




Loonのご紹介:変化し続けるベクターデータのための新しいストレージエンジン
重要なポイント
これは長く詳細なエンジニアリングの深掘りなので、詳細に入る前に重要な点を示します。
- AI データセットは静的なテーブルではありません。同じ行は、チームが埋め込みモデルを置き換え、スパースベクトルを追加し、キャプションを改訂し、ラベルをバックフィルし、インデックスを再構築し、オフライン分析を実行するにつれて、変化し続けます。
- 従来のストレージレイアウトは 3 つの点で破綻します。長いベクトル列によってバックフィルが高コストになり、単一のファイル形式ではスキャンとポイント読み取りの両方にうまく対応できず、プライベートなデータベースストレージは外部パイプラインに真実の追加コピーを作らせてしまいます。
- Loon は Milvus と Zilliz Vector Lakebase の新しいストレージエンジンです。ハイブリッドファイル形式、行 ID の整合、そしてデータセットのバージョン管理された状態を定義する Manifest を中心に構築されています。
- 目標は、単一のベクトルデータセットが、データを絶えずコピー、書き換え、再インポートすることなく、オンライン検索、オフライン分析、バックフィル、コンパクション、外部コンピュートをサポートできるようにすることです。
はじめに
しばらくの間、ベクトルデータベースに対する反論として、もっともらしく聞こえるものがありました。
従来のデータベースはすでに整数、文字列、JSON、blob、インデックスを保存している。ならば _vector_ 型を追加し、その横に ANN インデックスを構築して、それで終わりにすればよいのではないか?
初期のセマンティック検索では、それで十分に機能します。ベクトル列とインデックスがあれば、デモ、小規模な RAG アプリケーション、または社内検索機能をサポートできます。問題が現れるのはその後、データセットがテーブルというより AI データシステムのように振る舞い始めたときです。
本番環境のベクトルデータセットには、行、主キー、スカラー項目、クエリ可能な列があります。その意味では、データベーステーブルのように見えます。しかし同時に、データレイクのような規模とワークフローの形も持っています。数億件のレコードを含むことがあります。Spark、Ray、DuckDB、トレーニングパイプライン、評価ジョブ、データ品質システムによって繰り返し読み書きされます。
また、オブジェクトストレージにも依存します。ソースオブジェクトは多くの場合、S3、GCS、OSS、または別のオブジェクトストアに残る動画、画像、PDF、音声ファイル、Web ドキュメントです。データベースは参照、メタデータ、派生特徴量、インデックスを保存します。そして、従来のストレージモデルがファーストクラスオブジェクトとして管理するように設計されていなかったものを追加します。密ベクトル埋め込み、スパースベクトル、キャプション、ベクトルインデックス、テキストインデックス、削除ログ、統計情報、モデルバージョン、パーサーバージョン、外部 blob 参照、そしてそれらすべての間のバージョン関係です。
ここで「ベクトル列を追加するだけ」が破綻し始めます。 問題は、データベースがベクトルのバイト列を保存できるかどうかではありません。多くのシステムはそれができます。より難しい問いは、そのストレージモデルが、ベクトルデータがどのように変化し、どのようにクエリされ、AI データスタック全体でどのように共有されるかに対応できるかどうかです。
これが、私たちが Milvus と Zilliz Vector Lakebase (Zilliz Cloud の次の進化形)のための新しいストレージエンジンである Loon を構築した理由です。
Loon は 3 つの考え方に基づいて設計されています。
- 列の種類ごとに異なる物理形式を使用する。
- 共有された行 ID 空間を通じてそれらの列を整合させる。
- Manifest を使用してデータセットのバージョン管理された状態を定義する。
これらの要素がなぜ重要なのかを見るために、一般的なマルチモーダルワークフローから始めましょう。
ベクトルデータセットは本当の意味で完成することはありません。
マルチモーダルトレーニング用の動画データセットを構築している AI チームを想像してください。
長い動画がオブジェクトストレージにアップロードされます。パイプラインは、シーンの変化、ショット境界、または時間ウィンドウに基づいてそれをクリップに切り分けます。長すぎる、短すぎる、ぼやけている、重複している、または品質の低いクリップは除外されます。残ったクリップは、美的評価モデルによってスコア付けされ、別のモデルによってキャプション付けされ、視覚言語モデルによって埋め込まれ、検索、重複排除、トレーニングデータのフィルタリングのためにベクトルデータベースに保存されます。
大まかには、ワークフローはシンプルに見えます。
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
しかし、データセットは最初から完成した形で到着するわけではありません。
- 最初の週には、テーブルには
clip_id、video_id、start_offset、durationだけが含まれているかもしれません。 - 2週目に、チームは
aesthetic_scoreを追加します。 - 3週目に、キャプション生成モデルが実行され、各クリップに
captionが付与されます。 - 4週目に、最初の埋め込みモデルがオンラインになり、各クリップに768次元のCLIP埋め込みが付与されます。
- 1か月後、チームはモデルを切り替え、今度は1024次元の
embedding_v2をバックフィルします。 - 2か月後、ハイブリッド検索が要件になったため、チームはスパースベクトル列を追加します。
- 3か月後、キャプションは人間によるレビューを受け、インプレースで修正されなければなりません。
データセットは一度も完成しませんでした。同じ基礎となる行に対する新しい解釈が蓄積され続けたのです。
これが、ベクトルデータと従来のビジネスデータの中核的な違いの1つです。同じ行が何度も何度も再処理されます。そして規模が大きくなると、これは不便さからストレージ問題へと変わります。マルチモーダルデータセットは、しばしば数百万レコードではなく、数億または数十億レコードです。LAION-5Bは、その形を理解するうえで有用な参照例です。数十億の画像テキストペアがあり、それぞれにメタデータ、キャプション、埋め込みが付いています。したがって難しい部分は最初の挿入ではありません。難しい部分は、データセットが進化し始めた後に起こるすべてのことです。その進化は3つの問題を明らかにします。
