




Clearing Up Misconceptions about Data Insertion Speed in Milvus
Many users relying on LangChain or LlamaIndex for their convenient and shorter API steps might think that "Inserting data into Milvus is slow." However, this perception often stems from a glossing-over of the detailed process steps.
The Hidden Steps
When using LangChain or LlamaIndex, these libraries convert unstructured data (like texts, images, or sounds) into vectors using embedding models. They then insert these vectors into Milvus Lite. The libraries simplify this complex process by handling multiple behind-the-scenes steps for you.
This abstraction can create the illusion that the data insertion process takes a long time.
The Time-Hog: Embedding Generation
The average time spent generating embeddings from unstructured data is significantly longer than the time required to insert data into Milvus. The perceived slowness is often due to the computationally intensive process of transforming the data into vector representations rather than the data insertion step.
To illustrate the difference between embedding generation and data insertion times, I’ll show an example in this blog where the average embedding time is approximately 5 seconds. In contrast, the average Milvus vector database insert time is only about a tenth of a second. The full code is on my GitHub.
In other words, around 97% of the "Milvus insert" time observed in LangChain or LlamaIndex is spent on embedding generation, while about 3% is spent on the actual database insertion step.
I showed in a previous blog how to connect to Milvus Lite using either LlamaIndex or LangChain.
In the following sections, I’ll cover:
Example of LlamaIndex code to insert data into Milvus
Example of LangChain code to insert data into Milvus
Example of Pymilvus API code to insert data into Milvus
Example LlamaIndex Code to Insert Data into Milvus
Here is an example code in LlamaIndex.
from llama_index.core import (
ServiceContext,
StorageContext,
VectorStoreIndex,
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.milvus import MilvusVectorStore
import time
# Define the embedding model.
service_context = ServiceContext.from_defaults(
# LlamaIndex local: translates to the same location as default HF cache.
embed_model="local:BAAI/bge-large-en-v1.5",
)
# Create a Milvus collection from the documents and embeddings.
EMBEDDING_DIM = 1024
vectorstore = MilvusVectorStore(
uri="./milvus_llamaindex.db",
dim=EMBEDDING_DIM,
# Override LlamaIndex default values for Milvus.
consistency_level="Eventually",
drop_old=True,
index_params = {
"metric_type": "COSINE",
"index_type": "AUTOINDEX",
"params": {},}
)
storage_context = StorageContext.from_defaults(
vector_store=vectorstore
)
llamaindex = VectorStoreIndex.from_documents(
lli_docs[:1],
storage_context=storage_context,
service_context=service_context
)
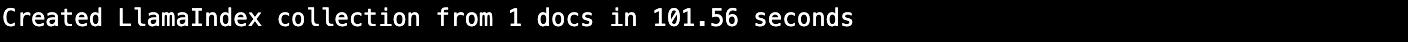
Example LangChain Code to Insert Data into Milvus
Here is an example code in LangChain.
from langchain_milvus import Milvus
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
import time
# Define the embedding model.
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embed_model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
EMBEDDING_DIM = embed_model.dict()['client'].get_sentence_embedding_dimension()
# Define the chunking strategy.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=51)
# Create a Milvus collection from the documents with chunking and embeddings.
start_time = time.time()
docs = text_splitter.split_documents(docs)
vectorstore = Milvus.from_documents(
documents=docs,
embedding=embed_model,
connection_args={"uri": "./milvus_demo.db"},
# Override LangChain default values for Milvus.
consistency_level="Eventually",
drop_old=True,
index_params = {
"metric_type": "COSINE",
"index_type": "AUTOINDEX",
"params": {},}
)

Example Pymilvus API Code to Insert Data into Milvus
Using Pymilvus API calls directly, let’s show what is actually happening behind the scenes of those short, convenient LangChain and LlamaIndex codings.
The above examples used Milvus docs webpages downloaded from the Internet directly. To show the difference between embedding times vs insert times, I’ll use an open-source multimodal embedding model below to 1) embed both images and texts and 2) insert the dense vectors into Milvus.
import pymilvus
import requests
from io import BytesIO
# Run this in small batches to avoid memory issues.
BATCH_SIZE = 10
# Batch embed text and images and insert data into Milvus.
batch_embedding_times = []
batch_insert_times = []
for i in range(0, 300, BATCH_SIZE):
batch_images = []
batch_texts = []
batch_urls = []
for j in range(BATCH_SIZE):
if i + j < len(image_texts):
text = image_texts[i + j]
url = image_urls[i + j]
with Image.open(f"./images/{url}.jpg") as img:
batch_images.append(img.copy())
batch_texts.append(text)
batch_urls.append(url)
# STEP 1. EMBEDDING INFERENCE FOR TEXT AND IMAGES.
start_time = time.time()
image_embeddings, text_embeddings = embedding_model(
batch_images=batch_images,
batch_texts=batch_texts)
end_time = time.time()
# print(f"Embedding time for batch size {len(batch_images)}: ", end="")
# print(f"{np.round(end_time - start_time, 2)} seconds")
batch_embedding_times.append(end_time - start_time)
# STEP 2. INSERT CHUNK LIST INTO MILVUS OR ZILLIZ.
chunk_dict_list = []
# Create chunk dict_list.
for chunk, img_url, img_embed, text_embed in zip(
batch_texts,
batch_urls,
image_embeddings, text_embeddings):
chunk_dict = {
'chunk': chunk,
'image_filepath': img_url,
'text_vector': text_embed,
'image_vector': img_embed
}
chunk_dict_list.append(chunk_dict)
start_time = time.time()
try:
col.insert(data=chunk_dict_list)
except:
print(f"Insert error: {img_url}")
end_time = time.time()
# print(f"Insert time for {len(chunk_dict_list)} vectors: ", end="")
# print(f"{np.round(end_time - start_time, 4)} seconds")
batch_insert_times.append(end_time - start_time)
col.flush()
# Calculate the average embedding time.
average_time = np.mean(batch_embedding_times)
print(f"Average embedding time: {round(average_time,2)} seconds")
# Calculate the average insert time.
average_time = np.mean(batch_insert_times)
print(f"Average insert time: {round(average_time,2)} seconds")
Here is the output from batch embedding times.
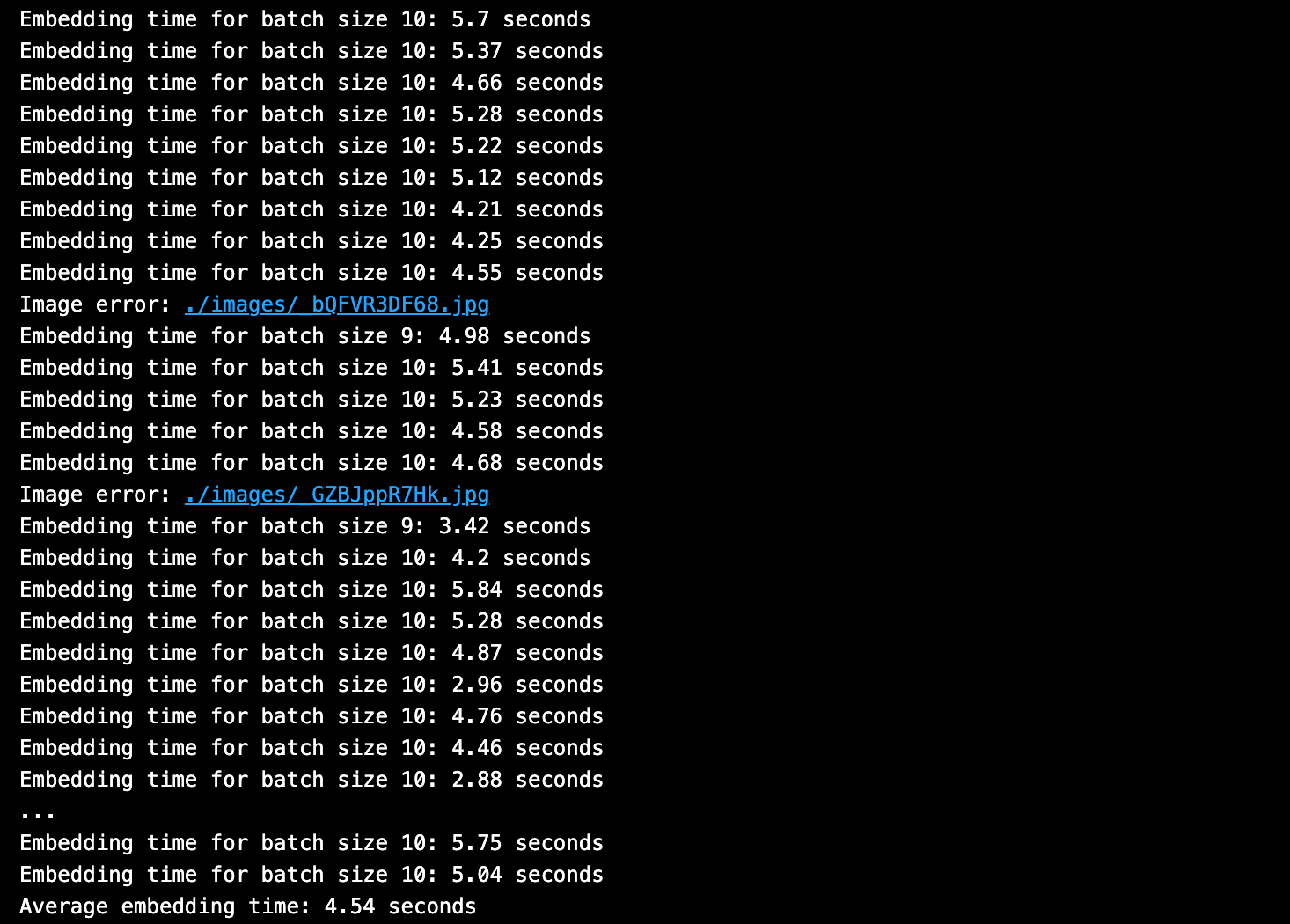
Here is the output from batch insert data into Milvus times.

The average embedding time was ~5 seconds, and the average Milvus vector database insert time was about a tenth of a second. This translates to about 97% of the total time spent performing embedding generation, while about 3% was spent on database insertion.
As you can see, the embedding step is what takes the longest!
Resources and Further Reading

Keep Reading

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.