




라가스를 사용한 RAG 평가
*이 게시물은 크리스티 버그만, 샤훌 에스, 지틴 제임스가 작성했습니다.
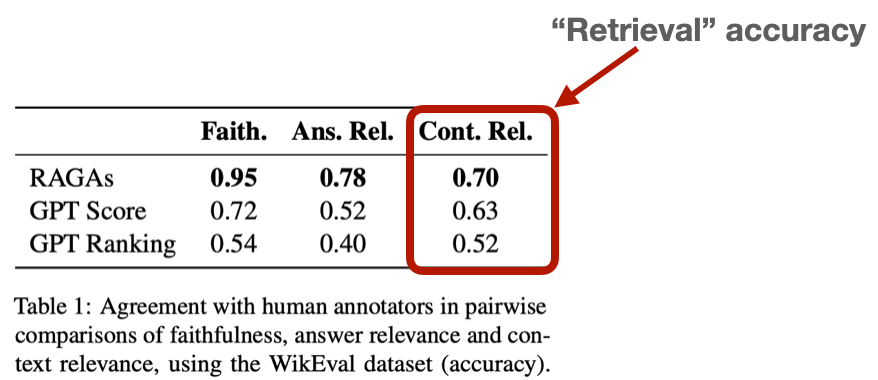
검색은 생성형 AI 시스템의 중요한 구성 요소이며, 특히 검색 증강 생성(RAG에서 그 과제가 잘 드러납니다.) 검색 증강 생성은 대규모 언어 모델(LLM)이 학습한 방대한 데이터를 기반으로 응답을 생성하여 AI 기반 챗봇을 향상시킵니다. RAG 시스템의 정교함에도 불구하고 검색 정확도는 WikiEval과 같은 벤치마크의 낮은 점수에서 알 수 있듯이 여전히 중요한 장애물로 남아 있습니다. 이러한 문제를 극복하기 위해서는 종합적인 평가 프레임워크를 구축하고 철저한 실험을 통해 RAG 매개변수를 미세 조정하고 최적의 성능을 달성하는 것이 필수적입니다.
**하지만 RAG 실험을 하기 전에 어떤 실험이 가장 좋은 결과를 가져왔는지 평가할 수 있는 방법이 필요합니다!
이미지 출처: https://arxiv.org/abs/2309.15217
라가스란 무엇인가요?
Ragas는 검색 증강 생성(RAG) 시스템의 성능을 평가하기 위해 고안된 전문 평가 프레임워크입니다. 이 프레임워크는 고급 LLM(대규모 언어 모델)을 판단 기준으로 활용하여 RAG 구현의 효율성을 평가하는 구조화된 접근 방식을 제공합니다. Ragas는 평가 프로세스를 자동화하는 데 중점을 두며, AI가 생성한 응답을 평가하기 위한 확장 가능하고 비용 효율적인 솔루션을 제공합니다. 이 프레임워크는 편견을 해결하고 자연어 결과물에 대해 설명 가능한 연속적인 점수를 제공하는 것을 목표로 합니다. Ragas는 직관적인 메트릭을 제공하고 검색 품질 평가 프로세스를 간소화하여 복잡한 RAG 시스템의 평가를 간소화합니다.
RAG 시스템 평가의 중요성
RAG 시스템을 효과적으로 평가하는 것은 AI 응답을 개선하는 데 필수적입니다. 강력한 평가 프레임워크는 실험에서 신뢰할 수 있는 결과를 도출하고 AI가 정확하고 상황에 적합한 답변을 제공할 수 있도록 보장합니다. 평가 프로세스를 자동화하면 이 작업을 간소화하고 가속화하여 비용 효율성과 확장성을 높일 수 있습니다.
LLM을 심사위원으로 활용하기
평가](https://arxiv.org/pdf/2306.05685)에 GPT-4와 같은 대규모 언어 모델(LLM)을 사용하는 것은 관련성 및 정확도 등 검색 품질의 다양한 측면을 평가할 수 있는 능력으로 인해 주목을 받고 있습니다. 한 LLM이 다른 LLM을 평가하는 것이 이상하게 보일 수도 있지만, 연구에 따르면 GPT-4는 약 80%의 경우 사람의 평가와 일치하며, 이는 사람의 합의에 대한 '베이지안 한계'와 일치하는 수치입니다. 이 방법은 평가 프로세스를 자동화하여 사람이 직접 라벨을 붙이는 것에 비해 확장성을 제공하고 비용을 절감할 수 있습니다.
LLM 기반 평가에 대한 접근 방식 ###
RAG 평가](https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications)의 판정자로 LLM을 사용하는 데는 크게 두 가지 접근 방식이 있습니다:
MT-Bench는 LLM을 사용하여 인간의 근거 자료로 확인된 질문-답변 쌍만 판단합니다. 사람이 처음에 질문과 답변을 심사하여 질문이 충분히 복잡한지 확인한 후 LLM이 80개의 Q-A 쌍을 사용하여 다양한 디코더(생성 AI 구성 요소)를 평가합니다. 논문, 코드, 리더보드.
라가스는 LLM을 직접 심사위원으로 사용하는 편견을 극복하는 패러다임을 형성하고 설명 가능하고 직관적으로 이해할 수 있는 연속 점수를 제공함으로써 자연어 산출물을 효과적으로 평가할 수 있다는 아이디어를 바탕으로 구축되었습니다). 논문, 코드, 문서.
이 블로그의 나머지 부분에서는 RAG 평가의 자동화와 확장성을 강조하는 Ragas를 소개합니다.
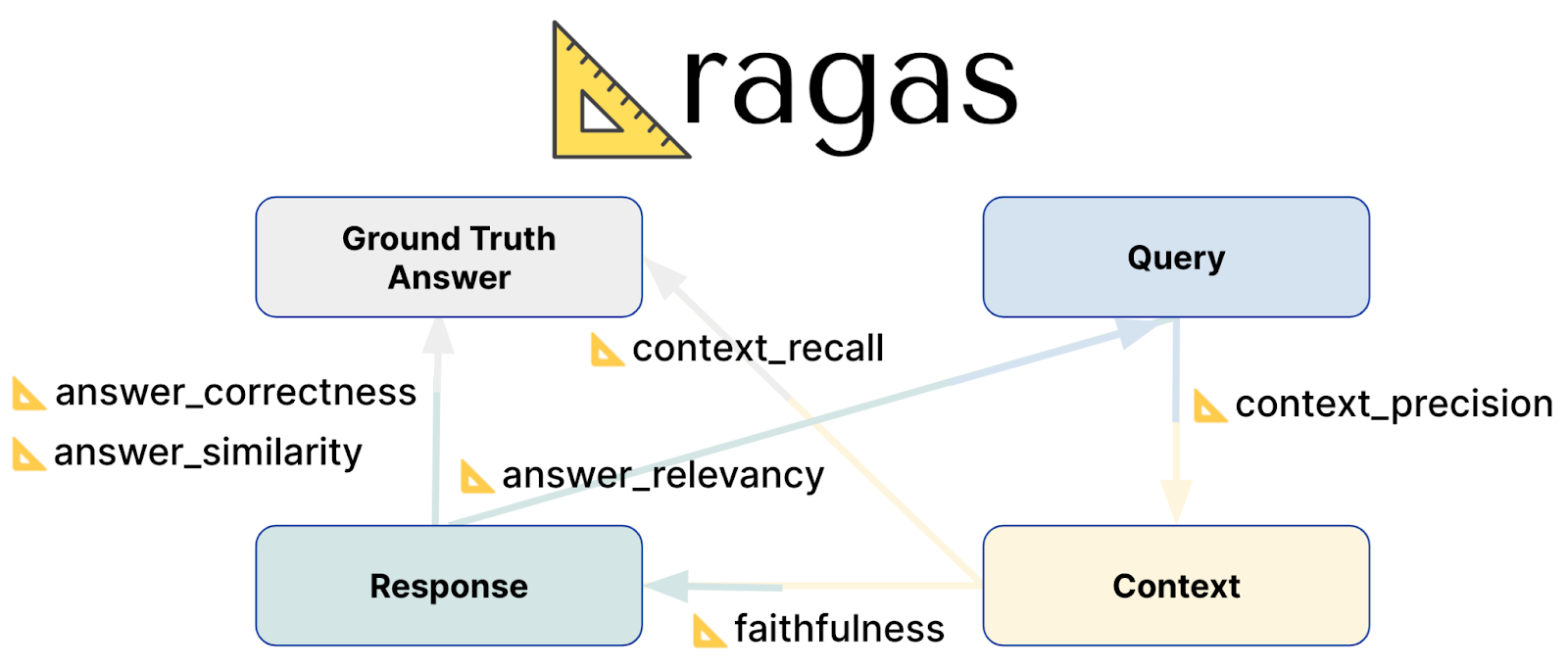
Ragas에 필요한 평가 데이터
Ragas 문서](https://docs.ragas.io/en/stable/howtos/applications/data_preparation.html)에 따르면 RAG 파이프라인 평가에는 네 가지 주요 데이터 포인트가 필요합니다.
질문: 질문.
컨텍스트: 질문의 의미와 가장 일치하는 데이터의 텍스트 청크입니다.
답변: 질문에 대한 RAG 챗봇의 생성된 답변입니다.
사실에 근거한 답변: 질문에 대한 예상 답변입니다.
 라가스 평가 지표
라가스 평가 지표
주요 평가 지표
기본 공식을 포함한 각 평가 지표에 대한 설명은 문서에서 확인할 수 있습니다. 예를 들어, 충실도. Ragas는 RAG 시스템의 효율성을 측정하기 위한 다양한 평가 점수를 제공합니다:
충실성: 이 점수는 생성된 답변이 제공된 맥락에서 정보를 얼마나 정확하게 반영하는지를 평가합니다. 답변의 사실적 정확성을 측정하여 답변이 도출된 문맥과 일치하는지 확인합니다. 점수는 0점에서 1점 사이이며, 점수가 높을수록 정확성과 일관성이 높음을 나타냅니다.
답변 관련성**: 이 답변 관련성 메트릭은 생성된 답변이 프롬프트에 얼마나 잘 응답하는지를 평가합니다. 답변의 완전성과 관련성에 중점을 두며, 불완전하거나 중복된 답변에 감점을 줍니다. 관련성 점수는 질문, 문맥 및 답변에서 파생되며, 점수가 높을수록 프롬프트와 더 잘 일치한다는 것을 반영합니다.
문맥 회상**: 문맥 회상은 검색된 문맥이 실제 답변과 얼마나 효과적으로 일치하는지를 측정합니다. 예상한 것과 비교하여 성공적으로 검색된 관련 조각의 비율을 계산합니다. 점수는 0에서 1 사이이며, 값이 높을수록 관련 문맥이 더 많이 검색되었음을 나타냅니다.
문맥 정확도: 이 메트릭은 관련성이 가장 높은 문맥 항목이 관련성이 낮은 항목보다 높은 순위를 차지하는지 여부를 평가합니다. 모든 관련성 있는 문맥 청크가 목록 상단에 표시되는지 여부를 확인합니다. 문맥 정확도는 질문, 근거 자료 및 문맥을 사용하여 결정되며, 점수가 높을수록 관련 정보의 순위가 더 높음을 나타냅니다.
문맥 관련성: 이 문맥 관련성 점수는 검색된 문맥이 질문과 얼마나 관련이 있는지를 평가합니다. 문맥이 쿼리의 의도와 일치하는 정도를 측정합니다. 측정 항목의 범위는 0에서 1까지이며, 값이 클수록 문맥이 질문과 관련성이 높다는 것을 나타냅니다.
- 컨텍스트 엔티티 리콜: 이 메트릭은 검색된 문맥이 기준 정보에 언급된 엔티티를 얼마나 잘 포착하는지를 계산합니다. 이 메트릭은 기준 자료의 총 개체 수 대비 문맥과 기준 자료 모두에서 발견된 개체의 비율을 측정합니다. 점수가 높을수록 문맥에서 중요한 엔티티를 더 잘 캡처하고 있음을 나타냅니다.
이러한 메트릭의 계산 방법에 대한 자세한 내용은 논문에서 확인할 수 있습니다.
RAG 평가 코드 예시
이 평가 코드는 이미 RAG 데모가 있다고 가정합니다. 데모에서는 검색을 위해 Milvus 기술 문서와 Milvus 벡터 데이터베이스를 사용하여 RAG 챗봇을 만들었습니다. 제 데모 RAG 노트북 및 평가 노트북의 전체 코드는 GitHub에 있습니다.
이 RAG 데모를 사용하여 질문을 하고, Milvus에서 RAG 컨텍스트를 가져오고, LLM에서 봇 응답을 생성했습니다(아래 마지막 두 칼럼 참조). 또한 동일한 질문에 대한 '사실에 근거한' 답변도 제공합니다(아래의 '컨텍스트' 열).
OpenAI, (HuggingFace) 데이터 세트, 라가스, 랭체인, 판다를 설치해야 합니다.
# 파이프 설치 OpenAI 데이터세트 ragas 랭체인 판다스
pandas를 pd로 가져옵니다.
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

팬더 데이터 프레임을 허깅페이스 데이터 집합으로 변환합니다.
에서 데이터 세트 가져오기 데이터 세트
def assemble_ragas_dataset(input_df):
question_list, truth_list, context_list = [], [], []
question_list = input_df.Question.to_list()
truth_list = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
context_list = [[context_list의 컨텍스트에 대한 컨텍스트]]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# 기준값 목록에서 HuggingFace 데이터셋을 생성합니다.
ragas_ds = Dataset.from_dict({"question": question_list,
"context": context_list,
"answer": rag_answer_list,
"ground_truth": truth_list
})
반환 RAGAS_DS
# 팬더 df에서 Ragas HuggingFace 데이터셋을 생성합니다.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

Ragas가 사용하는 기본 LLM 모델은 OpenAI의 gpt-3.5-turbo-16k이며, 기본 임베딩 모델은 text-embedding-ada-002입니다. 두 모델을 원하는 대로 변경할 수 있습니다.
OpenAI의 최신 블로그에서 가장 저렴하다고 발표했기 때문에 LLM-as-judge 모델을 고정된 gpt-3.5-turbo로 변경하겠습니다. 또한 블로그에서 새로운 임베딩이 압축 모드를 지원한다고 언급했기 때문에 임베딩 모델을 text-embedding-3-small로 변경했습니다.
아래 코드에서는 관련 문서의 검색 품질을 측정하는 데 초점을 맞추기 위해 RAG context 평가 지표만 사용하고 있습니다.
import os, openai, pprint
에서 OpenAI 가져오기
# 환경 변수에 API 키를 저장합니다.
openai_api_key=os.environ['OPENAI_API_KEY']
# 보고 싶은 메트릭을 선택합니다.
ragas.metrics에서 import ( context_recall, context_precision, faithfulness, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# llm-as-critic을 변경합니다.
ragas.llms에서 llm_factory 가져오기
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(모델=LLM_NAME)
# 임베딩도 변경합니다.
langchain_openai.embeddings에서 OpenAIEmbeddings를 가져옵니다.
ragas.embeddings에서 LangchainEmbeddingsWrapper를 가져옵니다.
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# 각 메트릭에 사용되는 기본 모델을 변경합니다.
메트릭의 메트릭에 대해
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# 데이터 집합을 평가합니다.
ragas에서 평가 가져오기
ragas_result = evaluate( ragas_input_ds,
metrics=[ context_precision, context_recall, 충실도, ],
llm=ragas_llm,
)
# 평가 보기.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

제 데모 RAG 노트북 및 평가 노트북의 전체 코드는 GitHub에서 확인할 수 있습니다.
결론
이 블로그에서는 자연어 AI 시스템을 발전시키기 위한 검색 증강 생성([RAG]) 기술(https://zilliz.com/learn/guide-to-chunking-strategies-for-rag)에 특히 중점을 두고 제너레이티브 AI에서 검색의 지속적인 과제에 대해 살펴봤습니다. 특정 데이터와 사용 사례에 맞게 RAG 매개변수를 최적화하여 최상의 성능을 보장하려면 효과적인 실험이 필수적입니다. 이제 LLM을 평가자로 사용하는 자동화를 통해 RAG 시스템의 평가를 크게 향상시킬 수 있습니다. 주요 RAG 평가 지표와 그 계산 방법을 다루며 실제 적용에 대한 인사이트를 제공합니다. 또한, Milvus 벡터 데이터베이스와 Ragas 패키지를 사용한 구현 예시를 통해 이러한 도구를 효과적으로 활용하여 RAG 평가 프레임워크를 개선하고 확장할 수 있는 방법을 보여주었습니다. 이러한 접근 방식은 평가 프로세스를 간소화할 뿐만 아니라 AI 기반 솔루션에서 컨텍스트 검색의 전반적인 효율성을 높여줍니다. 더 자세히 알아보려면 실제 애플리케이션을 조사하고, 문제를 해결하고, 향후 방향을 탐색하고, 모범 사례를 준수하고, 추가 리소스에 액세스하여 RAG 시스템 평가와 RAG 파이프라인 개선에 대한 이해를 심화하세요.

계속 읽기

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.