RAG Evaluation Tools: How to Evaluate Retrieval Augmented Generation Applications
RAG)), or Retrieval Augmented Generation, is a prominent AI framework in the era of large language models (LLMs))) like ChatGPT. It enhances the capabilities of these models by integrating external knowledge, ensuring more accurate and current responses. A standard RAG system includes an LLM, a vector database like Milvus, and some prompts as code, all of which can be assessed using a comprehensive rag evaluation framework.
As more and more developers and businesses adopt RAG for building GenAI applications, evaluating their effectiveness is becoming increasingly important. In a previous post, we evaluated the performance of two different RAG systems built with the OpenAI Assistants and the Milvus vector database, which shed some light on assessing RAG systems. This post will dive deeper and discuss the methodologies used to evaluate RAG applications. We’ll also introduce some powerful evaluation tools and highlight standard metrics.
Evaluating RAG applications is more than simply comparing a few examples. The key lies in using convincing, quantitative, and reproducible metrics to assess these applications. In this journey, we’ll introduce three categories of metrics:
Metrics based on the ground truth
Metrics without the ground truth
Metrics based on LLM responses
Ground truth refers to well-established answers or knowledge document chunks in a dataset corresponding to user queries. When the ground truth is the answers, we can directly compare the ground truth with the RAG responses, facilitating an end-to-end measurement using metrics like answer semantic similarity and answer correctness.
Below is an example of evaluating answers based on their correctness.
Ground truth: Einstein was born in 1879 in Germany.
High answer correctness: In 1879, in Germany, Einstein was born.
Low answer correctness: In Spain, Einstein was born in 1879.
Where ground truth is chunks from the knowledge document, we can evaluate the correlation between the document chunks and the retrieved contexts using traditional metrics such as Exact Match (EM), Rouge-L, and F1. In essence, we are evaluating the retrieval effectiveness of RAG applications.
We have now established the importance of using datasets with the ground truth for evaluating RAG applications. However, what if you want to assess a RAG application using your private datasets without annotated ground truth? How do you generate the required ground truth for your datasets?
The simplest method is to ask an LLM like ChatGPT to generate sample questions and answers based on your proprietary dataset. Tools like Ragas and LlamaIndex also provide methods for generating test data tailored to your knowledge documents.

_The sample questions and answers generated by Ragas evaluation tool (source: https://docs.ragas.io/en/latest/concepts/testset_generation.html)
These generated test datasets, comprising questions, context, and corresponding answers, facilitate quantitative evaluation without reliance on unrelated external baseline datasets. This approach empowers users to assess RAG systems using their unique data, ensuring a more customized and meaningful evaluation process.
Metrics without the ground truth
