




NVIDIA RAPIDS cuVS가 탑재된 GPU의 Milvus
소개 ## 소개
프로덕션 환경에서의 성능은 AI 애플리케이션의 성공에 있어 매우 중요한 요소입니다. 사용자에게 더 빨리 결과를 제공할수록 더 좋습니다. 이러한 긴급성 때문에 최적화가 필요합니다.
실제 사례인 검색 증강 생성(RAG) 애플리케이션을 예로 들어 보겠습니다. RAG 시스템에서 벡터 검색은 사용자 경험을 강화하는 엔진으로, 쿼리에 따라 관련성 높은 결과를 제공합니다. 하지만 벡터 검색은 리소스 집약적인 작업이라는 것을 우리 모두 잘 알고 있습니다. 저장하는 데이터가 많을수록 계산에 더 많은 비용과 시간이 소요됩니다.
이러한 경우 AI 애플리케이션의 성능을 최적화할 수 있는 솔루션을 찾아야 합니다. 최근 질리즈가 주최한 비정형 데이터 밋업에서 엔비디아의 수석 엔지니어인 코리 노렛은 이 문제를 해결하기 위한 엔비디아의 최신 기술에 대해 설명했는데요, 이 기사에서 이를 살펴보겠습니다. 유튜브](https://youtu.be/pBaq3CcZOFc?t=1548)에서도 [Corey의 강연]을 확인할 수 있습니다.
특히 벡터 검색과 관련된 여러 알고리즘이 포함되어 있고 GPU의 가속 성능을 활용하는 NVIDIA에서 개발한 라이브러리인 cuVS에 초점을 맞출 것입니다. 이 라이브러리가 어떻게 벡터 검색 작업의 성능을 개선하고 전체 운영 비용을 최적화할 수 있는지 살펴보겠습니다. 그럼 더 이상 고민할 필요 없이 바로 시작해 보겠습니다!
벡터 검색과 그 안에서 벡터 데이터베이스의 역할
벡터 검색은 사용자의 쿼리와 검색 대상 문서가 모두 벡터로 표현되는 정보 검색 방식입니다. 벡터 검색을 수행하려면 쿼리와 문서(이미지, 텍스트 등)를 벡터로 변환해야 합니다.
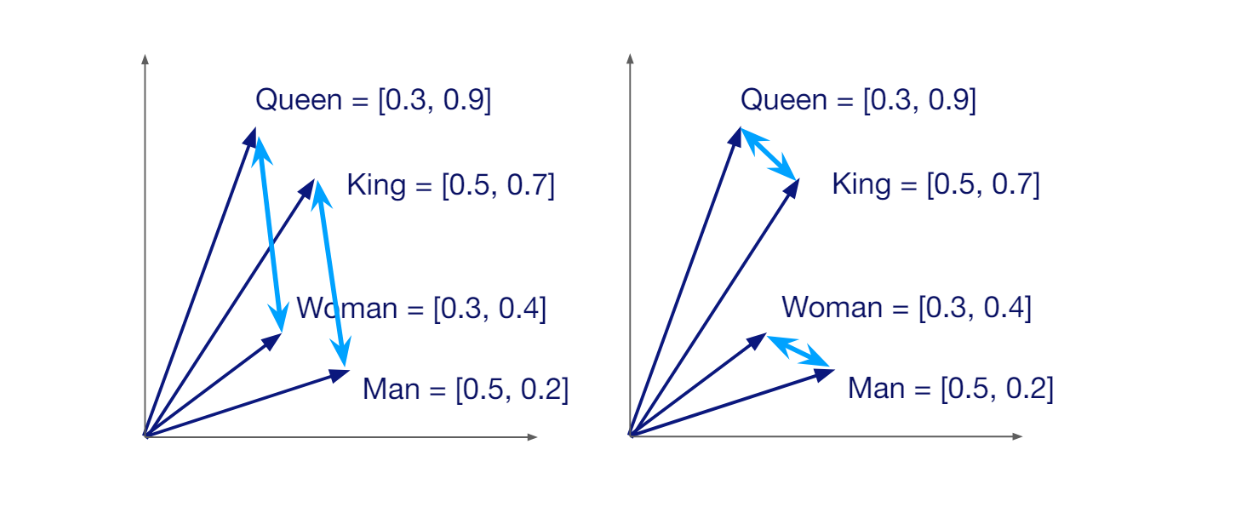
벡터는 생성하는 데 사용된 방법에 따라 특정 차원을 갖습니다. 예를 들어, all-MiniLM-L6-v2라는 HuggingFace 모델을 사용하여 쿼리를 벡터로 변환하면 차원이 384인 벡터를 얻게 됩니다. 벡터는 그것이 나타내는 데이터 또는 문서의 의미론적 의미를 전달합니다. 따라서 두 데이터가 서로 유사하면 해당 벡터는 벡터 공간에서 서로 가깝게 배치됩니다.
 벡터 공간에서 벡터 간의 의미적 유사성..png
벡터 공간에서 벡터 간의 의미적 유사성..png
벡터 공간에서 벡터 간의 의미적 유사성._.
각 벡터는 그것이 나타내는 데이터의 의미론적 의미를 전달한다는 사실 덕분에 임의의 벡터 쌍 사이의 유사도 계산이 가능합니다. 벡터가 비슷하면 유사도 점수가 높고, 그 반대의 경우도 마찬가지입니다. 벡터 검색의 주된 목적은 쿼리의 벡터와 가장 유사한 벡터를 찾는 것입니다.
몇 개의 문서를 다룰 때는 벡터 검색 구현이 비교적 간단합니다. 그러나 문서가 많아지고 더 많은 벡터를 저장해야 할수록 복잡성이 커집니다. 벡터가 많을수록 벡터 검색을 수행하는 데 시간이 더 오래 걸립니다. 또한 로컬 메모리에 더 많은 벡터를 저장하면 운영 비용도 크게 증가합니다. 따라서 확장 가능한 솔루션이 필요하며, 바로 여기에 벡터 데이터베이스가 등장합니다.
벡터 데이터베이스는 방대한 벡터 모음을 저장하기 위한 효율적이고 빠르며 확장 가능한 솔루션을 제공합니다. 벡터 데이터베이스는 벡터 검색 작업 중 더 빠른 검색을 위한 고급 인덱싱 방법을 제공할 뿐만 아니라, 널리 사용되는 AI 프레임워크와의 쉬운 통합을 통해 AI 애플리케이션의 개발 프로세스를 간소화합니다. 밀버스](https://milvus.io/) 및 질리즈 클라우드(관리형 밀버스)와 같은 벡터 데이터베이스에서는 벡터의 메타데이터를 저장하고 검색 작업 중에 고급 필터링 프로세스를 수행할 수도 있습니다.
 벡터 검색 작업의 전체 워크플로우..png
벡터 검색 작업의 전체 워크플로우..png
벡터 검색 작업의 전체 워크플로우._.
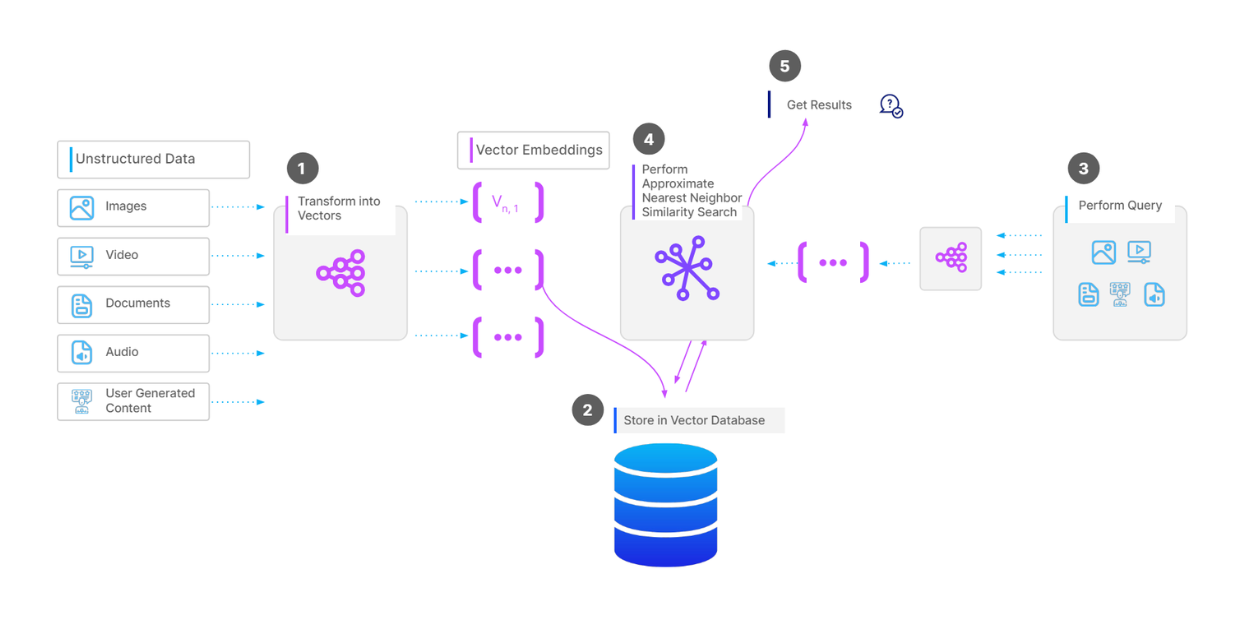
Milvus와 같은 벡터 데이터베이스에 벡터 모음을 저장하려면 먼저 데이터 유형에 따라 데이터 전처리를 수행해야 합니다. 예를 들어, 데이터가 문서 모음인 경우 각 문서의 텍스트를 청크로 분할할 수 있습니다. 다음으로, 선택한 임베딩 모델을 사용하여 각 청크를 벡터로 변환합니다. 그런 다음, 모든 벡터를 벡터 데이터베이스에 수집하고 벡터 검색 작업 중 더 빠른 검색을 위해 인덱스를 구축합니다.
쿼리가 있고 벡터 검색 작업을 수행하려는 경우, 앞서 사용한 것과 동일한 임베딩 모델을 사용해 쿼리를 벡터로 변환한 다음 데이터베이스의 벡터와의 유사도를 계산합니다. 마지막으로 가장 유사한 벡터가 반환됩니다.
CPU에서 벡터 검색 연산
벡터 검색 작업은 집중적인 계산을 필요로 하며, 벡터 데이터베이스에 더 많은 벡터를 저장할수록 계산 비용이 증가합니다. 인덱스 구축, 총 벡터 수, 벡터 차원, 원하는 검색 결과 품질 등 여러 가지 요인이 계산 비용에 직접적인 영향을 미칩니다.
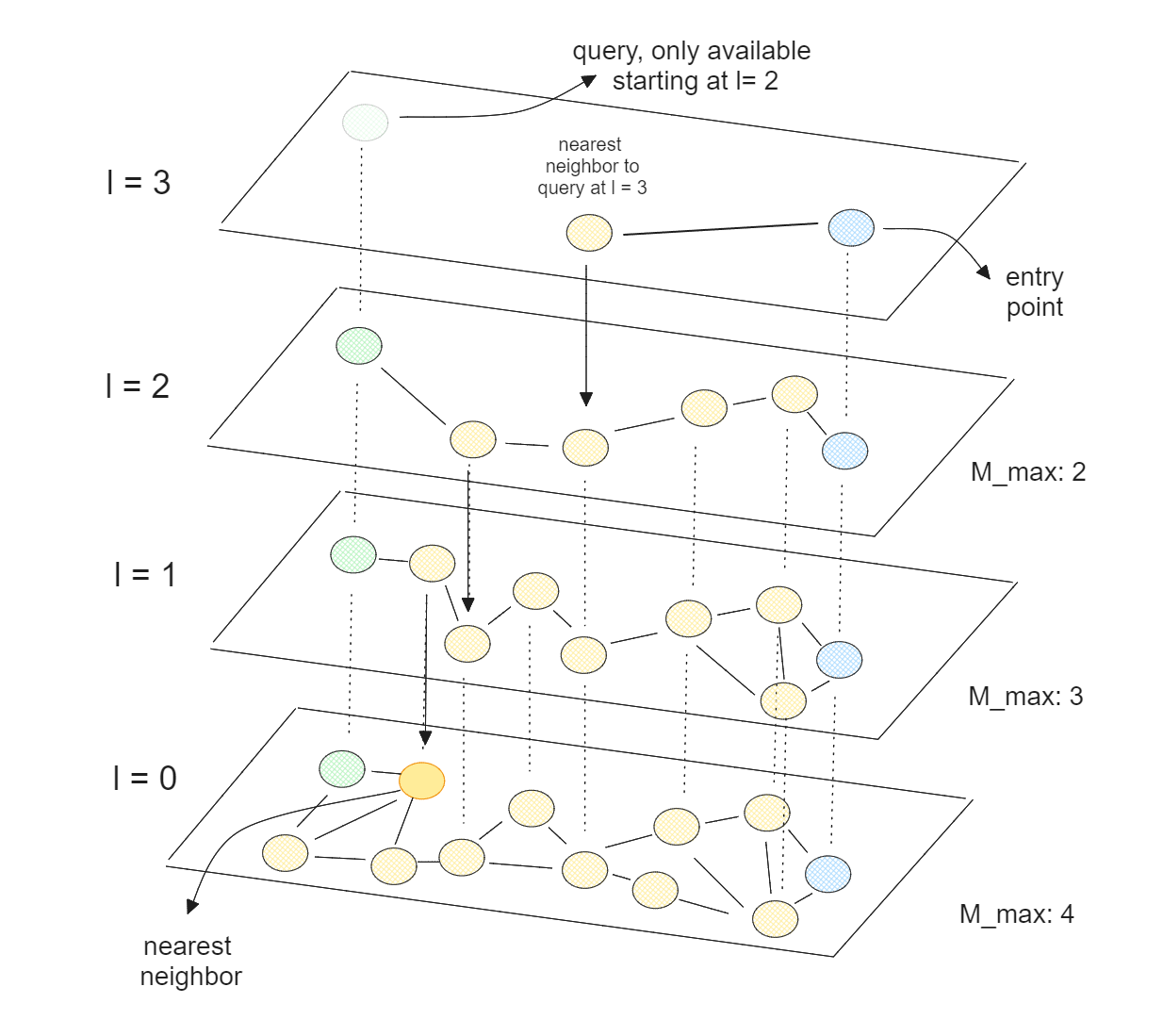
CPU는 비용 효율성이 높고 AI 애플리케이션의 다른 구성 요소와 쉽게 통합할 수 있기 때문에 벡터 검색 작업에 일반적으로 사용되는 처리 장치입니다. 많은 벡터 검색 알고리즘이 CPU에 완전히 최적화되어 있으며, 가장 널리 사용되는 알고리즘은 Hierarchical Navigable Small World(HNSW)입니다.
HNSW의 핵심은 스킵 리스트와 탐색 가능한 작은 세계(NSW)의 개념을 결합한 것입니다. NSW 알고리즘에서는 먼저 데이터 포인트를 무작위로 섞어 그래프를 만듭니다. 그런 다음 데이터 포인트를 하나씩 삽입하고, 각 포인트는 미리 정의된 수의 에지를 통해 가장 가까운 이웃과 연결됩니다.
 HNSW를 사용한 벡터 검색..png
HNSW를 사용한 벡터 검색..png
HNSW를 사용한 벡터 검색..
HNSW는 최하위 계층에는 모든 데이터 포인트가 포함되고 최상위 계층에는 데이터 포인트의 일부만 포함되는 다계층 NSW입니다. 즉, 계층이 높을수록 건너뛰는 데이터 포인트가 많아지는데, 이는 스킵 리스트 이론에 해당합니다.
HNSW를 사용하면 적은 수의 반복을 통해 다른 노드에서 대부분의 노드에 도달할 수 있는 그래프를 갖게 됩니다. 이 속성을 통해 HNSW는 그래프를 효율적으로 탐색하여 가장 가까운 이웃을 빠르게 찾을 수 있습니다. HNSW는 CPU에 최적화되어 있기 때문에 여러 CPU 코어에서 실행을 병렬화하여 벡터 검색 프로세스를 더욱 가속화할 수도 있습니다.
하지만 벡터 데이터베이스에 더 많은 데이터를 저장할수록 HNSW의 계산 시간은 여전히 느려집니다. 벡터의 차원이 매우 높으면 문제는 더욱 악화될 수 있습니다. 따라서 차원이 높은 벡터가 매우 많은 경우에는 다른 솔루션이 필요합니다.
GPU에서 벡터 검색 작업
대량의 고차원 벡터를 처리할 때 벡터 검색 성능을 향상시키는 한 가지 솔루션은 GPU에서 작업하는 것입니다. 이를 위해 여러 GPU에 최적화된 벡터 검색 구현이 포함된 라이브러리인 NVIDIA의 RAPIDS cuVS를 활용할 수 있습니다. 이 라이브러리는 벡터 검색 작업과 인덱스 구축 모두에 GPU 사용을 간소화합니다.
cuVS는 다음과 같은 여러 가지 근사 이웃 알고리즘을 제공합니다:
무차별 대입**: 데이터베이스의 각 벡터와 쿼리를 비교하는 철저한 최근접 이웃 검색.
IVF-Flat**: 데이터베이스의 벡터를 교차하지 않는 여러 분할로 나누는 근사 최인접 이웃(ANN) 알고리즘입니다. 그런 다음 쿼리는 동일한(그리고 선택적으로 인접한) 파티션에 있는 벡터와만 비교됩니다.
IVF-PQ**: 데이터베이스에 저장된 벡터의 메모리 사용량을 줄여주는 IVF-Flat의 양자화된 버전입니다.
cagra: HNSW와 유사한 GPU 네이티브 알고리즘.
 CAGRA 그래프 구성. .png
CAGRA 그래프 구성. .png
CAGRA 그래프 구성. Source._
이러한 최접근 이웃 알고리즘 중에서 CAGRA에 초점을 맞추겠습니다.
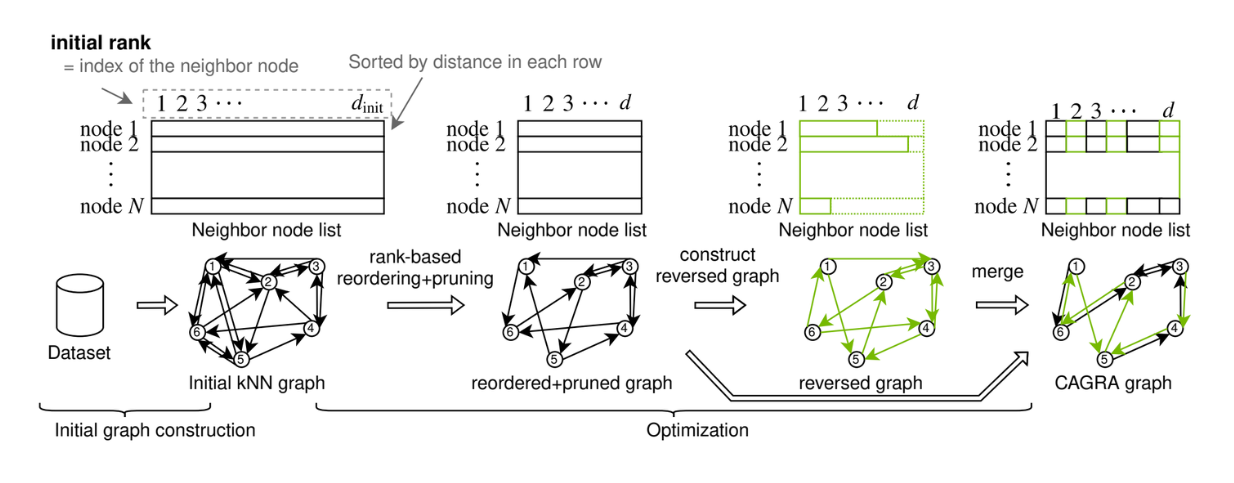
CAGRA는 GPU의 병렬 처리 성능을 활용하여 빠르고 효율적인 근사 근접 이웃 검색을 위해 NVIDIA에서 도입한 그래프 기반 알고리즘입니다.
CAGRA의 그래프는 IVF-PQ 방법 또는 NN-DESCENT 방법을 사용하여 구축할 수 있습니다:
IVF-PQ 방법**: 인덱스를 활용하여 각 점을 많은 이웃에 연결함으로써 메모리 효율적인 초기 그래프를 생성합니다.
NN-DESCENT 방법**: 반복적인 프로세스를 사용하여 점 사이의 연결을 확장하고 세분화하여 그래프를 구축합니다.
CAGRA의 그래프 구축 방식은 HNSW에 비해 병렬화가 쉽고 작업 간 데이터 상호 작용이 적어 그래프 또는 인덱스 구축 시간을 크게 개선할 수 있습니다. CAGRA에 대해 더 자세히 알아보려면 [[공식 논문](https://arxiv.org/pdf/2308.15136) 또는 [CAGRA 기사를 확인하세요.
CAGRA는 벡터 검색 작업에서 최첨단 성능을 자랑합니다. 이를 입증하기 위해 다음 섹션에서 HNSW와 성능을 비교해보겠습니다.
CAGRA와 HNSW 성능 비교
벡터 검색에서 성능이 중요한 두 가지 중요한 작업은 인덱스 구축과 검색 자체입니다. 이 두 가지 작업에서 CAGRA와 HNSW의 성능을 비교해 보겠습니다.
인덱스 구축부터 시작하겠습니다.
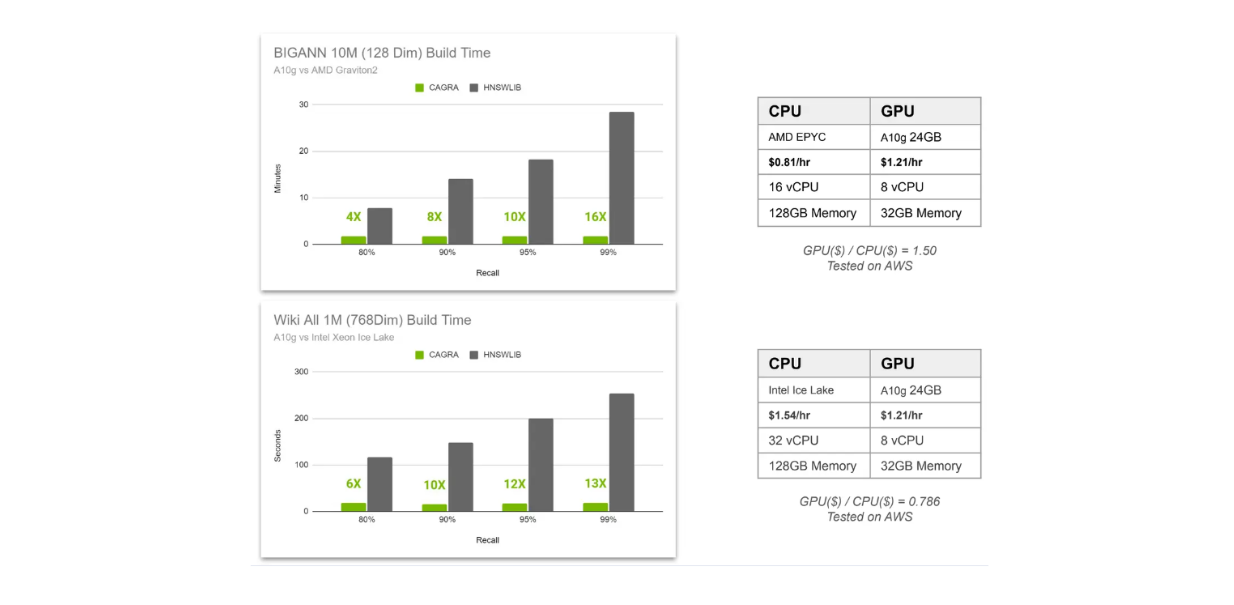 인덱스 구축 시간 비교 CAGRA vs HNSW..png
인덱스 구축 시간 비교 CAGRA vs HNSW..png
인덱스 구축 시간 비교 CAGRA vs HNSW.
위의 시각화에서는 두 가지 다른 시나리오에서 CAGRA와 HNSW의 인덱스 구축 시간을 비교합니다. 첫째, 벡터 데이터베이스에 1,000만 개의 128차원 벡터가 저장되어 있고 둘째, 1백만 개의 768차원 벡터가 저장되어 있습니다. 첫 번째 시나리오는 HNSW용 CPU로 AMD Graviton2를, CAGRA용 GPU로 A10G를 사용하고, 두 번째 시나리오는 HNSW용 CPU로 인텔 제온 아이스 레이크, CAGRA용 GPU로 A10G를 사용합니다.
80%에서 99%에 이르는 네 가지 리콜 값에서 인덱스 구축 시간을 비교합니다. 이미 알고 계시겠지만, 리콜이 높을수록 더 많은 연산이 필요합니다.
그래프 기반 벡터 검색에서는 각 계층에서 가장 가까운 이웃을 찾기 위해 고려하는 이웃의 수와 각 계층의 진입점으로 고려하는 가장 가까운 이웃의 수라는 두 가지 요소를 미세 조정할 수 있기 때문입니다. 리콜이 높을수록 더 많은 이웃을 고려하므로 검색 정확도가 높아지지만 계산 비용도 높아집니다.
위의 시각화를 보면, 높은 리콜을 가진 결과를 원할 때 GPU를 사용하면 더 많은 가치를 얻을 수 있음을 알 수 있습니다. 또한 벡터 데이터베이스에 저장된 고차원 벡터의 수가 증가함에 따라 GPU 사용으로 인한 속도 향상도 증가합니다.
다음으로, 벡터 검색에서 흔히 사용되는 두 가지 메트릭을 사용하여 HNSW와 CAGRA의 성능을 비교해 보겠습니다:
처리량**: 특정 시간 간격 동안 완료할 수 있는 쿼리 수입니다.
지연 시간**: 알고리즘이 쿼리 하나를 완료하는 데 필요한 시간.
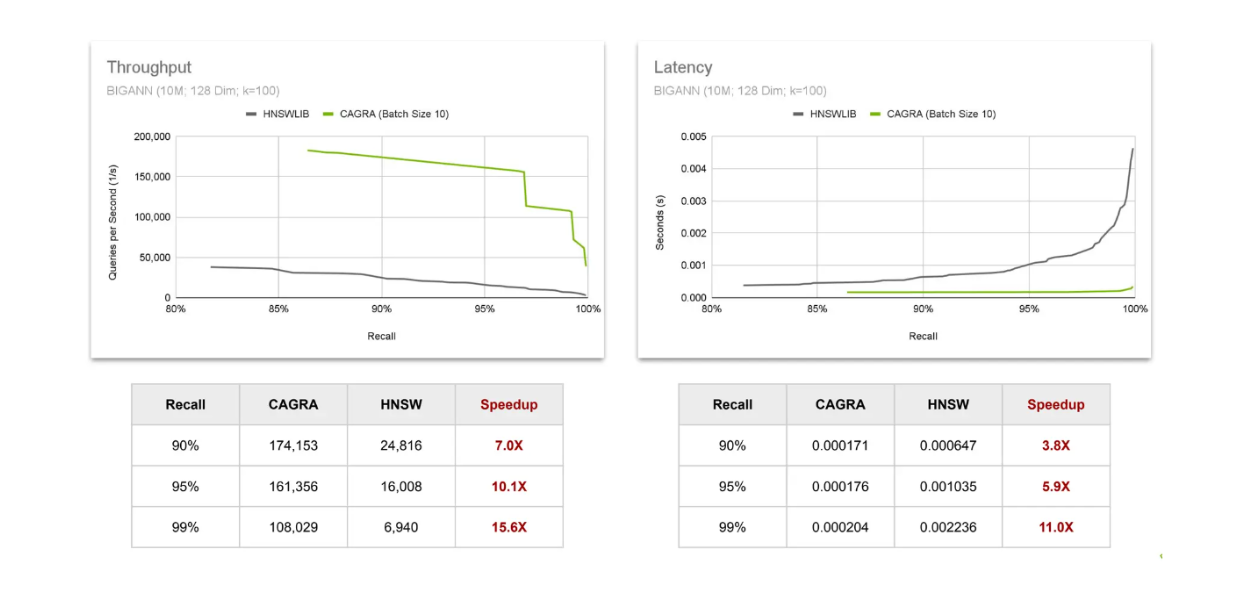 처리량 및 지연 시간 비교 CAGRA 대 HNSW..png
처리량 및 지연 시간 비교 CAGRA 대 HNSW..png
처리량 및 지연 시간 비교 CAGRA와 HNSW._.
처리량을 평가하기 위해 초당 완료할 수 있는 쿼리 수를 관찰합니다. 결과는 더 높은 리콜 값을 가진 결과를 요구할수록 GPU에서 CAGRA를 사용할 때 속도가 빨라지는 것을 보여줍니다. 지연 시간에서도 동일한 추세가 관찰되는데, 리콜 값이 증가할수록 속도가 빨라집니다. 이를 통해 벡터 검색에서 보다 정확한 결과를 얻을수록 GPU 사용의 가치가 증가한다는 것을 확인할 수 있습니다.
그러나 때로는 벡터 검색 중에 CPU를 사용하는 것이 더 간단하고 AI 애플리케이션의 다른 구성 요소와 쉽게 통합할 수 있기 때문에 여전히 CPU를 사용하고 싶을 때가 있습니다. 이 경우에도 CAGRA로 최인접 이웃 알고리즘을 구현하면 나중에 GPU와 CPU 모두에서 벡터 검색을 수행할 수 있으므로 여전히 유용합니다.
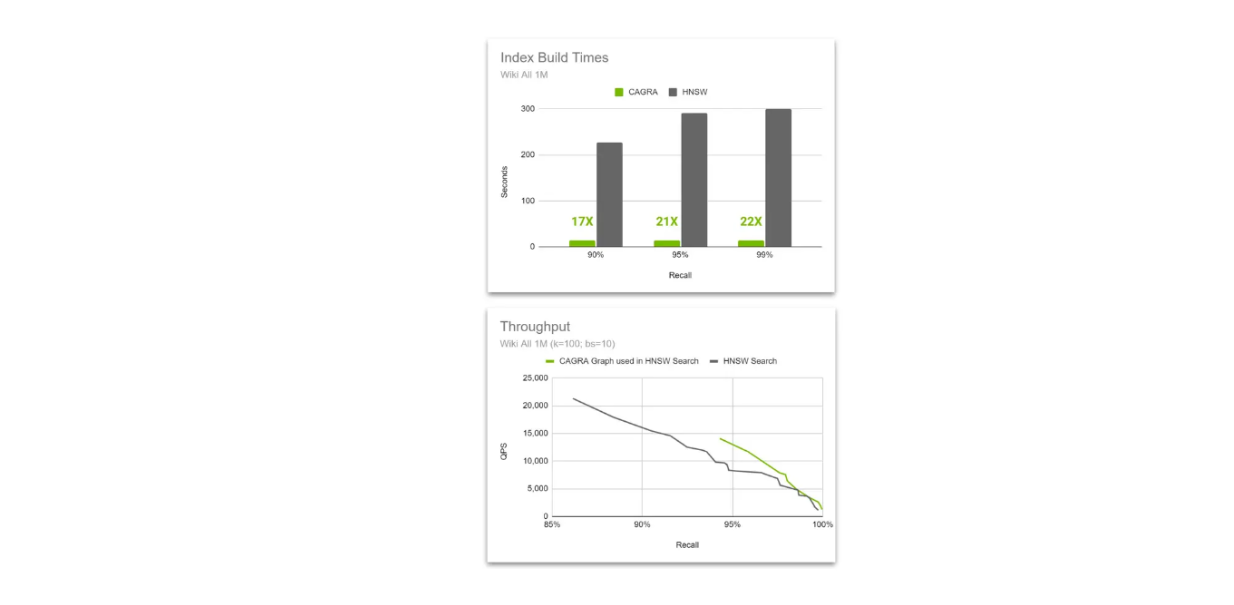 HNSW 검색에 사용되는 HNSW 네이티브와 CAGRA 그래프 간의 처리량 비교..png
HNSW 검색에 사용되는 HNSW 네이티브와 CAGRA 그래프 간의 처리량 비교..png
HNSW 검색에 사용되는 HNSW 네이티브 그래프와 CAGRA 그래프 간의 처리량 비교._.
이 아이디어는 인덱스 구축 중에는 CAGRA와 GPU의 가속 성능을 사용하다가 벡터 검색 중에는 HNSW로 전환하는 것입니다. 이 방식이 가능한 이유는 HNSW 알고리즘이 CAGRA로 구축한 그래프를 사용해 검색을 수행할 수 있고, 벡터 차원이 커질수록 HNSW로 구축한 그래프보다 성능이 더 우수하기 때문입니다.
또한 CAGRA는 저장된 벡터의 메모리를 더욱 압축하기 위해 CAGRA-Q라는 양자화 방법을 제공합니다. 이는 메모리 할당을 보다 효율적으로 하는 데 특히 유용하며, 양자화된 벡터를 더 작은 디바이스 메모리에 저장하여 더 빠르게 검색할 수 있도록 해줍니다.
호스트 메모리에 비해 메모리 크기가 더 작은 디바이스 메모리가 있다고 가정해 보겠습니다. NVIDIA의 초기 성능 벤치마크에 따르면 장치 메모리에 저장된 양자화된 벡터와 호스트 메모리에 저장된 그래프는 원래의 비정량화된 벡터와 장치 메모리에 저장된 그래프에 비해 더 높은 리콜률로 비슷한 성능을 보였습니다.
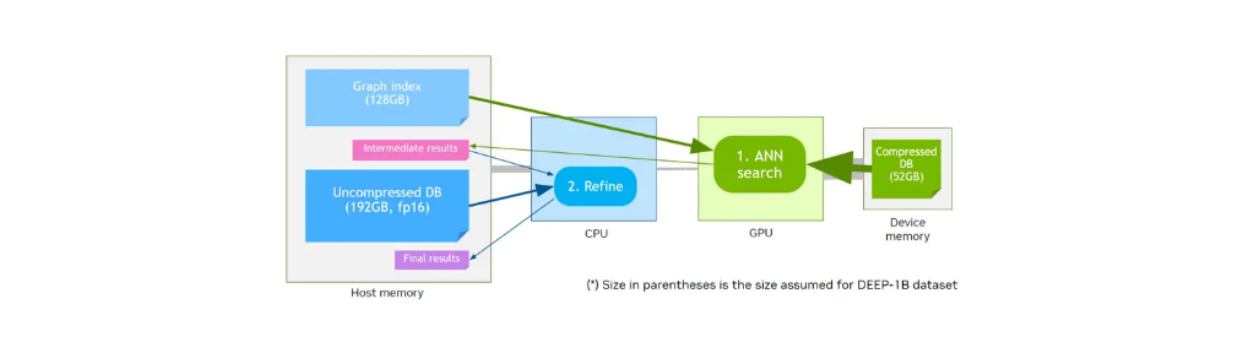 디바이스 메모리와 CAGRA-Q를 활용한 벡터 검색 워크플로
디바이스 메모리와 CAGRA-Q를 활용한 벡터 검색 워크플로
장치 메모리와 CAGRA-Q를 활용한 벡터 검색 워크플로.
CuVS를 사용한 GPU의 밀버스
Milvus** cuVS 라이브러리와의 통합을 지원하여 Milvus와 CAGRA를 결합하여 AI 애플리케이션을 구축할 수 있습니다. Milvus의 아키텍처는 인덱스 노드, 쿼리 노드, 데이터 노드와 같은 여러 노드로 구성되며, cuVS는 쿼리 노드와 인덱스 노드 내의 프로세스 가속화를 통해 Milvus의 성능을 최적화합니다.
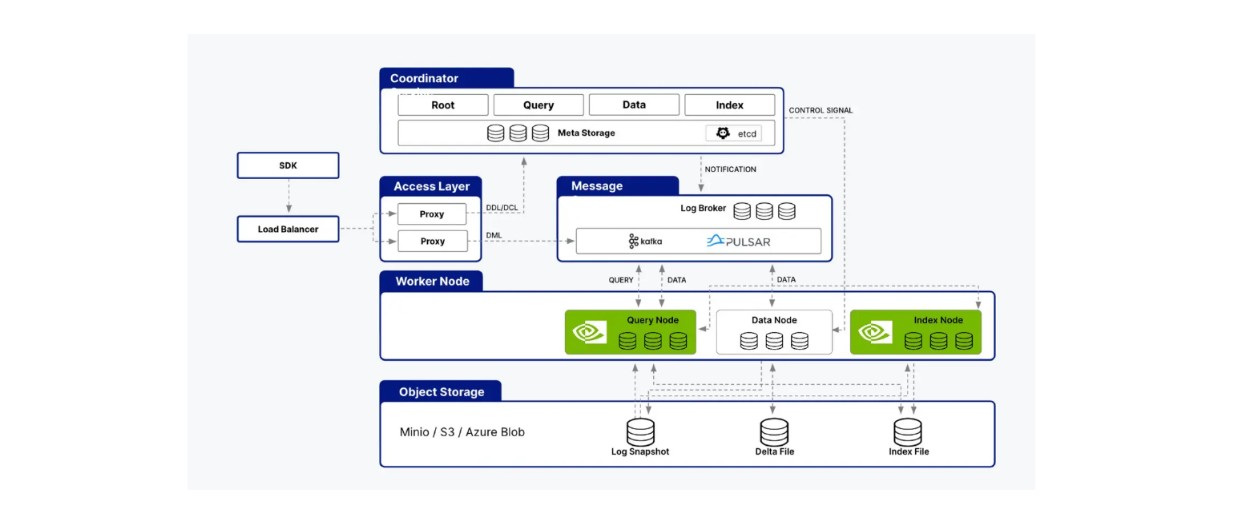 밀버스 아키텍처의 쿼리 노드와 인덱스 노드를 모두 지원하는 cuVS..png
밀버스 아키텍처의 쿼리 노드와 인덱스 노드를 모두 지원하는 cuVS..png
cuVS는 Milvus 아키텍처의 쿼리 노드와 인덱스 노드를 모두 지원합니다.
이미 알고 계시겠지만, 인덱스 노드는 인덱스 구축을 담당하고 쿼리 노드는 사용자 쿼리를 처리하고 벡터 검색을 수행하여 사용자에게 결과를 반환하는 역할을 합니다. 이전 섹션에서 HNSW와 같은 기본 CPU 알고리즘에 비해 CAGRA가 이러한 모든 측면을 어떻게 개선하는지 살펴봤습니다.
이제 cuVS와 온프레미스 Milvus를 사용한 인덱스 구축의 성능을 살펴보겠습니다. 특히, 다양한 수의 벡터에 대해 CAGRA와 IVF-PQ를 사용한 인덱스 구축 시간을 살펴보겠습니다: 10,000만, 20,000만, 40,000만, 8,000만.
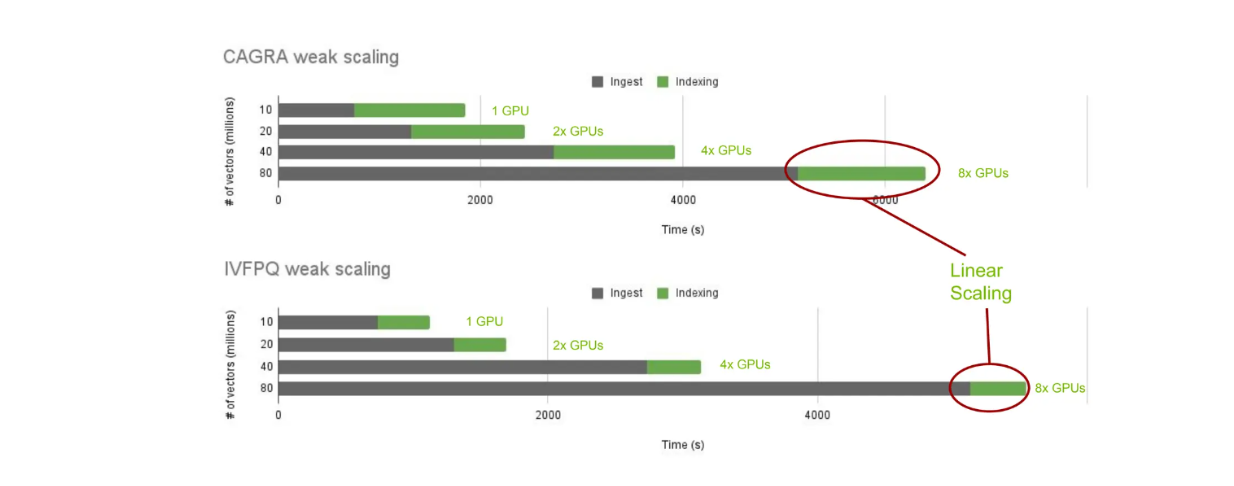 다양한 최접근 이웃 알고리즘에 걸친 인덱스 구축 시간의 cuVS 스케일링..png
다양한 최접근 이웃 알고리즘에 걸친 인덱스 구축 시간의 cuVS 스케일링..png
서로 다른 가장 가까운 이웃 알고리즘에 걸친 인덱스 구축 시간 스케일링 cuVS.
예상대로 저장된 벡터의 수가 증가함에 따라 수집 시간이 증가합니다. 그러나 저장된 벡터의 수에 따라 선형적으로 더 많은 GPU를 추가하기 때문에 인덱스 구축 시간은 일정하게 유지됩니다. 이를 통해 cuVS를 사용해 다양한 최인접 이웃 알고리즘의 인덱스 구축 시간을 확장하고 비교할 수 있습니다.
우리는 GPU가 CPU에 비해 더 빠른 연산 작업을 제공한다는 것을 알고 있습니다. 그러나 GPU를 사용하는 데 드는 운영 비용도 더 높습니다. 따라서 아래 그림과 같이 GPU와 CPU를 사용할 때의 비용 대비 성능 비율을 Milvus와 비교해야 합니다.
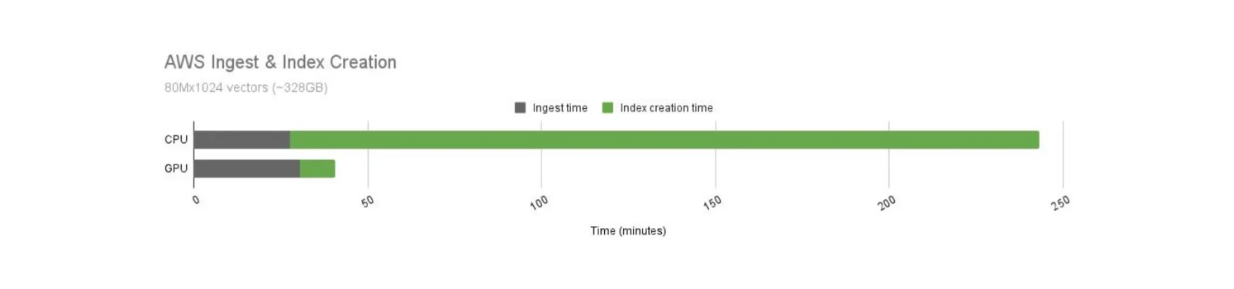 밀버스의 GPU와 CPU의 인덱스 구축 시간 비교..png
밀버스의 GPU와 CPU의 인덱스 구축 시간 비교..png
Milvus의 GPU와 CPU 간 인덱스 구축 시간 비교.png
GPU를 사용한 인덱스 구축 시간이 CPU보다 훨씬 빠릅니다. 이 사용 사례에서 GPU 가속 Milvus는 CPU에 비해 21배의 속도 향상을 제공합니다. 그러나 GPU의 운영 비용도 CPU보다 더 비쌉니다. GPU는 시간당 16.29달러, CPU는 시간당 9.68달러입니다.
GPU와 CPU의 비용 대비 성능 비율을 정규화하면 인덱스 구축에 GPU를 사용하면 여전히 더 나은 결과를 얻을 수 있습니다. 같은 비용으로 GPU를 사용하면 인덱스 구축 시간이 12.5배 더 빠릅니다.
또 다른 벤치마크 테스트에서는 6억 3,500만 1024차원 벡터에 대한 인덱스를 구축했습니다. 8개의 DGX H100 GPU를 사용해 IVF-PQ 방식으로 인덱스를 구축하는 데 약 56분이 걸렸습니다. 반면, CPU를 사용해 동일한 작업을 수행하면 약 6.22일이 소요됩니다.
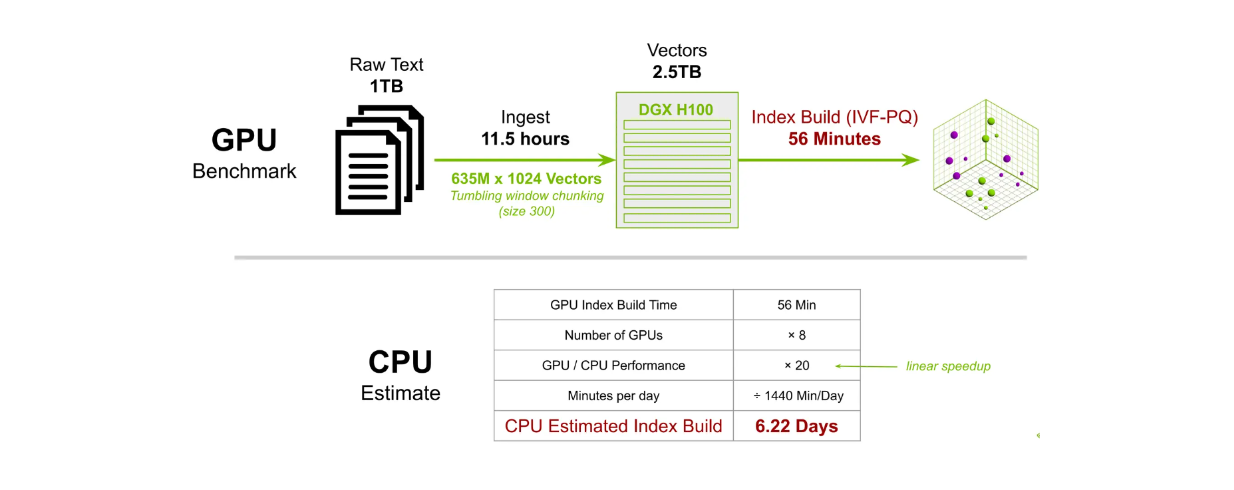 대규모 밀버스 인덱스 구축 시간 GPU와 CPU 비교..png
대규모 밀버스 인덱스 구축 시간 GPU와 CPU 비교..png
GPU와 CPU의 대규모 Milvus 인덱스 빌드 시간 비교._.
결론
NVIDIA의 cuVS 라이브러리와 CAGRA 알고리즘을 통한 GPU 가속 벡터 검색의 발전은 프로덕션 환경에서 AI 애플리케이션의 성능을 최적화하는 데 매우 유용합니다. 특히 GPU는 높은 리콜 값, 높은 벡터 차원, 많은 수의 벡터를 포함하는 경우 CPU에 비해 상당한 개선 효과를 제공합니다.
Milvus의 통합 기능 덕분에 이제 cuVS를 Milvus 벡터 데이터베이스에 쉽게 통합할 수 있습니다. GPU는 CPU보다 운영 비용이 더 높지만, 위의 벤치마크에서 볼 수 있듯이 대규모 애플리케이션에서는 여전히 성능 대비 비용 비율이 GPU를 선호하는 경우가 많습니다. cuVS에 대해 자세히 알아보려면 NVIDIA 팀에서 제공하는 [종합 문서]를 참조하세요.
추가 리소스
RAG란 무엇인가요? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
RAG 파이프라인의 성능을 향상시키는 방법](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Milvus 및 NVIDIA Merlin을 사용한 RecSys의 효율적인 벡터 검색](https://zilliz.com/blog/efficient-vector-similarity-search-recommender-workflows-using-milvus-nvidia-merlin)
계속 읽기

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.