




FARFETCHにおける会話AIの最適化

15x
インデックス作成時間の短縮
5x
クエリー時間の短縮
コンバージョンの向上
より適切な製品の推奨を通じて
複数のメトリック・タイプ
様々なユースケースをサポートする
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
#ファーフェッチについて
オンライン・ファッション・リテールのリーディング・カンパニーであるファーフェッチは、最新のイノベーションであるiFetchでデジタル・ショッピングの限界を押し広げようとしている。この会話型AIシステムは、高級実店舗で一般的な、パーソナライズされた高級サービスをデジタル領域にもたらすよう設計されている。ファーフェッチ・チャットR&Dは、この構想の一環として、会話に特化したレコメンダー・システムを開発している。iFetchに統合されたこのチャットボットにより、ユーザーは自然言語と画像を通じてFARFETCHの商品カタログと対話することができる。例えば、ユーザーが気に入ったジャケットの写真をアップロードすると、チャットボットが似たようなジャケットを厳選して返答してくれる。高度なAI技術とユーザー体験をシームレスに融合させることで、FARFETCHは顧客がオンライン・ショッピングに期待するものを再定義することを目指している。
FARFETCHチャットが類似のショーケースを表示](https://assets.zilliz.com/FARFETCH_Chat_show_similar_showcase_4d268c1bc0.jpg)
しかし、彼らは大きな課題に直面した。メタデータが限られているため、従来の商品カタログでは、幅広い商品の複雑な関係や微妙な属性を把握するのに苦労していたのだ。この課題に取り組むため、彼らは機械学習アルゴリズムを採用し、AIシステムのロバストな言語として機能する製品埋め込み-高次元データ-ポイントを開発した。これにより、チャットボットはかつてない精度で商品を理解し、推奨することができる。しかし、これらの埋め込みデータをリアルタイムで保存・検索するには、高次元データを効率的に処理できる専用のストレージ・ソリューションが必要で、別のハードルがあった。
ベクターデータベースの重要性
ベクトルデータベースは、ベクトル類似度エンジン(VSE)とも呼ばれ、ベクトル埋め込みと呼ばれる複雑な高次元データを扱うために設計された特殊なデータベースです。これらのデータベースは、近似最近傍(ANN)アルゴリズムを採用しており、迅速かつ正確なデータ検索に不可欠です。この機能は、リアルタイムでの顧客とのインタラクションが要求されるiFetchには特に不可欠であり、即座に商品の推薦を提供し、問い合わせに答えることができる。ベクトルデータベースの選択は、単なる技術的なことではなく、iFetchのパフォーマンス、堅牢性、効率性に直接影響する戦略的な決定なのです。彼らは、最適なVSEを選択するために、包括的なベンチマーク調査を実施しました。このベンチマークでは、Vespa、Milvus、Qdrant、Weaviate、Vald、Pineconeを含む様々なデータベースを、インデックス作成速度、クエリ速度、スケーラビリティなどの様々な基準で評価しました。ベンチマークには、各VSEがピーク負荷下でどのように動作するかを評価するストレステストや、回復力を評価するフェイルオーバーとリカバリーのシナリオも含まれていました。
Vector Similarity SearcによるiFetchシステム・アーキテクチャの全体像](https://assets.zilliz.com/Holistic_representation_of_the_i_Fetch_system_architecture_with_Vector_Similarity_Search_10948cc2e7.png)
ベンチマーク基準と選択
Farfetchチームによって行われたベンチマーク・プロセスは、iFetchの長期的な成功に不可欠な幅広い要素を網羅し、徹底的かつ体系的なものでした。これらには、インデックス・タイプの多様性、メトリック・タイプ、モデル提供能力、コミュニティ採用が含まれます。彼らはまた、ドキュメンテーションの質とサポートの可用性も考慮しました。なぜなら、これらの要因は、実装の容易さと継続的なメンテナンスに影響を与えるからです。
| フィーチャー|Qdrant|Milvus|Weaviate|Vespa|Vald|Pinecone
| --------- | ---------- | --------- | -------- | -------- | ---- | ------------ |
| 一貫性モデル|N/A|強い一貫性|最終的な一貫性|N/A|最終的な一貫性|N/A|最終的な一貫性
| N/A|はい|N/A|N/A|N/A|N/A|N/A|N/A|N/A|N/A
| シャーディング|なし(対応予定
時期不明)|あり|あり|N/A|N/A
| ページネーション(Pagination) | N/A | No (バージョン2.2で期待
2022.3で期待) | Yes | Yes | N/A | N/A |
| メトリックの種類|内積
コサイン類似度
ユークリッド(L2)|L2
内積
ハミング
ジャカード
谷本
超構造
部分構造|コサイン|ユークリッド
Angular
Inter Product
Geo degrees
Hamming|L1
L2
Angle
Hamming
Cosine
Normailized Angle
Normalized Cosine
Jaccard|Euclidean
Cosine
Inner Product|...
|最大ベクトルサイズ| N/A | N/A | 32
768 | N/A | max.MaxInt64 | N/A
|最大インデックスサイズ|N/A|無制限|N/A|N/A|N/A|N/A
インデックス・タイプ| HNSW | ANNOY
HNSW
IVF_PQ
IVF_SQ8
IVF_FLAT
FLAT
IVF_SQ8_H
RNSG | NHSW | HNSW
BM25 | N/A |Proprietary| |インデックス・サイズ| max.
|Model Serving| N/A | N/A | text2vec-contextionary
Weaviate独自の言語ベクタライザー; Weighted Mean of Word Embeddings (WMOWE)ベクタライザーモジュール。最新のtext2vec - contextionaryは、WikiとCommonCrawlのデータでfastTextを使って学習されています。
text2vec- transformers
Transfomer モデルは Contextionary とは異なり、ユースケースに特化した事前学習済みの NLP モジュールをプラグインすることができます。つまり、BERT、DilstBERT、RoBERTa、DilstilROBERTa などのモデルを Weaviate ですぐに使用することができます。
Custom models | N/A | N/A | N/A | N/A | N/A
厳密な分析の結果、2つのVSE-MilvusとWeaviate-が詳細なベンチマーク用に選ばれた。これらのプラットフォームは、ロバスト性、効率性、およびスケーラビリティに関する厳しい要件と密接に一致していた。これらのプラットフォームのロードマップも最終的な選定に影響を与えた。
実験セットアップ
公平で包括的な評価を確実にするため、標準化されたハードウェアとソフトウェアのセットアップを使用した。
- ハードウェア: Intel Xeon E5-2690 v4 CPU、112GB RAM、1024GB HDD
- ソフトウェアLinux 16.04-LTS、Anaconda 4.8.3、Python 3.8.12
- データセットFarfetchチームはstartups-list.comの40,474レコードからなる公開データセットを使用した。このデータセットには、事前に計算された企業説明の埋め込みが含まれている。
シナリオとインデックス作成アルゴリズム
彼らは、異なる条件下でこれらのVSEの性能を評価するために、複数のテストシナリオを設計した。これらのシナリオでは、レコード数とエンティティごとのエンコーディング数を変化させた。インデックス付けには、高次元データ空間での効率性で知られる HNSW(Hierarchical Navigable Small World)アルゴリズムを使用した。
最終的なシナリオのリストを以下に示す。
| シナリオ | ---------------- | ------------------ | ------------------------------ | | シナリオ#1(S1)|1.000|1|。 | シナリオ#2(S2)|10.000|1|。 | シナリオ#3 (S3) 40.474 1 | シナリオ#4(S4)|1.000|2|1 | シナリオ#5(S5)|10.000|2|。 | シナリオ#6(S6)|40.474|2|。 | シナリオ#7(S7)|1.000|5 | シナリオ#8(S8) 10.000|5 | シナリオ#9(S9)|40.474|5
パフォーマンス分析
インデックス作成
Weaviate:クラス・スキーマ作成時にインデックス・パラメータを明示的に宣言できます。ただし、数字や特殊文字を使用できないなど、クラスの命名が制限されます。
Milvus:より広範なインデックス作成アルゴリズムとメトリック・タイプを提供します。また、インデックスファイルのサイズを定義できるため、バッチ操作を最適化できる。
**結果Milvusは、全シナリオにおいて平均インデックス作成時間に関して優位であった。最もリソースを消費するシナリオであるS9では、Milvusの方が顕著に高速であった。
Milvus 1.1.1 シナリオS1~S9の平均インデックス作成時間](https://assets.zilliz.com/Milvus_Average_Indexing_Time_f319bf820f.png)
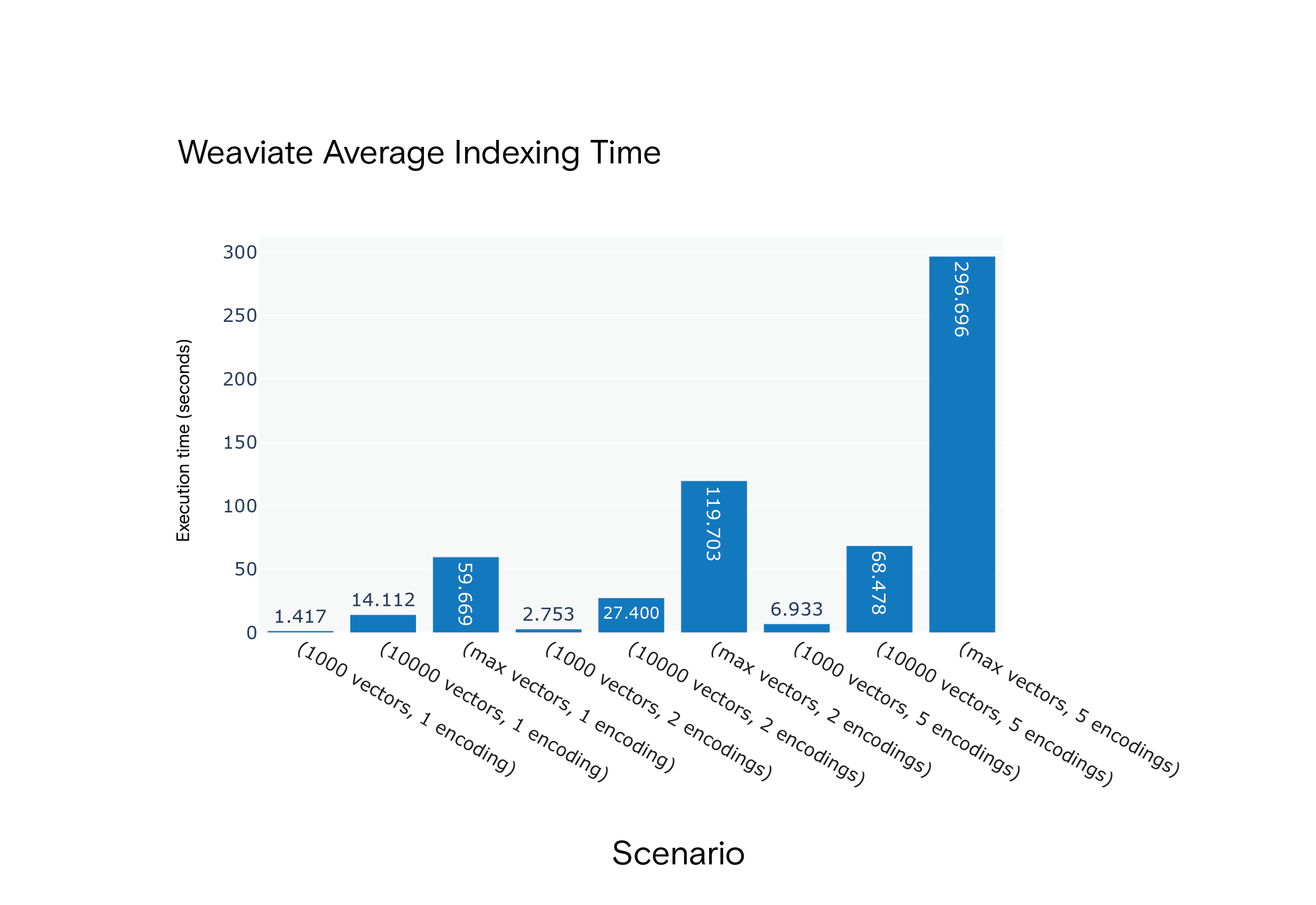 WeaviateシナリオS1からS9までの平均インデックス作成時間
WeaviateシナリオS1からS9までの平均インデックス作成時間
クエリ
Weaviate:Pythonクライアントはベクトル検索をサポートするが、一度に単一のベクトルに対してのみである。
Milvus:より柔軟な検索方法を提供し、ベクトルのリストを扱うことができるため、複数ベクトルのクエリが容易になります。
**結果Milvusは、最適なパフォーマンスに到達するために "ウォームアップ "フェーズが必要であったにもかかわらず、すべてのシナリオにおいて平均クエリ時間が短縮された。
Milvus 1.1.1 シナリオS1からS9までの平均クエリー時間](https://assets.zilliz.com/Milvus_Average_Querying_Time_3917a37469.png)
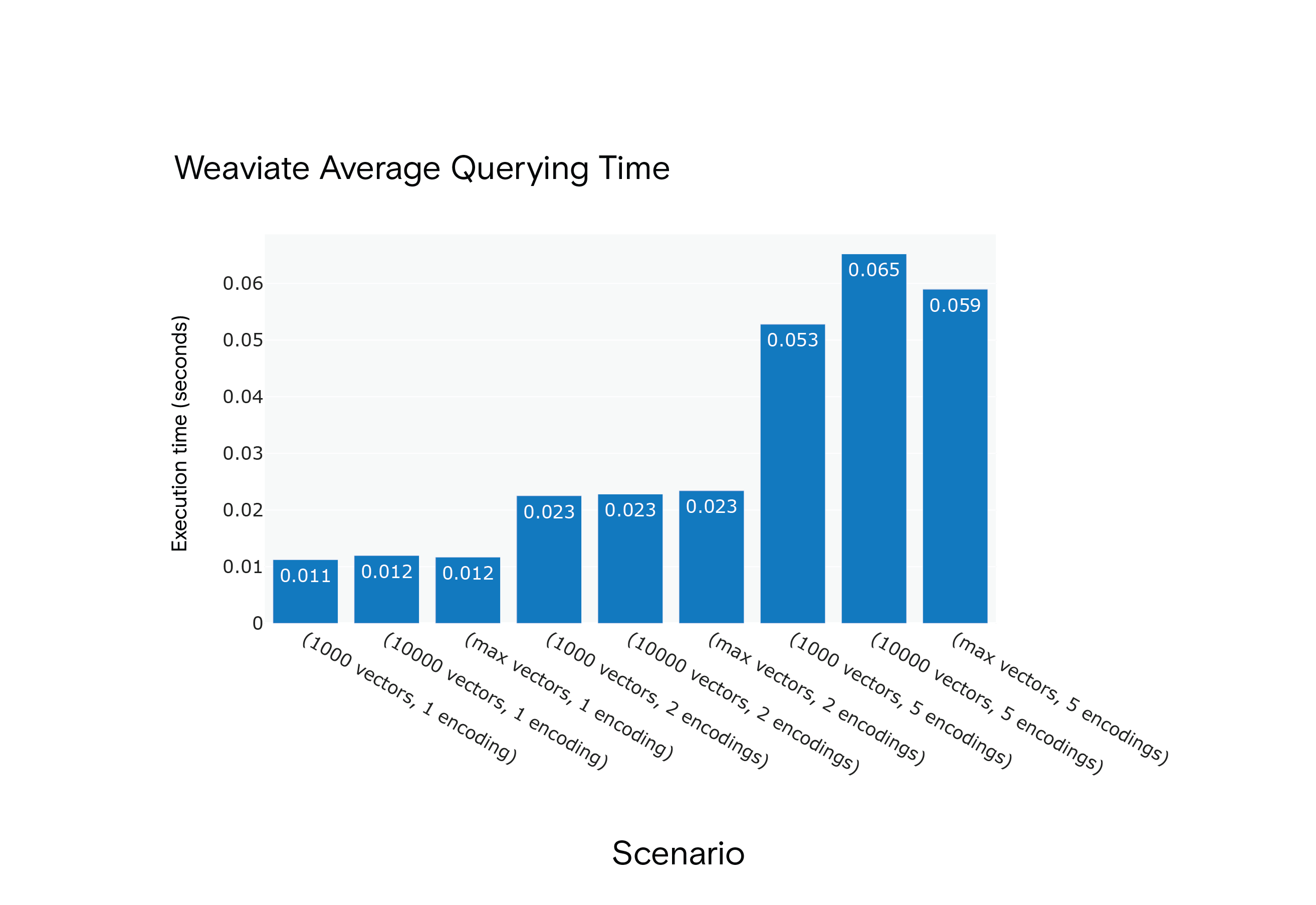 WeaviateシナリオS1からS9までの平均クエリー時間
WeaviateシナリオS1からS9までの平均クエリー時間
Farfetchチームは、MilvusとWeaviateは有望であるが、まだ進化中であると感じた。水平スケーリング、シャーディング、GPUサポートなどの機能がロードマップにある。30万から500万の商品カタログを扱うことを目的とするファーフェッチにとって、理想的なVSEは以下のようなものである:
- 高品質で正確な結果
- 効率的なインデックス作成機能
- 高速なクエリー実行
- ロードバランシングやデータレプリケーションのようなスケーラビリティ機能
実験によると、Milvusはインデックス作成とクエリ実行時間において、常にWeaviateを上回っていた。しかし、両プラットフォームには、複数のエンコーディングをサポートしていないなど、ある種の制限があることは注目に値する。今後の研究では、両プラットフォームの開発を注意深く監視し、新機能の導入に合わせて再評価を行う可能性がある。
このケーススタディは、元々FarfetchのPEDRO MOREIRA COSTAによって発表された詳細なベクトルデータベースベンチマーキングブログの凝縮版である。より詳細な分析と洞察については、元のブログ記事を参照してください:POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART IおよびPOWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART IIをご参照ください。
ユースケース
産業
電子商取引