




Zilliz attended VLDB Workshop 2021
What are the major breakthroughs in database industry in 2021?
This August, Zilliz was invited to VLDB Workshop 2021 to share its latest research progress and achievement in applying machine learning methods to database systems in company with Harvard University, Carnegie Mellon University, Tsinghua University, Microsoft and many other organizations. Zilliz senior researcher, Dr. Xiaomeng Yi introduced the development background, design ideas, challenges and technological innovations during the development of Milvus, an open source vector database.
VLDB, SIGMOD and ICDE are known as the three most prestigious conferences in the database field. Recently, the research result by Zilliz research team, Milvus: A Purpose Built Vector Data Management System, was selected by SIGMOD and included as one of the 21 papers this year due to the excellent underlying functionality and perfect application in business scenarios of Milvus.
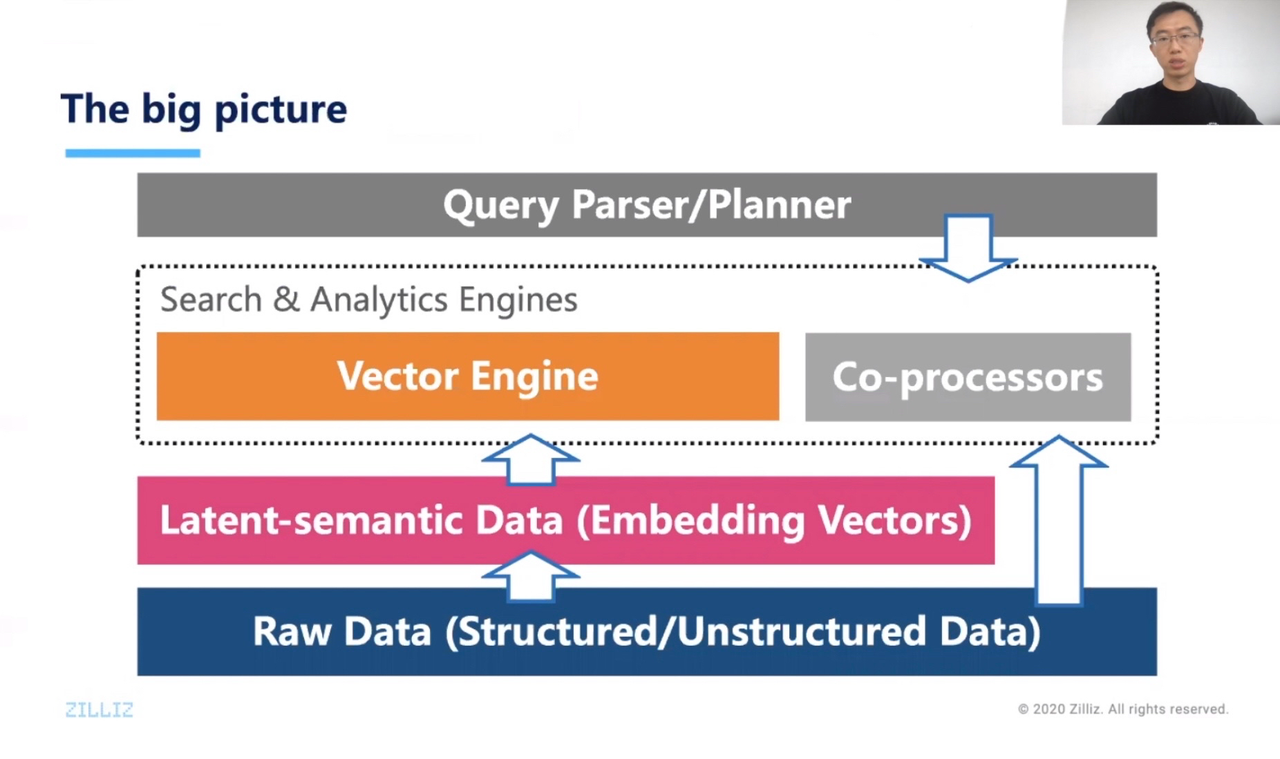
Every day, the world produces a huge amount data, of which more than 80% is unstructured data that is difficult to process. Whereas traditional databases can only store structured data, the Milvus engineer team proposed a hypothesis: all data can be uniformly represented by vectors at the semantic level regardless of the data types. Dr. Yi remarked that if the AI neural network model is used to extract the semantics of data and present them uniformly as vectors, the processing logic of many data can be directly executed on the level of vectors.
Milvus is designed specifically for analysis and retrieval of massive feature vectors. It provides a complete framework for vector data update, indexing and similarity search, which not only can be performed in real time on streaming data, but also meets the diverse search requirements in actual business scenarios. Until now, Milvus has released two versions: 1.0 and 2.0. The source code of Milvus is completely open source on GitHub and has been widely used in the frontier fields of artificial intelligence. Tested by 1,000 users around the world, its performance greatly surpasses the peer products.
 VLDB
VLDB
In the sharing, Dr. Yi introduced the design concept of Milvus 2.0: cloud-native, log-as-data, and unified batch-and-stream processing. On the basis of its predecessor, Milvus 2.0 provides users with an intelligent, stable and smooth search experience.
Facing the two major challenges of index selection and data tuning in database development, Dr. Yi believes that AI can open doors to best solutions. For example, new configuration can be first tested and evaluated on a small dataset, and then transferred to a large dataset. Use machine learning to analyze the existing dataset, and guide the configuration of the new dataset, so as to achieve better performance than that of the current BOHB algorithm.
Dr. Xiaomeng Yi (Ph.D. of Computer Architecture, Huazhong University of Science and Technology), Senior Researcher and Research team leader of Zilliz. His research concentrates on high-dimension data management, large-scale information retrieval, and resource allocation in distributed systems. Dr. Yi's research works have been published on leading journals and international conferences including IEEE Network Magazine, IEEE/ACM TON, ACM SIGMOD, IEEE ICDCS, and ACM TOMPECS.
Keep Reading

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.