




自己回帰和分移動平均(ARIMA)

自己回帰和分移動平均(ARIMA)
企業が今後のシーズンに向けて製品需要を正確に予測し、ローンチを最適化する方法について考えたことはありますか?そこで ARIMA が役立ちます。ARIMA は、過去のパターンを分析することで将来の時系列値を予測する統計モデルです。
ARIMA の仕組みを確認しながら、その重要性、利点、課題について説明しましょう。
ARIMA とは?
自己回帰和分移動平均(ARIMA)は、時系列予測のための一般的な統計モデルです。 履歴データを使用してデータセットのパターンを理解し、将来の値を予測します。このモデルは、将来の値を予測するために 自己回帰(AR)、差分化(I)、移動平均(MA) という3つの要素を使用します。各要素は、過去の値と将来の値の関係を示すことで、モデルの予測を形成します。
各要素の役割は次のとおりです。
自己回帰(p): AR は、将来の値が過去の値に依存すると仮定します。AR 次数とは、モデルが現在の値を予測するために使用する過去の値の数を指します。たとえば、AR 次数が3の場合、モデルは直近3つの過去の値に基づいて現在の値を予測します。
差分化/ 和分(d): これは、時系列を定常にするために必要な差分化の程度を決定します。平均や分散などの統計的性質が時間とともに変化する非定常時系列では、差分化を適用することで系列を安定化できます。
移動平均(q): MA は、時系列の現在の値と過去の予測誤差との関係を捉えます。MA 次数は、時系列の現在の値と過去の予測誤差との関係を反映します。たとえば、MA(2) または次数2の MA は、現在の値を予測するために過去2つの誤差の加重平均を計算します。
数学的には、ARIMA モデルは ARIMA (p, d, q) と表され、次のように表現されます。
y′t=I+α1y′t−1+α2y′t−2+⋯+αpy′t−p+et+θ1et−1+θ2et−2+⋯+θqet−q
ここで:
Yt: 時系列の現在の値
c: 定数項
φ₁, φ₂, ..., φp: 自己回帰係数
θ₁, θ₂, ..., θq: 移動平均係数
εt: ノイズ誤差項
p: 自己回帰の次数
q: 移動平均の次数
d: 差分化/ 和分の次数
これは、差分化された時系列の現在の値(y′t)が、その過去の値(y′t-₁, y′t-₂, ..., y′t-p)および過去の誤差項(et-₁, et-₂, ..., et-q)の線形結合であることを表しています。
ARIMA はどのように機能するのか?
自己相関と移動平均は、ARIMA モデルの重要な要素です。自己相関は、過去の値と現在の値の直接的な関係を特定するのに役立ち、移動平均は、過去の予測誤差の間接的な影響を考慮するのに役立ちます。
これらがどのように連携するかを段階的に説明します。
定常性
ARIMA モデルによる時系列予測の最初のステップは、時系列が定常であることを確認することです。非定常データは不正確な予測や偏ったモデル結果につながる可能性があるため、ARIMA は定常性の仮定に基づいています。時系列データが非定常である場合、ARIMA は差分化を適用して定常にします。これは、現在の値から前の値を差し引くことを含みます。差分化の次数(d)は、このプロセスを繰り返す回数を決定します。
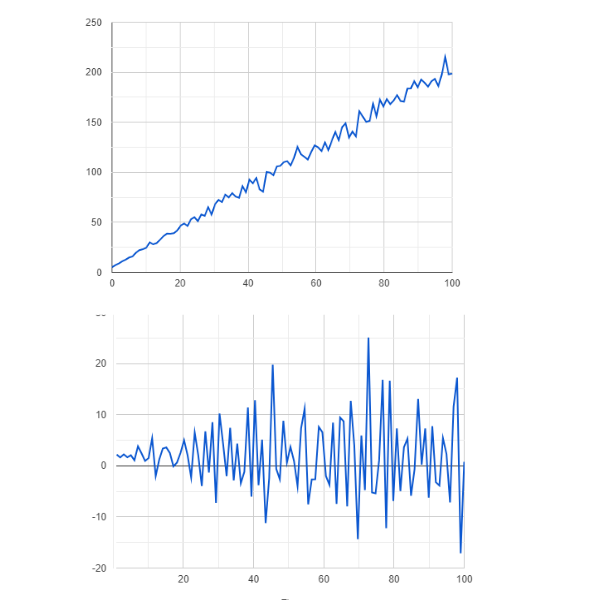 図- 非定常データと定常データ .png
図- 非定常データと定常データ .png
図: 非定常データと定常データ
モデルの識別
モデルの識別では、自己回帰(p)要素と移動平均(q)要素に適切な値を決定します。自己相関関数(ACF)と偏自己相関関数(PACF)は、このプロセスに不可欠なツールです。
自己相関関数
自己相関関数は、自己回帰(AR)成分の次数(p)を特定します。ラグ k で相関が示される場合、現在の値が k 期間前の値に関連していることを示唆します。ここで k は、時系列における現在の値と過去の値の間のラグ数(時間ステップ)を表します。
偏自己相関関数
偏自己相関関数(PACF)は、移動平均(MA)成分の次数(q)を特定します。ラグ k で有意な相関が示される場合、現在の値が k 期間前に発生した予測誤差に関連していることを示します。
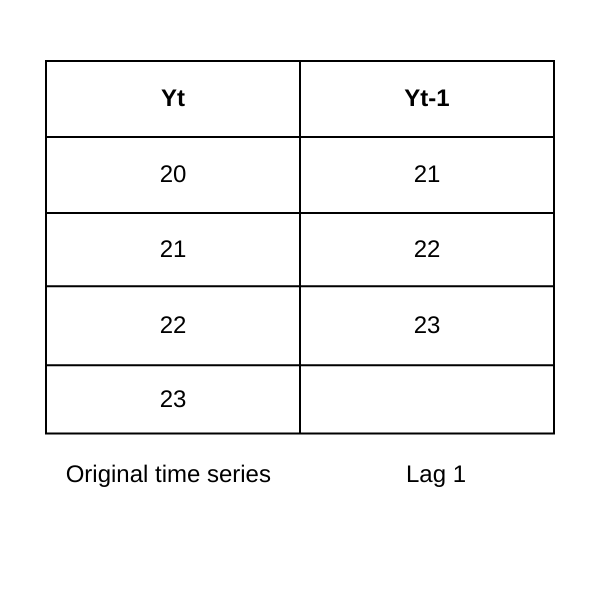 Figure- Lag-1 autocorrelation.png
Figure- Lag-1 autocorrelation.png
図: ラグ1自己相関
モデル推定
自己回帰(AR)の次数と移動平均(MA)成分を決定した後、ARIMA はモデルパラメータを推定します。モデルパラメータは、現在の値とその過去の値(AR)との関係、および現在の値と過去の誤差(MA)との関係の強さを定量化します。
最尤推定(MLE)は、ARIMA モデルにおけるパラメータ推定の最も一般的な方法です。MLE は、与えられたデータを観測する尤度を最大化する値を見つけることによって、モデルパラメータを推定します。ARIMA モデルでは、尤度関数は通常、誤差が正規分布に従うという仮定に基づいています。最小二乗法やベイズ法も、ARIMA モデルにおけるパラメータ推定の別のアプローチです。
モデル予測
推定された ARIMA モデルは、最終的に履歴データに基づいて将来の値を予測します。必要に応じて、AR 成分と MA 成分の次数を調整したり、季節性などの他の要因を考慮したりすることで、モデルを改良することもできます。
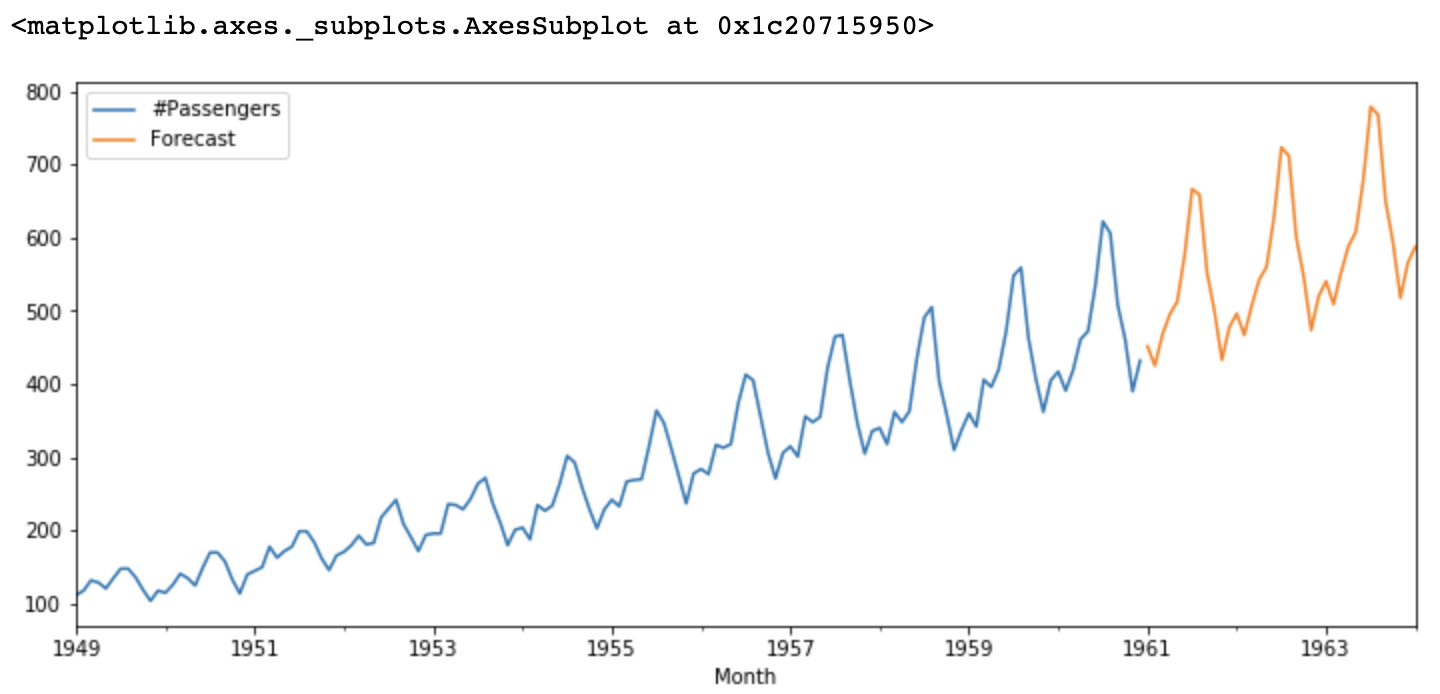 Figure- ARIMA forecasts.png
Figure- ARIMA forecasts.png
図: ARIMA 予測
類似概念との比較
ARIMA は、データ分析や予測の文脈で、他の類似概念とよく比較されます。一般的な誤解を解くための比較を以下に示します。
ARIMA vs. SARIMA: SARIMA(Seasonal ARIMA)は、時系列データ分析において季節性を特に組み込んだ ARIMA の拡張です。ARIMA は、明確な季節パターンを持たない時系列データのための統計モデルです。
ARIMA vs. Exponential Smoothing: ARIMA と指数平滑法は、時系列予測のための手法です。ARIMA は、トレンド、季節性、自己相関を含む基礎的なパターンをモデル化するために統計的手法を使用します。一方、指数平滑法は、より単純な加重平均の方法を適用し、古い観測値よりも新しい観測値により大きな重みを与えます。ARIMA は複雑なパターンを持つデータにより適していますが、指数平滑法は比較的安定したトレンドと最小限の季節性を持つ時系列に適しており、複雑なデータへの適応性は低くなります。
ARIMA vs. Vector Autoregression (VAR): VAR は、複数の変数が互いに影響し合う多変量時系列予測に適しています。ARIMA は単変量時系列に適しており、定常性を達成するために系列の差分化が必要です。
ARIMA の利点と課題
ARIMA にはいくつかの利点があり、最も広く使用されている時系列予測モデルの一つとなっています。しかし、一定の課題も伴うため、ARIMA を適用する前に、分析の特性や具体的な目標を考慮する必要があります。
利点
時系列予測に ARIMA モデルを使用する利点には、以下が含まれます。
柔軟性: ARIMA は、線形および非線形トレンド、季節パターン、ボラティリティ、自己相関を含む幅広い時系列データを扱うことができます。これにより、経済指標や株価の非線形パターンなど、現実世界の時系列に共通する特徴に対応できます。
単純性: ARIMAモデルは、機能がシンプルで仮定が透明であるため、理解しやすいです。比較的多数の観測値を持つ長い時系列を扱うことができます。
精度: ARIMAモデルの精度はデータの品質に依存します。したがって、仮定を考慮し、適切なモデルを選択することで、正確な結果につながります。
解釈可能性: ARIMAモデルのパラメータには、自己回帰係数や移動平均係数など、明確な解釈があります。これらの係数は、過去の値や誤差が将来の値にどのように影響するかについての洞察を与えます。
幅広い適用性: ARIMAモデルは、金融モデリング、需要予測、負荷予測などの予測アプリケーションにおいて、業界全体で広く使用されています。したがって、多くのプログラミング言語に組み込まれており、広範な支持者コミュニティがあります。
他のモデルの基盤: ARIMAモデルは、SARIMAやARIMAXなど、より複雑な時系列モデルの基盤です。追加要因を考慮することで、時系列の過去の値を超えて予測精度を向上させるのに役立ちます。
課題
ARIMAモデルの課題には以下が含まれます。
定常性の仮定: ****ARIMAモデルは時系列が定常であると仮定します。そうでない場合は、定常性を達成するためにデータを変換します。しかし、多くの実世界のデータセットは非定常であり、それらを前処理することでモデリングプロセスが複雑になる可能性があります。
線形関係: ARIMAは線形モデルであり、データ内の複雑な非線形関係を捉えることはできません。したがって、経済危機、外部ショックなどによって引き起こされるデータの急激な変化を正確に捉えられない可能性があります。
モデル識別: ARIMAモデルの性能は、適切なパラメータ(p, d, q)を選択することに依存します。しかし、多くの場合、試行錯誤やグリッドサーチ手法が必要であり、過学習または未学習につながる可能性があります。
外れ値への感度: ARIMAモデルは外れ値に敏感である可能性があり、それが性能に影響を与えることがあります。したがって、望ましい結果を得るには、慎重なデータ前処理が必要です。
長期予測: ARIMAは長期予測にはあまり適していません。これは、ARIMAモデルが過去のパターンに基づいており、予期しない事象やデータ生成プロセスにおける構造変化を十分に捉えられない可能性があるためです。
ARIMAのユースケース、ツール、プロバイダー
ARIMAモデルは、さまざまな分野で時系列予測および分析に広く適用されています。これには、経済学および金融、需要予測、生産および能力計画、ヘルスケアなどが含まれます。
たとえば、ARIMAモデルはインドにおけるCOVID-19の感染拡大を予測するために使用されました。研究者たちは、2020年3月14日から5月3日までの日次COVID-19症例データを使用してARIMAモデルを訓練し、満足のいく精度を得ました。
多くのプログラミング言語や統計パッケージが、ARIMAモデルを実装するためのツールを提供しています。それらには以下が含まれます。
R
Rには、ARIMAモデリングを含む広範な時系列分析機能があります。stats、forecast、tseriesを含む複数のライブラリが、RでARIMAモデルを実装するための関数を提供しています。
Python
PythonもARIMAを実装するための広範な統計ライブラリを提供しています。これらにはStatsmodels、Numpy、Pandasなどが含まれます。
MATLAB
MATLABは、ARIMAモデリング用の組み込み関数を備えた商用の数理計算ソフトウェアです。また、ARIMAモデリングを他のワークフローと組み合わせるために、他のソフトウェアツールやプログラミング言語との統合も可能にします。
ARIMAのFAQ
ARIMAは何に使用されますか?
AutoRegressive Integrated Moving Average(ARIMA)は、時系列分析および予測に使用される統計モデルです。過去の値に基づいて時系列の将来の値を予測するための一般的な方法です。
ARIMAは他の時系列予測モデルとどのように異なりますか?
ARIMAは、その柔軟性、解釈可能性、幅広い適用性により、他の時系列予測モデルとは異なります。ARIMAは、トレンド、季節性、自己相関を含む、時系列データの幅広いパターンを捉えることができます。ARIMAモデルのパラメータには明確な解釈があり、より複雑なモデルと比較するためのベースラインとして役立ちます。
ARIMA予測をどのように解釈するか?
ARIMA予測は通常、時系列の将来値の期待値に対する点推定として解釈されます。予測精度を評価するために、平均二乗誤差(MSE)、平均絶対誤差(MAE)、二乗平均平方根誤差(RMSE)などのさまざまな指標を使用できます。
ARIMAモデルの仮定とは?
以下はARIMAモデルの仮定です。
定常性: 時系列の統計的特性(平均、分散、自己相関)は、時間の経過とともに一定でなければなりません。
線形性: ARIMAは、現在値とその過去の値および誤差との間に線形関係があると仮定します。
正規性: 誤差は正規分布に従うと仮定されます。
誤差に自己相関がないこと: 誤差は無相関であると仮定されます。
関連リソース
時系列データの保存と前処理について詳しく読む: