




♪データモデリングを理解する
♪データモデリングを理解する
データが企業にとって最も価値ある資産である時代において、広範なデータを効率的に収集、保存、管理することは、競争力を確保するために不可欠である。しかし、企業はどのようにして異種のデータソースから意味を生み出すのだろうか。どのようなデータを収集し、どのように保存すればよいのだろうか。
その答えは、効率的なデータ・モデリングにある。どのようなデータを収集する必要があるのか、複数のソース間の重要な関係をどのように特定するのかを理解するのに役立つ。このプロセスにより、意思決定者は効果的な意思決定のために関連するデータセットを特定することができる。
この記事では、データモデリングについて、その仕組み、テクニック、プロセス、メリット、課題、そしてモデリング・ワークフローの効率化に役立つツールについて説明する。
データモデリングとは?
**データモデリングは、アプリケーションやシステムのデータ構造を表す青写真を作成します。データ・モデルとは、関連するデータ・エンティティ、オブジェクト、リレーションシップ、保存のための複雑なスキーマを図示したものである。
データモデルはまた、データ定義、用語集、その他の重要なメタデータを確立し、複数の利害関係者が特定のユースケースに対して意味のある洞察を引き出せるようにします。利害関係者には、データ分析者、開発者、データソースを分析、整理、アクセス管理する管理者などが含まれる。
効率的なデータモデリングは、データの共通理解を促進し、データの冗長性を排除し、管理上のハードルを最小限に抑えることで、チーム全体でデータ資産を効果的に利用することを保証する。また、スケーラブルなデータ管理システムを構築するための潜在的な障害や設計上の制約を特定し、解決することができます。
データモデリングはどのように機能するのか?
データモデルを作成する手法はケースによって異なりますが、一般的には概念設計、論理的枠組み、物理モデルの開発が含まれます。
概念設計
概念設計は、全体的なデータ構造を視覚化する抽象化です。プロジェクトの範囲を特定し、システムを作成するためのハイレベルな要件を確立します。
概念モデルはまた、ビジネス分析タスクに関連するデータエンティティ、関係、統合、およびセキュリティプロトコルをマッピングします。例えば、下図は販売データベースシステムの分かりやすい概念モデルです。
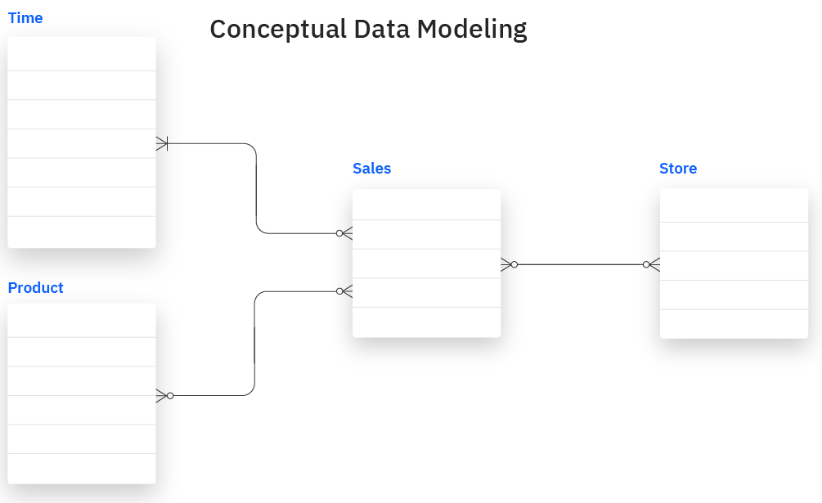 概念モデル.png
概念モデル.png
その目的は、ビジネスエグゼクティブのデータニーズに対応し、効果的なデータ駆動型の意思決定を行うために重要なデータ要素と関係を発見するのを支援することです。
論理的フレームワーク
論理フレームワークは、データ型、一意識別子、定義を含むことで、より詳細な情報を提供する。正式なデータ表記を使用してエンティティの関係をマークし、ユーザーがデータ属性と関係をより明確に視覚化できるようにします。
例えば、販売データベースの論理フレームワークには、商品テーブルと販売テーブルを接続する主キーが 含まれます。
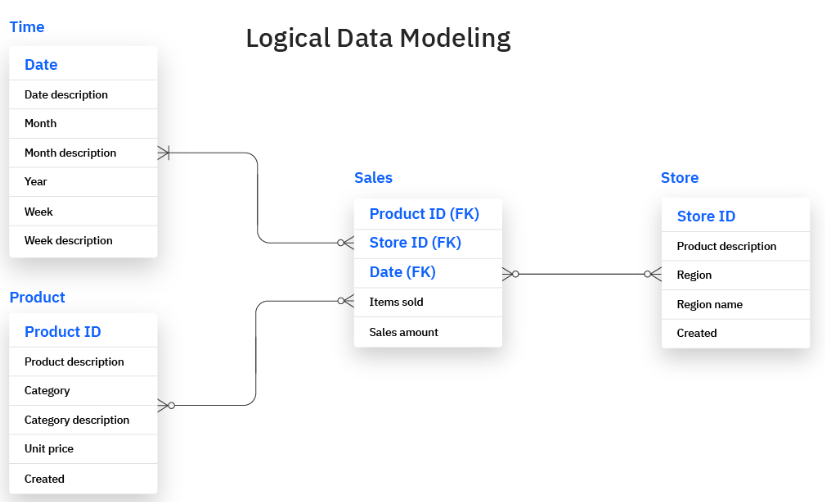 論理フレームワーク.png
論理フレームワーク.png
論理モデルはまた、ユーザーが各データエンティティ内で必要とされる情報の性質と、データ構造を実装するためのルールを決定するのに役立ちます。
物理データモデル
物理データモデルは、データ駆動型システムの最後にして最も詳細な表現である。これには、システムがデータ資産をどのように保存するかを記述する詳細なスキーマが含まれます。
例えば、リレーショナル・データベース・システムの物理データ・モデルは、各テーブル、カラム、および対応するデータ型の名前で構成されます。
 物理データモデル.png
物理データモデル.png
物理モデルはシステム固有であり、構築しようとしているモデルのタイプによって変わります。次のセクションでは、異なるデータモデルのタイプについて詳しく説明します。
データモデルの種類
時代とともに、データ量の増加に伴い、より複雑なデータベース管理システム(DBMS)が登場してきました。DBMSのアーキテクチャが多様化した結果、組織が管理システムをより効率的に設計できるよう、複数のデータモデルタイプが生まれた。
モデルの種類はまだ進化を続けていますが、よく使われるものとしては、階層型、リレーショナル型、実体関係型、オブジェクト指向型、次元型などがあります。
階層型データモデル
階層型データ・モデルは、1つの親が複数の子レコードに接続された、1対多のツリーのような構造でデータを整理します。
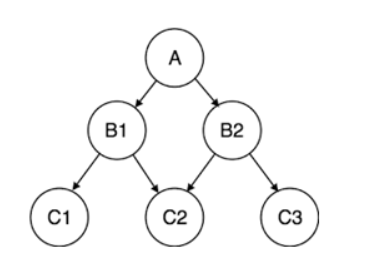 階層モデル.png
階層モデル.png
IBM情報管理システム(IMS)は、1966年に導入された階層構造を最初に使用した。このモデルは今日では珍しいが、Extensible Markup Language (XML)ファイルや地理情報システム(GIS)のデータ整理に今でも使われている。
リレーショナル・データ・モデル
1970年にIBMの研究者エドガー・F・コッドによって導入されたリレーショナル・データ・モデルは、階層構造よりも汎用性が高い。データを行と列のある表に整理し、複数のデータ要素や関係を発見しやすくする。
| ID|名前|住所 | ||
| 125|名前1|住所1 | ||
| 236|名前2|住所2 |
表関係モデル
リレーショナル・モデルは、ユーザーが主キーに基づいて複数のテーブルを結合し、データの複雑さを軽減することを可能にします。構造化クエリー言語(Structured Query Language、SQL)は、主にリレーショナル・データベースのデータの操作と分析に使用される。
エンティティ-関係データモデル
エンティティ-リレーションシップ(ER)モデルは、エンティティに従ってデータ属性を整理し、複数のエンティティ間の関係をマッピングします。
例えば、販売 DBMS では、顧客はエンティティであり、その属性には顧客の名前、住所、連絡先、その他の特徴が含まれる。顧客エンティティは、特定の顧客が購入した商品を通じて、商品エンティティに関連付けることができます。
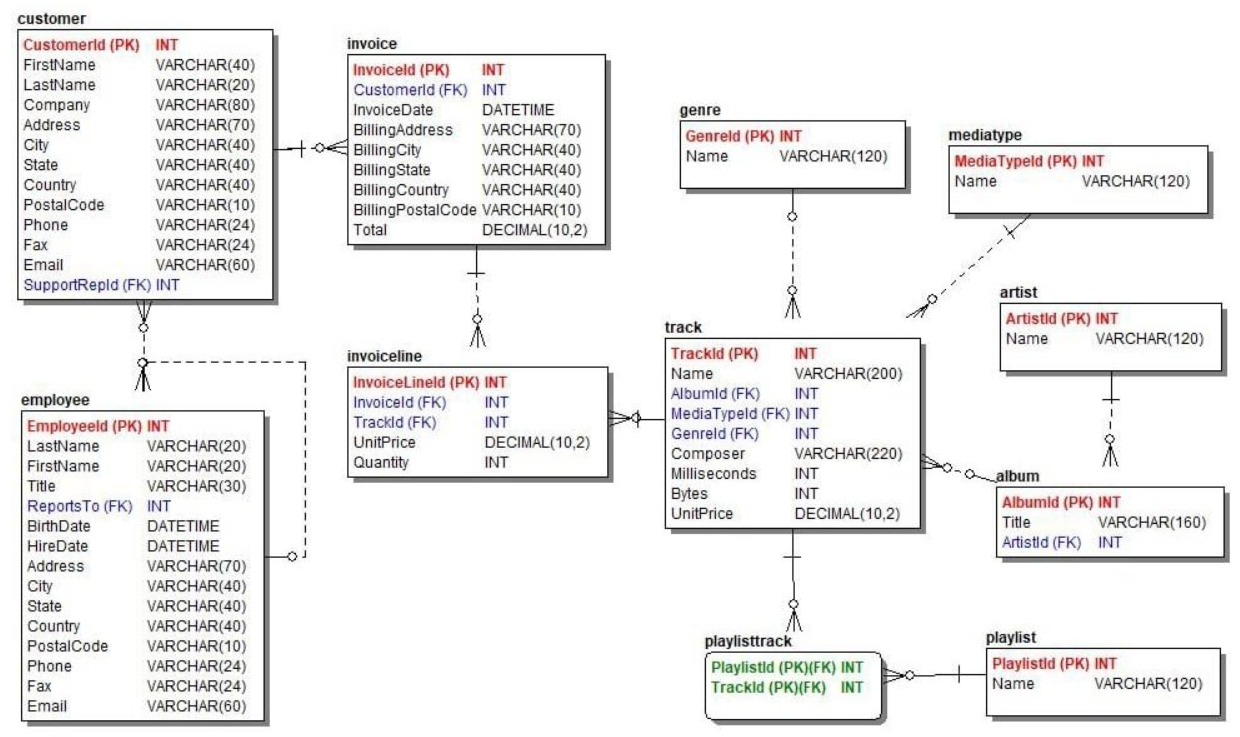 ERモデル.png
ERモデル.png
この構造は、トランザクションベースのデータをより効率的に取り込み、分析するのに役立つため、リレーショナルモデルよりも動的である。
オブジェクト指向データモデル
オブジェクト指向データ・モデルは、データ・オブジェクトをその属性に従って整理するオブジェクト指向プログラミングとともに普及した。
同じような属性を持つデータ・オブジェクトはクラスに分類される。プログラマーは、以前のクラスの属性を継承した新しいクラスを作成することができます。
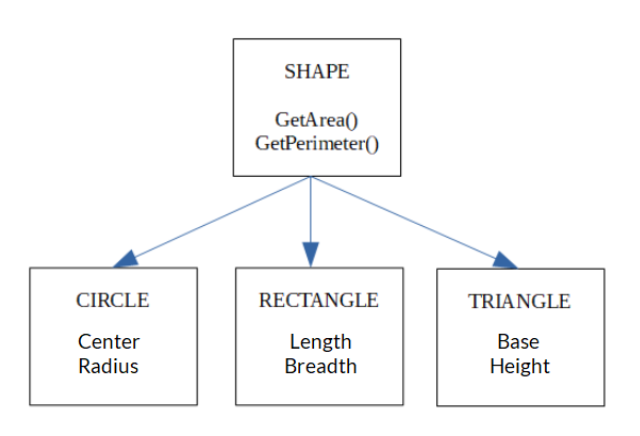 オブジェクト指向データモデル- .png
オブジェクト指向データモデル- .png
オブジェクト指向データモデル_:CIRCLE、RECTANGLE、TRIANGLEオブジェクトはSHAPE __**_オブジェクトを継承しています。各図形には属性があります。
例えば、オブジェクト指向データモデルでは、顧客データと従業員データは、名前、住所、 連絡先情報などの同一の属性を持つため、同じクラスに属する可能性があります。これは、顧客と従業員が別々のエンティティであるERモデルとは異なります。
次元データモデル
