. Over time, this overhead slowed innovation: search performance degraded, development cycles stretched longer, and new ideas never got past the whiteboard. As data volumes continued to grow, the system became increasingly rigid and fragile. It was clear that attempting to upgrade the legacy setup was no longer sustainable.
The Solution: Re-Architecting for Scale with Milvus
To overcome these challenges, the AV Data team required a system capable of handling tens of billions of vectors today, with a clear path to 10× growth and beyond. It had to provide robust filtering, operational simplicity, and—above all—production reliability with minimal maintenance.
The Evaluation Process
Instead of running a broad bake-off across every emerging vector database, the team focused on the popular Milvus Vector Database, running a proof-of-concept with 400–500 million vectors—large enough to expose real-world bottlenecks. During testing, the engineers replicated their full data workflow: indexing datasets with different index types to compare trade-offs, measuring indexing time to estimate daily batch updates, and benchmarking latency under realistic filter combinations and query patterns. They deliberately pushed Milvus to its limits, running complex multi-condition searches and scaling data volumes to test stability.
Why Milvus?
The proof-of-concept results made Milvus the clear choice for the AV Data team.
Acceptable query performance: Milvus consistently delivered second-level query latencies for even the most complex, filter-heavy searches—well within requirements for internal data-mining workloads.
Native filtering and query flexibility: Engineers could now combine vector similarity search with metadata filters in a single query—capabilities that previously required extensive custom code in FAISS.
Organized data structure: Vector embeddings from different models were stored in separate collections, each partitioned by attributes such as capture date or region. Milvus automatically managed data distribution across segments, removing the burden of manual file management.
Seamless scalability: As data grew, the team added more nodes to expand capacity. Milvus’s distributed architecture scaled linearly without requiring system redesigns.
Active open-source community: During testing, the AV Data engineers received prompt, hands-on support from the Milvus team and community contributors, building strong confidence in Milvus as a trusted, production-ready ecosystem.
Implementing the New Architecture with Milvus
At its core, the architecture of this multimodal data mining system is simple—but executing it at massive scale requires careful engineering and precision. Raw video data from autonomous vehicle drives—hours of continuous footage from multiple cameras—flows into a processing pipeline that extracts individual frames or short clips, typically a few seconds long.
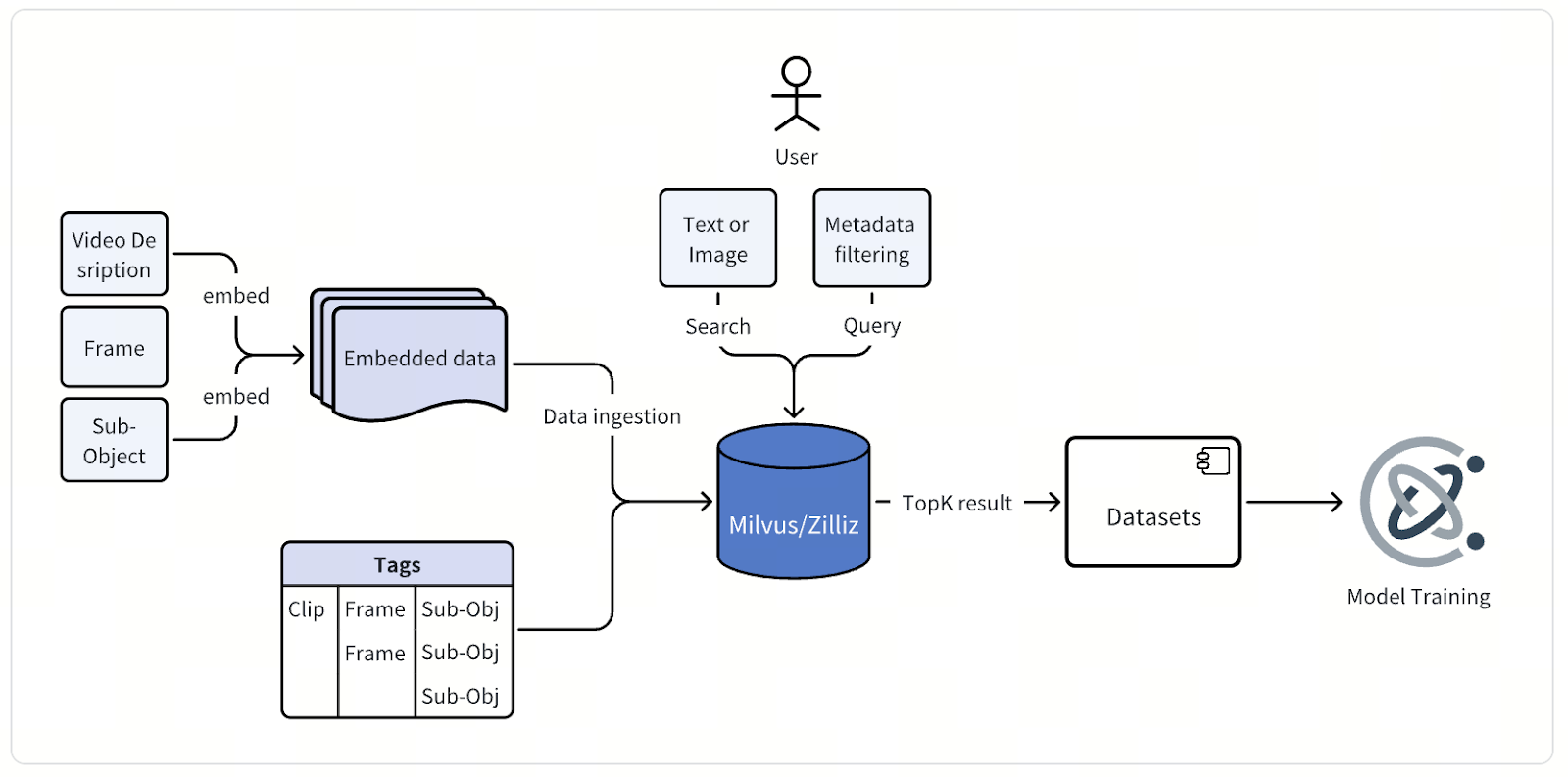
Each frame or clip then passes through the company’s proprietary embedding models, purpose-built for autonomous driving. For image data, the team uses models derived from the CLIP architecture, customized and fine-tuned to capture road-specific semantics. For video data, they rely on their own homemade models, a family of foundation models for physical AI applications. Together, these models convert visual data into high-dimensional vector embeddings that encode rich contextual meaning.
Once generated, these vector embeddings—along with detailed metadata—are stored and indexed into the Milvus Vector Database. Each data point carries attributes describing the drive session, camera position, timestamp, vehicle state, location, and weather conditions, among others. This metadata is also indexed to enable fast and precise filtered searches across massive datasets.
Through a unified query interface, engineers can search the data in multiple ways. They can type a text description, upload a reference image or video, or combine vector search with metadata filters to pinpoint exactly what they need. A single query might ask, for instance, for “urban intersections at night with pedestrians crossing,” and Milvus returns the most relevant frames or clips for review, analysis, and model improvement.
The Benefits: Cost Efficiency, Stability, and Scale
After more than a year in continuous operation, Milvus has proven itself not only technically sound but operationally transformative. The following outcomes capture how its architecture and ecosystem translated into real-world efficiency at scale.
Simpler Operations, Fewer Headaches, and Faster Development
Migrating from hundreds of thousands of FAISS files to Milvus removed an entire layer of operational overhead. There’s no more manual index file management, no ad-hoc scripts, and no custom query logic. Data distribution, segment management, and query routing now happen automatically. Upgrades are straightforward, monitoring is unified, and metrics tell a clear story. The result is less time spent maintaining systems and more time mining data for insights.
Lower Engineering Overhead Plus 30% Additional Cost Reduction After Upgrading to Milvus 2.5
Deploying Milvus immediately reduced both infrastructure and engineering costs. The move away from FAISS’s file-based system eliminated manual file management and complex metadata tracking, saving significant developer time and operational effort. Upgrading from Milvus 2.4 to Milvus 2.5 then delivered an additional 30% reduction in infrastructure costs, thanks to smarter memory mapping, disk-based primary key storage, and more efficient segment management.
Together, these improvements allow the AV Data team to run the same workloads on smaller AWS instances—or index far more data—without increasing spend or maintenance overhead. Encouraged by these results, the team plans to test Milvus 2.6, which introduces new index types like RaBitQ and further optimizations expected to push both performance and cost efficiency even further. For large offline batch workloads, index build speed remains a core challenge. Thanks to contributions from the NVIDIA cuVS team, Milvus now supports GPU-accelerated index builds with CPU-based serving (GPU-build, CPU-serve). This approach significantly accelerates index construction while maintaining cost efficiency — and is expected to further enhance Milvus’s price-performance advantage in autonomous driving workloads.
Built-In Scalability, Proven in Practice
The platform now indexes tens of billions of vectors and ingests new data daily with no friction. Internal modeling confirms it can scale 10× further without redesign or cost surprises—turning what was once a capacity constraint into a long-term strategic advantage. With this headroom, the team can expand from indexing two years of recent driving data to covering the entire historical archive, enabling search across every drive session ever recorded. They can also run multiple embedding models in parallel to optimize retrieval for different query types and even retain data indefinitely instead of aging it out. Scalability here means not just handling more data, but enabling continuous learning and faster progress toward safer autonomous driving.
Enterprise Reliability at Massive Scale
In more than a year of nonstop production, Milvus has quietly handled tens of billions of vectors with daily ingestion and querying—without a single major incident. The system runs steadily in the background, requiring minimal oversight. No weekend outages, no emergency patches—just consistent, predictable performance. That kind of reliability at this scale translates into fewer operational risks, less firefighting, and more focus on building value rather than managing infrastructure.
Richer Search, Smarter Workflows
Milvus combines vector search with metadata filtering, giving the company’s engineers new ways to analyze complex driving data. They can, for example, find all construction-zone images captured from front-facing cameras in daylight or filter by time and location to compare model behavior across updates and regions. Different collections hold embeddings from different models, allowing teams to test new architectures without impacting production. These capabilities accelerate experimentation and uncover insights that previously required extensive custom engineering.
A Strong Community That Multiplies Impact
Beyond the technology, the Milvus open-source community has been a major part of the company’s success. During testing and deployment, engineers received quick support directly from Milvus contributors and maintainers. This responsiveness reduced downtime, sped up debugging, and kept progress on track. Over time, the active community has continued to add value by helping validate new ideas, smooth out upgrades, and share best practices. For this customer, Milvus isn’t just reliable software—it’s a collaborative ecosystem that strengthens the platform and delivers long-term efficiency.
Lessons from Production
Choosing the Right Index: Balancing Scale, Cost, and Accuracy
Choosing an index is one of the most important practical decisions when building a vector search system. Milvus supports many index types, each with its own trade-offs in speed, memory use, and accuracy. For the AV Data team, the goal was to find a balance between data scale, infrastructure cost, and search accuracy—not just pick the fastest option.
After testing several configurations, they selected IVF_FLAT, which groups vectors into clusters and performs an exact search within the relevant ones. It isn’t the quickest or most compact option, but for tens of billions of vectors and moderate latency needs, it delivered the right mix of performance and accuracy while staying efficient.
The team found that once an index nicely fits the workload, there’s rarely a need to switch to something newer. In practice, a well-matched index saves more time and resources than chasing small performance gains. For large-scale systems, steady and predictable performance is what keeps operations smooth.
Memory Mapping: Trading Latency for Cost at Scale
One of the team’s most effective technical choices was using memory mapping (Mmap) to control infrastructure costs. In traditional setups, keeping all vector data in RAM would require massive, high-cost instances. With memory mapping in Milvus, most data stays on disk while the operating system automatically keeps frequently accessed portions in memory. This design introduces some latency—disk reads are slower than RAM—but it maintains predictable performance and efficient resource use. For the company’s workload, that trade-off made perfect sense. Their users are engineers running analytical queries, not end users expecting instant responses, and concurrency stays low.
Delete Operations: When Small Assumptions Break at Scale
One of the team’s biggest lessons came from something that seemed simple: deleting data. In Milvus’s append-only architecture, deleted vectors aren’t removed right away—they’re marked for deletion and cleaned up later through background compaction. During testing, deleting millions of vectors unexpectedly triggered the reindexing of billions, as Bloom filters produced false positives across thousands of segments. What appeared to be a routine cleanup ended up overloading data nodes and stalling jobs.
The fix came from understanding how Milvus manages data and adjusting their workflow—tuning Bloom filters, using partition keys to target deletions precisely, and switching to insert-only bulk loading. The takeaway: at scale, even simple operations can behave differently, and understanding the system’s internals is key to keeping performance predictable.
Looking Forward
The team is preparing to adopt Milvus 2.6 shortly after release, confident that new index types and architectural optimizations will deliver another leap in efficiency. Early discussions with the Milvus engineering team point to continued cost reductions and improved resource utilization, which the company plans to validate through full-scale benchmarks.
Looking further ahead, the team sees exciting opportunities to expand functionality and scale. Features such as hybrid search, which blends text and vector queries, could unlock new ways to explore multimodal data, while enhanced database-style filters will simplify complex workflows. The upcoming Milvus 3.0 release also holds promise for tiered architectures, enabling the company to keep fast access to recent data while storing its full historical archive efficiently. Together, these advances will give the company a data platform that scales effortlessly, supports deeper search capabilities, and grows more efficiently.
In addition, the introduction and maturation of NVIDIA cuVS-powered GPU-accelerated index builds with CPU-based serving (GPU-build, CPU-serve) in Milvus is expected to deliver a step-change improvement in offline indexing performance. By leveraging NVIDIA GPUs and the highly optimized cuVS libraries, Milvus can build large-scale vector indexes dramatically faster than CPU-only pipelines, while continuing to serve queries cost-efficiently on CPU. This significantly shortens data-to-query time, enables more frequent index refresh cycles, and further amplifies Milvus’s price-performance advantage for autonomous driving and other large-scale multimodal workloads where rapid iteration and fresh data are critical.
Conclusion
The customer’s AV Data team has built a powerful data mining platform that accelerates autonomous driving development by making massive volumes of multimodal data searchable and actionable. The migration from FAISS to Milvus resolved critical challenges in scalability, flexibility, and operational complexity—while delivering measurable cost savings and remarkable production stability.
After more than a year of continuous operation and tens of billions of indexed vectors, the platform has proven that Milvus can serve as a production-grade foundation for large-scale, domain-specific vector search. The system ingests new data daily, supports engineers across the company’s autonomous driving programs, and offers a clear path to scale 10× further without re-architecture.
For organizations building vector search systems with massive data scale, cost efficiency matters, and stability outweighs sub-millisecond latency. The company’ss experience is instructive. Milvus demonstrates that an open-source vector database can not only meet the demands of production but continue to improve over time—delivering a dependable, scalable, and future-ready backbone for real-world AI infrastructure.