




Building Zilliz Cloud in 18 Months: Lessons Learned While Creating a Scalable Vector Search Service on the Public Cloud

Preface
Vector databases have emerged as a leading trend in the database industry in 2023. This post details the creation of Zilliz Cloud, a fully managed service powered by Milvus, the most adopted open-source vector database, developed from the ground up over eighteen months. Throughout this time, we developed a comprehensive cloud service from scratch and navigated a tenfold surge in traffic, propelled by the rapid expansion of Large Language Models (LLM). This retrospective focuses on sharing the critical design choices and invaluable insights gained during our journey.
Zilliz Cloud Dedicated Cluster - The Journey Begins
Turning the clock back to May 2022, the open-source vector database Milvus 2.0 finally began to stabilize after several major iterations. Through conversations with our users, the need for a stable, commercially hosted version emerged as a recurring request. For Zilliz, the commercial company behind Milvus, the timing seemed perfect to embark on commercialization—we had an experienced team of engineers, a maturing product, and a dedicated user base with urgent needs. With this in mind, we set an ambitious goal: launch our product within six months.
As we initiated the project, we assessed our current capabilities and objectives:
- Our core technology, a cloud-native, open-source vector database designed with storage-computing disaggregation and a microservices framework, is engineered for seamless integration into a Kubernetes (K8s) cluster. This cloud-native framework enables us to adapt to cloud production environments rapidly.
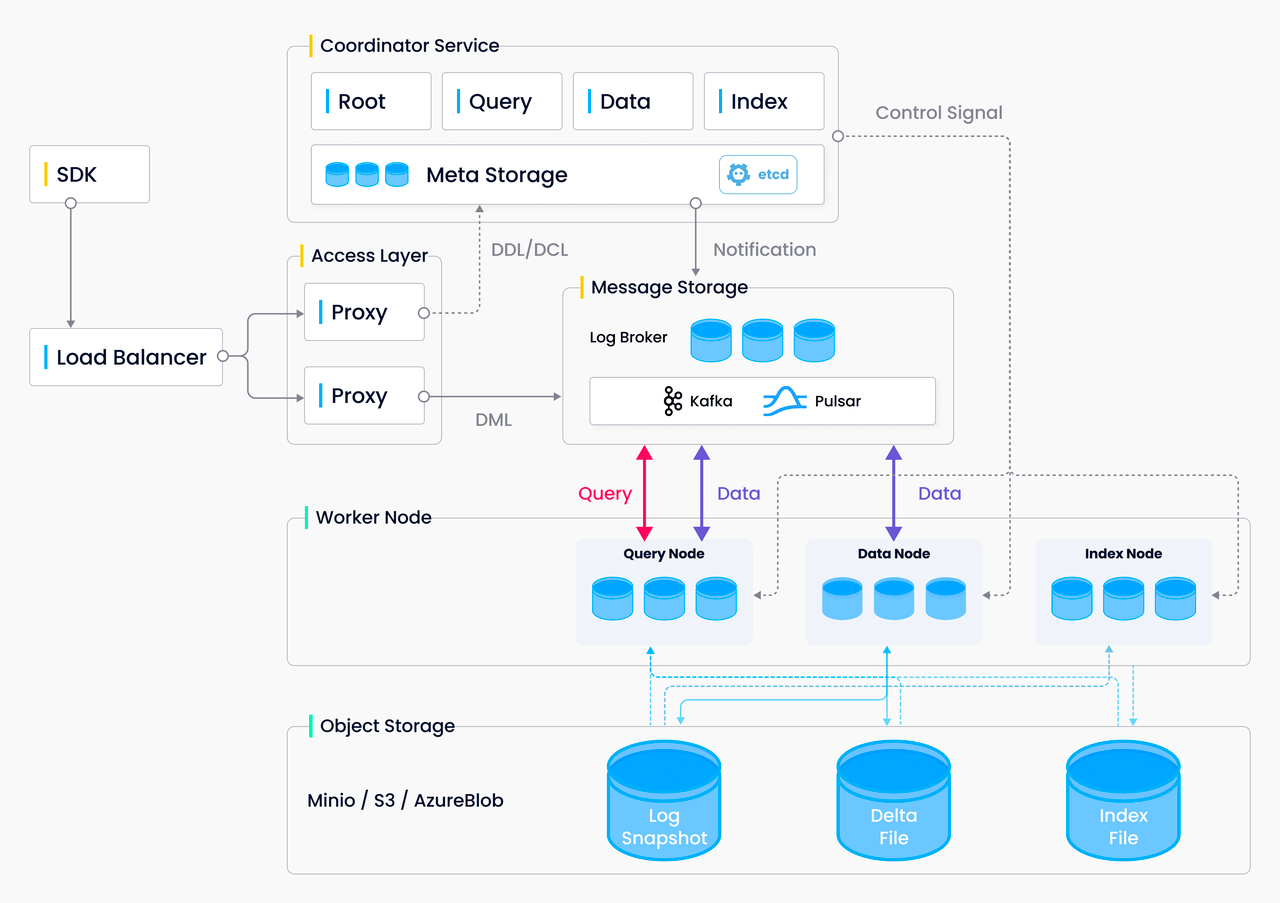 Figure 1: Milvus Architecture
Figure 1: Milvus Architecture
Because we utilized the Kubernetes Operator, we were equipped to rapidly deploy services across major public cloud platforms such as AWS and GCP; this was confirmed by several users who have successfully implemented their production services on the public cloud.
Our platform included basic observability features such as monitoring and logging, yet it needed crucial alerting functions for production.
In addition to the previously mentioned elements, as a service, we were missing several critical components, including but not limited to user login authentication, metering and billing, payment mechanisms, networking, security, a Web console, OpenAPI support, resource scheduling, and workflow management.
Narrowing down which essential modules to build within six months posed a formidable task. In response, we engaged in a critical self-assessment: How could we leverage available resources most efficiently? Could we distill our approach to create a lean yet fully functional version? These pivotal questions steered our contemplation and ultimately shaped a set of foundational design principles:
Maximize the Use of Mature Third-party Products to Avoid Reinventing the Wheel:
Emphasizing swift market readiness, we strategically leaned on established cloud and third-party services. We harnessed AWS's core services, such as EKS, EC2, S3, EBS, and ALB, alongside AWS-managed Kafka and RDS as our infrastructure backbone. This approach not only facilitated our immediate needs but also revealed that such components offer a cost-effective path for future adaptation to a multi-cloud environment, thereby accelerating our pace of innovation. Confronted with compatibility issues between GCP/Azure messaging queues and managed Kafka services, we developed our distributed log system, anchored on Apache Bookkeeper. The lack of dependable, open-source, or cloud-native distributed logging solutions drove this endeavor. Motivated by this gap, we are considering open-sourcing our solution, hopeful that it will aid others in building cloud services.
Third-party SaaS providers were instrumental in fast-tracking our platform's development. For instance, we adopted Stripe to manage our payment processing, addressing complex metering and taxation requirements. To facilitate connections with multi-cloud marketplaces, we integrated Sugar.io. Additionally, we evaluated billing service platforms such as Orb and Metronome to enhance our billing operations. Auth0 was our product of choice for account management and login functionality; we further expanded our authentication and login functionality to include Google login support. We established our operational alerting system on PagerDuty, selected for its snappy integration with our existing monitoring tools and its versatility in customizing notification rules.
Entities should not be multiplied unnecessarily
Guided by Occam's Razor's philosophy, we embraced a minimalist design approach that manifested in various aspects of the product:
Architecture Simplicity: Initially, our design included over 60 microservices, which posed significant challenges in development and testing coordination. To simplify our architecture, we streamlined the number to fewer than ten core microservices, including user, billing, CloudService, resources, metadata, and scheduling. This reduction clarified dependencies and reduced the testing burden.
Functional Simplicity: In its initial iteration, the emphasis of Zilliz Cloud was placed on core user functionalities such as registration, cluster deployment, and billing, while we deliberately deferred less urgent features like scaling and backups to alleviate the workload. Noteworthy was our commitment to establishing a robust feedback loop, initially facilitating email-based feedback and subsequently augmenting it with Zendesk integration to ensure prompt and high-quality feedback could guide us in further improvements.
Design Simplicity: Our cloud service design prioritized efficient communication and user engagement potential, requiring a disciplined and focused approach. Leveraging rapid A/B testing allowed us to validate features swiftly and adapt based on user engagement metrics.
Anticipate Day 2 Challenges from Day 1:
In the dynamic landscape of cloud services, the ability to evolve rapidly without sacrificing the reliability of user interfaces and services is paramount. This intricate maneuver resembles "swapping out the jet engines mid-air." To the external observer, the service operates flawlessly while a vigorous cycle of innovation and improvement is in progress internally. Embracing an end-in-mind development approach is crucial.
Multi-cloud Support: Initially focused on AWS, our approach has always prioritized cloud-agnosticism. We extensively evaluated providers like GCP and Alibaba Cloud to ensure compatibility across public clouds. Through customizations to the open-source project Crossplane, we developed a 'cloud adapter' layer, reducing costs associated with multi-cloud support. This design facilitated rapid integration with GCP in just one month and streamlined integration with other public cloud providers.
Security: While AIGC application developers may prioritize something other than security, Zilliz Cloud Services places utmost importance on data security. Adhering strictly to cloud IAM standards, we meticulously control data access permissions and employ encryption for all data, both in transit and at rest. Emphasizing network isolation for optimal performance, we selected AWS's EKS network add-ons for their efficiency and user-friendliness. Delineating interaction boundaries between the data and control layers has resulted in significant cost savings during the rollout of our BYOC product.
Resource Pooling: Zilliz Cloud Services adopts the "law of cloud commutativity," prioritizing elastic scalability through resource pooling. By separating storage and computation and employing dynamic load balancing, we ensure efficient utilization of cloud resources. This approach enables us to reserve resources only when necessary, significantly improving the utilization of Spot Instances and Lambda functions while reducing costs.
Operations-friendly: Zilliz Cloud is designed with developers and operational staff in mind, unlike other vector databases. Featuring a comprehensive GUI and sophisticated monitoring capabilities, the platform offers triple AZ disaster recovery and adheres to strict SLAs, ensuring stability and reliability for production environments.
Guided by our core design philosophies, we achieved the milestone of launching our commercial vector search product in just six months, securing our initial group of seed customers in the process. Below, you'll find the architectural diagram for our inaugural release.
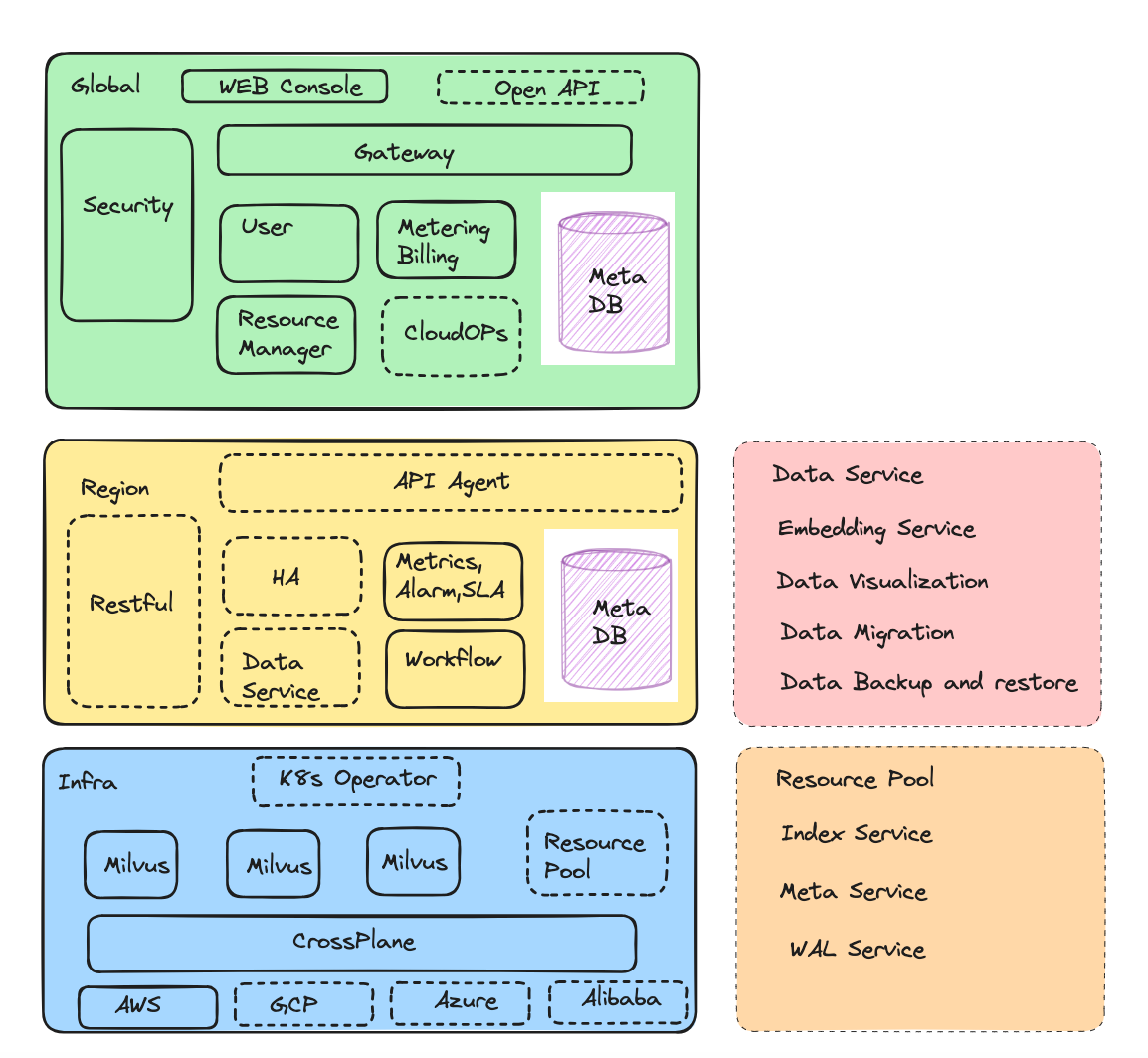 Figure 2- Zilliz Cloud Architecture
Figure 2- Zilliz Cloud Architecture
Serverless: From $300 to $5 New User Acquisition Cost
Growth often occurs at unexpected moments. After experiencing steady growth in our SaaS services for three months, the growth of Zilliz Cloud, fueled by the explosive popularity of AutoGPT, reached a high point. Viewing vector databases as long-term memory for Large Language models gradually gained acceptance, leading to a rapid increase in Zilliz's user base, with the number of new clusters added daily quickly reaching the hundreds.
However, this growth brought two main challenges to Zilliz: stability and cost. Although we always focused on scalability, the sudden high-traffic spikes nearly paralyzed all our services, with only the core database emerging unscathed. The APIs provided by cloud service providers were throttled, and our logging storage system, Loki, was filled up twice in just a few days, forcing many services to be interrupted due to a lack of resources.
Furthermore, the initial free trial strategy adopted by Zilliz Cloud, which offered $300 Credits to new users to experience all features, led to a sharp increase in costs as the number of users surged (most of whom were trying out the service), forcing us to rethink our business model. These pain points prompted us to launch Zilliz Cloud Serverless, a product that is more flexible, has a lower barrier to entry, and is more suitable for AIGC users who are just starting on their vector database journey.
The Holy Grail is Still Out There: Taming Scalability, Cost, and Latency for RAG Application development
For the Retrieval-Augmented Generation (RAG) use case, the ideal free tier solution needs to consider the following:
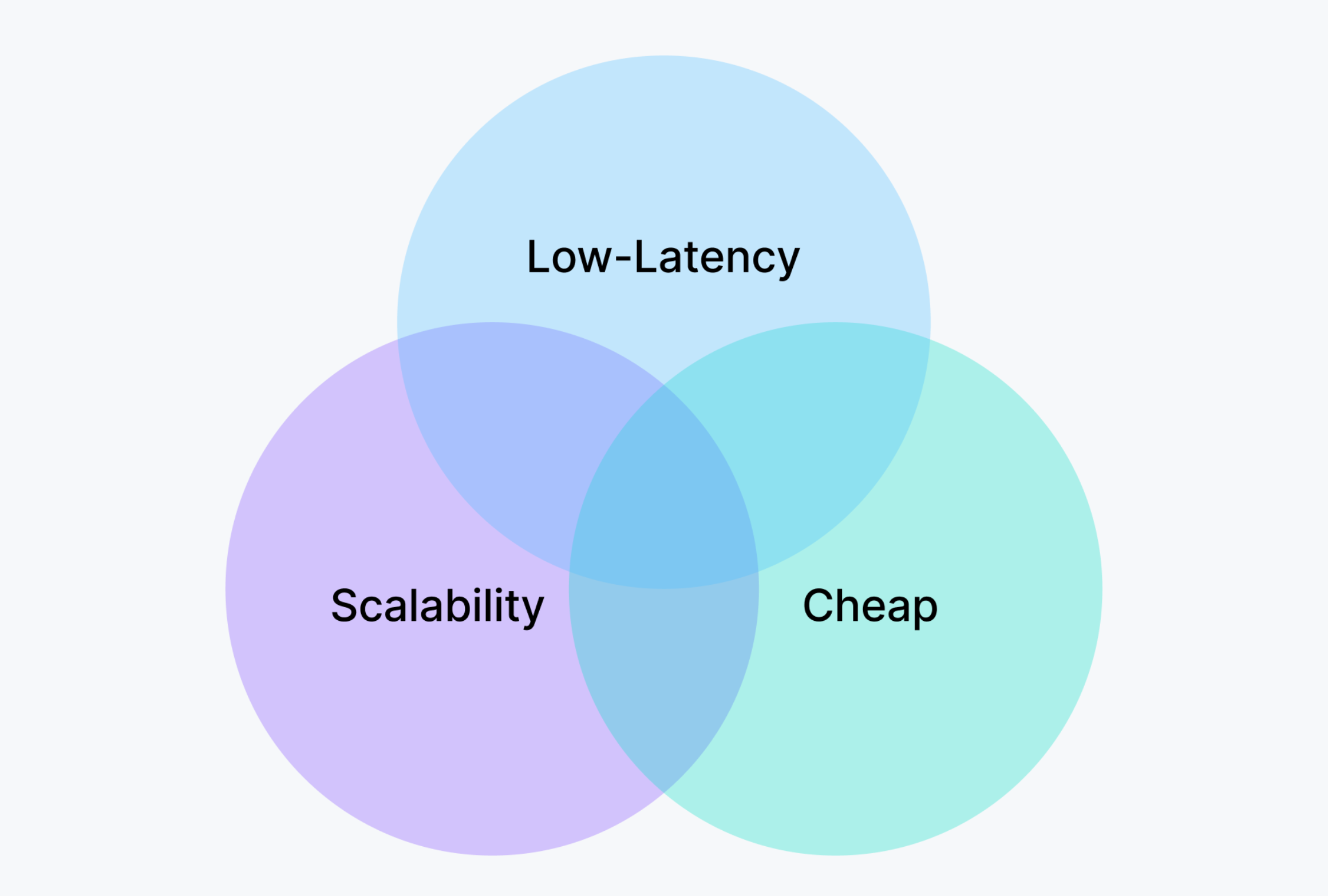
Figure 3: Taming Scalability, Cost, and Latency in RAG Application
Scalability — This encompasses two key aspects:
At the individual tenant level, the system must dynamically scale to process data effectively. This dynamic scaling requires the vector database to be versatile enough to adjust to the fluctuating data volumes of different tenants, whether they are processing small or large datasets. Consistently stable query response times must be maintained, irrespective of the size of the data being handled.
In managing lots of tenants, the system must efficiently support the scalability of up to millions of tenants. Specifically, it should intelligently differentiate and accommodate the 'hot' (highly active) and 'cold' (less active) usage patterns, ensuring optimal resource allocation and performance consistency across the board.
Cost — Cost control for the free tier is crucial. Ideally, the cost should be kept below $1 while providing enough resources to support 1 million 768-dimensional vectors. However, when relying on in-memory vector indexing, the price for handling 1 million 768-dimensional vectors can easily exceed $10. While this cost may be acceptable for SaaS companies targeting enterprise services, it is excessive for consumer-facing ToC applications.
Low Latency — Although RAG use cases may not be as sensitive to latency as the search and recommendation domains, the performance of vector retrieval significantly impacts the "Time-to-first-token." Therefore, maintaining low latency is crucial for enhancing user experience and system responsiveness.
Zilliz Cloud's initial offering showcased outstanding scalability for handling large volumes of data and achieving low latency, surpassing user expectations. Even with managing numerous tenants and cost control, the dedicated cluster solution fell short of fully satisfying user demands. To remedy this, we developed the 'Zilliz Serverless Tier,' a service model specifically designed to reduce the entry barrier for individual AIGC users. This tier offers the most cost-effective storage solutions and scalability to effectively address the challenges mentioned above.
The Zilliz Cloud Serverless Architecture
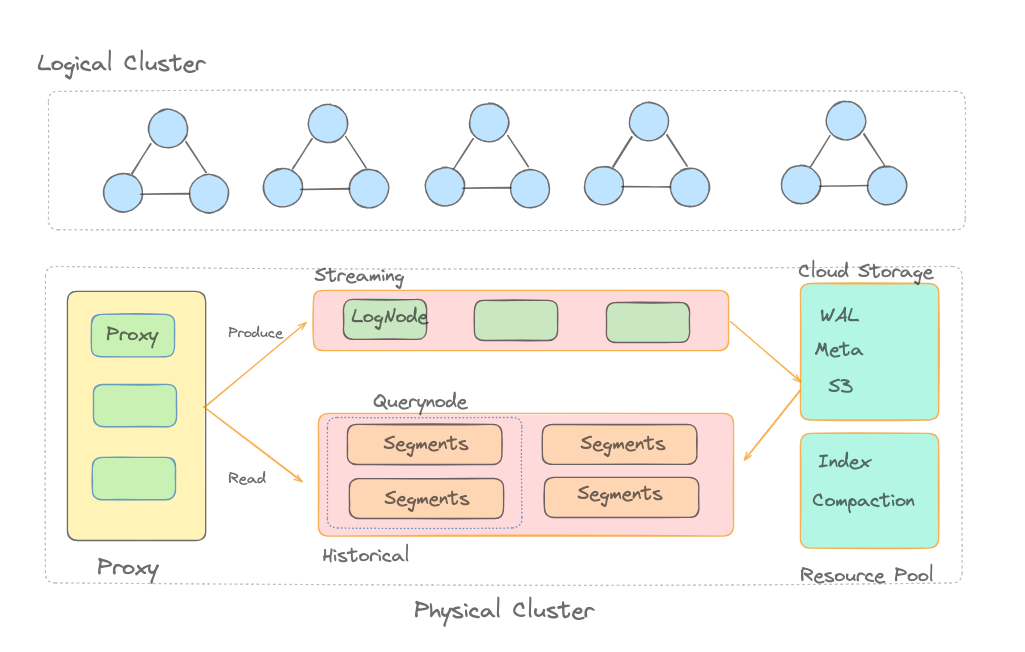 Figure 4- The Zilliz Cloud Serverless Architecture
Figure 4- The Zilliz Cloud Serverless Architecture
Zilliz Cloud Serverless introduces the concept of logical clusters, where each logical cluster corresponds to a database in a physical cluster. We achieve logical isolation for all tenants within a single physical cluster through database and API key-based authentication mechanisms. During queries, the system routes requests based on API keys to determine the data that users need to access, using proxy nodes for routing.
Data write operations are initially sent to a pool of log nodes, which then write the data to a Write-Ahead Logging (WAL) service, periodically reorganizing the data and flush into object storage. The CompactionService is a pooling service responsible for consolidating smaller data segments into larger ones and purging deleted entries, optimizing storage space and access speed. The Index Service is accountable for building indexes on raw data, which are then loaded by query nodes to ensure query efficiency.
During query operations, our strategy involves caching all data onto the local disks of Query Nodes and executing memory-to-disk swapping locally. This methodology significantly reduces storage costs for Serverless users by over ten times compared to memory-based indexing. However, a primary challenge lies in effectively managing resources to prevent query node overload caused by tenant hotspot issues and noisy neighbors. This is particularly crucial as each Query Node must handle data loading from multiple tenants.
To enhance system stability, we have introduced the following three important mechanisms:
Distributed Quota: This mechanism, based on a centralized quota service, dynamically allocates resource quotas and adjusts them based on the load of query nodes. This dynamic allocation helps ensure fair resource consumption for each tenant.
Distributed Quota: This mechanism, based on a centralized quota service, dynamically allocates resource quotas and adjusts them based on the load of query nodes. This helps ensure fair resource consumption for each tenant.
Dynamic Resource Scaling based on Metrics: We have incorporated a Cloud Resource Scheduler module, which comprehensively manages memory, disk, CPU loads, and request queuing. It enables dynamic scaling of physical resources to meet varying resource demands in different scenarios.
Multi-tiered Scheduling: We've established a resource scheduling framework that operates across various levels, encompassing physical isolation through resource grouping, load balancing within these resource groups, and the management of query queues and cache scheduling at the node level. This approach guarantees equitable resource allocation among multiple tenants while mitigating the risk of any single tenant monopolizing resources.
Through our Serverless service, we've successfully reduced the trial cost for individual users to $5, supporting tens of thousands of AIGC developers. In the upcoming release of Zilliz Cloud, we're further enhancing our Serverless solution to be even more cost-effective and elastic. In this new version, each Serverless user will be able to handle data from millions of tenants in a single collection, achieving data isolation while significantly reducing storage costs by a factor of ten compared to the current solution. We'll continue to delve into the technical details of Zilliz Cloud Serverless in future articles.
Six lessons we learned from building a cloud service from an open-source VectorDB
Recognizing Cloud Limitations: Even with cloud-native systems like Milvus, transitioning to cloud SaaS poses significant challenges. It extends beyond a simple deployment on EC2 and EBS. In the domain of open-source databases, users must possess a deep understanding of product intricacies to achieve horizontal scaling, fault recovery, and performance optimization through meticulous knob tuning. The true challenge with cloud services lies in streamlining operations while maintaining high reliability and elasticity. Addressing specific constraints of the cloud environment, such as S3 rate limits and limitations on OpenAPI call frequency, is crucial for fully capitalizing on the elasticity and scalability potential of cloud computing.
Prudent Feature Rollout: While continuously adding new features in the product's early stages may seem enticing to attract customers, addressing users' genuine pain points should be prioritized. Maintaining a lead time of approximately six months for open-source product features over the SaaS version is a good compromise. This lead time ensures that these features undergo thorough testing and improvement before being rolled out for service provision.
Set appropriate limits: No product is flawless. Take S3, for example. Despite its sleek interface and extensive refinement, developers can only maximize its value in certain situations. Unlike the freedom that open-source products get to have, SaaS products require stricter constraints to safeguard themselves. These constraints form an integral part of the product and serve as guidance and education for users. Reasonable limitations can steer users towards smarter product usage, enhancing overall value and user experience.
Opting for Cloud-Agnostic Dependency Services: Considering the adoption of cloud-agnostic dependency services like S3, EC2, and K8s managed services, which are widely available across major cloud platforms, can offer substantial benefits in terms of cost reduction and simplification of multi-cloud adoption complexities. Alternatively, opting for SaaS services that inherently support multi-cloud usage can streamline the process. Despite potential variations in implementation among different cloud service providers, early establishment of a multi-cloud adaption layer can effectively minimize redundant development efforts and enhance overall efficiency.
Focus on Cloud FinOps: In the public cloud, seemingly affordable resources can unexpectedly result in high costs. For instance, before conducting a bill analysis, we had yet to anticipate that ALB network bandwidth costs might comprise a significant portion of overall expenses. To optimize costs and maximize performance optimizations, it's essential to understand the performance of different instance types and services thoroughly. For example, each GP3 cloud disk offers 3000 IOPS; bundling multiple disks on a single machine and configuring RAID allows disk throughput to be substantially increased, thereby avoiding hefty bills for additional IOPS.
Recognize the Significance of Open API: With the growing adoption of Agents, the role of Open API and related documentation becomes increasingly important. Traditional cloud services rely on web consoles and graph interfaces to deliver functionality, but the future interaction and integration of cloud services will increasingly depend on OpenAPI. The level of service automation, Agent-friendliness, and observability have become pivotal evaluation criteria for future cloud services.
Epilogue
Looking back over the past 18 months, we've embarked on an exceptionally thrilling and challenging journey, where time seemed to pass at triple the speed. This rapid progress can be attributed to several key factors: Firstly, the advent of LLMs has dramatically enhanced our coding efficiency. Secondly, users' quick and unanimous recognition regarding the value of RAG use cases has become the primary use case for vector search to acquire new users. Lastly, we must thank all open-source, SaaS, and cloud service providers we depend on; their exceptional services have helped accelerate this journey.
We owe special gratitude to the loyal users of Zilliz Cloud and Milvus. Your meticulous and patient feedback has provided us with invaluable advice and guidance. Whether in the realms of SaaS or Serverless, we firmly believe everything we've done is just the beginning. Pursuing cost-effectiveness, performance, scalability, and user-friendliness knows no bounds.
Acknowledgements
I want to extend a heartfelt thank you to our dedicated users, whose support has been instrumental in the development of Zilliz Cloud. Your encouragement has been crucial in sharing our journey to build Zilliz Cloud, offering insights that may benefit others who want to develop their cloud service. Special recognition goes to the 300+ Milvus community contributors for their tireless work and our CEO, Charles, for his unwavering backing of our innovative technical endeavors.
If you're interested in exploring vector search services, we invite you to sign up for Zilliz Cloud. New registrants will receive $100 in free credits to get started.

Keep Reading

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.