




Metrics-Driven Development of RAGs
In a recent presentation at the Zilliz Unstructured Data Meetup, Jithin James and Shahul Es, maintainers of Ragas, shared insights on leveraging metrics-driven development to evaluate Retrieval Augmented Generation (RAG) systems. Developers can tweak their systems based on the evaluation results for better performance.
In their talk, Jithin and Shahul discussed both the theoretical foundations and practical applications of RAG system evaluation. They explained how understanding the theory behind the evaluation code can provide deeper insights into its functionality. Following this part, they demonstrated the evaluation process using an actual RAG system powered by Milvus, a leading open-source vector database known for its efficiency in similarity search and AI applications.
For a more detailed understanding, watch the replay of the meetup talk.
How to Evaluate the Performance of RAG Systems
Shahul touched on how Ragas computes the truthfulness of an answer generated by the RAG system. This is a crucial evaluation metric, as the answer is what the end user sees. Let’s slow that down a bit and take a deep dive. Ragas uses the following formula to compute the truthfulness of an answer:
 Fig 1- Ragas answer_truthfulness metric computation formula
Fig 1- Ragas answer_truthfulness metric computation formula
Calculating Answer Correctness in Retrieval-Augmented Generation (RAG) Systems
The process involves two main metrics: factual similarity and semantic similarity. These metrics help determine the quality and relevance of the generated answer compared to the ground truth.
Key Metrics
Factual Similarity:
- This metric measures the factual correctness of the generated answer by comparing the presence of factual information between the ground truth and the generated answer.
Semantic Similarity:
- This metric measures how semantically similar the generated answer is to the ground truth, ensuring that the meaning conveyed by the generated answer aligns with the ground truth.
Steps to Calculate Answer Correctness
Identify True Positives (TP), False Positives (FP), and False Negatives (FN):
True Positives: Statements correctly present in both the ground truth and the generated answer.
False Positives: Statements present in the generated answer but not in the ground truth.
False Negatives: Statements present in the ground truth but not in the generated answer.
Calculate the F1 Score:
- The F1 score is a mean of precision and recall, providing a balance between the two. The formula for the F1 score is shown in Figure 1.
Practical Example
Consider a ground truth statement and a generated answer:
Ground Truth: "Alan Turing developed the concept of the Turing machine."
Generated Answer: "Alan Turing is known for developing the concept of the Turing machine and artificial intelligence."
Step 1: Identify TP, FP, and FN
True Positives (TP):
- "Alan Turing developed the concept of the Turing machine."
False Positives (FP):
- "Alan Turing is known for developing artificial intelligence."
False Negatives (FN):
- None (since the generated answer includes all elements of the ground truth).
Step 2: Calculate the F1 Score
TP = 1
FP = 1
FN = 0
F1 = 1 / (1 + 0.5 * (1 + 0))
= 1 / 1.5
≈ 0.67
Interpretation<
Factual Similarity: The generated answer is factually correct as it includes the essential information from the ground truth.
Semantic Similarity: The generated answer maintains semantic alignment with the ground truth, though it includes additional information.
The F1 score combines these aspects to provide a measure of answer correctness, balancing precision, and recall. This method helps evaluate how well the generated answer matches the ground truth in terms of both factual content and overall meaning.
But answer truthfulness is not the only metric that you can use to evaluate your rag systems. Other metrics are faithfulness, answer relevancy, context recall, and context precision. Let’s take a practical look at how you can evaluate and improve a Mivus-powered RAG system.
Evaluating and Improving a Milvus-Powered RAG System
Now that you have understood the theoretical basis for evaluating RAG systems, let's dive into a practical RAG example built with the Milvus vector database. We'll walk through setting up, implementing, and evaluating a RAG system. Based on the results, we will then look at how we can improve the system.
Setting Up the Environment
First, we need to set up our development environment. To do so, first, install all the required libraries:
!pip install pymilvus[model] ragas langchain langchain_openai python-dotenv nest_asyncio pypdf langchain_community
Let’s break down what the use of each library will be in the code:
Pymilvus[model]will help you connect to Milvus, create collections, insert data, and perform similarity searches.Ragaswill provide evaluation metrics, generate synthetic test sets, and evaluate RAG pipelines.Langchainwill Load documents, split them into chunks, and prepare text data for embedding and querying.Langchain_openaiwill interface with OpenAI models, generate embeddings, and answer questions using API calls.Python-dotenvwill Load environment variables from a .env file to manage sensitive information like API keys.Nest_asynciowill enable nested asynchronous operations within synchronous environments. Especially if you are using Jupiter notebooks.Pypdfwill load PDF documents, extract content, and prepare text for processing.Langchain_communitywill provide additional document loaders and utilities for integrating community-contributed resources. After installing the libraries, import them into your code and configure your API keys:
import os
import pandas as pd
import nest_asyncio
import openai
from pymilvus import MilvusClient, model
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
answer_correctness,
)
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_community.document_loaders import DirectoryLoader
from langchain.document_loaders import PyPDFLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from dotenv import load_dotenv
from datasets import Dataset
# Load environment variables
# Apply nest_asyncio to allow nested event loops
nest_asyncio.apply()
# Set up OpenAI API key
os.environ["OPENAI_API_KEY"] = "Your API Key"
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Importing the libraries and modules into the code will allow you to call and use their functions. The OpenAI key will help you authenticate yourself to OpenAI while making API calls. If you don’t have one, head to the OpenAI API page and generate one.
Loading and Preparing Documents
Next, we'll load our documents and prepare them for processing:
# Load PDF documents from a directory
pdf_loader = DirectoryLoader("/content/data", loader_cls=PyPDFLoader)
documents = pdf_loader.load()
# Ensure each document has a filename in its metadata
for document in documents:
document.metadata['filename'] = document.metadata['source'
The code loads PDF documents from a directory using the PyPDFLoader class. It then creates a DirectoryLoader instance, loads the documents, and iterates through each document to add a filename attribute to its metadata. This ensures each document is properly identified and managed with its corresponding filename. This step is crucial as it forms the knowledge base for our RAG system. We're using PDF documents in this example, but you could adapt this to other document types as needed.
Generating a Test Set
Now that you have loaded the data, you need a diverse set of test questions to help effectively evaluate our RAG system. We'll use the Ragas framework to generate a synthetic test set.
# Initialize OpenAI models for test set generation
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
# Create a TestsetGenerator
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Generate synthetic test set with 10 samples
testset = generator.generate_with_langchain_docs(documents, test_size=10, distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25})
# Convert test set to Pandas DataFrame
testset_df = testset.to_pandas()
print(testset_df)
This code initializes two language models (gpt-3.5-turbo-16k for generating test sets and gpt-4 for evaluation) and an embedding model from OpenAI. It then creates a TestsetGenerator instance using these models. The generator produces a synthetic test set of 10 samples from the loaded PDF documents, with specified distributions for different types of questions. This test set will help you assess various aspects of your RAG system's performance, including its ability to handle simple queries, reasoning tasks, and questions requiring multiple contexts. Here is an example of a generated test set.
 Fig 2- Test set generated using Ragas
Fig 2- Test set generated using Ragas
The ground truth is the actual answer to a given question. We will later use it to measure how well our RAG system is doing by how close its output is to these ground answers. As Shahul points out in the talk, generating the synthetic test set using Ragas does not mean you use it blindly. You have to have to filter out and use the samples you need.
Since you have the test set let's build a simple RAG system powered by Milvus and then evaluate it using the above test set.
Setting Up Milvus and Inserting Document Embeddings
Now, let's set up our Milvus vector database and insert our document embeddings. Ensure you have Milvus installed and running. If not, follow this Milvus installation comprehensive guide.
# Connect to Milvus instance
milvus_client = MilvusClient(uri="http://localhost:19530")
# Define collection name
collection_name = "pdf_collection"
# Drop the collection if it already exists
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
# Create a new collection
milvus_client.create_collection(
collection_name=collection_name,
dimension=768, # Dimension of vectors
overwrite=True
)
# Initialize the embedding function
embedding_fn = model.DefaultEmbeddingFunction()
# Extract document texts and generate embeddings
expanded_docs = [doc.page_content for doc in documents]
expanded_vectors = embedding_fn.encode_documents(expanded_docs)
# Prepare data for insertion
expanded_data = [
{"id": i, "vector": expanded_vectors[i], "text": expanded_docs[i], "subject": "pdf_documents"}
for i in range(len(expanded_vectors))
]
# Insert expanded data into the collection
milvus_client.insert(data=expanded_data, collection_name=collection_name)
The above code connects to a Milvus instance and sets up a collection named pdf_collection for storing document vectors. If the collection already exists, it drops and recreates it with a dimension of 768 for the vectors. It initializes an embedding function, extracts text from loaded documents, and generates their embeddings. The code then prepares the data with embeddings and associated text and inserts this data into the Milvus collection. This step is where Milvus really shines as it allows you to perform fast and efficient similarity searches on the stored data embeddings which is crucial for the retrieval part of your RAG system.
Performing Similarity Search
With your documents indexed in Milvus, you can now perform similarity searches to retrieve relevant contexts for our questions:
# Define the search parameters
search_params = {"metric_type": "COSINE", "params": {"nprobe": 20}} # nprobe for better recall
# Perform the search
query_vectors = embedding_fn.encode_queries(testset_df['question'].tolist())
results = milvus_client.search(
collection_name=collection_name,
data=query_vectors,
anns_field="vector", # specify the vector field name
search_params=search_params,
limit=3, # number of top results to retrieve
output_fields=["id", "text"]
)
The above code sets up search parameters for the Milvus collection using cosine similarity and a nprobe value of 20 for better recall. It encodes the test set questions into query vectors and performs a search in the pdf_collection collection, retrieving the top three most similar vectors for each query. The search results include the IDs and text of the matching documents.
