




От извлечения до понимания: Понимание ETL

От извлечения до понимания: Понимание ETL
 ETL Pipeline.png
ETL Pipeline.png
Как компании преобразуют огромные необработанные наборы данных в мощные идеи? Какие шаги предпринимают организации для интеграции и уточнения данных перед анализом? Ответ заключается в извлечении, преобразовании и загрузке данных (ETL)..
ETL - это ключ к современному управлению данными. Он позволяет организациям собирать, обрабатывать и загружать данные для анализа. ETL извлекает информацию из нескольких ресурсов, изменяет ее для устранения ошибок, а затем помещает в централизованную базу данных. Этот процесс позволяет получить уточненную, точную и упорядоченную информацию, способствующую принятию бизнес-решений.
Данные без ETL сложно анализировать из-за их разрозненности и искаженности. Неэффективные данные могут приводить к ошибкам, влияющим на различные аспекты, такие как работа с клиентами или операционная деятельность. ETL решает проблему низкого качества данных, автоматизируя рабочие процессы и поддерживая целостность данных. Это помогает бизнесу оптимизировать отчетность, улучшить аналитику и повысить эффективность принятия решений.
В условиях, когда компании все делают на основе данных, понимание ETL становится крайне важным. Независимо от того, работаете ли вы со структурированными [базами данных] (https://docs.zilliz.com/docs/database), облачными системами или аналитикой в реальном времени, ETL гарантирует интеграцию и обработку качественных данных.
В этой статье мы обсудим, как функционирует ETL, каково его влияние и как организация может использовать его в полной мере. Мы также расскажем о лучших инструментах, которые можно использовать, чтобы сделать процесс ETL более плавным.
Что такое ETL (извлечение, преобразование и загрузка)?
ETL - это основной процесс управления данными и интеграции. Он начинается с извлечения данных из различных источников и их преобразования в подходящий формат для загрузки в целевые хранилища, такие как хранилища данных или озера данных. Организации добиваются консолидации данных, объединяя отдельные источники данных в единое хранилище для поддержки анализа.
ETL является основой для поддержания согласованности, качества и доступности данных независимо от различий в системах и платформах. Этот подход используется в различных отраслях, включая финансы, здравоохранение и электронную коммерцию.
Предприятия используют этот метод для упорядочивания данных и устранения несоответствий, что расширяет возможности принятия решений. Современные инструменты ETL могут эффективно обрабатывать как структурированные, так и неструктурированные данные.
Хорошо продуманная система ETL позволяет организациям анализировать тенденции и выявлять новые моменты. Автоматизированный рабочий процесс повышает операционную эффективность за счет автоматизации обработки данных. Предприятия используют ETL для создания единой картины, которая поддерживает точную отчетность и стратегическое планирование.
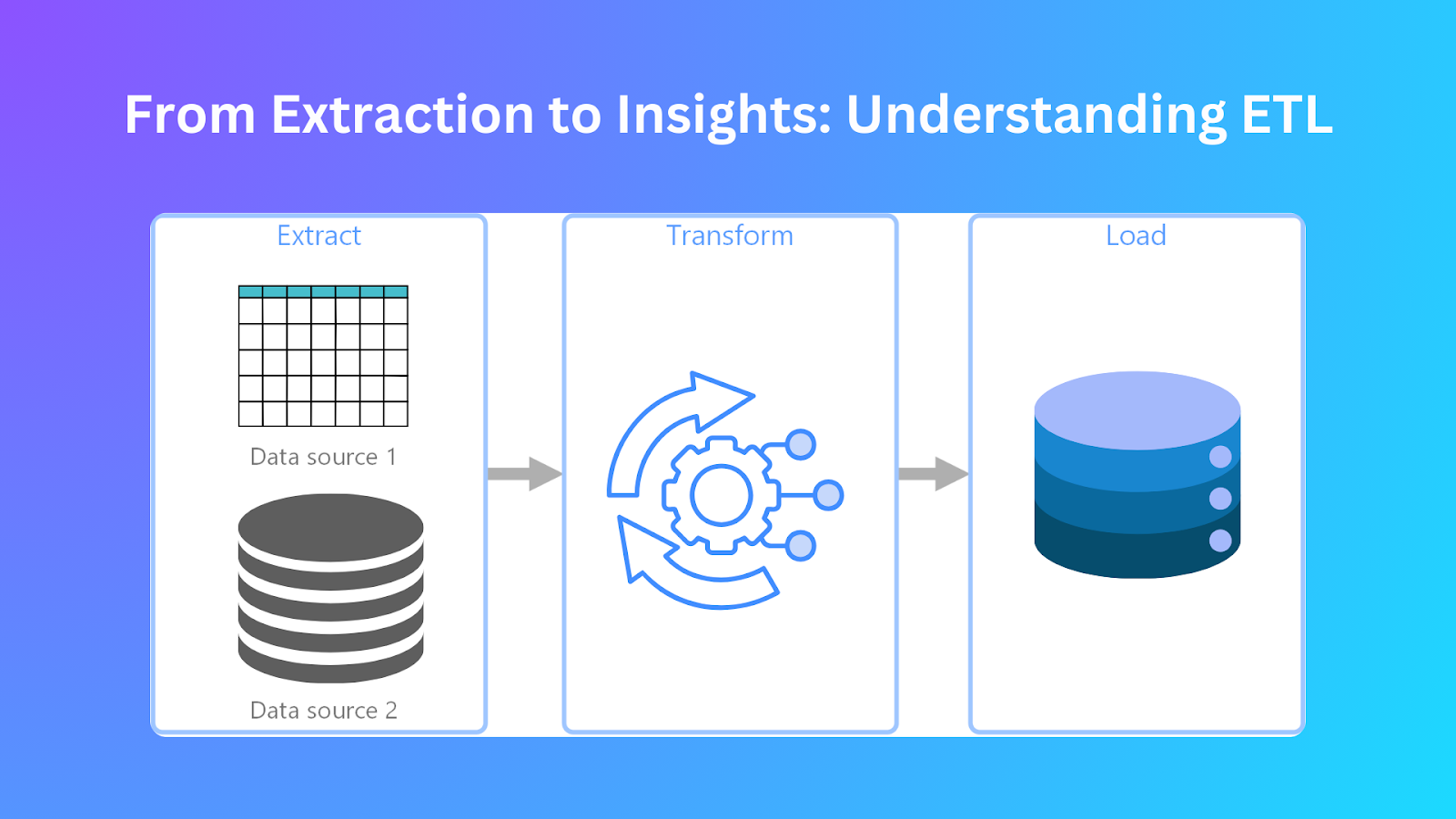
Как работает ETL
Обработка данных с помощью ETL состоит из трех этапов, которые обеспечивают точность и эффективность на каждом этапе. Этими этапами являются:
Извлечение
Конвейер ETL начинается с извлечения данных в качестве начального этапа. На этом этапе происходит сбор данных из различных источников, а затем их объединение для обработки. В процессе извлечения данных организации получают полные наборы данных из различных систем, включая базы данных, плоские файлы, облачные хранилища и API. Вот некоторые шаги на этапе извлечения данных:
Идентификация источника данных: На первом этапе извлечения данных определяется, где они находятся. Данные могут поступать из реляционных баз данных MySQL и PostgreSQL, баз данных NoSQL MongoDB и Cassandra, сторонних API, файлов CSV или JSON, а также платформ потоковых данных. Построение эффективного конвейера ETL требует правильного определения подходящих источников данных.
Получение данных: Методы получения данных зависят от бизнес-требований и доступных функциональных возможностей системы. Данные можно извлекать двумя способами: полным или инкрементным. Полное извлечение собирает все данные из источников, в то время как инкрементное извлечение собирает только изменения с момента последнего извлечения. Инкрементное извлечение предпочтительнее, поскольку оно сокращает продолжительность обработки и снижает нагрузку на исходные системы.
Работа с несоответствиями данных: Извлеченные данные могут содержать пустые поля, несоответствующие типы данных и структурные форматы. Организациям следует проводить предварительную обработку, чтобы выявить и устранить несоответствия до начала этапа преобразования.
Трансформация
После извлечения данные необходимо преобразовать, чтобы обеспечить их совместимость со схемой целевой системы и применить бизнес-правила. Этот процесс преобразования приводит к улучшению качества данных, согласованности данных и повышению удобства использования. Вот некоторые способы преобразования данных:
Очистка данных: Это одна из основных процедур преобразования. Она требует удаления дубликатов, вменения значений для недостающих данных и стандартизации соглашений об именовании. Это помогает создавать точные и свободные от ошибок отчеты.
Интеграция данных: Данные поступают из нескольких источников, содержащих отдельные структуры данных. Интеграция данных позволяет создать единое целостное представление данных из различных отдельных наборов данных. Этот процесс включает в себя сопоставление различных имен столбцов, согласование различий в часовых поясах и обеспечение ссылочной целостности.
Агрегация данных: Позволяет обобщить данные для эффективного анализа. Предприятиям часто требуются отчеты, содержащие итоговые данные о продажах в регионах, средние показатели расходов клиентов за квартал и ежемесячную динамику доходов. Процесс агрегирования позволяет быстрее выполнять запросы и упрощает интерпретацию данных.
Преобразование данных: Для обеспечения совместимости с требуемой системой необходимо преобразовать несколько типов данных. Стандартизация форматов данных имеет решающее значение, а нормализация текстовых полей и преобразование единиц измерения для числовых данных завершают процесс. Процесс преобразования данных гарантирует, что все загруженные данные будут точно соответствовать аналитическим потребностям.
Применение бизнес-правил: Организации обычно создают бизнес-правила для процессов преобразования данных. Финансовые учреждения используют пороговые значения транзакций для создания категорий, а компании электронной коммерции делят своих клиентов на сегменты в зависимости от их покупательской активности. Определенные правила генерируют ценность, организуя необработанные данные в функциональные категории.
Loading
Преобразованные данные необходимо загрузить в целевую систему, которая может представлять собой хранилище данных, озеро данных или аналитическую базу данных. Процесс загрузки устанавливает уровень, на котором данные могут быть эффективно запрошены и проанализированы.
Загрузка в целевую систему: При полной загрузке целевая система получает все данные за одну операцию. Этот метод используется в основном при первой миграции данных или для работы с небольшими наборами данных. Другой способ заключается в загрузке из исходной системы только новых записей и обновлений. Этот метод сокращает продолжительность обработки и делает операции более эффективными.
Индексирование и разбиение:** Методы индексирования данных и методы разбиения ускоряют работу системы при поиске записей. Методы разделения разбивают коллекции данных на более мелкие сегменты, повышая производительность запросов и делая данные более управляемыми.
Организации разрабатывают стратегии резервного копирования, чтобы защитить свои данные от потери во время системных сбоев. Этот метод обеспечивает защиту данных и их постоянную доступность.
Сравнение: ETL против ELT
Интеграция данных опирается на ETL (Extract, Transform, Load) и ELT (Extract, Load, Transform) в качестве основных методов передачи данных из различных источников в хранилища или озера данных. Эти два метода имеют общую цель - эффективную передачу данных, но они по-разному работают при обработке и встраивании в современные системы данных. Вот их сравнение:
| Аспект | ETL | ELT |
| Последовательность процесса | Извлечение -> Преобразование -> Загрузка | Извлечение -> Загрузка -> Преобразование |
| Трансформация | Трансформация происходит до загрузки в целевую систему | Трансформация происходит после загрузки в целевую систему |
| Хранение данных | Во время трансформации данные хранятся во временной области хранения | Данные хранятся в целевой системе, а трансформация происходит на месте |
| Обработка данных | Данные обрабатываются партиями, и обработка обычно выполняется линейно | Данные обрабатываются в реальном или близком к реальному времени, и обработка может выполняться параллельно |
| Масштабируемость | Может быть менее масштабируемой из-за необходимости создания зоны обработки и пакетной обработки | Более масштабируемой из-за возможности обрабатывать данные в реальном времени и параллельно |
| Стоимость | Может быть более дорогостоящей из-за необходимости создания зоны обработки и пакетной обработки | Может быть менее дорогостоящей из-за возможности параллельной обработки данных в реальном времени |
| Гибкость | Менее гибкая из-за жесткого порядка обработки | Более гибкая из-за возможности выполнять преобразования в любое время |
| Случаи использования | Подходит для пакетной обработки, хранилищ данных и бизнес-аналитики | Подходит для аналитики в реальном времени, интеграции данных и обработки больших данных |
RTL против ELT | Источник
Преимущества и проблемы
Хотя ETL поддерживает извлечение, преобразование и загрузку данных, у него есть свои преимущества и проблемы. Давайте рассмотрим их:
Преимущества
Отслеживание истории данных: Процессы ETL отслеживают движение данных от источников к местам назначения. Их основные функции включают выявление ошибок, поддержание целостности и обеспечение соответствия точности.
Сохранение исторических данных: Процесс ETL фиксирует снимки данных на всем их пути, позволяя организациям сохранять историческую информацию, необходимую для анализа тенденций и составления отчетов. Предприятия могут отслеживать данные при проведении сравнительного анализа, что помогает им в процессе принятия решений.
Сложное преобразование данных: Инструменты ETL позволяют выполнять сложные преобразования данных, включая процессы агрегирования, преобразования типов данных и реализацию бизнес-логики. Возможности системы облегчают операции по очистке данных, позволяя получить структурированную и стандартизированную информацию до того, как ее получит целевая система.
Обогащение данных:** Процесс обогащения данных в ETL позволяет предприятиям объединять информацию из различных внешних баз данных, повышая тем самым качество и полноту набора данных. Включение контекстной информации посредством обогащения повышает аналитическую проницательность, добавляя ценность данным для принятия решений.
Эффективность пакетной обработки: Рабочие процессы ETL достигают максимальной эффективности благодаря пакетной обработке, которая позволяет обрабатывать большие объемы данных во время запланированных непиковых циклов. Этот процесс минимизирует влияние на производительность системы в обычное рабочее время, эффективно управляя большими массивами данных.
Вызовы
Ограничения интеграции в режиме реального времени: Традиционные процессы ETL объединяют данные в запланированные пакеты, что ограничивает потребности в данных в реальном времени. Организации, которым требуется мгновенная аналитика и возможность принятия решений, сталкиваются с проблемами из-за задержек, связанных с традиционными процессами ETL.
Ресурсоемкие операции: Вычислительные требования для рабочих нагрузок ETL становятся особенно высокими, когда происходят процессы преобразования и загрузки данных. Высокое использование ресурсов CPU и памяти снижает скорость работы системы, что сказывается на уровне производительности.
Сложность обработки ошибок: Работа с ошибками становится сложной, поскольку ETL-конвейеры должны работать с многочисленными источниками данных и сложными правилами преобразования. Для выявления несоответствий, обработки недостающих данных и управления качеством необходимы надежные инструменты мониторинга и системы отладки.
Ограничения масштабируемости: Растущий объем данных создает проблемы масштабируемости, которые требуют от ETL-процессов либо новых инвестиций в инфраструктуру, либо перестройки архитектуры. Если оптимизация данных недостаточна, увеличение объема данных может привести к задержкам в обработке и ограничению производительности системы.
Управление зависимостями: Различные этапы рабочих процессов ETL зависят друг от друга, поэтому любой сбой на одном этапе может вызвать каскадный эффект во всем конвейере. Чтобы избежать сбоев в работе, эффективное управление зависимостями требует тщательного планирования, а также наличия систем мониторинга и планов механизмов восстановления после ошибок.
Примеры использования и инструменты
Процесс ETL - это фундаментальное операционное требование для многих отраслей промышленности, помогающее добиться эффективной интеграции и анализа данных. Вот некоторые примеры использования и инструменты:
Примеры использования
Розничная торговля:** Процесс ETL позволяет розничным магазинам собирать данные кассовой системы, которые они нормализуют с записями инвентаризации перед хранением в единой базе данных. Система позволяет отслеживать данные о продажах, управлять запасами и лучше понимать покупателей.
Финансы: Финансовые учреждения применяют методы ETL для объединения данных о транзакциях из нескольких систем перед их преобразованием и загрузкой в интегрированные системы хранения данных. Процесс консолидации позволяет организациям эффективно выявлять мошенничество, управлять рисками и составлять соответствующие отчеты.
Здравоохранение: Организации здравоохранения применяют процессы ETL для объединения данных из электронных медицинских карт (EMR), клинических баз данных и административных систем. Интеграция систем позволяет улучшить управление уходом за пациентами и повысить операционную эффективность, поддерживая процессы принятия обоснованных решений.
Популярные инструменты ETL
AWS Glue: Бессерверный сервис интеграции данных, обеспечивающий подключение к более чем 70 различным источникам данных. Он предлагает централизованный каталог данных, бессерверную среду и настраиваемые скрипты.
Apache NiFi: Система с открытым исходным кодом, обеспечивающая автоматизированную обработку потоков данных с помощью ETL-функций. Система обеспечивает простой в использовании веб-доступ, возможности мгновенной обработки и широкие возможности настройки, что благоприятно сказывается на сложных операциях по маршрутизации данных.
Matillion: Облачный ETL-инструмент, который работает без проблем на основных облачных платформах данных. Он предлагает такие функции, как генеративный искусственный интеллект, готовые коннекторы и совместные рабочие процессы.
Инструменты и их приложения демонстрируют, насколько важны методы ETL для преобразования необработанных данных в практические выводы в различных сферах бизнеса.
FAQs
- Какова основная цель ETL?
Функция ETL заключается в объединении данных из различных источников в единое хранилище. Рабочий процесс обработки данных включает три этапа: данные извлекаются из источников, затем преобразуются для оперативных нужд перед загрузкой в аналитическую систему.
- Чем ETL отличается от ELT?
Процесс ETL начинается с извлечения данных из исходных систем перед их преобразованием в область ожидания для загрузки в целевую систему. Затем данные загружаются в целевую систему, и преобразования выполняются непосредственно в ней.
- Каковы некоторые общие проблемы при реализации процессов ETL?
Внедрение процедур ETL сталкивается с многочисленными препятствиями, поскольку требует эффективного управления данными из разных источников, контроля качества и эффективной обработки значительных объемов данных. Эти трудности создают проблемы с производительностью, которые требуют тщательного планирования ресурсов для эффективного решения.
- Можно ли автоматизировать процессы ETL?
Инструменты ETL предоставляют возможности автоматизации с помощью функций планирования и управления рабочими процессами для выполнения процессов передачи данных. Автоматизация обеспечивает эффективную работу благодаря автоматической обработке данных, которая сокращает участие человека, сохраняя при этом неизменное качество данных, что позволяет поддерживать актуальность наборов данных для анализа.
- Почему преобразование данных важно для ETL?
Преобразование данных в рамках ETL-операций имеет решающее значение для очистки, стандартизации и форматирования данных, полученных из различных источников. Процесс преобразования данных гарантирует, что целевая система получит точные и согласованные данные для анализа и отчетности, что способствует принятию надежных бизнес-решений.
Связанные ресурсы
- Что такое ETL (извлечение, преобразование и загрузка)?
- Как работает ETL
- Сравнение: ETL против ELT
- Преимущества и проблемы
- Примеры использования и инструменты
- FAQs
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно