




Exploring the Marvels of Knowhere 2.0
Hot off the press, Milvus 2.3 has arrived with many game-changing updates. At the forefront of these enhancements is Knowhere 2.0, a transformative upgrade that promises to elevate Milvus to new heights.
Join us in this blog post as we deep dive into Knowhere 2.0, exploring its groundbreaking features, performance optimizations, and design principles that make it a standout force in vector databases.
What is Knowhere?
Knowhere is the core vector search engine for Milvus. Imagine the vector database as the vast Marvel Universe; Knowhere is its ultimate headquarters. The primary mission of Knowhere is to perform approximate nearest neighbor searches (ANNS) by constructing indexes at a low latency.
Knowhere 2.0 and its new capabilities
We’ve been working on restructuring and upgrading Knowhere since July 2022. After relentless discussions, design, development, and testing, Knowhere 2.0 debuted with Milvus 2.3 in late August 2023. This new version brings many enhancements, including support for the GPU index, Cosine similarity, ScaNN index, and Arm architecture. The upgraded Knowhere benefits users and developers, making it a powerhouse in Milvus. Next, let’s explore its key features.
Support for GPU indexes
Nvidia contributed the GPU_FLAT and GPU_IVFPQ indexes from their vector search library, RAFT, to Knowhere 2.0. This addition significantly accelerates index searches, with Milvus achieving remarkable throughput improvements on Nvidia A100, nearly 70 times for SIFT1M.
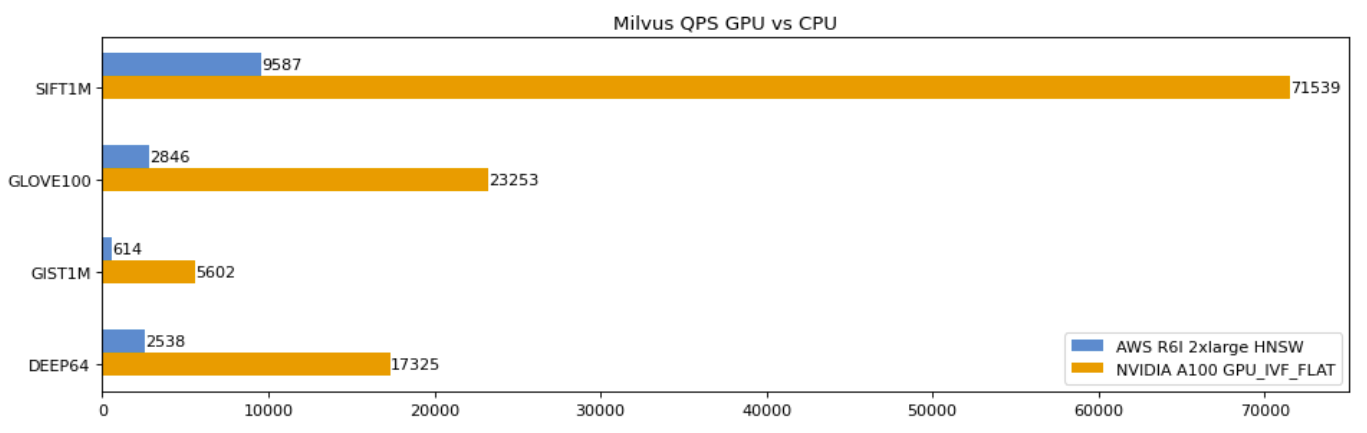 Milvus QPS GPU vs. CPU
Milvus QPS GPU vs. CPU
For more information about the GPU index, refer to Milvus documentation.
Support for Cosine similarity
In previous versions of Knowhere, users had to utilize the Inner Product and normalize vectors before vector insertion to use the Cosine similarity. This process was very costly, difficult to access, and required higher theoretical knowledge from users.
Knowhere 2.0 natively supports Cosine distance, automatically normalizes incoming vectors within the library, and matches corresponding index types, significantly improving the user experience.
Support for ScaNN index
ScaNN, or FastScan, is an open-source approximate nearest neighbor (ANN) index implemented by FAISS. It uses smaller PQ encoding and corresponding instruction sets to access CPU registers, resulting in excellent indexing performance.
Knowhere 2.0 now natively supports the ScaNN index. With Knowhere 2.0, Milvus 2.3 achieves seven times the QPS of IVF_FLAT and 1.2 times that of HNSW, with a recall rate of approximately 95% on the Cohere datasets.
Support for ARM architecture
ARM architecture is known for its cost-effectiveness in comparison to x86 architecture. Although less powerful, ARM has a more straightforward design and instruction sets, making it increasingly popular. For example, ARM instances with the same CPU specifications (e.g., 1 vCPU and 16GB of RAM) are about 15% cheaper on the AWS platform than x86 instances.
With support for ARM architecture in Knowhere 2.0, users can now run and build upper-layer services on this architecture.
Support for range search
There are two methods for finding the nearest neighbors: K Nearest Neighbor (KNN) and Range Search. KNN finds the "k" closest vectors to a query vector "q" within a collection of vectors "X." Meanwhile, Range Search doesn't have a specified "k"; instead, it returns all vectors within a certain distance (radius) from the query vector "q" within the vector collection "X."
Knowhere 2.0 supports range search for multiple indexes in the library, such as HNSW, DiskANN, and IVF indexes. This feature allows users to specify the distance between the input vector and the vectors stored in Milvus during a query.
Optimized filter queries
In mixed scalar and vector queries, you may filter out some vectors. Knowhere 2.0 has significantly improved filter vector queries for HNSW, resulting in performance boosts of up to 6 to 80 times compared to earlier versions.
Code structure and compilation enhancements
Knowhere 2.0 simplifies C++ class inheritance, uses proxy patterns for new index integration, refactors the Config module, adopts Conan as a package manager for streamlined compilation, and leverages Folly's thread pool for precise thread control. All these improvements make using Milvus more straightforward.
MMap support
In the past, some users faced memory space constraints due to their large datasets, which affected the indexes they could store. However, with the introduction of Knowhere 2.0, Milvus now supports Memory Mapping (MMap), enabling automatic mapping of large files into memory. This new feature allows users to access extensive index data despite insufficient memory.
Support for retrieval of original vectors
After finishing a search, users may require access to the original vectors based on the returned IDs for further customized calculations or filtering. With Knowhere 2.0, users can directly retrieve original vectors from the index, reducing latency compared to fetching from remote storage like S3.
For more details about Knowhere 2.0 features and enhancements, see Knowhere 2.0 Release Notes.
Welcome to contribute to Knowhere!
Knowhere is continually evolving, and your feedback matters. If you have valuable suggestions or ideas, please don't hesitate to contribute to the Knowhere repository.

Keep Reading

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.