




맞춤형 AI 모델로 RAG를 확장할 때의 인프라 과제
검색 증강 세대(RAG) 시스템은 보다 정확하고 맥락에 맞는 응답을 제공함으로써 AI 애플리케이션을 크게 향상시켰습니다. 그러나 이러한 시스템이 더욱 정교해지고 맞춤형 AI 모델을 통합함에 따라 프로덕션 환경에서 시스템을 확장하고 배포하는 데는 상당한 어려움이 있었습니다.
최근 질리즈가 주최한 비정형 데이터 밋업에서 BentoML의 설립자이자 CEO인 차오유 양은 맞춤형 AI 모델로 RAG 시스템을 확장할 때의 인프라 장애물에 대한 인사이트를 공유하고 BentoML 같은 도구가 어떻게 이러한 구성 요소의 배포와 관리를 간소화할 수 있는지에 대해 강조했습니다. 이 포스팅에서는 차오유 양의 핵심 사항을 요약하고 고급 추론 패턴과 최적화 기법을 살펴봅니다. 이러한 전략은 강력할 뿐만 아니라 효율적이고 비용 효율적인 RAG 시스템을 구축하는 데 도움이 될 것입니다.
RAG가 AI 애플리케이션을 강화하는 방법
검색 증강 생성(RAG) 시스템은 GenAI 애플리케이션의 환각 문제를 해결하기 위해 등장했습니다. 밀버스](https://zilliz.com/what-is-milvus) 및 질리즈 클라우드와 같은 벡터 데이터베이스의 벡터 유사도 검색 기능과 대규모 언어 모델(LLM)의 생성 능력을 통합함으로써 RAG 시스템은 AI 모델이 응답을 생성할 수 있게 해줍니다:
더 정확한
문맥 관련성
놀랍도록 유익한 정보
환각 없이
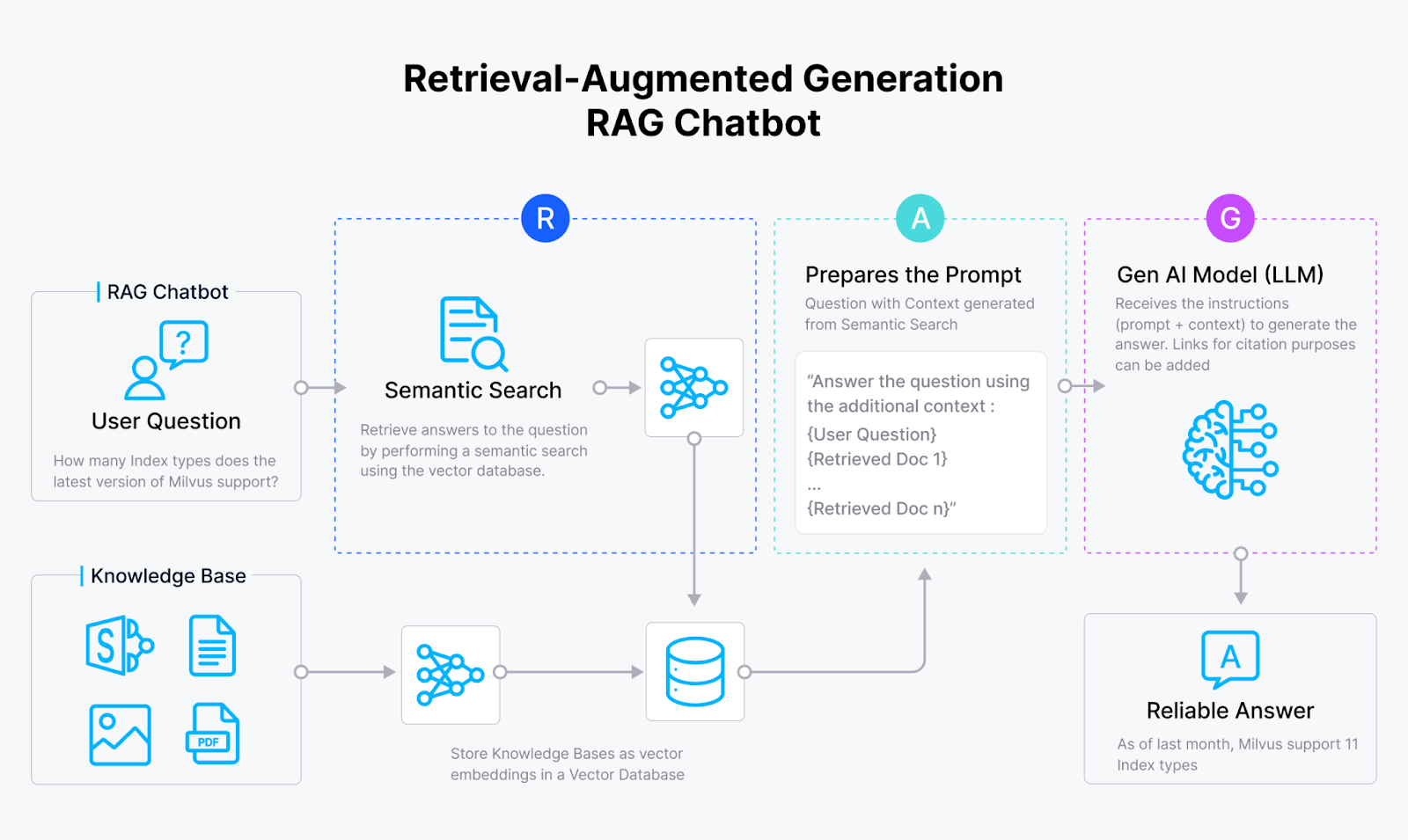
RAG 챗봇의 작동 원리_ 설명
이러한 시스템은 다음과 같은 다양한 분야를 혁신할 수 있는 잠재력을 가지고 있습니다:
질문-답변
문서 요약
개인화된 콘텐츠 생성
그리고 그 이상.
RAG 시스템은 AI 사서처럼 외부 소스에 숨겨진 방대한 지식을 활용하여 이러한 목표를 달성합니다!
프로덕션에 RAG 시스템을 배포할 때의 과제 ## 해결 방법
RAG 시스템이 프로덕션 환경에 적용되기까지 극복해야 할 과제가 있습니다. 가장 큰 장애물 중 하나는 최고 수준의 검색 성능을 보장하는 것이며, 여기에는 다음과 같은 것들이 포함됩니다:
리콜 최적화: **모든 관련 정보가 검색되는지 확인해야 합니다.
정확도 최적화:** 관련 없는 정보의 양 최소화
더욱 흥미로운 점은 RAG 시스템은 종종 복잡한 비정형 데이터 소스를 처리해야 한다는 점입니다. 만화책보다 더 많은 레이아웃, 표, 이미지가 포함된 PDF를 이해한다고 상상해 보세요! 이 문제는 상당히 정교한 문서 처리 및 이해 기술을 필요로 합니다.
RAG 시스템이 직면하는 또 다른 과제는 정확하고 문맥에 적합하며 사용자의 의도에 부합하는 응답을 생성하는 것입니다. 마치 여러 책의 단편만을 사용하여 일관된 이야기를 쓰는 것과 같습니다!
또한 생성된 콘텐츠의 안전성과 신뢰성을 보장하는 것도 매우 중요한데, 특히 위험 부담이 큰 경우에는 더욱 그렇습니다. AI 시스템이 잘못되어 잘못된 정보를 퍼뜨리는 것을 원하지 않습니다!
맞춤형 AI 모델은 이러한 상황에서 믿을 수 있는 조력자입니다. 개발자는 특정 도메인과 데이터 세트에 맞게 AI 모델을 미세 조정하고 조정함으로써 RAG 시스템에 이러한 문제를 정면으로 해결하는 데 필요한 강력한 기능을 부여할 수 있습니다.
맞춤형 AI 모델을 활용하여 RAG 성능 향상하기
RAG 시스템의 잠재력을 최대한 활용하려면 특정 사용 사례에 맞는 맞춤형 AI 모델을 활용하는 것이 중요합니다. 이러한 모델을 미세 조정하고 최적화함으로써 성능을 크게 향상시킬 수 있습니다. 맞춤형 AI 모델이 큰 영향을 미칠 수 있는 몇 가지 주요 영역을 살펴보겠습니다.
텍스트 임베딩 모델: RAG 성공의 토대
"text-embedding-ada-002"와 같은 기본 텍스트 임베딩 모델은 특정 도메인의 뉘앙스를 포착하는 데 부족한 경우가 많습니다. 이 모델은 MTEB 리더보드에서 57위에 랭크되어 있어 개선의 여지가 상당합니다.
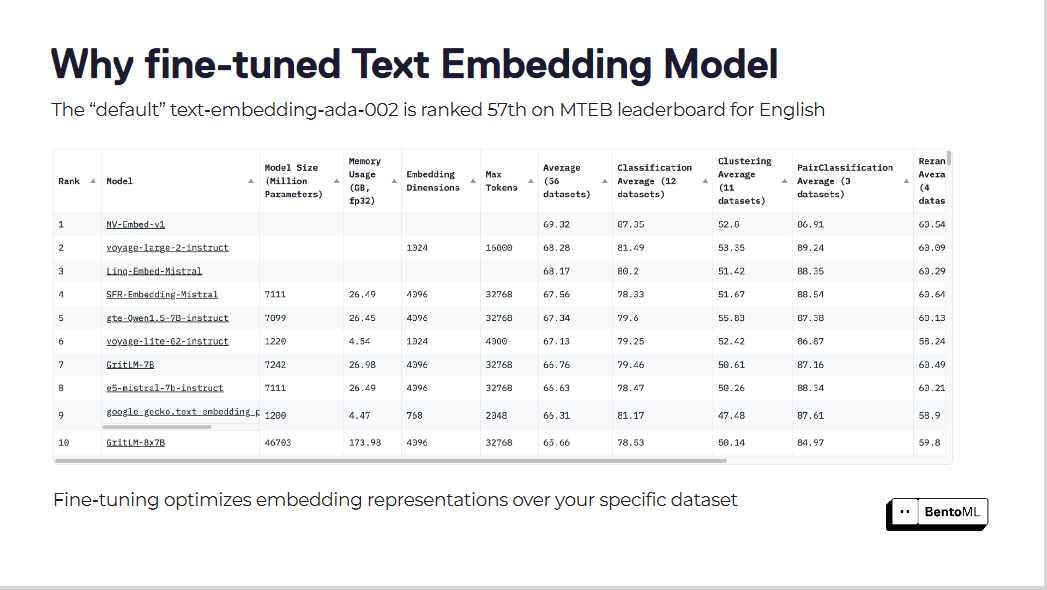
미세 조정을 통해 특정 데이터 세트에 대한 임베딩 표현을 최적화합니다.
이러한 임베딩 모델을 미세 조정하면 검색 점수가 현저하게 향상될 수 있습니다. 특정 데이터 세트에 대해 임베딩 모델을 최적화함으로써 RAG 시스템은 상당한 성능 향상을 보였습니다.
LLM 호스팅하기: 제어
독점 LLM은 편리함을 제공하지만 항상 요구 사항이나 제약 조건을 충족시키지 못할 수도 있습니다. 오픈 소스 LLM을 사용하면 요구 사항에 맞게 모델을 사용자 지정하고 조정할 수 있습니다. LLM을 호스팅할 때는 다음과 같은 주요 요소를 고려해야 합니다:
보안 및 데이터 개인정보 보호
지연 시간 및 성능
필요한 특정 기능
비용 및 확장성
유지 관리 및 지원
문서 처리 및 이해 비정형 데이터에서 인사이트 추출하기
RAG 시스템은 PDF, 이미지 등과 같은 복잡한 비정형 문서를 처리하고 이해해야 하는 경우가 많습니다. 다양한 모델과 기술을 통합하면 가치 있는 인사이트를 추출하는 데 도움이 될 수 있습니다. 예를 들어, 다음을 수행할 수 있습니다:
LayoutLM을 사용한 레이아웃 분석
테이블 트랜스포머 TATR을 사용한 테이블 감지
EasyOCR 또는 테서랙트를 사용한 OCR
LayoutLM v3 또는 Donut을 사용한 시각적 문서 QA
특정 문서 유형에 맞게 이러한 모델을 미세 조정하면 성능을 크게 향상시킬 수 있습니다.
검색 정확도 향상을 위한 고급 기술 ###
검색 정확도를 더욱 향상시키기 위해 다음 기술을 구현하는 것을 고려할 수 있습니다:
문맥 인식 청킹 및 글로벌 개념 인식 청킹:** 이러한 방법은 문서 내의 문맥과 중요한 개념을 고려하여 검색에 가장 관련성이 높은 정보를 식별하는 데 도움이 됩니다.
메타데이터 추출:** 문서에서 메타데이터를 추출하면 향상된 검색 및 응답 합성을 위한 추가 컨텍스트를 제공할 수 있습니다.
재랭커 모델:** 사용자 정의 데이터 세트에서 재랭커 모델을 미세 조정하면 일반 모델보다 10~30% 더 나은 성능을 얻을 수 있습니다.
이러한 주요 영역에서 맞춤형 AI 모델을 활용하면 RAG 시스템의 성능을 크게 향상시킬 수 있습니다.
하지만 이러한 모델을 효율적으로 배포하고 서비스하는 데는 여러 가지 어려움이 따릅니다. 다음 섹션에서는 사용자 지정 모델을 사용하여 RAG를 확장할 때 발생하는 몇 가지 인프라 문제에 대해 설명하겠습니다.
사용자 지정 모델을 사용하여 RAG를 확장할 때의 인프라 과제
RAG 시스템이 더욱 복잡해지고 여러 사용자 정의 모델을 통합함에 따라 컴퓨팅 리소스에 대한 요구와 효율적인 배포 및 관리에 대한 필요성이 크게 증가하고 있습니다. 맞춤형 AI 모델을 사용하여 검색 증강 생성(RAG) 시스템을 확장하는 것은 시급한 요구사항이 되었지만, 고유한 인프라 문제가 수반됩니다.
사용자 지정 모델 추론 API의 효율적인 제공
주요 과제 중 하나는 맞춤형 모델 추론 API를 효율적으로 제공하는 것입니다. RAG 시스템은 종종 다음과 같은 여러 모델을 통합해야 하는 경우가 많습니다:
텍스트 임베딩 모델
대규모 언어 모델(LLM)
문서 처리 모델
각 모델마다 계산 요구 사항과 성능 특성이 다를 수 있습니다. 이러한 모델을 실시간 요청을 처리하고 수요에 따라 확장할 수 있는 추론 API로 배포하는 것은 복잡합니다.
이 문제를 해결하려면 모델 추론 API를 제공하기 위한 강력하고 확장 가능한 인프라를 갖추는 것이 필수적입니다. 이 인프라는 GPU 할당, 메모리 관리, 지연 시간 제약과 같은 각 모델의 특정 요구 사항을 처리할 수 있어야 합니다. Docker와 같은 컨테이너화 기술은 모델 종속성을 캡슐화하고 여러 시스템에서 일관된 런타임 환경을 제공하는 데 도움이 될 수 있습니다.
효율적인 확장 메커니즘
그러나 단순히 모델을 컨테이너화하는 것만으로는 충분하지 않습니다. 인프라는 다양한 워크로드를 처리할 수 있는 효율적인 확장 메커니즘도 지원해야 합니다. 이러한 요구 사항에는 들어오는 요청 트래픽에 따라 모델 인스턴스 수를 자동으로 확장하고, 최적의 리소스 활용을 보장하며, 응답 시간을 최소화하는 기능이 포함됩니다.
모델 제공 최적화
또 다른 중요한 과제는 성능과 비용 효율성을 위해 모델 제공을 최적화하는 것입니다. 맞춤형 AI 모델, 특히 대규모 언어 모델은 계산 비용이 많이 들 수 있습니다. 순진한 배포 전략은 최적이 아닌 리소스 활용과 비용 증가로 이어질 수 있습니다. 여러 요청을 그룹화하여 GPU의 병렬성을 활용하는 동적 배치와 같은 기술을 사용하면 처리량을 크게 개선하고 응답 시간을 단축할 수 있습니다.
동적 배치 외에도 정량화, 프루닝, 모델 증류와 같은 다른 최적화 기술을 적용하여 사용자 지정 모델의 메모리 사용량과 계산 요구 사항을 줄일 수 있습니다. 그러나 이러한 최적화를 구현하려면 모델 성능과 리소스 효율성 간의 절충점을 신중하게 고려해야 합니다.
효율적인 리소스 할당 및 자동 확장
효율적인 리소스 할당 및 자동 확장은 사용자 지정 모델로 RAG 시스템을 확장하는 데 있어서도 중요한 측면입니다. 인프라는 각 모델의 워크로드 요구 사항에 따라 리소스를 동적으로 할당할 수 있어야 합니다. 이 접근 방식에는 GPU 사용률, 메모리 사용량, 요청 대기 시간 등의 주요 지표를 모니터링하여 정보에 입각한 확장 결정을 내리는 것이 포함됩니다. 자동 확장 메커니즘은 트래픽의 갑작스러운 급증을 처리하고 그에 따라 리소스를 확장하여 최적의 성능을 유지할 수 있어야 합니다.
여러 모델의 구성 및 오케스트레이션
또한 인프라는 RAG 시스템 내에서 여러 모델의 구성과 오케스트레이션을 지원해야 합니다. RAG 시스템에는 한 모델의 출력이 다른 모델의 입력으로 사용되는 복잡한 파이프라인이 포함되는 경우가 많습니다. 인프라는 이러한 파이프라인을 정의하고 관리하기 위한 도구와 프레임워크를 제공하여 원활한 데이터 흐름과 효율적인 실행을 보장해야 합니다.
모니터링 및 가시성
모니터링과 통합 가시성은 사용자 정의 모델을 사용하는 RAG 시스템의 상태와 성능을 유지하는 데 매우 중요합니다. 인프라는 모든 시스템 구성 요소에서 주요 메트릭, 로그 및 추적을 추적할 수 있는 포괄적인 모니터링 기능을 제공해야 합니다. 이를 통해 문제를 신속하게 감지 및 진단하고 실제 성능 데이터를 기반으로 시스템을 최적화 및 미세 조정할 수 있습니다.
지속적 통합 및 배포(CI/CD)
마지막으로, 인프라는 사용자 정의 모델의 지속적인 통합 및 배포(CI/CD)를 지원해야 합니다. 모델이 업데이트되고 개선됨에 따라 전체 시스템을 중단하지 않고도 새 버전을 배포할 수 있는 간소화된 프로세스를 구축해야 합니다. 이를 위해서는 RAG 시스템의 안정성과 신뢰성을 보장하기 위한 강력한 버전 관리, 테스트 및 롤백 메커니즘이 필요합니다.
이러한 인프라 문제를 해결하려면 도구, 프레임워크, 모범 사례의 조합이 필요합니다. 다음 섹션에서는 머신 러닝 모델을 제공하고 배포하는 플랫폼인 BentoML이 이러한 문제를 해결하고 맞춤형 AI 모델을 통해 RAG 시스템의 확장을 간소화하는 데 어떻게 도움이 되는지 살펴보겠습니다.
BentoML로 사용자 지정 모델을 위한 추론 API 구축하기
BentoML은 RAG 시스템에서 사용자 정의 모델을 위한 추론 API를 구축하고 배포하는 프로세스를 간소화합니다. 모델 개발에서 프로덕션 지원 API로의 원활한 전환을 제공하여 더 빠른 반복과 기존 시스템과의 손쉬운 통합을 가능하게 합니다. RAG 확장을 위한 인프라 문제를 극복하는 데 어떻게 도움이 되는지 알아보세요.
추론 스크립트에서 엔드포인트 서비스까지
단 몇 줄의 코드만으로 BentoML을 사용하여 추론 스크립트를 손쉽게 서빙 엔드포인트로 변환할 수 있습니다. 미세 조정된 텍스트 임베딩 모델을 위한 BentoML 서비스 생성 예시를 살펴보겠습니다:
import torch
from sentence_transformers import SentenceTransformer, models
클래스 SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
문장: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
이 코드 조각은 임베딩 모델과 관련 메서드를 캡슐화하기 위해 SentenceTransformers 클래스를 정의합니다. '__init__` 메서드 내에서 ``` SentenceTransformer모델은 미세 조정된 모델로 초기화되고 'cuda' 장치에서 실행되도록 설정됩니다. encode 메서드는 문장 목록을 입력으로 받아 그 임베딩을 NumPy 배열로 반환합니다.
이를 BentoML 서비스로 전환하려면 @bentoml.service`` 및 @bentoml.api`` 데코레이터를 추가하면 됩니다:
import bentoml
@bentoml.service
SentenceTransformers 클래스:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
문장: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
모델을 서비스하려면 BentoML CLI를 사용할 수 있습니다:
bentoml serve .
이 명령은 BentoML 서버를 시작하고 현재 디렉터리에 정의된 모델을 서비스합니다. CLI 출력은 서비스가 [http://localhost:3000](http://localhost:3000)에서 수신 대기 중임을 보여줍니다.
그런 다음 BentoML 클라이언트를 사용하여 제공된 모델에 요청을 할 수 있습니다:
import bentoml
bentoml.SyncHTTPClient("http://localhost:3000")를 클라이언트로 사용합니다:
결과: np.NDArray = client.encode(
sentences=["샘플 입력 문장"],
)
서빙 최적화
BentoML은 몇 가지 기본 제공 서비스 최적화를 제공합니다. 가장 강력한 최적화 중 하나는 동적 일괄 처리입니다. API 정의에 ```batchable=True`` 파라미터를 추가하면 BentoML은 수신 요청을 자동으로 일괄 처리하여 GPU 사용률을 최적화하고 모델 서빙의 처리량을 개선합니다.
@bentoml.api(batchable=True)
def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
동적 일괄 처리는 들어오는 요청을 그룹화하고, 큰 배치를 세분화하고, 배치 크기를 자동 조정하여 지능적으로 작은 배치를 형성합니다. 이 최적화를 통해 임베딩 서빙의 응답 시간이 최대 3배 빨라지고 처리량이 최대 200% 향상될 수 있습니다.
배포 및 서빙 인프라
BentoML은 유연하고 확장 가능한 배포 및 서빙 인프라를 제공합니다. Docker를 통한 컨테이너화, Kubernetes를 통한 오케스트레이션 등 다양한 배포 옵션을 지원합니다. GPU의 수와 유형 등 리소스 요구 사항을 쉽게 지정하고 동시성 및 외부 대기열과 같은 트래픽 설정을 구성할 수 있습니다.
import bentoml
@bentoml.service(
resources={
"GPU": 1,
"gpu_type": "엔비디아-테슬라-T4",
},
traffic={
"동시성": 512,
"external_queue": True
}
)
SentenceTransformers 클래스:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
BentoML의 적응형 마이크로 배치 및 탄력적 확장 기능은 들어오는 트래픽에 따라 최적의 리소스 활용과 자동 확장을 보장합니다. 또한 요청 속도, 응답 시간, 리소스 활용도에 대한 인사이트를 제공하는 사용자 친화적인 배포 대시보드도 제공합니다. 다음으로 BentoML로 LLM 추론을 확장하는 방법을 살펴보겠습니다.
BentoML로 LLM 추론 서비스 확장하기
BentoML은 LLM 추론 서비스를 효율적으로 확장하는 데 도움이 되는 포괄적인 기능과 최적화를 제공합니다.
자동 확장 전략
자동 확장은 LLM 추론 서비스가 다양한 워크로드를 처리하고 최적의 성능을 유지할 수 있도록 보장합니다. 그러나 GPU 사용률 및 초당 쿼리 수(QPS)와 같은 기존의 자동 확장 메트릭은 LLM 서비스에 필요한 복제본 수를 정확하게 반영하지 못할 수 있습니다.
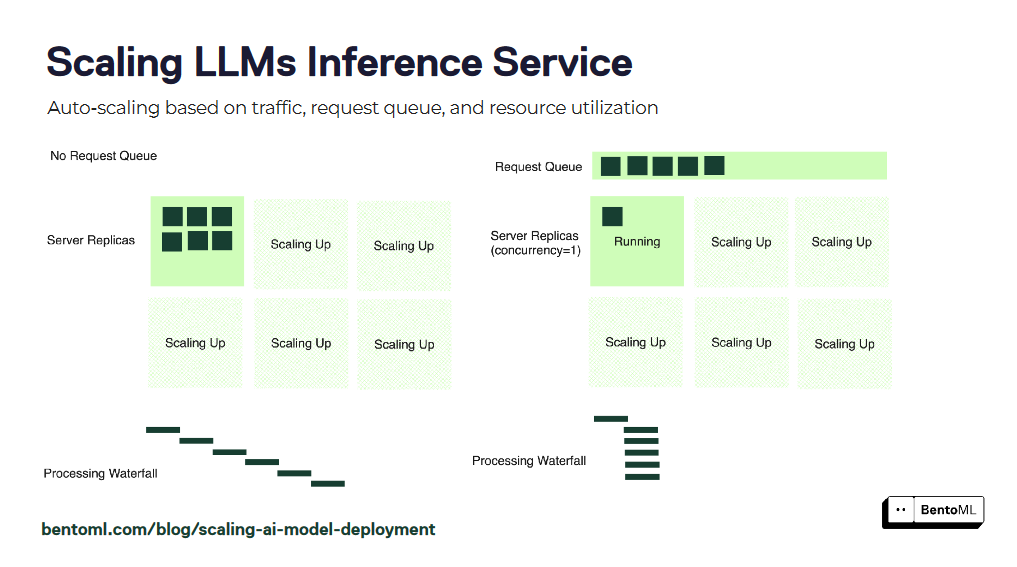
BentoML은 LLM 추론 서비스 확장을 위한 보다 효과적인 접근 방식인 동시성 기반 오토스케일링을 도입합니다. 동시성 기반 자동 확장은 각 모델 복제본이 처리할 수 있는 동시 요청의 수를 고려하여 서비스의 용량을 보다 정확하게 표현합니다.
콜드 스타트 최적화
콜드 스타트는 특히 대용량 컨테이너 이미지와 모델 파일로 LLM 추론 서비스를 확장할 때 중요한 문제가 될 수 있습니다. BentoML은 콜드 스타트 지연을 완화하기 위한 몇 가지 최적화 기술을 제공합니다.
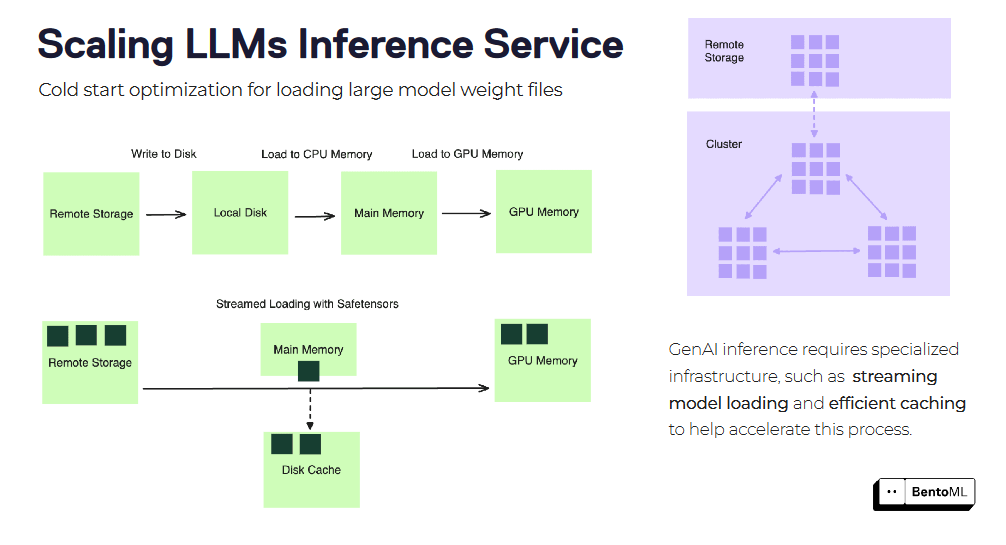
이러한 기법 중 하나는 컨테이너 이미지 스트림 로딩입니다. 서비스를 시작하기 전에 전체 컨테이너 이미지를 다운로드하는 대신 BentoML은 필요에 따라 필요한 파일만 가져와서 이미지를 스트리밍 로드할 수 있습니다. 이렇게 하면 새 복제본의 시작 시간을 크게 단축할 수 있습니다.
또 다른 최적화는 효율적인 모델 가중치 파일 로딩 및 캐싱입니다. BentoML은 로드된 모델 가중치를 여러 복제본에 캐시하여 각 새 요청에 대해 모델을 로드하는 데 필요한 시간을 단축할 수 있습니다. 이는 가중치 파일이 방대한 대규모 언어 모델에 특히 유용합니다.
BentoML의 자동 확장 전략과 콜드 스타트 최적화를 활용하면 LLM 추론 서비스를 효과적으로 확장하여 RAG 시스템의 수요를 처리할 수 있습니다. BentoML은 인프라 관리의 복잡성을 추상화하여 최적의 성능과 확장성을 보장하면서 모델 개발과 반복에 집중할 수 있도록 해줍니다.
RAG 시스템을 위한 고급 추론 패턴
RAG 시스템은 복잡한 워크플로우를 처리하고 성능을 최적화하기 위해 고급 추론 패턴이 필요한 경우가 많습니다. BentoML은 이러한 패턴을 지원하는 유연하고 확장 가능한 프레임워크를 제공하여 정교한 RAG 시스템을 쉽게 만들 수 있도록 지원합니다.
레이아웃 분석, 테이블 추출, OCR 등 여러 모델과 처리 단계를 결합하여 문서 처리 파이프라인을 구축할 수 있습니다.
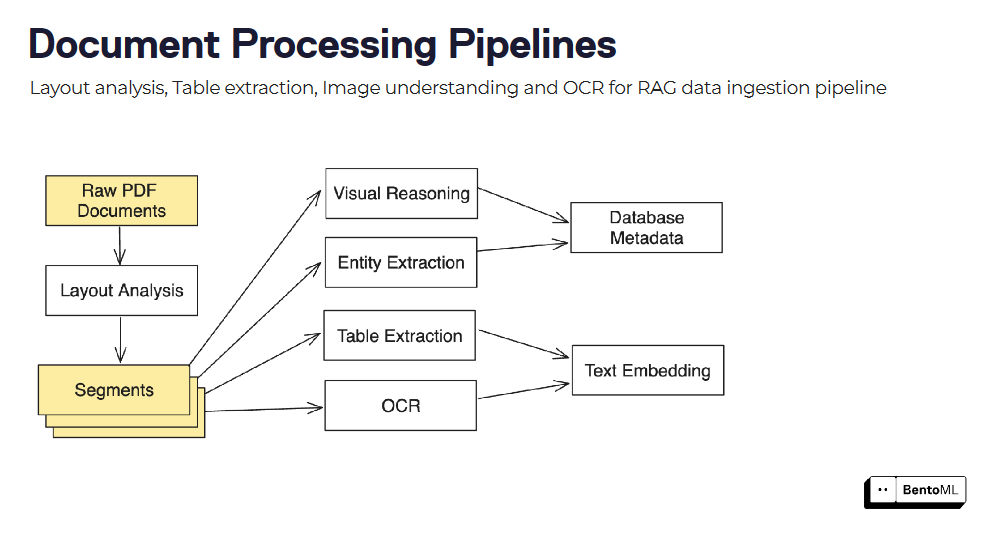
BentoML의 비동기 추론 인터페이스는 장기 실행 작업을 효율적으로 처리하며, 일괄 추론 지원으로 병렬 처리와 최적화를 활용하여 대규모 데이터 세트를 처리할 수 있습니다.
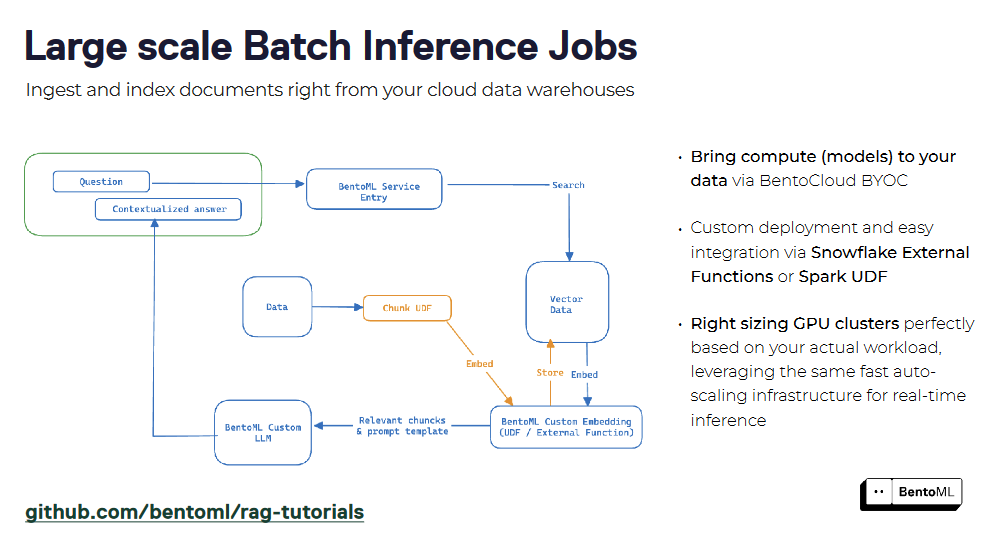
RAG 시스템은 BentoML을 사용하여 서비스 형태로 패키징하여 쿼리 및 상호 작용을 위한 통합 인터페이스를 생성할 수 있습니다. 리트리버와 제너레이터 구성 요소를 캡슐화하여 RAG 서비스를 쉽게 배포하고 다른 애플리케이션과 통합할 수 있습니다. 컨테이너화 및 오케스트레이션에 대한 BentoML의 지원은 프로덕션 환경에서 RAG 서비스의 확장 및 관리를 간소화합니다.
이러한 고급 추론 패턴은 다양한 작업과 워크로드를 처리하는 강력하고 효율적인 RAG 서비스를 구축하는 데 있어 BentoML의 유연성과 확장성을 보여줍니다.
LLM을 제공하기 위한 인프라 외에도 벡터 임베딩을 저장하고 유사성 검색을 수행하기 위한 강력한 벡터 데이터베이스도 필요합니다. 바로 이 부분에서 Milvus 벡터 데이터베이스가 도움이 됩니다. 다음 섹션에서는 BentoML과 Milvus를 사용해 간단한 RAG 앱을 구축하는 방법을 살펴보겠습니다.
BentoML과 Milvus 벡터 데이터베이스 통합하기
Milvus는 고성능 유사도 검색을 위해 설계된 오픈 소스 벡터 데이터베이스로, 검색 증강 생성(RAG) 구축의 핵심 인프라 구성 요소입니다.
Milvus는 BentoML과 통합되어 확장 가능한 RAG 애플리케이션을 더 쉽게 구축할 수 있습니다. 이 섹션에서는 BentoML과 Milvus 벡터 데이터베이스로 RAG 앱을 구축하는 과정을 안내합니다. 이 예제에서는 빠른 프로토타이핑을 위해 Milvus의 경량 버전인 Milvus Lite를 사용하겠습니다.
우리가 사용하는 데이터 세트는 여기에서 찾을 수 있습니다: 도시 데이터.
1단계: 환경 설정
먼저 아래와 같이 필요한 라이브러리를 설치합니다:
# 필요한 라이브러리 설치
pip install -U pymilvus bentoml
2단계: 데이터 준비
도시 데이터](https://github.com/ytang07/bento_octo_milvus_RAG/tree/main/data)를 다운로드하여 처리해 보겠습니다.
import os
요청 가져오기
import urllib.request
# 데이터 소스 설정
repo = "ytang07/bento_octo_milvus_RAG"
디렉터리 = "데이터"
save_dir = "./city_data"
api_url = f"https://api.github.com/repos/{repo}/contents/{directory}"
# GitHub에서 파일 다운로드
response = requests.get(api_url)
data = response.json()
os.path.exists(save_dir):
os.makedirs(save_dir)
데이터의 항목에 대해
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# 다운로드한 데이터 처리
def chunk_text(filename):
with open(filename, "r") as f:
text = f.read()
sentences = text.split("\n")
반환 [sentences의 s에 대해 len(s) > 7이면 s]]
cities = os.listdir("city_data")
city_chunks = []
도시의 도시에 대해
청크 = 청크_텍스트(f"city_data/{city}")
city_chunks.append({
"city_name": city.split(".")[0],
"청크": 청크
})
3단계: BentoML 클라이언트 설정
이제 아래와 같이 임베딩 모델과 LLM 모두에 대해 BentoML 클라이언트를 설정하겠습니다.
import bentoml
# 엔드포인트와 API 토큰을 설정합니다.
embedding_endpoint = "your_embedding_model_endpoint"
llm_endpoint = "your_llm_endpoint"
api_token = "your_api_token"
# BentoML 클라이언트 초기화
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
플레이스홀더 엔드포인트와 토큰을 실제 BentoML 배포 엔드포인트와 API 토큰으로 바꾸세요. 이러한 클라이언트를 사용하면 임베딩을 생성하고 텍스트 생성을 위해 언어 모델을 사용할 수 있습니다.
4단계: 임베딩 생성****
임베딩을 생성하기 전에 아래와 같이 임베딩 함수를 생성해 보겠습니다:
임베딩 함수 생성하기
def get_embeddings(text):
# 대량의 텍스트 일괄 처리
len(text) > 25:
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
embeddings = []
분할 분할의 경우:
embedding_split = embedding_client.encode(sentences=split)
임베딩 += 임베딩_스플릿
임베딩 반환
# 소량 배치 직접 처리
반환 embedding_client.encode(sentences=texts)
이 함수는 임베딩 모델에 입력 크기 제한이 있을 수 있으므로 큰 텍스트 세트에 대한 일괄 처리를 처리합니다.
모든 청크에 대해 임베딩을 생성합니다.
entries = []
도시_청크의 city_dict에 대해:
# 각 도시의 텍스트 청크에 대한 임베딩을 가져옵니다.
embedding_list = get_embeddings(city_dict["chunks"])
# 임베딩과 메타데이터로 항목 만들기
for i, embedding in enumerate(embedding_list):
entry = {
"embedding": 임베딩,
"문장": city_dict["청크"][i],
"city": city_dict["city_name"],
}
entries.append(entry)
여기서는 임베딩, 원본 문장, 도시 이름이 각각 포함된 항목 목록을 만들고 있습니다. 이 구조는 Milvus에 데이터를 삽입할 때 유용합니다.
5단계: Milvus 설정
이제 Milvus를 사용하여 임베딩을 추가하기 위해 벡터 데이터베이스를 초기화하겠습니다.
밀버스 클라이언트 초기화 및 스키마 생성하기
pymilvus에서 MilvusClient, DataType을 가져옵니다.
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # 임베딩 모델의 출력 차원과 일치해야 합니다.
# 밀버스 클라이언트 초기화
밀버스_클라이언트 = 밀버스클라이언트("milvus_demo.db")
# 스키마 생성
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
여기서는 애플리케이션에 임베드된 Milvus lite를 사용하고 있습니다. 스키마는 자동 생성된 ID와 임베딩 벡터를 포함하여 Milvus의 데이터 구조를 정의합니다.
인덱스 매개변수를 준비하고 컬렉션을 생성합니다.
# 인덱스 매개변수 준비
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="임베딩",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# 컬렉션 생성 또는 재생성
밀버스_클라이언트.has_collection(collection_name=COLLECTION_NAME):
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
milvus_client.create_collection(
collection_name=COLLECTION_NAME, schema=schema, index_params=index_params
)
데이터에 따라 최적의 인덱스 유형을 자동으로 선택하는 AUTOINDEX를 사용하고 있습니다. 벡터 비교를 위한 거리 메트릭으로 코사인 유사도가 사용됩니다.
밀버스에 데이터 삽입하기
이제 아래와 같이 Milvus에 데이터를 삽입합니다.
# 밀버스에 전처리된 데이터 삽입하기
밀버스_클라이언트.삽입(컬렉션_이름=컬렉션_이름, 데이터=엔트리)
이 단계에서는 전처리된 모든 데이터(임베딩 및 메타데이터)를 Milvus 컬렉션에 삽입합니다.
6단계: RAG 구현****
RAG를 효율적으로 구현하기 위해 아래와 같이 RAG 응답을 생성하고, 컬렉션에서 관련 컨텍스트를 검색하고, 답변을 생성하는 세 가지 함수를 생성합니다:
LLM이 답변을 생성하는 함수 만들기
def generate_rag_response(question, context):
# LLM을 위한 프롬프트 준비
prompt = (
f"당신은 유용한 도우미입니다. 컨텍스트만을 기반으로 사용자 질문에 답하세요: {context}. \n"
f"사용자 질문은 {질문}입니다."
)
# LLM을 사용하여 응답 생성
results = llm_client.generate(max_tokens=1024, prompt=prompt)
반환 "".join(results)
이 함수는 검색된 컨텍스트와 사용자의 질문을 사용하여 프롬프트를 구성한 다음 LLM을 사용하여 응답을 생성합니다.
관련 컨텍스트를 검색하는 함수 만들기****
def retrieve_context(question):
# 질문에 대한 임베딩 생성
embeddings = get_embeddings([question])
# 밀버스에서 유사한 벡터를 검색합니다.
res = milvus_client.search(
collection_name=COLLECTION_NAME,
data=embedings,
anns_field="embedding",
limit=5,
output_fields=["문장"],
)
# 관련 문장 추출 및 결합
문장 = [히트["엔티티"]["문장"] 히트에서 히트에서 히트]
반환 ". ".join(sentences)
이 함수는 사용자의 질문을 임베드하고 밀버스에서 유사한 벡터를 검색한 다음 문맥에 맞는 해당 텍스트 청크를 검색합니다.
위의 함수를 결합하여 RAG 파이프라인을 생성합니다.
def ask_question(question):
# 관련 컨텍스트 검색
context = retrieve_context(question)
# 컨텍스트와 질문을 기반으로 답변 생성
return generate_rag_response(question, context)
이 함수는 모든 것을 하나로 묶어 RAG 파이프라인을 생성합니다.
7단계: RAG 시스템 사용****
이제 RAG 시스템을 사용하여 아래와 같이 질문에 답할 수 있습니다:
# 사용 예
question = "캠브리지는 어떤 주에 있나요?"
answer = ask_question(question)
print(f"Question: {question}")
print(f"Answer: {answer}")
이 예는 RAG 시스템을 사용하여 도시에 대한 특정 질문에 답하는 방법을 보여줍니다.
중요 참고 사항:
이 코드를 실행하기 전에 임베딩 및 대규모 언어 모델이 BentoML에 올바르게 배포되었는지 확인하세요.
임베딩의 차원(이 예에서는 384)이 임베딩 모델의 출력과 일치해야 합니다.
이 설정은 소규모 데이터 세트에 적합한 Milvus Lite를 사용합니다. 대규모 애플리케이션의 경우 Docker 또는 K8에서 전체 Milvus 배포를 사용하는 것을 고려하세요.
RAG 시스템의 효율성은 초기 도시 데이터의 품질과 커버리지에 따라 달라집니다. 최상의 결과를 얻으려면 데이터 세트가 포괄적이고 정확한지 확인하세요.
BentoML과 Milvus의 통합으로 제공된 도시 정보를 기반으로 질문에 답할 수 있는 강력한 RAG 시스템을 구축할 수 있습니다. 데이터를 더 추가하거나 특정 사용 사례에 맞게 미세 조정하여 이 시스템을 확장할 수 있습니다.
결론
맞춤형 AI 모델을 사용하여 검색 증강 생성(RAG) 시스템을 구축하고 확장하는 데는 고유한 과제가 있습니다. 개발자는 맞춤형 모델의 성능을 활용하고, 배포 및 서비스 인프라를 최적화하고, 고급 추론 패턴을 채택하여 고성능의 확장 가능한 RAG 시스템을 만들 수 있습니다.
BentoML은 이 여정에서 매우 유용한 도구입니다. 추론 API 구축 및 배포 프로세스를 간소화하고, 서비스 성능을 최적화하며, 원활한 확장을 가능하게 해줍니다.
조직은 BentoML을 Milvus 벡터 데이터베이스와 통합함으로써 더욱 강력하고 확장 가능한 RAG 시스템을 구축할 수 있습니다. 이러한 조합을 통해 관련 정보를 효율적으로 검색하고 상황에 맞는 응답을 생성하여 다양한 영역과 산업에 걸쳐 고급 AI 애플리케이션의 가능성을 열 수 있습니다.
BentoML과 RAG에 대한 자세한 내용은 다음 리소스를 참조하세요.
밀버스가 더 쉽고, 더 빠르고, 더 비용 효율적으로 RAG를 구축하는 이유 - 질리즈 블로그](https://zilliz.com/blog/why-milvus-makes-building-rag-easier-faster-cost-efficient)
계속 읽기

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.