We can still evaluate RAG applications without a ground truth for each query. TruLens-Eval, an open-source evaluation tool, innovates the concept of the RAG Triad, which focuses on evaluating the relevance of elements in the query, context, and response triplets. Three corresponding metrics are:
Context Relevance: Measures how well the retrieved context supports the query.
Groundedness: Assesses the extent to which the LLM's response aligns with the retrieved context.
Answer Relevance: Gauges the relevance of the final response to the query.
Below is an example of evaluating answers based on their relevance to the question.
Question: Where is France and what is its capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
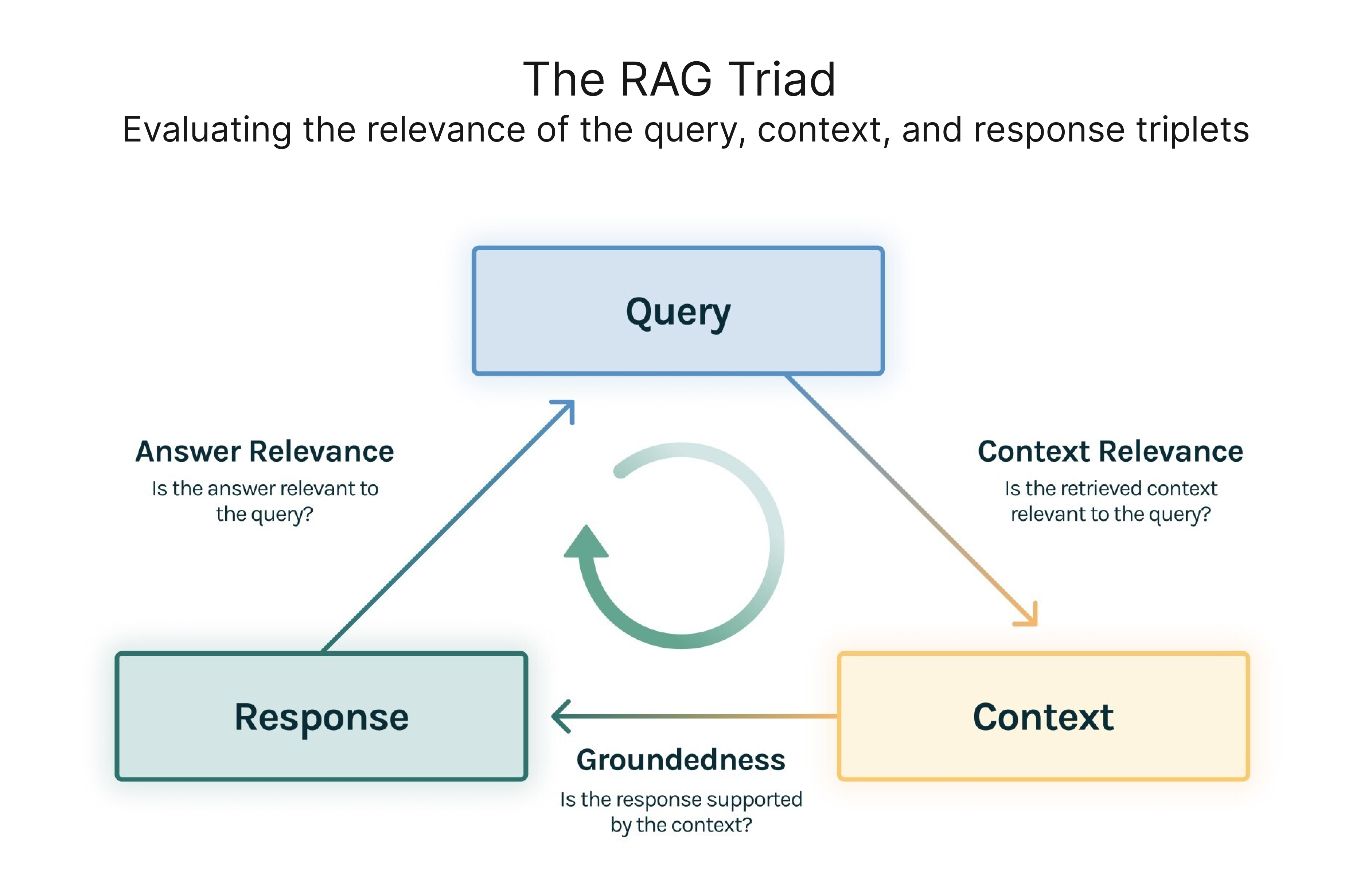
RAG Triad, source: https://www.trulens.org/getting_started/core_concepts/rag_triad/
Additionally, these triad metrics can be further subdivided, enhancing the granularity of evaluation. For example, Ragas (an open-source framework dedicated to evaluating the performance of RAG systems) has split context relevancy into three further detailed metrics: context precision, context relevance, and context recall.
This category of metrics evaluates LLM responses, considering factors such as friendliness, harmfulness, and conciseness. For example, proposes metrics such as conciseness, relevance, correctness, coherence, harmfulness, maliciousness, helpfulness, controversiality, misogyny, criminality, and insensitivity.
Below is an example of evaluating answers based on their conciseness.
Question: What's 2+2?
Low conciseness answer: What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.
High conciseness answer: 4
Using LLMs to score the metrics
Most metrics mentioned earlier require inputting text to obtain a score, which takes work. The good news is that this process becomes more manageable with the advent of LLMs like GPT-4, where all you need to do is design a suitable prompt.
The paper "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" proposes a prompt design for GPT-4 to judge the quality of an AI assistant's response to a user question. Below is a quick example:
[System]
Please act as an impartial judge and evaluate the quality of the response provided by an AI assistant to the user question displayed below. Your evaluation should consider factors such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of the response. Begin your evaluation by providing a short explanation. Be as objective as possible. After providing your explanation, please rate the response on a scale of 1 to 10 by strictly following this format: "[[rating]]", for example: "Rating: [[5]]".
[Question]
{question}
[The Start of Assistant's Answer]
{answer}
[The End of Assistant's Answer]
This prompt asks GPT-4 to evaluate the response quality and rate them on a scale of 1 to 10.
It is important to note that GPT-4, like any judge, is not infallible and might have biases and potential errors. So, prompt design is crucial. Advanced prompt engineering techniques such as multi-shot or Chain-of-Thought (CoT) may be necessary. Fortunately, we don’t have to worry about this problem because many evaluation tools for RAG applications have already integrated well-designed prompts.
Now that we have covered evaluating a RAG application, let's explore some tools for assessing RAG applications, offering insights into how they work and what use case fits these tools best.
Ragas: streamlined RAG evaluation
Ragas is an open-source evaluation tool for assessing RAG applications. With a simple interface, Ragas streamlines the evaluation process. By creating a dataset instance in the required format, users can quickly initiate evaluations and obtain metrics such as 'ragas_score,' 'context_precision,' 'faithfulness,' and 'answer_relevancy.'
from ragas import evaluate
from datasets import Dataset
# prepare your huggingface dataset in the format
# Dataset({
# features: ['question', 'contexts', 'answer', 'ground_truths'],
# num_rows: 25
# })
dataset: Dataset
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_precision': 0.817,
# 'faithfulness': 0.892, 'answer_relevancy': 0.874}
Ragas supports a variety of metrics and imposes no specific framework requirements, offering flexibility in evaluating different RAG applications. Ragas enables real-time monitoring of evaluations via LangSmith, offering insights into each assessment's reasons and API key consumption.
Understanding RAG Systems
Retrieval Augmented Generation (RAG) systems are a type of artificial intelligence (AI) technology that combines the strengths of large language models (LLMs) with external knowledge retrieval. RAG systems consist of three main components: Index, Retrieve, and Generate. The Index component creates a database of knowledge that can be searched and retrieved. The Retrieve component retrieves relevant information from the indexed database. The Generate component creates new text based on the retrieved information.
RAG systems are commonly used for chatbots and question-answering systems. They provide a robust and dynamic approach to AI conversations and information processing. By leveraging external knowledge, RAG systems enable more accurate, contextual, relevant, and up-to-date responses. This makes them invaluable in various domains, including customer service and internal knowledge chatbots, where precise and timely information is crucial.
Evaluation Metrics for RAG
Evaluating the performance of RAG systems is crucial for their reliability and performance. There are several evaluation metrics for RAG systems, including:
Context Relevance: Measures the relevance of the retrieved context to the user’s query.
Context Recall: Measures the proportion of relevant context retrieved by the system.
Faithfulness: Measures the accuracy of the generated text based on the retrieved context.
Answer Relevance: Gauges the relevance of the generated text to the user’s query.
Answer Correctness: Assesses the accuracy of the generated text.
These metrics provide a comprehensive framework for evaluating the performance of RAG systems. By analyzing these aspects, developers can identify areas for improvement and ensure that the system delivers high-quality, relevant, and accurate responses.
LlamaIndex: building and evaluating with ease
LlamaIndex is a robust AI framework for building RAG applications, including an RAG evaluation tool. It is handy for assessing applications built within its framework.
from llama_index.evaluation import BatchEvalRunner
from llama_index.evaluation import (
FaithfulnessEvaluator,
RelevancyEvaluator,
)
service_context_gpt4 = ...
vector_index = ...
question_list = ...
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
runner = BatchEvalRunner(
{"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4},
workers=8,
)
eval_results = runner.evaluate_queries(
vector_index.as_query_engine(), queries=question_list
)
TruLens-Eval: integrated evaluation for diverse frameworks
TruLens Eval provides an easy way to evaluate RAG applications built with LangChain and LlamaIndex. The following code snippet shows how to set up the evaluation for a LangChain-based RAG application.
from trulens_eval import TruChain, Feedback, Tru,Select
from trulens_eval.feedback import Groundedness
from trulens_eval.feedback.provider import OpenAI
import numpy as np
tru = Tru()
rag_chain = ...
# Initialize provider class
openai = OpenAI()
grounded = Groundedness(groundedness_provider=OpenAI())
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons)
.on(Select.RecordCalls.first.invoke.rets.context)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(openai.relevance).on_input_output()
tru_recorder = TruChain(rag_chain,
app_id='Chain1_ChatApplication',
feedbacks=[f_qa_relevance, f_groundedness])
tru.run_dashboard()
Trulens-Eval can assess RAG apps built with other frameworks, but implementing it in code can be complex. Refer to the official documentation for more details.
In addition, Trulens-Eval also offers visual monitoring in the browser for analyzing evaluation reasons and observing API key usage.
Phoenix: evaluating LLM with flexibility
Phoenix provides a complete set of metrics to evaluate LLMs, including the quality of generated embeddings and the LLM’s responses. It can also assess RAG applications but includes fewer metrics than the other mentioned evaluation tools. The following code snippet shows how to use Phoenix to evaluate a RAG application built by LlamaIndex.
import phoenix as px
from llama_index import set_global_handler
from phoenix.experimental.evals import llm_classify, OpenAIModel, RAG_RELEVANCY_PROMPT_TEMPLATE, \
RAG_RELEVANCY_PROMPT_RAILS_MAP
from phoenix.session.evaluation import get_retrieved_documents
px.launch_app()
set_global_handler("arize_phoenix")
print("phoenix URL", px.active_session().url)
query_engine = ...
question_list = ...
for question in question_list:
response_vector = query_engine.query(question)
retrieved_documents = get_retrieved_documents(px.active_session())
retrieved_documents_relevance = llm_classify(
dataframe=retrieved_documents,
model=OpenAIModel(model_name="gpt-4-1106-preview"),
template=RAG_RELEVANCY_PROMPT_TEMPLATE,
rails=list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values()),
provide_explanation=True,
)
Apart from the above-mentioned tools, other platforms like DeepEval, LangSmith, and OpenAI Evals also offer capabilities for evaluating RAG applications. Their methodologies are similar, but prompt design and implementation specifics vary, so be sure to pick the tool that works best for you.
In conclusion, we reviewed a few methodologies, metrics, and RAG application evaluation tools. In particular, we explored three categories of metrics:
those based on a ground truth,
those without a ground truth,
and those based on the responses of large language models (LLMs).
Ground truth metrics involve comparing RAG responses with established answers. In contrast, metrics without ground truth, such as the RAG Triad, focus on evaluating the relevance between the queries, context, and responses. Metrics based on LLM responses consider friendliness, harmfulness, and conciseness.
We also explored using LLMs for scoring metrics through well-designed prompts and introduced a set of RAG evaluation tools, including Ragas, LlamaIndex, TruLens-Eval, and Phoenix to help in this task.
In the fast-changing world of AI, regularly evaluating and enhancing RAG applications is crucial for their reliability. Using the methodologies, metrics, and tools discussed here, developers and businesses can make informed decisions about the performance and capabilities of their RAG systems, driving the progress of AI applications.
Creating a Gold Standard Dataset
Creating a gold standard dataset is a critical step in evaluating RAG systems. A gold standard dataset is a set of examples that are used as a reference to evaluate the performance of the system. The dataset should include a set of questions, answers, and contexts that are relevant to the domain of the RAG system.
To create a gold standard dataset, you can follow these steps:
Identify a set of relevant questions and answers for the domain of the RAG system.
Create a set of contexts that are relevant to the questions and answers.
Have human evaluators annotate the contexts and answers to create a ground truth dataset.
Use the ground truth dataset to evaluate the performance of the RAG system.
This process ensures that the evaluation is based on accurate and relevant data, providing a reliable benchmark for assessing the system’s performance.
Best Practices for RAG Evaluation
Evaluating RAG systems requires careful consideration of several factors. Here are some best practices for RAG evaluation:
Use a gold standard dataset to evaluate the performance of the RAG system.
Use a combination of evaluation metrics to get a comprehensive understanding of the system’s performance.
Consider the trade-offs between different evaluation metrics and choose the ones that best suit your use case.
Regularly review and refine your evaluation metrics to ensure they remain relevant and effective.
Use automated evaluation tools to streamline the evaluation process and reduce the burden on human evaluators.
By following these best practices, you can ensure a thorough and effective evaluation of your RAG system, leading to continuous improvement and optimal performance.
Conclusion
RAG systems are a powerful technology for building chatbots and question-answering systems. Evaluating the performance of RAG systems is crucial for their reliability and performance. By understanding RAG systems, using evaluation metrics, creating a gold standard dataset, and following best practices for RAG evaluation, you can ensure that your RAG system is performing optimally and providing accurate and relevant responses to users.
In the fast-changing world of AI, regularly evaluating and enhancing RAG applications is crucial for their reliability. Using the methodologies, metrics, and tools discussed here, developers and businesses can make informed decisions about the performance and capabilities of their RAG systems, driving the progress of AI applications.
 Cheney Zhang
Cheney ZhangCheney Zhang is an accomplished Algorithm Engineer at Zilliz. With a profound passion for and expertise in cutting-edge AI technologies such as LLMs and Retrieval Augmented Generation (RAG), Cheney has actively contributed to many innovative AI projects, including Towhee, Akcio, and OSSChat. Before joining Zilliz, he worked for CMB Network Technology as an Algorithm Engineer. Cheney holds a master's degree from Nanjing University of Aeronautics and Astronautics.
- Using LLMs to score the metrics
- Understanding RAG Systems
- Evaluation Metrics for RAG
- Creating a Gold Standard Dataset
- Best Practices for RAG Evaluation
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

ColPali + Milvus: Redefining Document Retrieval with Vision-Language Models
When combined with Milvus's powerful vector search capabilities, ColPali becomes a practical solution for real-world document retrieval challenges.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.