Generating Answers Using a Large Language Model
With the relevant contexts retrieved, you can now generate answers using a language model. In this case, we will use GPT 3.5 turbo.
# Function to generate answers using OpenAI
def generate_answer(question, contexts):
context_text = " ".join(contexts)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Context: {context_text}nnQuestion: {question}nAnswer:"}
]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
max_tokens=100,
temperature=0.7,
)
return response.choices[0].message.content.strip()
# Extract contexts and generate answers using OpenAI
contexts = []
answers = []
for i, result in enumerate(results):
context = [match['entity']['text'] for match in result]
contexts.append(context)
question = testset_df['question'].iloc[i]
answer = generate_answer(question, context)
answers.append(answer)
The code defines a generate_answer function that uses OpenAI's gpt-3.5-turbo model to generate answers based on a given question and context. It prepares messages for the API call, concatenates the context, and queries the model. It then extracts and returns the generated answer. The subsequent loop iterates through the search results and uses the generate_answer function to generate answers for each question in the test set, storing the contexts and answers in lists. The questions used in the loop to generate answers are the same ones generated in the test set.
Since you now have the RAG system-generated answers and the ground truth answers, let's evaluate how well the RAG system is doing.
Evaluating the RAG System
Finally, we'll evaluate the performance of our RAG system using the metrics discussed earlier:
# Ensure all lists are the same length
min_length = min(len(testset_df['question']), len(testset_df['ground_truth']), len(answers), len(contexts))
questions = testset_df['question'][:min_length]
ground_truths = testset_df['ground_truth'][:min_length]
answers = answers[:min_length]
contexts = contexts[:min_length]
# Create the dataset with correct column names
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
from datasets import Dataset
# Convert dict to dataset
dataset = Dataset.from_pandas(pd.DataFrame(data))
# Evaluate using RAGAS
metrics = evaluate(
dataset=dataset,
metrics=[
answer_correctness,
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
raise_exceptions=False #handle async issues
)
# Convert result to DataFrame for better readability
result_df = metrics.to_pandas()
print(result_df)
The code ensures consistency in the evaluation process by trimming all relevant lists to the same minimum length. This prevents mismatched lengths that could cause errors during evaluation. It then creates a dictionary with these trimmed lists and converts it into a Pandas DataFrame, which is then transformed into a Hugging Face Dataset. This structured dataset allows for systematic evaluation using the RAGAS framework which compares the generated answers from the ground truths. The evaluation metrics (answer correctness, context precision, context recall, faithfulness, and answer relevancy) provide an assessment of the RAG pipeline's performance.
Take a look at the evaluation results below:
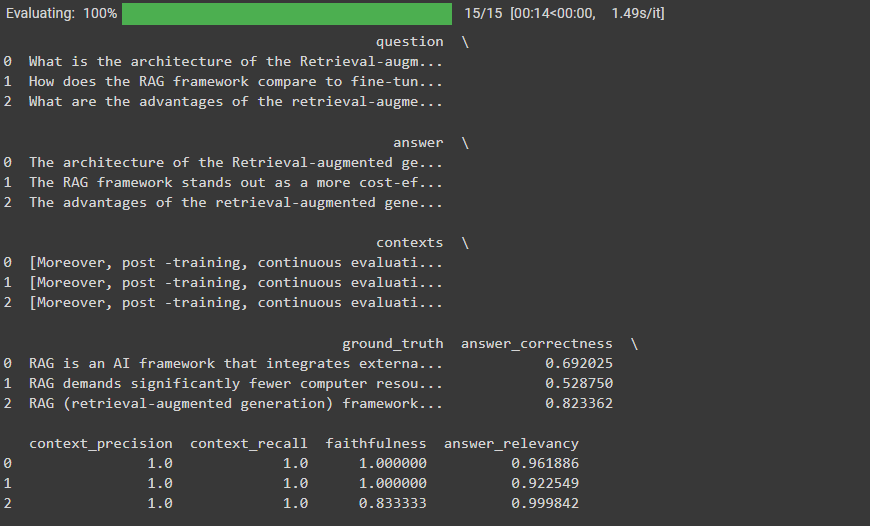 Fig 3- Ragas RAG system evaluation results
Fig 3- Ragas RAG system evaluation results
The context precision of our RAG system and recall is excellent and the answer relevancy is commendable. But the answer correctness is fairly low.
The retrieval side is good due to excellent context recall and precision. So we can conclude that the generation part might be affecting our answer correctness. To improve this, you can use a more powerful answer generation model like GPT-4.
Conclusion
Evaluating and improving Retrieval-Augmented Generation (RAG) systems is a nuanced but essential task in the realm of AI-driven information retrieval. By leveraging a metrics-driven approach, as demonstrated by Jithin James and Shahul Es, you can systematically refine your RAG systems to ensure they deliver accurate, relevant, and trustworthy information.
For more details about this topic, watch the talk’s replay on YouTube.
Further Resources
Keep Reading

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.