ディメンショナル・データ・モデルは、データ・エンティティをファクトシートに接続されたディメンションとして整理し、データ・ウェアハウスやマートでの分析を改善する。ファクトシートにはイベントに関するデータが含まれ、ディメンジョンにはこれらのイベント内に現れるエンティティに関する情報が含まれます。
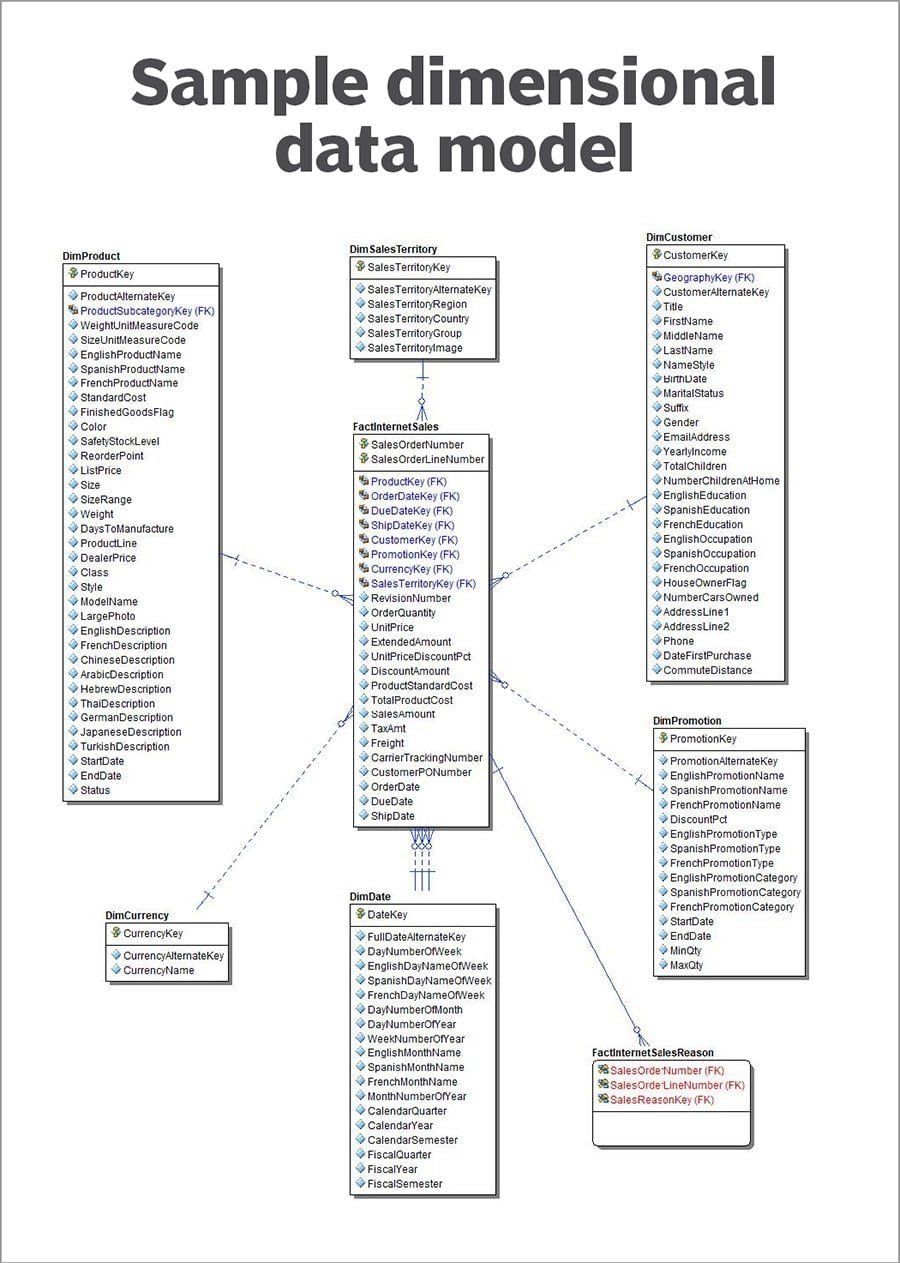 次元データモデル- .jpg
次元データモデル- .jpg
次元データモデル:販売ファクトシートは、その中に現れるエンティティの複数の次元に関係する。
例えば、ファクトシートは、複数の顧客による日常的な取引を記録した表になる。例えば、ファクトシートは、複数の顧客による日常的な取引を記録するテーブルになります。しかし、ユーザは、顧客関連データまたは製品データを格納するディメンジョン・テーブルで、各顧客または製品に関するより詳細な情報を見つけることができます。
スタースキーマは有名な次元データ構造で、1つのファクトシートが複数の次元に接続されている。より複雑な変形はスノーフレーク構造で、多数のディメンジョン・テーブルがさまざまなファクトシートに関連付けられます。
データベース設計およびデータ工学との比較
データベース設計とデータエンジニアリングは類似した概念ですが、データモデリングとはいくつかの点で異なります。
データモデリングとデータベース設計の比較: **データモデリングはデータベースを構築する際の初期段階である。データベース設計は、データモデルを実装するための要件を決定する、抽象度の低いプロセスです。開発者は、スケーラビリティとデータの完全性を向上させるために、最適なデータベース構造を検討します。例えば、主キーの選択、インデックス作成技法、スキーマ設計などが含まれる。
データモデリングとデータエンジニアリングの比較: **データエンジニアリングは、複数のプラットフォーム間でデータを処理、変換、移動するための自動化されたデータパイプラインの開発を含む、より広い概念である。効率的なデータモデルは、堅牢なデータベース設計を構築し、開発者がデータエンジニアリングのワークフローを合理化するのに役立ちます。
データモデリング・プロセス
データモデルを設計するには、データベースシステムの範囲、目標、およびリソースの制約を理解するために、複数の利害関係者からのインプットが必要です。
データの専門家は、特定のユースケースに必要なデータ構造を表す適切なデータモデルタイプを選択する必要があります。また、モデルを構築するために、関連する記号と表記規則を決定しなければなりません。
データ・モデリングのワークフローは、ビジネス・ニーズやデータの性質によって異なりますが、モデルを設計するためのいくつかのステップを以下に示します。
エンティティの識別最初のステップは、データが含まなければならない関連エンティティを特定することである。エンティティは相互に排他的でなければならず、モデルの概念設計の基礎となる。
属性の識別:*** 開発者は、各エンティティに固有の属性を識別しなければならない。例えば、顧客の銀行口座の詳細を含むデータベースでは、「銀行口座」は、口座の性質、口座番 号、作成日、最初の預金額などの固有の属性を持つ別のエンティティにすることができます。
エンティティ間の関係:** 複数のエンティティ間の関係をマッピングする。例えば、"銀行口座 "エンティティは "顧客 "エンティティに関連付けることができ、各顧客はさらに1つの口座を持つ。
主キーの割り当て:** 開発者は、エンティティに一意のキーを割り当てて、それらの関係を正式に表現する必要があります。例えば、口座番号は、"customers" エンティティと "bank accounts" エンティティを関連付ける主キーとなる。
データ・モデルの作成と最終化: **関連するすべてのエンティティ、属性、および主キーを持つ関係を特定した後、開発者は適切なデータ・モデルを決定し、ビジネスのデータ・ニーズを最も満たす設計を最終化することができます。
データモデリングの利点
データモデルは効果的なデータ管理システムのバックボーンである。これにより、複数の利害関係者がデータ資産を使用して、戦略的意思決定のための貴重な洞察を発見することができます。
以下のリストでは、効果的なデータモデルの利点をいくつか挙げている。
より良いコミュニケーション: **データモデルは、関連する利害関係者にデータの流れや概念をより簡単に伝えるのに役立ちます。
一貫性のあるドキュメンテーション: **データモデルは、データ構造全体の標準化された視覚化を提供するため、ドキュメンテーションはより一貫性があり、より堅牢なシステム設計を可能にします。
チーム横断的なコラボレーションの強化:*** データ理解が共有されることで、複数のドメインのチームがプロジェクトでより効果的にコラボレーションできるようになります。
データ品質の向上:** 適切に設計されたモデルにより、データソース間のデータ整合性が保証され、ユーザーは迅速かつ効率的なデータ分析ワークフローを開発することができます。
データモデリングの課題
データモデリングには複数の利点がある一方で、実装上の課題もいくつかあります。これらのハードルを理解し、それを克服する方法を理解することは、組織がデータモデリングの利点をより早く実現するのに役立ちます。
以下に、開発者がデータモデルを設計する際に直面する可能性のある課題をいくつか示します。
増大するデータの複雑性:*** 現代のDBMSはダイナミックでなければならず、変化するビジネスニーズや増大するデータの多様性に対応しなければなりません。しかし、将来の変化を予測することは複雑で、かなりの推測を伴います。モデルをより小さなコンポーネントに分解し、業界標準を使用することで、このような問題を軽減することができます。
エグゼクティブチームの賛同:** データモデルの利点についてエグゼクティブチームを説得するのは退屈なことです。ビジネスユーザーにとっては、話が抽象的になりすぎることもある。確実に支持を得るためには、データチームは会社全体のミッションやビジョンに沿った明確な目標や目的を持って経営トップにアプローチしなければならない。
要件の変更:*** データモデルの設計は反復プロセスであり、スコープや目標の変更が必要になることがあります。しかし、頻繁な変更は、設計が軌道から外れたり、開発コストが増加したりする可能性があります。関連する利害関係者を特定し、最初から関与させ、定期的にフィードバックを得ることで、このような問題を克服することができます。
データモデリングツール
開発者はデータモデリングツールを使用することで、より効率的な設計を迅速に行うことができる。複数のプロバイダーがデータモデリング・ソリューションを提供していますが、ビジネス・ニーズに最適なものを選ぶには時間と労力がかかります。以下のリストでは、検索を簡素化するのに役立つ人気のあるツールをいくつか紹介しています。
1.**複数のデータベースシステムをサポートする詳細なスキーマの作成と視覚化の設計を支援します。バージョン管理システムを備えており、既存のデータ構造からデータモデルをリバースすることができます。
2.DbSchema:コードを使用せずにデータモデルと対話し、視覚的にクエリを構築できる直感的なユーザーインターフェイスを備えています。
3.ER/Studio:リレーショナルやディメンション構造を含む複数のデータベースシステムをサポートします。アクティビティやディスカッションストリームを通じて、チームがデータをより効果的に理解できるコラボレーションツールを備えています。
データモデリングに関するFAQ
1.**データモデリングとデータベース設計の違いは何ですか?
データモデリングとは、データ実体、属性、および異なる実体間の関係を特定することを指します。データモデリングは、データベースがこれらのエンティティをどのように格納し、ユーザーがどのように関係を活用して分析を行うことができるかという全体的な構造を作成するのに役立ちます。
データベース設計はデータモデルを確定した後に行われ、データベース管理システム(DBMS)にデータモデルを実装する。これには、インデックス作成技術、スキーマ名、ストレージ構造などが含まれる。
2.**データモデリングにおける正規化とは?
正規化とは、データをグループに整理して冗長性を排除し、データの一貫性を向上させることです。例えば、リレーショナルDBMSの次のような表を考えてみましょう:
| 顧客|購入商品|価格 | ||
| A|電話|200ドル | ||
| B|パソコン|1500ドル | ||
| C|充電器|50ドル | ||
| D|電話機|200ドル |
ここで、特定の顧客のレコードを削除したい場合、ユーザーはアイテムの価格を削除します。正規化では、2つのテーブルを作成することで、顧客データと価格情報を分離します。
このプロセスにより、データの一貫性が保たれ、ユーザーは情報の全体的な構造を変更することなく、より柔軟にデータを操作できるようになります。
3.**非構造化データのデータモデルをどのように設計するか?
非構造化データには、画像、動画、テキストデータが含まれる。非構造化データセットのモデルは、従来のスキーマよりも表現が複雑になるため、異なるテクニックが必要になる。
開発者は、非構造化データセットのデータモデルを格納・開発するために、ベクトルデータベースを使用することができる。このデータベースは人工知能(AI)アルゴリズムを使って、データサンプルをembeddings、各データポイントのベクトル化表現に変換する。ベクトルの各要素はデータサンプルの特定の属性に対応する。
いったんサンプルがベクトル形式になれば、ユーザーは類似性メトリクスを計算して、異なるデータポイント間の類似性を評価することができる。類似度スコアを使用して、データをグループに整理し、それらの間の関係を表すモデルを開発することができる。
4.**データモデリングで避けるべき一般的な間違いは何ですか?
開発者はしばしばモデルを複雑にしすぎ、関連する利害関係者を設計フェーズに参加させることができない。また、不必要なデータ・エンティティを含めたり、パフォーマンス制約を考慮しなかったりすることも、データ・モデルの効率を低下させるよくあるミスです。
5.**正しいデータモデリングツールはどのように選択するのか?
データモデリング・ソリューションに投資する際には、以下の要素を考慮する必要があります:
使いやすさ
対応データベースシステム
視覚化機能
コラボレーション・ツール
スケーラビリティ
価格
関連リソース
非構造化データの管理およびモデリング技術については、以下の記事をご参照ください。
非構造化データ入門](https://zilliz.com/learn/introduction-to-unstructured-data)
ベクトル・データベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
ベクトルデータベースを理解する](https://zilliz.com/learn/comparing-vector-database-vector-search-library-and-vector-search-plugin)
ベクトルデータベースのデータモデリング技法](https://zilliz.com/learn/data-modeling-techniques-optimized-for-vector-databases)