




Денормализация базы данных: подробное руководство

Денормализация базы данных: подробное руководство
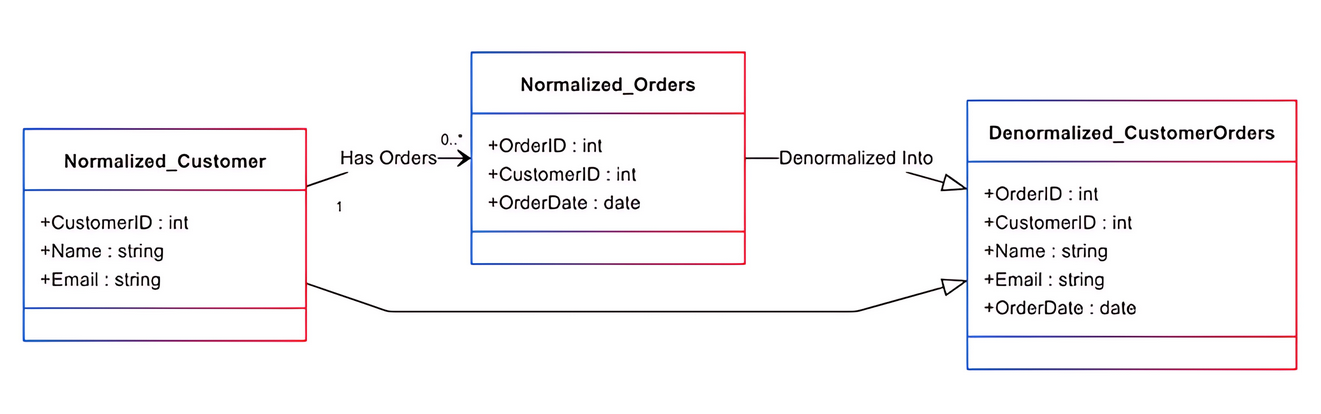
Рисунок 1: Иллюстрация денормализации базы данных
Почему одни базы данных обрабатывают запросы быстрее других, даже когда имеют дело с большими объемами информации? Ответ заключается в индексировании базы данных, оптимизации запросов и архитектуре хранения. Быстрое извлечение данных крайне важно, поскольку оно повышает производительность, улучшает пользовательский опыт и общую эффективность.
Традиционная нормализация базы данных поддерживает целостность данных, организуя их в таблицы с четко определенными связями. Хотя нормализация повышает точность данных, она обычно приводит к узкому месту в производительности в системах, где используется много соединений. При большом количестве таблиц и соединений извлекать данные становится сложнее, что замедляет отклик приложения.
Один из методов, используемых для оптимизации производительности базы данных, — денормализация. Денормализация вводит в базу данных избыточные данные, чтобы оптимизировать нагрузки с преобладанием операций чтения. Это снижает необходимость в сложных соединениях, тем самым повышая производительность запросов.
В этом руководстве будет объяснена концепция денормализации базы данных, проведено сравнение с нормализацией и рассмотрены ее преимущества. Мы также разберем сценарии использования, в которых денормализация базы данных полезна, и трудности, с которыми могут столкнуться компании при ее внедрении.
Что такое денормализация базы данных?
Денормализация базы данных — это метод оптимизации, который добавляет дублирующиеся данные в ранее нормализованную схему. Этот метод повышает производительность чтения за счет упрощения запросов и уменьшения количества соединений.
Нормализованные базы данных страдают от необходимости выполнять множество соединений для получения данных из различных таблиц, что делает их медленными при работе с большими наборами данных. Метод денормализации полезен в системах, которые выполняют операции чтения чаще, чем операции записи.
Например, предположим, что нормализованная база данных содержит три отдельные таблицы: клиентов, заказов и продуктов. Получение истории заказов клиента с подробностями о продуктах требует от базы данных соединения нескольких таблиц, объединяющих данные о клиентах, заказах и продуктах. Денормализованная схема объединяет связанные данные, такие как сведения о продукте, в одну таблицу, чтобы минимизировать соединения и улучшить производительность чтения.
Однако повышение производительности операций чтения достигается ценой усложнения операций записи. Согласованные обновления данных становятся более сложными, поскольку базе данных необходимо поддерживать избыточную информацию.
Как это работает
Процесс денормализации преобразует нормализованные базы данных путем реструктуризации, чтобы повысить скорость и производительность запросов и извлечения данных. Если процесс нормализации устраняет дубликаты, сохраняя согласованность данных, то денормализация добавляет дублирующиеся данные специально для ускорения операций чтения в приложениях.
Базы данных, которым нужны отчетность в реальном времени, высокоскоростные запросы и аналитика, широко применяют этот метод. Ниже мы обсудим подходы к денормализации и их влияние на эффективность базы данных.
 Подходы к денормализации базы данных
Подходы к денормализации базы данных
Рисунок 2: Подходы к денормализации базы данных
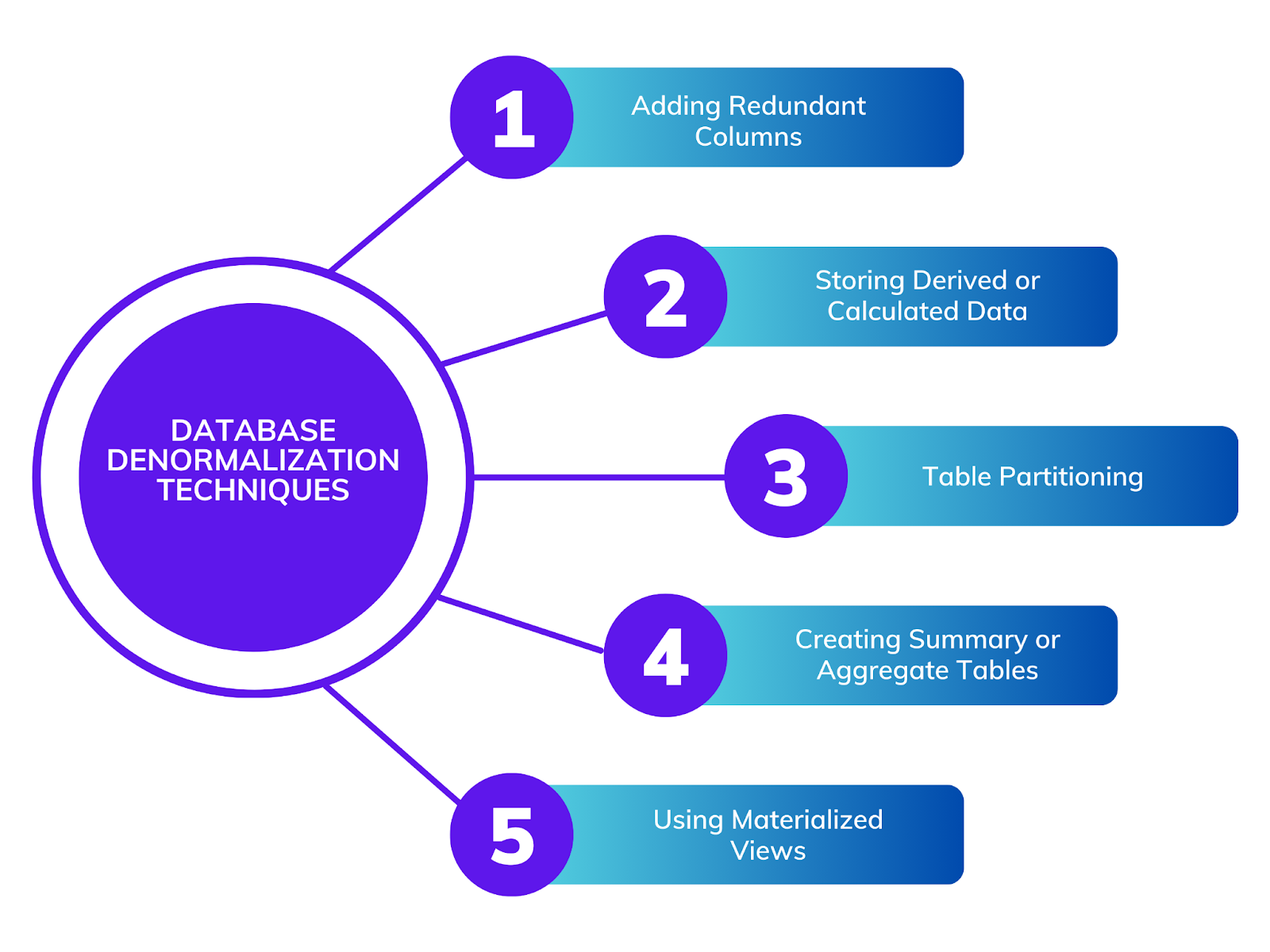
Добавление избыточных столбцов
Добавление избыточных столбцов — простой и стандартный метод денормализации. Он предполагает добавление данных в несколько мест, чтобы сократить операции соединения. Например, таблица заказов в базе данных имеет внешний ключ с именем ID, который связывает ее с таблицей клиентов. Таблица клиентов содержит важные сведения о каждом клиенте, такие как имя, ID и контактная информация.
При анализе сведений о заказах клиентов требуется операция соединения для извлечения данных клиентов. Соединение таблиц может быть особенно затратным и замедлять общую производительность. Если информация о клиенте хранится в таблице orders, это устраняет необходимость в соединении и приводит к эффективному извлечению данных.
Хотя этот метод значительно повышает скорость запросов, он увеличивает затраты на избыточность данных. Когда данные клиента изменяются, все избыточные копии должны быть обновлены для согласованности. Это требует оптимизации производительности и управления целостностью данных с помощью обновлений или триггеров. Сбалансировать эту проблему можно с помощью четко определенных процессов обновления.
Хранение производных или вычисляемых данных
Еще один метод денормализации — хранение и предварительное вычисление часто используемых расчетов. В нормализованной системе базы данных вычисления выполняются динамически во время запроса. Хотя это гарантирует актуальность значений, это также негативно влияет на вычислительную нагрузку.
Производительность системы страдает при работе с большими наборами данных или многочисленными запросами. Однако производительность можно повысить, добавив эти значения как дополнительные столбцы в существующие строки таблицы.
Например, база данных может заранее хранить общие суммы заказов в таблице orders, чтобы пользователям не приходилось пересчитывать эту информацию при запросе истории своих заказов. Система базы данных может предоставить значение без дополнительной обработки, поскольку эти значения уже сохранены.
Этот прием полезен в финансовом секторе, электронной коммерции и BI-системах, где имеется большой объем данных, требующих агрегированных и сложных вычислений. Однако поддержание целостности предварительно вычисленных значений крайне важно. Это, в свою очередь, требует периодических обновлений или активации триггеров на основе изменений в данных.
Партиционирование таблиц
Партиционирование таблиц — ключевой подход денормализации, который разделяет большие таблицы на разделы для повышения скорости обработки запросов и извлечения данных. Он дает выдающиеся результаты при обработке обширных баз данных, содержащих журналы транзакций, записи аудита и наборы исторических данных. Он дополнительно делится на две части:
Горизонтальное партиционирование: Метод партиционирования разделяет таблицу на более мелкие разделы на основе таких критериев, как параметры даты, географические области и пользовательские сегменты. Например, онлайн-ритейлер с миллионами торговых транзакций может разделить свою таблицу orders по годовым разделам. Производительность улучшается, когда запросам нужны недавние транзакции, поскольку им требуется сканировать сокращенное подмножество данных, а не всю таблицу.
Вертикальное партиционирование: Вертикальное партиционирование работает иначе, чем горизонтальное, поскольку оно разделяет таблицы на отдельные секции на основе столбцов. Оно делит таблицы на две части, размещая часто используемые столбцы отдельно от менее часто используемых, чтобы запросам нужно было извлекать только необходимые данные. Подход оказывается полезным для широких таблиц, содержащих многочисленные атрибуты, поскольку он позволяет запросам обращаться только к необходимым полям.
Оба метода партиционирования улучшают оптимизацию хранения и сокращают время выполнения запросов, добавляя значительную ценность высокопроизводительным базам данных. Однако эти методы увеличивают сложность индексирования и партиционирования и могут привести к неэффективности запросов, если не применяются надлежащие стратегии.
Создание сводных или агрегированных таблиц
Приложения для формирования отчетов и обработки аналитики данных часто извлекают сводную статистику в реальном времени из необработанных входных данных. Обычно это требует значительной вычислительной мощности. Поэтому один из подходов — агрегирование таблиц. Вместо повторного вычисления сводная таблица может использоваться как точка хранения, обеспечивая мгновенный доступ к предварительно агрегированным данным.
Рассмотрим розничную компанию, которая анализирует показатели продаж в нескольких регионах. Создание сводной таблицы с общим объемом продаж, агрегированным по месяцам для каждого региона, упростило бы понимание общих инсайтов.
Эта таблица может обновляться в реальном времени, через триггеры или с помощью запланированных пакетных обновлений. Сводная таблица обеспечивает более быстрое выполнение запросов, поскольку содержит меньше строк, чем исходная таблица транзакций, что повышает отзывчивость дашбордов и отчетов.
Хотя этот метод улучшает получение общих инсайтов, он также требует надежного механизма обновления данных. Пакетная обработка или ETL-конвейеры могут обеспечивать поддержание актуальности сводных данных.
Использование материализованных представлений
Материализованные представления — это расширенная функция оптимизации, которая создает физические объекты базы данных, содержащие результаты выполнения запросов. Стандартные представления требуют динамического выполнения запроса при каждом обращении. Однако материализованные представления хранят свои данные на диске, поэтому пользователи могут мгновенно получать информацию без дополнительной обработки.
Возьмем пример веб-сайта электронной коммерции, который отслеживает покупки клиентов. Владельцы сайта могут создать материализованное представление, которое отслеживает общие расходы по каждому клиенту в нескольких категориях продуктов. База данных извлекает предварительно вычисленные результаты, а не выполняет расчеты в реальном времени, поскольку такой подход обеспечивает более быстрые ответы на запросы.
Материализованные представления могут периодически обновляться или обновляться инкрементально в зависимости от требований системы. Этот метод дает исключительные преимущества базам данных, которым требуются соединения, агрегации и многоэтапные преобразования.
Сравнение: денормализация и нормализация
Выбор между нормализацией и денормализацией при проектировании базы данных зависит от требований к скорости производительности, эффективности хранения и согласованности данных. Эта таблица показывает различия между денормализацией и нормализацией.
| Аспект | Нормализация | Денормализация |
| Цель | Снижение избыточности | Повышение производительности чтения |
| Структура данных | Несколько связанных таблиц | Меньше таблиц, избыточные данные |
| Сложность запросов | Сложные соединения | Упрощенные запросы |
| Лучше всего подходит для | Приложений с интенсивной записью | Приложений с интенсивным чтением |
| Целостность данных | Высокая | Потенциально нарушается |
| Использование хранилища | Эффективное | Увеличенное |
| Обслуживание | Упрощенное | Более сложное |
| Аномалии обновления | Минимизированы | Повышенный риск |
Процесс выбора базы данных требует анализа шаблонов извлечения данных, требований к скорости обновления и спецификаций производительности системы. Правильно сбалансированная база данных поддерживает операционную эффективность и масштабируемость.
Преимущества и сложности
Денормализация — это метод оптимизации, который добавляет избыточные данные для ускорения операций чтения и выполнения запросов. Однако прирост производительности может создавать проблемы с хранением и аномалиями. Преимущества денормализации требуют сбалансированной реализации, предотвращающей возникновение потенциальных рисков. Вот некоторые преимущества и сложности:
Преимущества денормализации
Снижение сложности приложения: Денормализация упрощает логику приложения, устраняя необходимость в сложных соединениях и запросах к нескольким таблицам. Это повышает читаемость и простоту запросов, что приводит к росту продуктивности разработчиков.
Повышенная производительность в распределенных системах: Извлечение данных из нескольких узлов в распределенных базах данных приводит к задержкам производительности. Денормализация размещает дублирующиеся данные рядом с основными точками доступа к ним. Это снижает необходимость извлечения данных между узлами. Этот метод ценен как для облачных систем, так и для горизонтально масштабируемых архитектур.
Повышенная эффективность хранилищ данных: Хранилища данных требуют эффективной обработки аналитических задач, выполняющих сложные вычисления и процедуры агрегации. Денормализация улучшает производительность чтения за счет хранения предварительно объединенных или предварительно агрегированных данных, устраняя необходимость в преобразованиях данных в реальном времени.
Способствует аналитике в реальном времени: Приложения, выполняющие анализ, нуждаются в немедленном доступе к данным для быстрого получения инсайтов. Денормализация снижает потребность в сложных вычислениях в реальном времени за счет хранения предварительно вычисленных значений вместе с избыточными данными.
Оптимизированная отчетность: Денормализованные базы данных хранят предварительно обработанные данные для мгновенного создания отчетов и минимизируют необходимость операций преобразования данных. Такой подход дает существенные преимущества приложениям бизнес-аналитики и панелям мониторинга для руководителей.
Проблемы
Аномалии данных: Дублирование данных создает более высокий риск несогласованности данных, поскольку обновления могут некорректно распространяться между всеми экземплярами системы. Проверка данных и контроль согласованности важны в денормализованных системах для снижения риска аномалий.
Увеличение затрат на хранение: Избыточные данные требуют дополнительного пространства для хранения, что увеличивает общий размер базы данных. Облачные базы данных, использующие модели ценообразования на основе потребления, могут столкнуться с более высокими затратами из-за требований к хранению.
Сложность синхронизации данных: Синхронизация данных требует, чтобы каждая операция обновления одновременно изменяла все копии данных, что приводит к ограничениям производительности. Некачественное выполнение синхронизации данных приводит к появлению записей, содержащих неточности или устаревшую информацию.
Потенциальные проблемы с целостностью данных: Неправильное выполнение обновлений в нескольких экземплярах приводит к несогласованным данным. Это снижает качество операций и точность отчетности. Системы с высокой транзакционной нагрузкой требуют дополнительных ресурсов и строгих систем проверки для поддержания целостности данных.
Сниженная гибкость: Среды с несколькими таблицами усложняют изменения схемы. Это приводит к более медленным циклам разработки и затрудняет адаптацию организаций к новым бизнес-требованиям.
Для внедрения денормализации необходимо надлежащее управление, чтобы предотвратить аномалии данных, проблемы целостности и расходы на хранение. Организации должны внедрять денормализацию на основе выявленных требований к производительности, соответствующих потребностям их систем.
Варианты использования
Преимущества денормализации становятся очевидными в конкретных вариантах использования, но организациям следует понимать ее последствия в разных ситуациях. Вот некоторые из ключевых вариантов использования:
Хранилища данных и OLAP-системы: Хранилища данных и OLAP-системы используют методы денормализации, чтобы сделать сложные запросы и агрегации более эффективными. Использование денормализованных схем приводит к более быстрому извлечению данных, поскольку устраняет необходимость в множественных соединениях таблиц. Это важно для приложений бизнес-аналитики и аналитических рабочих нагрузок.
Приложения с низкой задержкой: Денормализация приносит пользу приложениям с низкой задержкой, сокращая время, необходимое для извлечения и обработки данных в критически важных средах, таких как платформы финансовой торговли.
Приложения с преобладанием чтения: Приложения, выполняющие больше операций чтения, чем записи, могут достичь лучшей производительности с помощью денормализации. Системы, такие как системы управления контентом и инструменты отчетности, могут повысить производительность запросов чтения за счет добавления дублирующихся данных.
Аналитика в реальном времени: Приложения, которым нужны мгновенные инсайты, могут получить пользу от денормализации за счет доступа к предварительно агрегированным данным. Это сокращает время обработки запросов, позволяя быстро принимать решения на основе актуальной информации.
FAQs
Всегда ли денормализация базы данных лучше для производительности?
Денормализация в системах с высокой нагрузкой на запись создает проблемы несогласованности данных, поскольку поддержание избыточных данных представляет значительные сложности. Перед принятием решения о денормализации базы данных необходимо оценить шаблоны чтения и записи вашего приложения.
Заменяет ли денормализация нормализацию?
Денормализация выступает дополнительным шагом после нормализации для устранения проблем производительности. Процесс нормализации структурирует данные, чтобы устранить дублирование и поддерживать целостность данных, но денормализация повторно вводит дубликаты данных для повышения скорости чтения.
Каковы риски денормализации?
Внедрение денормализации создает три основных риска: избыточность данных, повышенные требования к хранилищу и несогласованности. Увеличенная избыточность данных создает потенциальные аномалии при неправильном управлении, тогда как увеличенный объем данных требует дополнительных расходов на хранение.
Могу ли я денормализовать только часть моей базы данных?
Да, денормализация базы данных работает путем нацеливания на определенные разделы базы данных для оптимизации производительности. Целевое внедрение обеспечивает более высокую эффективность чтения в конкретных областях, не влияя на управляемость или целостность базы данных.
Как поддерживать согласованность данных в денормализованной базе данных?
Денормализованная база данных требует триггеров базы данных, ограничений и логики приложения, чтобы поддерживать согласованность избыточных данных во время обновлений. Внедрение этих механизмов поддерживает синхронизацию данных во всех копиях данных.
Related Resources
- Что такое денормализация базы данных?
- Как это работает
- Сравнение: денормализация и нормализация
- Преимущества и сложности
- Варианты использования
- FAQs
- Related Resources
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно