




벡터 검색을 위한 유사성 지표
검색을 위한 벡터 유사도 메트릭 - 질리즈 블로그
사과와 오렌지를 비교할 수는 없습니다. 아니면 할 수 있을까요? 밀버스](https://zilliz.com/what-is-milvus)와 같은 벡터 데이터베이스를 사용하면 벡터화할 수 있는 데이터를 모든 비교가 가능합니다. 심지어 주피터 노트북에서도 바로 할 수 있습니다. 하지만 벡터 유사도 검색은 어떻게 작동할까요?
벡터 검색에는 인덱스와 거리 메트릭이라는 두 가지 중요한 개념적 요소가 있습니다. 인기 있는 벡터 인덱스로는 HNSW, IVF, ScaNN 등이 있습니다. 세 가지 주요 거리 메트릭이 있습니다: L2 또는 유클리드 거리, 코사인 유사도, 내적 곱입니다. 맨해튼 거리는 각 차원의 절대 차이를 합산하여 점 사이의 거리를 계산하며, 이상값 감도를 최소화해야 하는 시나리오에서 유리합니다. 이진 벡터에 대한 다른 메트릭으로는 해밍 거리와 자카드 인덱스가 있습니다.
이 문서에서는 이에 대해 다뤄보겠습니다:
벡터 유사성 메트릭
L2 또는 유클리드
L2 거리는 어떻게 작동하나요?
유클리드 거리는 언제 사용해야 하나요?
코사인 유사도
코사인 유사도는 어떻게 작동하나요?
코사인 유사도는 언제 사용해야 하나요?
내부 제품
내부 제품은 어떻게 작동하나요?
이너 프로덕트는 언제 사용해야 하나요?
기타 흥미로운 벡터 유사도 또는 거리 메트릭
해밍 거리
제이카드 인덱스
벡터 유사도 검색 지표 요약
벡터는 숫자의 목록 또는 방향과 크기로 표현할 수 있습니다. 벡터를 가장 쉽게 이해하려면 벡터를 공간에서 특정 방향을 가리키는 선분으로 상상하면 됩니다.
L2 또는 유클리드 메트릭**은 두 벡터의 "빗변" 메트릭입니다. 이는 벡터의 선이 끝나는 지점 사이의 거리의 크기를 측정합니다.
코사인 유사도**는 두 선이 만나는 지점 사이의 각도를 측정합니다.
내적 곱은 한 벡터를 다른 벡터에 "투영"한 값입니다. 직관적으로 벡터 사이의 거리와 각도를 모두 측정합니다.
가장 직관적인 거리 측정 지표는 L2 또는 유클리드 거리입니다. 이는 두 물체 사이의 공간의 양이라고 생각하면 됩니다. 예를 들어, 화면이 얼굴에서 얼마나 멀리 떨어져 있는지 알 수 있습니다.
그렇다면 L2 거리가 공간에서 어떻게 작동하는지 상상해 봤는데, 수학에서는 어떻게 작동할까요? 먼저 두 벡터를 숫자의 목록으로 상상해 보겠습니다. 목록을 서로 나란히 정렬하고 아래쪽으로 뺍니다. 그런 다음 모든 결과를 제곱하고 더합니다. 마지막으로 제곱근을 구합니다.
밀버스는 제곱근과 제곱근이 아닌 순위 순서가 동일하므로 제곱근을 생략합니다. 이렇게 하면 연산을 건너뛰고 동일한 결과를 얻을 수 있으므로 지연 시간과 비용을 낮추고 처리량을 늘릴 수 있습니다. 아래는 유클리드 또는 L2 거리가 어떻게 작동하는지 보여주는 예시입니다.
d(퀸, 킹) = √(0.3-0.5)2 + (0.9-0.7)2
= √(0.2)2 + (0.2)2
= √0.04 + 0.04
= √0.08 ≅ 0.28
유클리드 거리를 사용하는 주된 이유 중 하나는 벡터의 크기가 다를 때입니다. 주로 단어가 공간적 거리 또는 의미적 거리에서 얼마나 멀리 떨어져 있는지에 관심이 있습니다.
두 벡터의 방향 차이를 나타내기 위해 "코사인 유사성" 또는 "코사인 거리"라는 용어를 사용합니다. 예를 들어, 현관문을 향해 얼마나 멀리 돌아갈까요?
재미있고 적용 가능한 사실: "유사도"와 "거리"는 그 의미만으로는 서로 다르지만, 두 용어 앞에 코사인을 붙이면 거의 같은 의미로 바뀝니다! 이것은 의미적 유사성이 작용하는 또 다른 예입니다.
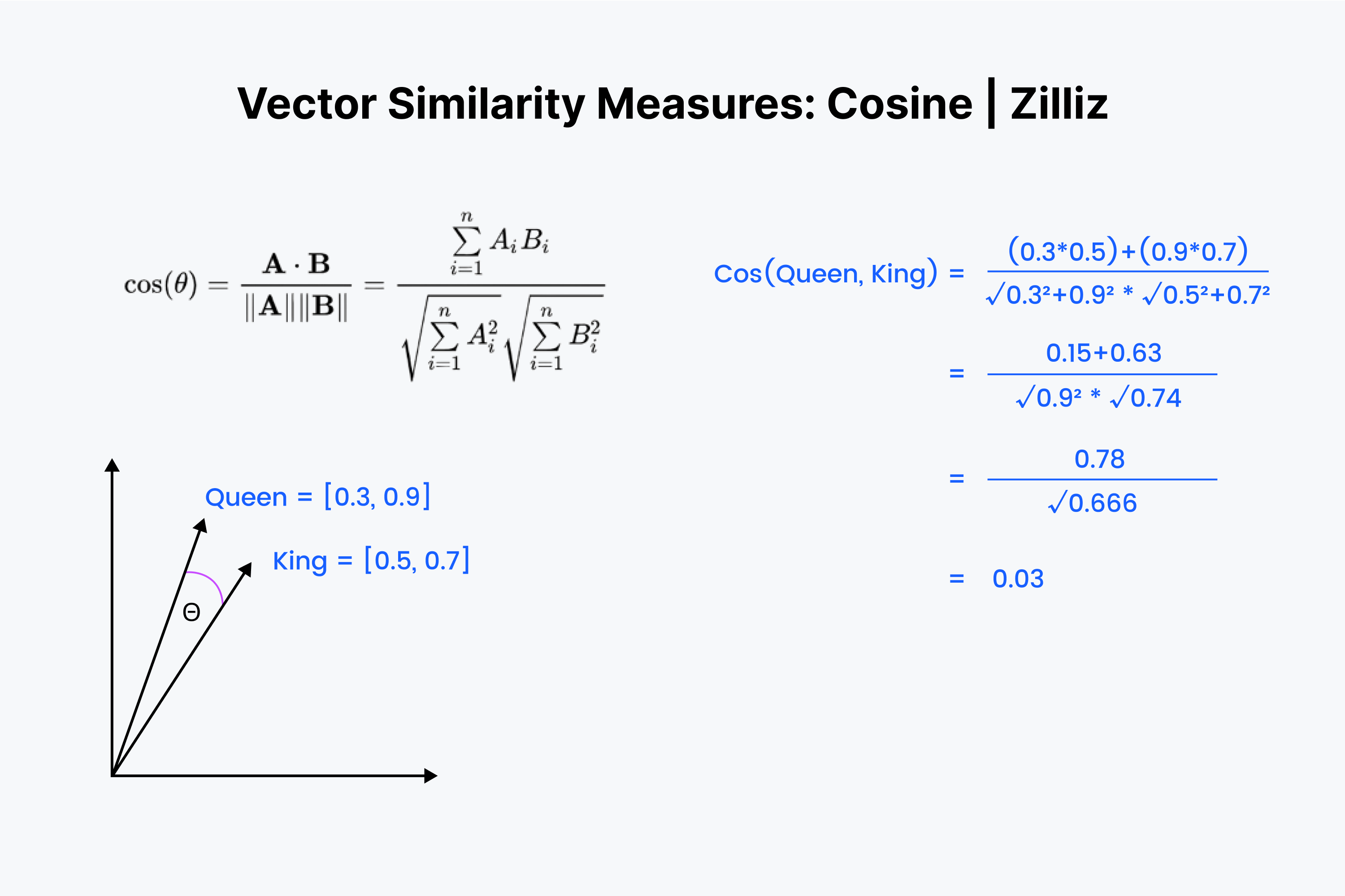
코사인 유사성은 두 벡터 사이의 각도를 측정한다는 것을 알고 있습니다. 다시 한 번 벡터를 숫자의 목록으로 상상해 보겠습니다. 하지만 이번에는 과정이 조금 더 복잡합니다.
벡터를 다시 서로 겹쳐서 정렬하는 것부터 시작합니다. 숫자를 곱한 다음 모든 결과를 더하는 것으로 시작합니다. 이제 그 숫자를 저장하고 'X'라고 부릅니다. 다음으로 각 숫자를 제곱하고 각 벡터의 숫자를 더해야 합니다. 각 숫자를 가로로 제곱하고 두 벡터에 대해 합산한다고 상상해 보세요.
두 합의 제곱근을 구한 다음 곱하고 이 결과를 "y"라고 부릅니다. 코사인 거리의 값은 "x"를 "y"로 나눈 값으로 구할 수 있습니다.
코사인 유사도는 주로 NLP 애플리케이션에서 사용됩니다. 코사인 유사도가 측정하는 가장 중요한 것은 의미적 방향의 차이입니다. 정규화된 벡터로 작업하는 경우 코사인 유사도는 내적 곱과 동일합니다.
내적 곱은 한 벡터를 다른 벡터에 투영한 것입니다. 내적 곱의 값은 벡터의 길이를 빼낸 값입니다. 두 벡터 사이의 각도가 클수록 내적 곱은 작아집니다. 또한 더 작은 벡터의 길이에 따라 스케일링됩니다. 따라서 방향과 거리가 중요할 때는 내적 곱을 사용합니다. 예를 들어 벽을 통해 냉장고까지 직선으로 거리를 측정해야 한다고 가정해 보겠습니다.
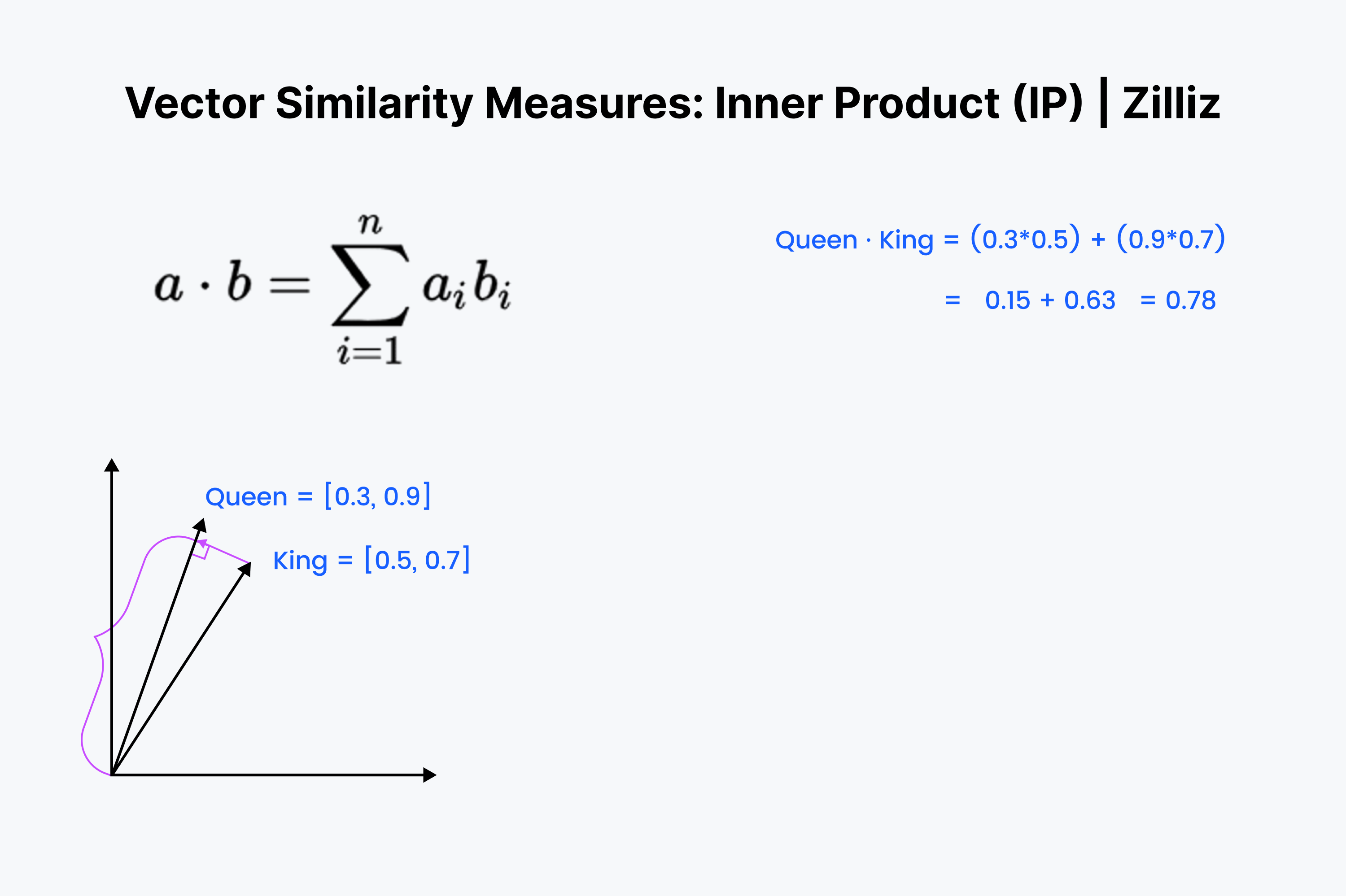
내부 곱은 익숙하게 보일 것입니다. 이것은 코사인 계산의 첫 번째 ⅓에 불과합니다. 이 벡터를 머릿속에 정렬하고 아래쪽으로 곱하면서 행을 내려가세요. 그런 다음 합산합니다. 이것은 여러분과 가장 가까운 딤섬 사이의 직선 거리를 측정합니다.
내적 곱은 유클리드 거리와 코사인 유사도 사이의 교집합과 같습니다. 정규화된 데이터 세트의 경우 코사인 유사도와 동일하므로 IP는 정규화된 데이터 세트나 정규화되지 않은 데이터 세트 모두에 적합합니다. 코사인 유사도보다 더 빠른 옵션이며, 더 유연한 옵션입니다.
내적 곱을 사용할 때 염두에 두어야 할 한 가지는 삼각형 부등식을 따르지 않는다는 것입니다. 더 큰 길이(큰 크기)가 우선시됩니다. 즉, 역파일 인덱스 또는 HNSW와 같은 그래프 인덱스와 함께 IP를 사용할 때는 주의해야 합니다.
위에서 언급한 세 가지 벡터 메트릭은 벡터 임베딩과 관련하여 가장 유용합니다. 하지만 두 벡터 사이의 거리를 측정하는 유일한 방법은 아닙니다. 다음은 벡터 간의 거리 또는 유사성을 측정하는 다른 두 가지 방법입니다.
 그룹 13401.png
그룹 13401.png
해밍 거리는 벡터나 문자열에 적용할 수 있습니다. 여기서는 벡터를 예로 들어보겠습니다. 해밍 거리는 두 벡터의 항목의 "차이"를 측정합니다. 예를 들어 "1011"과 "0111"의 해밍 거리는 2입니다.
벡터 임베딩의 경우, 해밍 거리는 이진 벡터에 대해서만 측정하는 것이 합리적입니다. 신경망의 두 번째에서 마지막 계층의 출력인 부동 소수점 벡터 내포는 0에서 1 사이의 부동 소수점 숫자로 구성됩니다. 예를 들어 [0.24, 0.111, 0.21, 0.51235] 및 [0.33, 0.664, 0.125152, 0.1]이 있습니다.
보시다시피, 두 벡터 임베딩 사이의 해밍 거리는 거의 항상 벡터 자체의 길이로 나옵니다. 각 값에 대한 가능성이 너무 많기 때문입니다. 그렇기 때문에 해밍 거리는 이진 또는 희소 벡터에만 적용할 수 있습니다. TF-IDF](https://zilliz.com/learn/tf-idf-understanding-term-frequency-inverse-document-frequency-in-nlp), BM25 또는 SPLADE와 같은 프로세스에서 생성되는 벡터의 유형입니다.
해밍 거리는 두 텍스트 사이의 문구 차이, 단어 철자 차이 또는 두 이진 벡터 사이의 차이와 같은 것을 측정하는 데 좋습니다. 하지만 벡터 임베딩 간의 차이를 측정하는 데는 적합하지 않습니다.
재미있는 사실이 하나 있습니다. 해밍 거리는 두 벡터에 대한 XOR 연산의 결과를 합산하는 것과 같습니다.
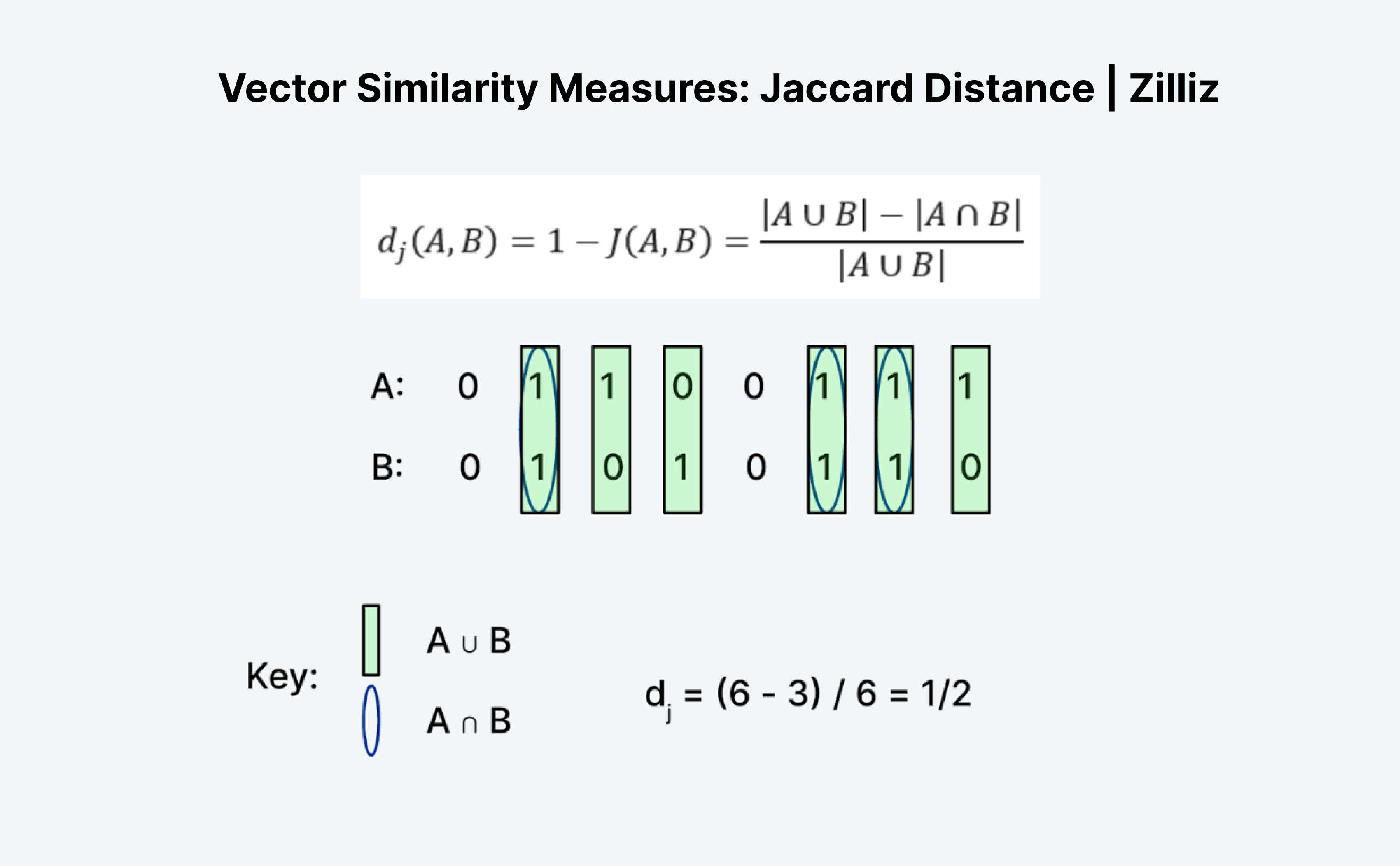
자카드 거리는 두 벡터의 유사성 또는 거리를 측정하는 또 다른 방법입니다. Jaccard의 흥미로운 점은 Jaccard Index와 Jaccard Distance가 모두 존재한다는 것입니다. Jaccard 거리는 1에서 Milvus가 구현하는 거리 메트릭인 Jaccard 인덱스를 뺀 값입니다.
자카드 거리 또는 인덱스를 계산하는 것은 언뜻 보기에 이해가 되지 않기 때문에 흥미로운 작업입니다. 해밍 거리와 마찬가지로 Jaccard는 이진 데이터에서만 작동합니다. 저는 '합집합'과 '교집합'이라는 전통적인 개념이 혼란스럽습니다. 제가 생각하는 방식은 논리로 접근하는 것입니다. 기본적으로 A "OR" B에서 A "AND" B를 뺀 값을 A "OR" B로 나눈 값입니다.
위 이미지와 같이 A 또는 B 중 하나가 1인 항목의 수를 "합집합"으로, A와 B가 모두 1인 항목의 수를 "교집합"으로 계산합니다. 따라서 A(01100111)와 B(01010110)에 대한 Jaccard 인덱스는 ½입니다. 이 경우 Jaccard 거리인 1에서 Jaccard 인덱스를 뺀 값도 ½입니다.
이 포스팅에서는 가장 유용한 세 가지 벡터 유사도 검색 메트릭에 대해 알아보았습니다: L2(유클리드 거리라고도 함) 거리, 코사인 거리, 내적 곱입니다. 이들 각각은 서로 다른 사용 사례를 가지고 있습니다. 유클리드 거리는 크기 차이가 중요할 때 사용합니다. 코사인은 방향의 차이가 중요할 때 사용합니다. 내적 곱은 크기와 방향의 차이를 고려할 때 사용합니다.
벡터 유사도 메트릭에 대해 자세히 알아보려면 이 동영상을 확인하거나 문서 읽기를 통해 Milvus에서 이러한 메트릭을 구성하는 방법을 알아보세요.
유사도 메트릭 소개
유사도 메트릭은 다양한 데이터 분석 및 머신 러닝 작업에서 중요한 도구입니다. 서로 다른 데이터 간의 유사성을 비교하고 평가하여 클러스터링, 분류, 추천과 같은 애플리케이션을 용이하게 해줍니다. 각각 장단점이 있는 수많은 유사성 메트릭을 사용할 수 있기 때문에 특정 작업에 적합한 메트릭을 선택하는 것은 어려울 수 있습니다. 이 섹션에서는 유사도 메트릭의 개념과 그 중요성을 소개하고 가장 일반적으로 사용되는 메트릭에 대한 개요를 제공합니다.
코사인 유사도
코사인 유사도는 두 벡터 사이의 각도의 코사인을 측정하는 널리 사용되는 유사도 메트릭입니다. 자연어 처리 및 정보 검색 작업에서 일반적으로 사용됩니다. 코사인 유사도 메트릭은 계산 효율이 높고 희박한 데이터를 처리할 수 있기 때문에 고차원 데이터를 다룰 때 특히 유용합니다. 두 벡터 사이의 코사인 유사도는 벡터의 도트 곱을 크기의 곱으로 나눈 값을 사용하여 계산할 수 있습니다.
유클리드 거리
직선 거리라고도 하는 유클리드 거리는 n차원 공간에서 두 점 사이의 거리를 측정하는 데 널리 사용되는 거리 측정 기준입니다. 두 벡터의 해당 요소 사이의 제곱 차이의 합의 제곱근으로 계산됩니다. 유클리드 거리는 클러스터링, 분류, 회귀 분석 등 다양한 애플리케이션에서 일반적으로 사용됩니다. 하지만 이상값에 민감할 수 있으며 고차원 데이터에서는 잘 작동하지 않을 수 있습니다.
올바른 유사도 메트릭 선택하기
올바른 유사성 지표를 선택하는 것은 데이터 유형, 분석 목표, 변수 간의 관계 등 다양한 요인에 따라 달라집니다. 예를 들어, 코사인 유사도는 고차원 데이터 및 자연어 처리 작업에 적합하며, 유클리드 거리는 클러스터링 및 분류 작업에 일반적으로 사용됩니다. L1 거리라고도 하는 맨해튼 거리는 이상값이 있는 데이터에 적합하며, 해밍 거리는 이진 데이터에 사용됩니다. 특정 작업에 가장 적합한 유사도 메트릭을 선택하려면 각 유사도 메트릭의 특성과 한계를 이해하는 것이 중요합니다.
실제 적용 사례
유사도 메트릭은 다음과 같은 다양한 분야에서 실제 활용되고 있습니다:
자연어 처리: 코사인 유사도는 텍스트 분류, 감정 분석, 정보 검색 작업에서 널리 사용됩니다.
추천 시스템: 코사인 유사도 및 유클리드 거리와 같은 유사도 메트릭은 사용자 행동과 선호도에 따라 제품이나 서비스를 추천하는 데 사용됩니다.
이미지 및 동영상 분석: 유클리드 거리, 맨해튼 거리 등의 유사도 메트릭은 이미지 및 동영상 분류, 객체 감지, 추적 작업에 사용됩니다.
클러스터링 및 분류: 유클리드 거리 및 코사인 유사도와 같은 유사도 메트릭은 클러스터링 및 분류 작업에서 유사한 데이터 포인트를 함께 그룹화하는 데 사용됩니다.
결론적으로 유사성 메트릭은 다양한 데이터 분석 및 머신 러닝 작업에서 중요한 도구입니다. 특정 작업에 가장 적합한 유사도 메트릭을 선택하려면 각 유사도 메트릭의 특성과 한계를 이해하는 것이 필수적입니다. 올바른 유사성 지표를 선택하면 결과의 정확성과 관련성을 개선하여 더 나은 의사 결정과 인사이트를 얻을 수 있습니다.

계속 읽기

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.