最初の問題: 長い列は書き込み増幅を高コストにする
Parquetのようなカラムナ形式は、多くの分析ワークロードに非常に優れています。スキーマがかなり安定しており、データが書き換えられるよりも読み取られることが多く、スキャンが列の一部だけに触れ、圧縮が重要である場合にうまく機能します。それこそが、多くの分析形式が最適化されてきた世界です。
ベクトル行は分析行よりはるかに幅が広い
TPC-Hの lineitem は良いベースラインです。16列で構成され、整数キー、10進値、日付、短い文字列、小さなコメントフィールドがあります。非圧縮の1行はおよそ150バイトです。圧縮後は、はるかに小さくなる場合があります。64 MBの行グループであれば、ストレージシステムは1つのグループに数十万行を詰め込むことができます。
ベクトルデータセットはそのような形をしていません。
LAION風の画像テキストデータセットは、今日多くのAIパイプラインが生成しているものにはるかに近いです。各行には依然として通常のメタデータがあります。URL、キャプション、幅、高さ、品質スコア、ラベルなどです。しかし埋め込みが追加されると、その行の物理的な形は変わります。
768次元のCLIPベクトルは、fp16で約1.5 KB、fp32で約3 KBを占めます。その1列だけで、TPC-Hの lineitem 行全体よりもはるかに大きくなることがあります。
そして768次元は、今日の基準では珍しくも大きくもありません。1024次元または2048次元の埋め込みは、マルチモーダルパイプラインでは一般的です。OpenAIの text-embedding-3-large は最大3072次元まで対応しており、これはfp32でベクトルあたり約12 KBです。
比較は鮮明です。
| データセットの形 | おおよその行サイズ | 支配的なフィールド |
|---|---|---|
| TPC-H lineitem | 非圧縮で約150バイト | スカラーと短い文字列 |
| 768次元fp16ベクトルを含むLAION風の行 | 約1.5 KB以上 | 埋め込み |
| 768次元fp32ベクトルを含むLAION風の行 | 約3 KB以上 | 埋め込み |
| 3072次元fp32ベクトルを含む行 | ベクトルだけで約12 KB以上 | 埋め込み |
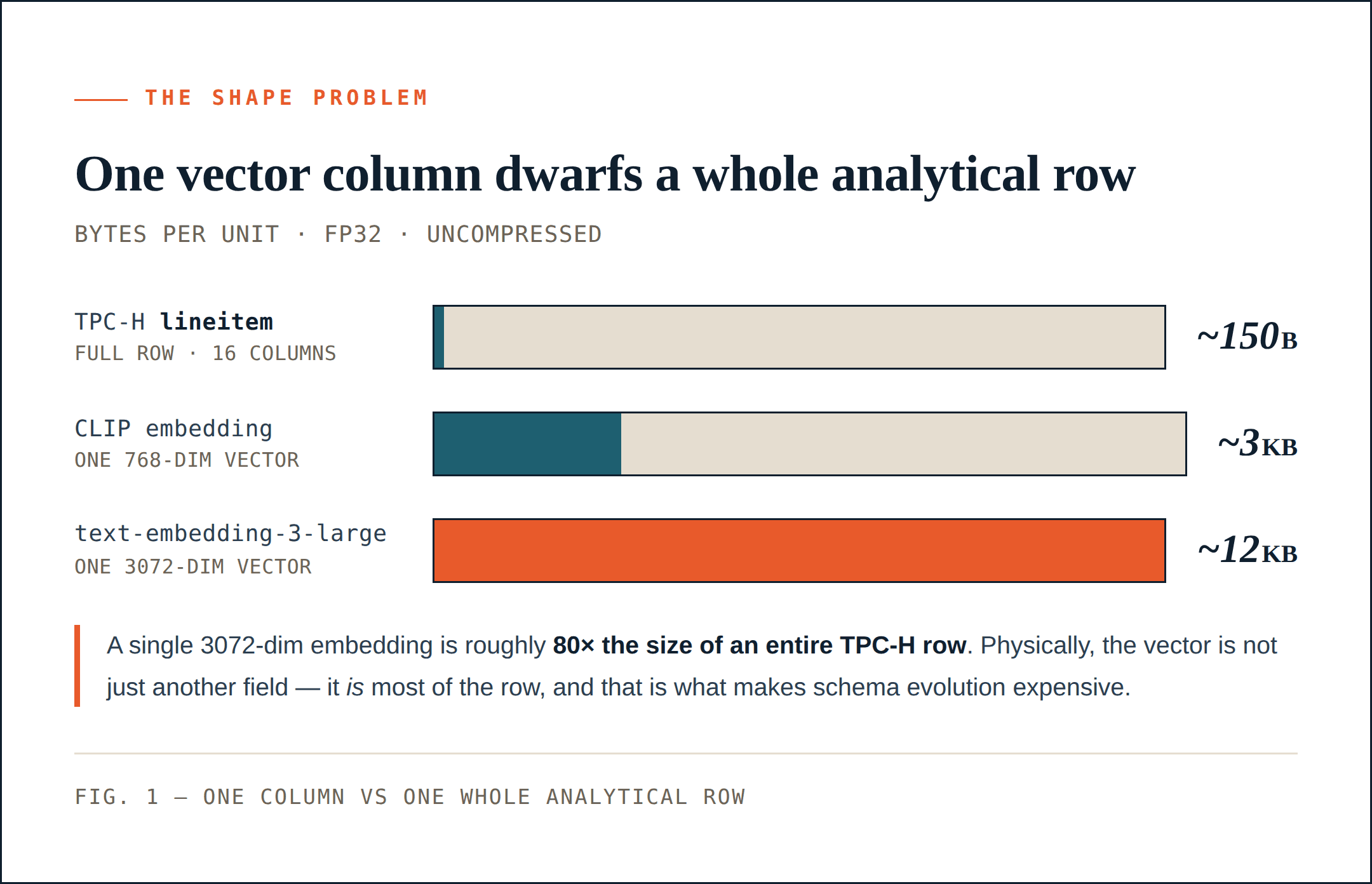
多くのAIデータセットでは、ベクトル列は単なる別のフィールドではありません。物理的には、それが行の大部分を占めています。これにより、スキーマ進化のコストが変わります。
ベクトル列を1つ追加するだけで数百ギガバイトになることがある
あるデータセットに1億本の動画クリップがあるとします。新しい1024次元fp32埋め込み列を追加するということは、およそ400 GBの生のベクトルデータを書き込むことを意味します。これには、統計、インデックス、メタデータ更新、オブジェクトストレージのオーバーヘッド、検証、または提供パスとの統合は含まれていません。

チームが毎月、embedding_v2、sparse_vector、あるいは rerank features のようなベクトル風の列を1つか2つ追加する場合、スキーマ進化は数百ギガバイト、あるいはテラバイト単位で測られる、繰り返し発生するデータエンジニアリング作業になります。
小さな論理更新が大きな物理的書き換えを引き起こすことがある
更新も同じくらい重要です。
カラムナシステムでは、古いデータは通常インプレースでは更新されません。delete log が何が変更されたかを記録し、その後 compaction が有効な行を新しいファイルへ書き換えます。このモデルは、行が小さい場合には管理可能です。
ベクトルデータでは、小さな論理更新が大きな物理的書き換えを引き起こすことがあります。
人間によるレビュー作業では、キャプション内の数百バイトを修正するだけかもしれません。しかし、キャプション、dense vector、sparse vector、その他の派生 features が同じ物理ファイルのライフサイクルを共有している場合、システムは結果的にベクトルまで書き換えることがあります。論理的な変更は小さいです。物理的な I/O は巨大になり得ます。
これがベクトルストレージにおける write amplification 問題です。高コストな部分は、ベクトルが大きいという点だけではありません。大きな派生フィールドと小さな変更可能フィールドが、しばしばそれらを1つの単位として扱うストレージレイアウトによって結び付けられてしまう点にあります。
AI データセットでは、backfill は日常的なワークロードである
従来の分析テーブルでは、スキーマ進化はたまにしか起きないかもしれません。AI データセットでは、それは日常的です。Caption models はアップグレードされます。Embedding models は置き換えられます。Sparse vectors は後から追加されます。Rerank features が現れます。Human labels は修正されます。Governance tags は backfill されます。Indexes は再構築されます。
これらの操作は単純な append ではありません。既存の行を変更または拡張することが頻繁にあります。
だからこそ、ベクトルストレージは scan throughput だけを最適化していてはいけません。backfills や partial updates もより安価にする必要があります。
2つ目の問題: 同じデータが scan と point read の両方をサポートしなければならない
データが書き込まれた後、read path は分岐します。同じベクトルデータセットには通常、2つの異なるアクセスパターンがあります: analytical scanning と point reads です。

分析ワークロードは、幅広く圧縮された scan を求める
パイプラインは次のような filter を実行することがあります:
WHERE aesthetic_score > 0.8 AND duration > 5
あるいは、offline analysis、full embedding evaluation、BM25 statistics、bitmap construction、data quality checks、counts、group-bys を実行することもあります。
このパターンは多くの行を読みますが、列は少数しか読みません。sequential I/O、より大きな row groups、compression、column pruning、batch decoding、vectorized execution を好みます。
大きな row groups はここで役立ちます。単一の I/O request で大量の有用なデータを取得でき、compression efficiency を向上させ、execution engine に十分な連続データを提供して overhead を償却できます。複数の列を一緒に読む場合、scan throughput のためにそれらを整理しておくことは、vectorized execution 中の cache misses を減らすのにも役立ちます。
Parquet はこの path に強いです。
ANN の結果には、狭い row-level lookups が必要である
ANN search が candidate row IDs を返した後、システムはしばしば次のようなフィールドを取得する必要があります:
caption
embedding
rerank feature
video_uri
metadata
このパターンはより少ない行、しばしば数百または数千行を読みますが、row ID による正確なアクセスが必要です。特定の行と列を見つけ、必要な byte range だけを取得し、数件のレコードを取得するためだけに row group 全体を読み込むことを避けたいのです。
Point lookup は scanning とはほぼ正反対の好みを持ちます。より小さな read granularity を求めます。理想的には、storage layer が row ID によって関連する segment または byte range を見つけ、その range だけを読み、結果に必要なデータだけを decode できることです。
Compression にも異なる tradeoff があります。scan では、システムが大量のデータを読み I/O を節約できるため、より重い compression はしばしば価値があります。point lookup では、1行を取得するためにより大きな compressed block を decode する必要がある場合、compression は負担になり得ます。
1つの layout では両方の path を最適化できない
これが核心的な対立です。スカラーのフィルタリングと分析は、幅広く、圧縮され、スキャンしやすいレイアウトを求めます。ベクトルのルックアップは、狭く、精密で、行アドレス指定可能なレイアウトを求めます。
単一のファイル形式で両方をある程度サポートすることはできますが、両方に対して同時に最適であることはできません。
すべてのカラムがParquetにある場合、スカラーのスキャンは快適です。しかし、リコール後のANNルックアップは難しくなります。システムが必要とするのは数百個のベクトル、キャプション、またはメタデータレコードだけかもしれませんが、ストレージ層はほとんど無関係な行を含む大きな行グループを読み込まなければならない場合があります。
ローカルSSDでは、キャッシュとmmapがこのコストの一部を隠してくれます。データがオブジェクトストレージに保存されると、そのコストはより顕在化します。キャッシュミスのたびにリモートのrange readが発生する可能性があります。候補行が多数の行グループに散在している場合、1つのクエリが複数の読み取りを引き起こし、それぞれがクエリに必要な量を超えるデータを取得することになります。レイアウトが不適切な場合、1,000件の候補行を取得するだけで、容易に数十から数百メガバイトの不要なI/Oが発生し、極端なケースではそれ以上になることもあります。
行グループを小さくするとポイントルックアップには役立ちますが、スキャンには悪影響を与えます。小さな断片が多すぎると、圧縮効率が低下し、メタデータのオーバーヘッドが増え、分析エンジンが依存する長いシーケンシャル読み取りが損なわれます。
したがって問題は、単一の魔法のような行グループサイズを見つけることではありません。問題は、同じデータセットが2つの異なるストレージシステムのように振る舞うことを求められている点にあります。
ハイブリッド検索は両方の経路を1つのクエリに押し込む
ハイブリッド検索は、この対立を無視しにくくします。1つのクエリはまずスカラーフィルタを適用するかもしれません。
aesthetic_score > 0.8 AND duration > 5
次にANN検索を実行します。
その後、行IDによってキャプション、ベクトル、メタデータを取得します。
ユーザーにとって、これは1つの検索リクエストです。ストレージ層にとっては、分析スキャンであると同時に低レイテンシのランダムルックアップでもあります。
だからこそ、ベクトルストレージには、より良いParquet設定以上のものが必要です。実際にどのように読み取られるかに応じて、異なるカラムを配置する方法が必要なのです。
第三の問題: データセットは1つのエンジンの中に存在しているわけではない

AIデータパイプラインは多くのシステムにまたがる
動画ワークフローでは、ベクトルデータベース自体の内部で行われることはごくわずかです。
生の動画はオブジェクトストレージにあります。クリップ生成はSparkやRayで実行されるかもしれません。美的スコアリングはGPUサービスで実行されるかもしれません。キャプション生成はLLM推論パイプラインで実行されるかもしれません。埋め込みは別のGPUジョブで生成されるかもしれません。スパースベクトルはSPLADEサービスから来るかもしれません。オフライン評価、学習データのフィルタリング、人手によるレビュー、ガバナンスジョブもすべて別の場所で実行される可能性があります。
ベクトルデータベースはオンライン検索を提供しますが、データセットは多くのシステムによって生成され、修正され、評価され、拡張されます。
プライベートなストレージ形式は複数の真実のコピーを生む
データベースが、そのデータベースだけが読み書きできるプライベートな物理形式を使用している場合、すべての外部ジョブにはエクスポート、変換、コピー、インポートが必要になります。同じコレクションが、データベース内、Sparkの一時ディレクトリ内、評価出力内、ローカルのバックフィルディレクトリ内に存在するかもしれません。すると本当の問題は次のようになります。
- どのコピーが信頼できる唯一の情報源なのか?
- どれが先月のキャプションモデルを含んでいるのか?
- どの行がすでに人手によるレビューで修正されているのか?
- どのスパースベクトルカラムがどのモデルによって生成されたのか?
- バックフィル後もどのベクトルインデックスがまだ有効なのか?
- この行はどの元動画オブジェクトを参照しているのか?
小規模であれば、チームは命名規則や手動チェックで何とか乗り切れることもあります。数億行と数テラバイトの埋め込みになると、これは一貫性の問題になります。
ベクトルデータセットには共有されたバージョン付き状態が必要です
Lakehouse システムは、構造化データにおけるこの問題の一形態に対処しました。Iceberg、Delta Lake、Hudi は、単にファイルを保存するためのものではありません。その中核的な貢献は、複数のエンジンが同じテーブル状態を中心に連携できるようにすることです。
ベクトルデータベースにも今、同様の機能が必要ですが、その状態はより複雑です。テーブルファイルやパーティションだけでなく、ベクトルインデックス、テキストインデックス、スパース特徴量、削除ログ、統計情報、行 ID 範囲、外部 blob への参照も含める必要があります。
問題は単に、「Spark は Milvus のファイルを読めるのか?」ではありません。
問題は、Spark がスパースベクトル列をバックフィルした後、Milvus はその列がどのバージョンに属し、どの行を対象とし、どのモデルによって生成され、オンラインクエリがいつ安全に利用できるのかを、どのように把握するのか、ということです。
その答えはストレージモデルの中に存在しなければなりません。
パッチだけでは不十分な理由
これらを 3 つの別々のエンジニアリング課題として扱いたくなるかもしれません。
- 書き込み増幅?バッチ処理を追加する。
- ポイント読み取り?キャッシュを追加する。
- 外部システム?エクスポートとインポートのツールを追加する。
こうしたパッチは役立つことがありますが、根本的な問題には対処していません。つまり、ベクトルデータセットは物理的に異種混在であるということです。

動画の例では、clip_id、video_id、duration、aesthetic_score は短いスカラー項目です。これらはフィルタリングや分析に役立ちます。
captionはテキストです。BM25、レビュー、修正、バックフィルに使用されることがあります。embeddingは長い密ベクトルです。ANN リコールに使用され、その後、行レベルの検索やリランキングにも使われます。embedding_v2は新しいモデルの出力であり、多くの場合、元のデータが挿入されてからかなり後にバックフィルされます。sparse_vectorはハイブリッド検索をサポートし、独自のアクセスパターンを持ちます。- 生の動画はオブジェクトストレージに置いておくべきです。データベースは参照、チェックサム、MIME タイプ、パーサーバージョン、行レベルの関係を保存すべきです。
- ベクトルインデックス、テキストインデックス、統計情報、削除ログは、それぞれ独自のバージョンセマンティクスを持つ派生オブジェクトです。
これらのオブジェクトは論理的な行を共有しますが、すべてが同じ物理レイアウトやライフサイクルを共有すべきではありません。
- それらが 1 つの通常のテーブルレイアウトに押し込められると、更新は高コストになります。
- それらが 1 つのカラムナファイル形式に押し込められると、ポイント読み取りは高コストになります。
- それらが無関係なオブジェクトファイルとして扱われると、バージョン管理は脆弱になります。
したがって、ストレージモデルは、データセットが異種混在であるという事実から出発する必要があります。
これにより、3 つの設計要件が導かれます。
- 第一に、異なる列グループは異なる物理フォーマットで保存されるべきです。
- 第二に、それらの列グループには共有された行 ID 空間が必要です。そうすることで、単一の論理テーブルとして振る舞い続けられます。
- 第三に、データセットには、どのファイル、インデックス、ログ、統計情報、オブジェクト参照が現在のビューに属するのかを宣言する、バージョン管理された Manifest が必要です。
これが、Milvus と Zilliz Cloud の背後にある新しいストレージエンジンである Loon の設計です。
Loon: 進化するベクトルデータセットのための、Milvus と Zilliz Cloud の背後にあるストレージエンジン
上記のすべての問題を解決するために、私たちは Loon を構築しました。これは、Milvus と Zilliz Vector Lakebase(Zilliz Cloud の次なる進化)のための新しいストレージエンジンであり、進化するベクトルデータセット向けに設計されています。
この名前は、Zilliz の鳥にちなんだ命名の伝統に従っています。loon は湖に生息する潜水鳥であり、このシステムの目標によく対応しています。つまり、ベクトルデータベースは、クエリを実行したり、列をバックフィルしたり、インデックスを構築したりするたびに、データの湖全体を移動、スキャン、または書き換える必要があってはならないということです。まず、列、インデックス、統計情報、削除ログ、オブジェクト参照を含む現在のデータセットバージョンを理解し、そのうえで実際に必要な部分だけを読み取るべきです。
ハイブリッドファイル形式、行 ID の整合、Manifest は、3 つの別々の機能ではありません。これらは同じ設計上の前提から生まれています。すなわち、ベクトルデータセットは本質的に異種混在であるという前提です。
3つの要素、1つのストレージモデル
ハイブリッドファイル形式は、列ごとに異なるアクセスパターンがあることを前提としています。スカラー項目はスキャンやフィルターに適しています。ベクトル項目には効率的な行レベルのルックアップが必要です。動画、PDF、画像、音声ファイルなどの生オブジェクトは、データベースのデータファイル内ではなく、オブジェクトストレージに置くべきです。
行IDの整合は、これらの列が物理的には分離されていても、同じ論理行を記述していることを前提としています。キャプション、埋め込み、スパースベクトル、動画URIは異なるファイルや形式に存在するかもしれませんが、それでも単一の結果として再び結合される必要があります。
Manifestは、データセットが一度書き込まれて放置されるものではないことを前提としています。データセットは、複数のシステムによって、複数のバージョンにわたり、複数のタスクのために変更されます。インデックス、統計情報、削除ログ、外部オブジェクト参照、列グループは、すべて同じバージョン管理されたビューに現れなければなりません。
これが、Loonが単なるより高速なベクトルファイル形式ではない理由です。 より高速な形式はポイントルックアップに役立ちますが、スキーマ進化やマルチエンジン連携の問題は解決しません。行IDの整合により、分割された列は単一のテーブルのように振る舞えますが、どのファイルが現在のバージョンに属するのかは指定しません。Manifestはデータセットの状態を記述できますが、列グループと行IDの整合がなければ、1つの論理コレクション内の異なる物理レイアウトをきれいに表現することはできません。
ストレージモデルには、3つすべてが必要です。異なる列グループのための異なる形式、行を再構築するための共有された行ID空間、そしてデータセットの現在の状態をすべての読み取り側と書き込み側に伝えるバージョン管理されたManifestです。
MilvusとZilliz Vector LakebaseにおけるLoonの位置づけ
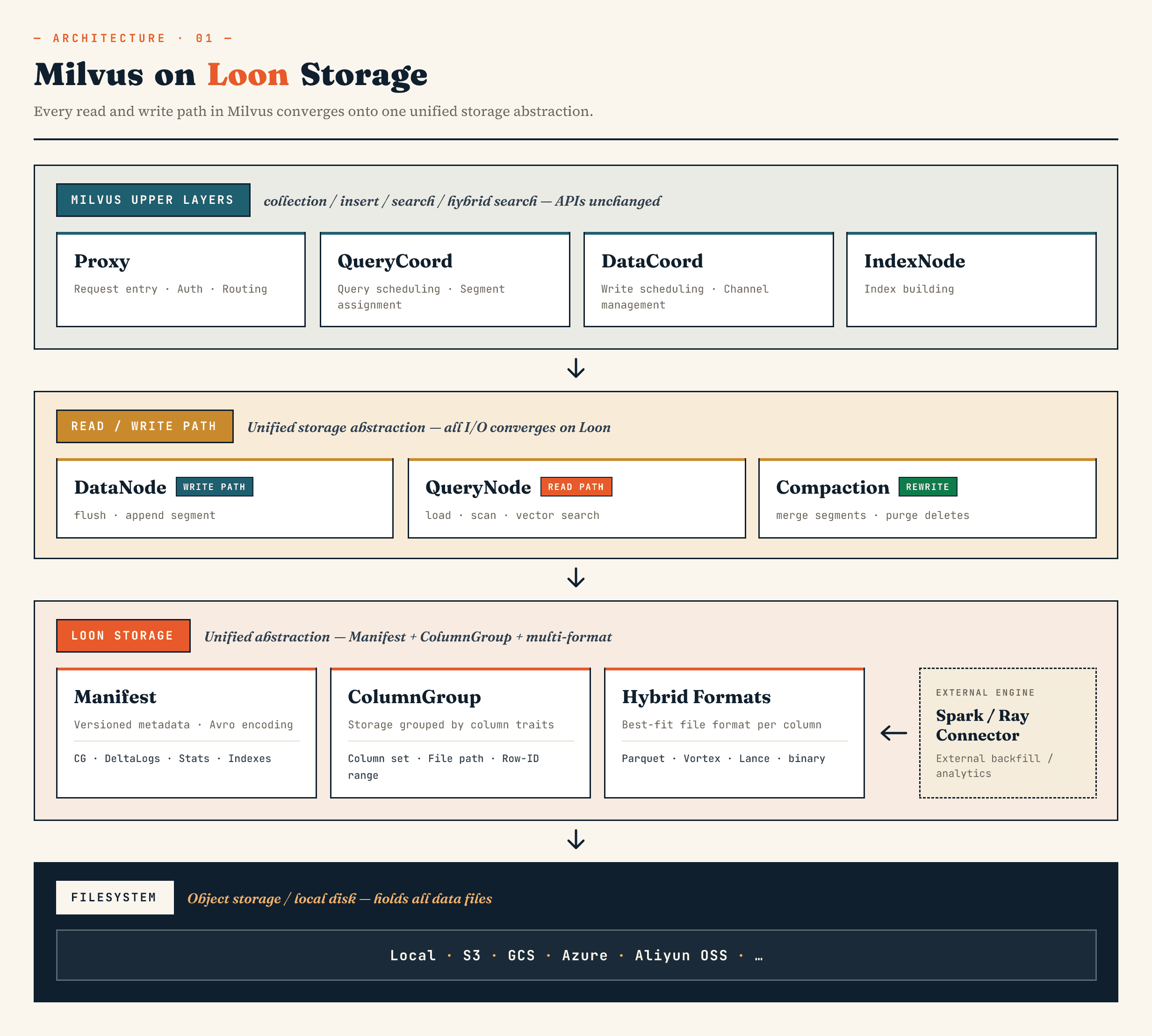
Milvusでは、Manifest、ColumnGroup、ファイル形式、ファイルシステム抽象化を中心に構築されたモデルによって、従来のセグメントbinlogストレージ層を置き換えます。Zilliz Vector Lakebase(Zilliz Cloudの次の進化形)では、 同じ方向性がVector Lakebaseアーキテクチャにも適用されます。つまり、ベクトルデータベースのサービングパスを高速に保ちながら、基盤となるデータを進化、分析、外部システムとの連携がしやすいものにします。
上位レベルのMilvusコンポーネントは、引き続きおなじみの役割を維持します。Proxyはルーティングを処理します。QueryCoordとDataCoordはスケジューリングを処理します。IndexNodeはインデックスを構築します。コレクション、挿入、検索、ハイブリッド検索のアプリケーション向けAPIは、ManifestファイルやColumnGroupsを公開する必要はありません。
変化はその下にあります。
DataNode、QueryNode、segcore、コンパクション、外部コネクタは、同じストレージ抽象化を通じて動作できます。これが重要なのは、データセットがもはやデータベースだけによって書き込まれ、読み取られるものではないからです。外部のコンピューティングシステムによって拡張され、同時にオンライン検索によって消費される可能性があります。
大まかに言うと、レイヤーは次のようになります。
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
Manifestは、データセットのバージョン管理された状態を記述します。ColumnGroupsは、論理コレクションを物理的な列グループにマッピングします。ファイル形式レイヤーにより、各ColumnGroupは適切な形式を選択できます。ファイルシステム抽象化は、オブジェクトストレージとローカルストレージの両方で機能します。
重要なのは、ハイブリッドファイル形式、行IDの整合、Manifestが別々の機能ではないということです。これらが一緒になって、ストレージモデルを定義します。
このモデルが整ったところで、3つの設計上の選択を1つずつ見ていくことができます。Loonが異なるColumnGroupsをどのように保存するか、それらをどのように行へ再整合するか、そしてManifestがそれらのファイルをどのようにバージョン管理されたデータセットへ変えるかです。
設計1:適切な列グループには適切なファイル形式を使用する
列ごとに異なるアクセスパターンがあります。それらを同じファイル形式に押し込むべきではありません。
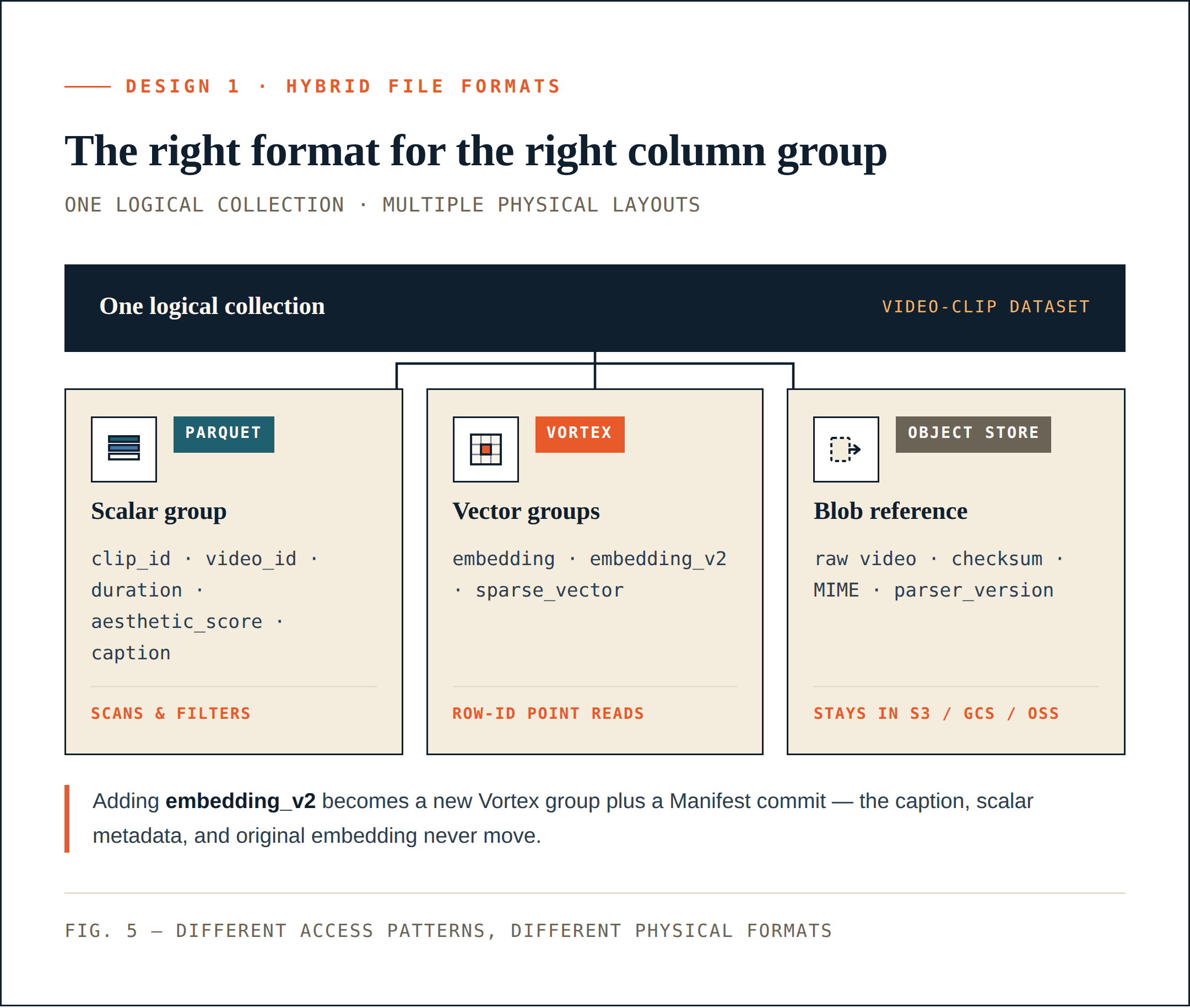
Loon は論理的なコレクションを ColumnGroup に分離します。
- スカラー フィールド、フィルター フィールド、ビジネス キー、統計フィールドは、スキャン、フィルタリング、集計、またはクエリ計画に使用されることがよくあります。これらは圧縮、カラム プルーニング、エコシステム互換性の恩恵を受けます。Parquet はこれらのカラムに適しています。
- 密ベクトル、疎ベクトル、rerank 機能は、ANN リコール後に行 ID によって読み取られることがよくあります。これらには低レイテンシのランダム アクセス、正確なバイト範囲読み取り、選択的デコードが必要です。セグメント指向のレイアウトの方が適しています。Loon はこの方向で Vortex を使用します。
- 動画、PDF、画像、音声ファイルなどの生オブジェクトは、ベクトル データベースのデータ ファイルに埋め込むべきではありません。これらはオブジェクト ストレージに残すべきです。データベースは参照、チェックサム、MIME タイプ、パーサー バージョン、行レベルの関係を記録します。
動画の例では、物理レイアウトは次のようになります。
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
アプリケーションにとって、これは依然として 1 つのコレクションです。ストレージ レイヤーにとっては、そのコレクションの異なる部分が異なる物理フォーマットを使用します。これにより、不要な再書き込みが直接削減されます。embedding_v2 の追加は、新しいベクトル ColumnGroup と Manifest コミットにできます。caption カラム、スカラー メタデータ、既存の embedding カラムを書き換える必要はありません。
同じ考え方は、疎ベクトル、rerank 機能、その他の派生フィールドにも適用されます。新しいカラムが物理的に独立しており、行 ID で揃えられる場合、無関係なカラムを同じ再書き込み経路に巻き込む必要はありません。
Loon はファイル フォーマットの使い方も適応させます。
Parquet では、デフォルト設定がベクトル中心のデータに常に最適とは限りません。 64 MB の行グループは、ポイント ルックアップには大きすぎる場合があります。小さなランダム読み取りが、必要以上にはるかに多くのデータを取り込む可能性があるためです。Loon は関連するパスで行グループを 1 MB に絞り、ベクトル カラムの dictionary encoding など、ランダムに見えるベクトル データに役立たないエンコーディングを無効にします。
Vortex でより重要なのはレイアウトです。 Loon は、スキャン効率とポイント ルックアップのバランスを取るレイアウトを使用します。行グループ内では、関連カラムのセグメントを近接して配置し、スキャンをサポートできます。操作を実行する際、サブセグメント読み取りにより、システムはセグメント全体を取り込むのではなく、関連するバイトのみを取得できます。
Loon は読み取り専用の Lance 統合もサポートしています。そのため、互換性が重要な場合、既存の Lance データセットを ColumnGroup としてマウントできます。
ベンチマークが示すこと
あるローカル テストでは、40,000 行とスキーマ {id: int64, name: utf8, value: float64, vector: list<float32>[128]} を持つ単一ファイルを使用し、Vortex は 1 MB 行グループの Parquet に対して次の結果を示しました。
| Operation | Vortex | Parquet | Difference |
|---|---|---|---|
| Take, K=1000 random rows | 5.8 ms | 144 ms | 25x faster |
| Full vector-column scan | 21 ms | 142 ms | 6.76x faster |
| File size, ~21 MB raw data | 6.62 MB | 7.16 MB | 7% smaller |
take の結果は、読み取りとデコードが必要な無関係データの量を削減したことによるものです。スキャンの結果は、圧縮と実装上の選択によるものです。
これらの数値は、そのセットアップに紐づけて理解する必要があります。8 vCPU Ubuntu 22.04 KVM、ローカル ファイルシステム、単一ファイル、40,000 行、1 MB 行グループ、および上記のスキーマです。オブジェクト ストレージでは、ネットワーク I/O が支配的になることがあるため、読み取り増幅の削減はさらに重要になる可能性があります。実際の結果は、データセットの形状、オブジェクト ストレージの挙動、キャッシュ状態、クエリ パターンによって異なります。
より広い要点は、すべてのカラムが Vortex を使用すべきだということではありません。
要点は、ベクトル データセットには ColumnGroup レベルでのファイル フォーマット選択が必要だということです。

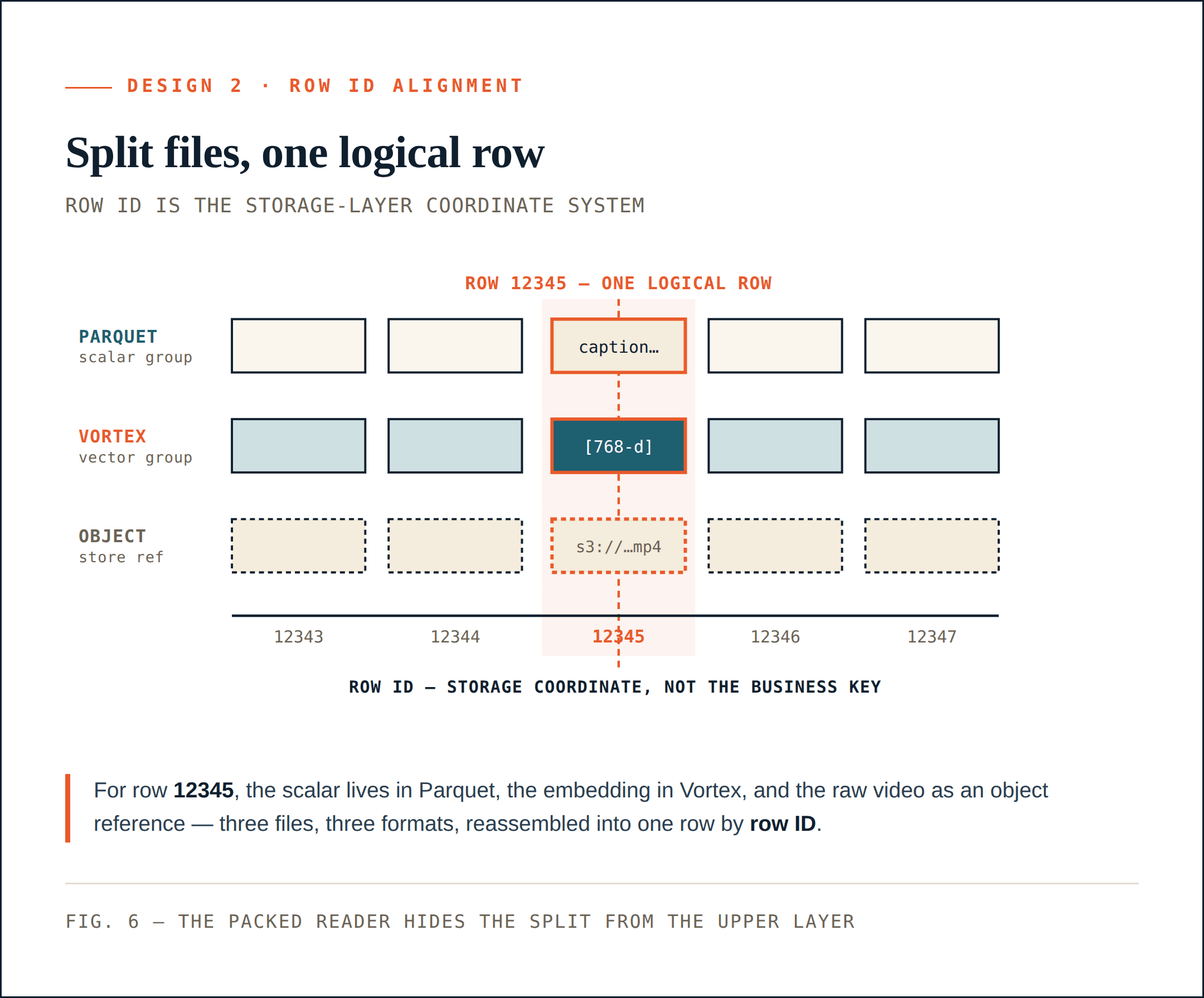
設計 2: 行 ID によって物理ファイルを整列させる
ハイブリッドファイル形式は 1 つの問題を解決します。つまり、異なる列を、それぞれに最も適した形式で保持できるようになります。
しかし、それによって 2 つ目の問題が生まれます。スカラー フィールドが Parquet に、ベクトルが Vortex に、生のオブジェクトがオブジェクトストレージに存在する場合、システムはそれらをどのようにして 1 つのコレクションとして扱い続けるのでしょうか。
Loon は行 ID の整列によってこれを解決します。
行 ID はストレージ層の座標系である
各物理 ColumnGroupFile は、ファイルパスと、それがカバーする行 ID 範囲を記録します。
path
start_index
end_index
異なる ColumnGroups は、たとえ異なるファイルや形式に存在していても、同じ行 ID 空間をカバーできます。
行 ID 12345 について、スカラー メタデータは Parquet ColumnGroup に、埋め込みは Vortex ColumnGroup に、生の動画はオブジェクトストレージ参照として表現されているかもしれません。論理的には、それらは依然として 1 つの行です。これにより、ストレージ層には安定した座標系が与えられます。
行 ID はビジネス上の主キーではありません。これは、Loon がコレクションを物理的に分割しながらも、それを論理的に再構築する能力を失わないようにするための、ストレージ層の座標系です。
新しい列のために古い列を書き換える必要はない
embedding_v2 を追加しても、元のキャプション、メタデータ、または embedding_v1 ColumnGroups を書き換える必要はありません。Loon は新しいベクトル ColumnGroup を書き込み、それがカバーする行 ID 範囲を記録し、その変更を Manifest を通じてコミットできます。
同じことは、後から到着するスパースベクトル、rerank 機能、またはその他の派生フィールドにも当てはまります。
新しい ColumnGroup が正しい行 ID 範囲をカバーしている限り、無関係なデータの移動を強制することなく、同じ論理コレクションに結合できます。
削除とコンパクションはより対象を絞れる
行 ID の整列は削除にも役立ちます。
削除はまず削除ログを通じて表現できます。その行は論理レベルで不可視になり、物理的なクリーンアップはコンパクションまで遅延されます。最終的にコンパクションが実行されるとき、影響を受ける行に紐づくすべての ColumnGroup を常に書き換える必要があるわけではありません。クリーンアップが必要な ColumnGroups に集中できます。
これは、すべての列が同じコスト特性を持つわけではないため重要です。短いスカラー ColumnGroup を書き換えることは、数百ギガバイトの密ベクトルを書き換えることとは大きく異なります。
ハイブリッド検索は必要な列だけを取得できる
行 ID の整列は、ハイブリッドファイル形式の上でハイブリッド検索を実用的にするものでもあります。
ANN 検索が候補行 ID を返した後、システムは最終結果に必要なフィールドだけを取得できます。キャプション、メタデータ、ベクトル、rerank 機能、またはオブジェクト参照です。
たとえば、クエリには次が必要になる場合があります。
caption
embedding
video_uri
これらのフィールドは異なる ColumnGroups に存在しているかもしれません。Loon は行 ID 範囲によって関連ファイルを特定し、必要なバイト範囲を読み取り、結果を組み立てることができます。
行 ID の整列がなければ、ハイブリッド形式は単に別々のファイルが並んで置かれているだけになります。行 ID の整列があれば、それらは単一の論理コレクションとして振る舞います。
Packed Reader は上位層から分割を隠す
これを使いやすくしているランタイムコンポーネントが Packed Reader です。
上位層には、統一された Arrow RecordBatch ストリームが見えます。その下では、データは異なるファイル形式の複数の ColumnGroups から来ている場合があります。Packed Reader はそれらの違いを隠し、row-ID 範囲によってデータを整列させ、制御されたメモリ使用量でマルチファイル I/O をスケジュールします。
また、行 ID による直接の take もサポートします。行 ID の集合が与えられると、関連する ColumnGroupFiles を特定し、範囲読み取りを発行し、要求されたフィールドを返します。
動画ワークフローでは、ANN クエリに caption、embedding、video_uri が必要になる場合があります。Packed Reader は、無関係な列に触れることなく、スカラー ColumnGroup とベクトル ColumnGroup を取得できます。
それが「別々のファイル」と「複数の物理レイアウトを持つテーブル」の違いです。
Design 3: Manifestを信頼できる唯一の情報源にする
ハイブリッドファイルフォーマットは、データが物理的にどのように保存されるかを定義します。行IDの整合性によって、分離されたColumnGroupがそれでも単一の論理テーブルを形成できるようになります。しかしシステムは、さらに大きな問いに答える必要があります。現在のデータセットバージョンに属するファイル、ログ、統計、インデックス、オブジェクト参照はどれか? それがManifestの役割です。

オブジェクトストレージのディレクトリだけでは不十分
オブジェクトストレージはデータベースカタログではありません。ディレクトリには、古いファイル、新しいファイル、失敗したジョブの出力、一時ファイル、削除ログ、古いスナップショットからまだ参照されているファイル、クリーンアップ待ちのファイルが含まれている場合があります。ファイルが存在するという事実は、それが現在のデータセットバージョンに属していることを意味しません。
Loonデータセットは、次のようなディレクトリに編成される場合があります。
_metadata/
_data/
_delta/
_stats/
_index/
しかし、ディレクトリ構造は信頼できる唯一の情報源ではありません。Manifestがそうです。リーダーはディレクトリを一覧表示して、たまたま存在するファイルから状態を推測すべきではありません。現在のManifestを読み、それが宣言するバージョン化されたビューに従うべきです。
Manifestはデータセットの1つのバージョン化されたビューを定義する
Manifestは、特定のバージョンにおけるデータセットを定義します。Manifestは次を記録します。
- どのColumnGroupが存在するか
- それらがどの行ID範囲をカバーするか
- 各ColumnGroupがどの物理フォーマットを使用するか
- ファイルがどこにあるか
- どの削除ログがアクティブか
- どの統計が利用可能か
- どのインデックスが存在するか
- どの外部blobが参照されているか
- それらの統計またはインデックスがどの列と行範囲をカバーするか
各更新は新しいManifestバージョンを書き込みます。バージョンNを開いたリーダーは、バージョンNにおけるデータセットの安定したビューを参照します。ライターは、まだバージョンNを使用しているリーダーを妨げることなく、バージョンN+1を準備できます。
Manifestはテーブルファイル以上のものを追跡する
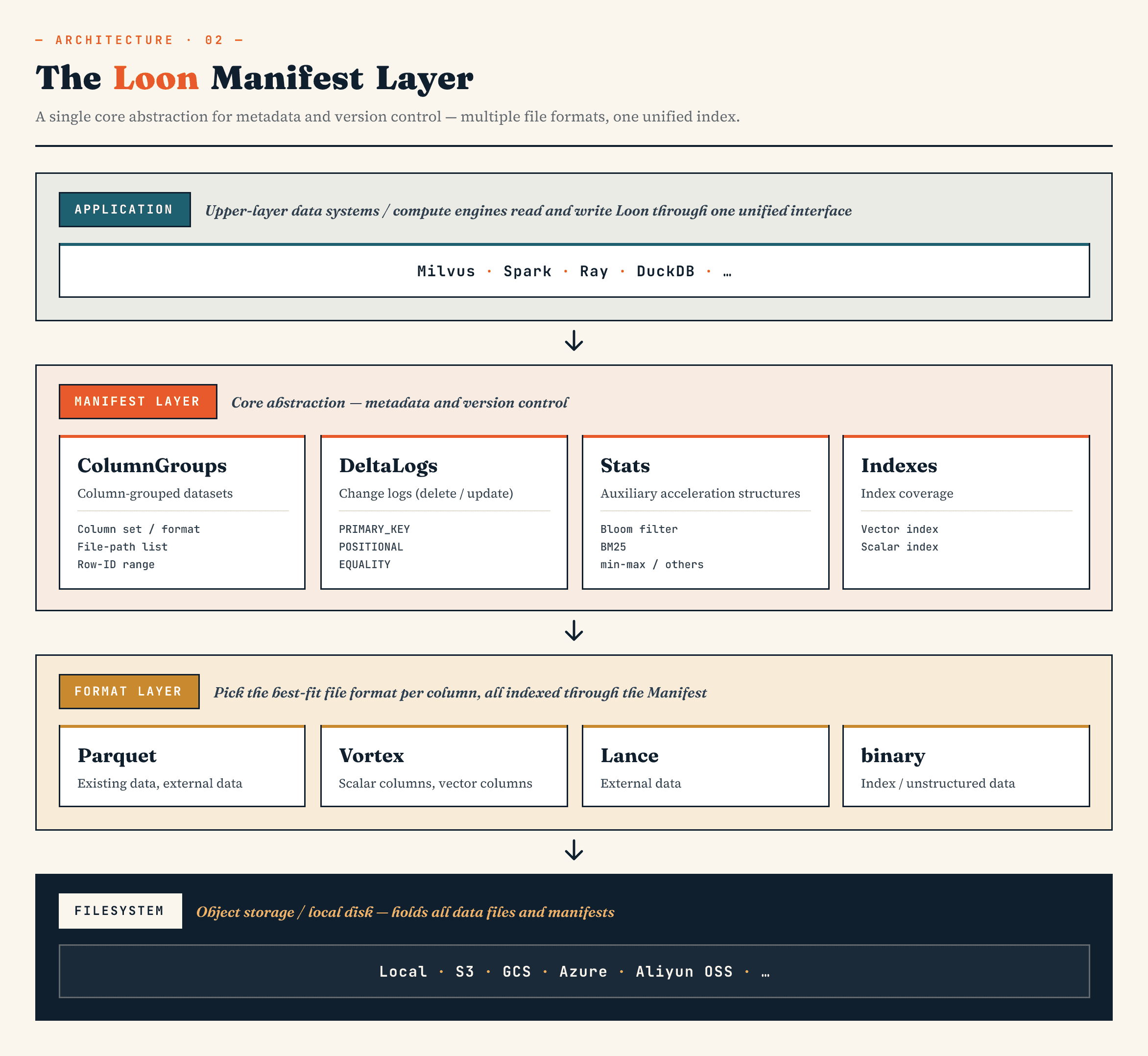
Loonでは、Manifest本体はApache Avroでエンコードされ、4つの主要なセクションを中心に構成されます。
- ColumnGroupsは、列、フォーマット、ファイル、行ID範囲を記述します。
- DeltaLogsは削除を記述します。異なる削除タイプは、クライアントからの主キー削除、内部コンパクションからの位置削除、外部エンジンからの等価削除など、異なる変更元をカバーします。
- Statsには、bloom filter、BM25統計、min/max値などのプランニング用メタデータが含まれます。
- Indexesは、インデックスタイプ、パラメータ、対象列、行ID範囲を記述します。これには、HNSWやIVFなどのベクトルインデックス、テキストインデックス、転置インデックス、ビットマップインデックス、および関連構造を含めることができます。
ここが、Loonが従来のテーブルManifestと異なる点です。
ベクトルデータセットでは、データファイルとパーティションだけを追跡すればよいわけではありません。ベクトルインデックス、テキストインデックス、スパース特徴量、削除ログ、統計、外部オブジェクト参照、そしてそれらを結び付ける行ID範囲も追跡する必要があります。
Manifestはデータベース以外からも書き込み可能でなければならない
最も重要なのは、Manifestに何が含まれるかだけではありません。誰がそれを書き込めるかです。
- データベースだけがManifestを書き込める場合、それは内部メタデータのままです。より整理されたメタデータではありますが、それでも1つのエンジン専用です。
- 外部エンジンが新しいColumnGroup、統計、Manifestエントリを生成できる場合、Manifestは調整インターフェースになります。
- たとえばSparkジョブは、スパースベクトル列をバックフィルできます。新しいColumnGroupを書き込み、行カバレッジと統計を記録し、新しいManifestをコミットします。オンラインクエリは、そのジョブ中も古いバージョンを読み続けることができます。コミットが成功すると、新しいバージョンが可視になります。
これは精神的にはIcebergやDelta Lakeに似ていますが、オブジェクトモデルはより広範です。ベクトルデータセットでは、テーブルファイルとパーティションだけでなく、ベクトルインデックス、テキストインデックス、スパース特徴量、削除ログ、統計、blob参照、行ID範囲を追跡する必要があります。
楽観的コミットによりバージョン更新をシンプルに保つ
各コミットは新しい Manifest バージョンを書き込みます。ライターはバージョン N に基づいて新しいコンテンツを構築し、その後 manifest-{N+1}.avro の書き込みを試みることができます。オブジェクトストレージの条件付き書き込み、または generation-match セマンティクスにより、そのバージョンがすでに存在する場合はコミットを失敗させることができます。ライターはその後、より新しいバージョンに対してリトライできます。
これにより、Loon はすべての更新を重く強整合な調整パスに通すことなく、楽観的同時実行制御を実現できます。Manifest がなければ、マルチフォーマットかつマルチエンジンのストレージは、最終的に命名規則と手動の調整に行き着きます。それは小規模なデータセットでは機能するかもしれません。TB スケールのベクトルデータでは機能しません。
Manifest は、異種ファイルを、複数のシステムが安全に読み取り更新できるデータセットへと変えるものです。
ストレージがバージョン化されるとユーザーに何が変わるか
アプリケーション開発者にとって、Loon は新たな API 負担になるべきではありません。
ユーザーは引き続き、コレクション、挿入、検索、ハイブリッド検索といった馴染みのある Milvus の概念で作業できるべきです。通常のアプリケーション開発中に、Manifest ファイル、ColumnGroup、行 ID 範囲、ファイルレイアウトについて考える必要はありません。
変化はその下にあります。ストレージは、AI データセットが実際にどのように進化するかをより意識するようになります。
新しい埋め込みの追加で古いデータを移動するべきではない
以前は、既存のコレクションに embedding_v2 を追加するには、多くの場合、データをエクスポートし、新しいモデルを学習し、ベクトルを生成し、その後 SDK 経由でコレクションに再インポートまたは一括更新する必要がありました。この経路は、バージョン追跡、失敗したジョブのリトライ、インデックス再構築、サービングへの影響、整合性チェックなど、多くの運用作業を生み出します。
Loon では、これはスキーマ進化と新しい ColumnGroup コミットにできます。 新しい埋め込みカラムは、行 ID によって整列された独自の物理 ColumnGroup として書き込まれ、Manifest を通じて可視化できます。古いキャプションカラム、スカラーメタデータカラム、元の埋め込みカラムを移動する必要はありません。
バックフィルにクライアント側の更新ループを必要とすべきではない
多くの AI データ更新はバックフィルです。チームは、ハイブリッド検索が重要になった後にスパースベクトルを追加するかもしれません。新しいモデルを学習した後にリランキング特徴量を追加するかもしれません。人間のレビュー後にキャプションを修正するかもしれません。ポリシー更新後にガバナンスタグを追加するかもしれません。
従来のレイアウトでは、こうした変更は、データが Spark、Ray、または別の外部エンジンによって生成されている場合でも、クライアント SDK 更新またはデータベース専用の書き込みパスを通じて行われることがよくあります。
Loon では、外部コンピュートシステムが新しい ColumnGroup を生成し、Manifest を通じてそれらをコミットできます。データベースは、すべての書き換えの唯一の入口である必要がなくなります。
オフライン分析に別の真実のコピーを必要とすべきではない
以前は、チームはオフライン評価や分析のためにオンラインコレクションを Parquet にダンプすることがよくありました。これにより、同じデータセットの 2 つのバージョン、つまりオンラインコレクションと分析用コピーが作られます。キャプションが修正され、埋め込みが再生成され、削除ログが適用され、またはインデックスが再構築されると、チームはどちらのコピーが最新なのかを問わなければなりません。
Manifest ベースのストレージモデルでは、分析エンジンはサービングシステムと同じバージョン化されたデータセットビューを読み取ることができます。必要なカラムだけを射影し、関連する行範囲だけをスキャンし、手動でエクスポートされたスナップショットではなく宣言されたデータセットバージョンに対して作業できます。
削除と修正は変更されたものだけに触れるべきである
削除、キャプション修正、ラベル修正、ガバナンス更新は AI データセットでは日常的です。それらによって、すべての長いベクトルカラムを同じ書き換えパスに通すべきではありません。
Loon では、削除ログをまず論理削除として扱えます。後続のコンパクションで、無関係なデータを書き換えることなく、影響を受けた ColumnGroup をクリーンアップできます。短いテキストフィールドが変更された場合、同じ論理行を共有しているというだけで、ストレージ層が数百ギガバイトの密ベクトルを書き換える必要はありません。
外部エンジンは逃げ道ではなくワークフローの一部になる
より大きな変化は、外部エンジンがもはやベクトルデータベースの外側にあるシステムとして扱われなくなったことです。
Spark、Ray、評価ジョブ、ラベリングシステム、ガバナンスパイプラインは、すでにデータの大部分を生成し、変更しています。ストレージ層は、それらが絶えずエクスポート、コピー、再インポートするのではなく、単一の信頼できる情報源を中心に協調できるようにするべきです。
それを可能にするのが Manifest のバージョンです。これにより、オンラインサービング、オフライン分析、バックフィルジョブ、コンパクションが、データセットの共有ビューを持てるようになります。
これらは内部ストレージの詳細のように聞こえるかもしれませんが、チームが AI データセットをどれだけ迅速に反復できるかに影響します。すべてのモデル変更、特徴量バックフィル、キャプション修正、品質フィルター、インデックス再構築は、同じ問いに依存しています。「システムは、移動する必要のないデータを移動せずにデータセットを更新できるか? "
それが、このストレージモデルの実用的な価値です。
Loon は Milvus 3.0 beta と Zilliz Vector Lakebase で利用可能です
Loon は Milvus 3.0 beta で利用可能であり、Zilliz Cloud の次の進化形である Zilliz Vector Lakebase のストレージ層の一部でもあります。そしてこのリリースは、3 つの中核領域に焦点を当てています。
- Manifest。 目標は、書き込み、バックフィル、削除、統計、インデックス更新が、リーダーが一貫して開けるバージョン管理されたデータセットビューを生成できるようにすることです。リーダーにとって、これはクエリが特定の Manifest バージョンを開き、データセットの安定したビューを確認できることを意味します。ライターにとって、これは新しいデータファイル、削除ログ、統計、またはインデックスファイルを先に準備し、その後バージョン管理されたコミットを通じて可視化できることを意味します。
- ColumnGroup とフォーマットサポート。 Parquet はスカラー列とエコシステムに適した列をサポートします。Vortex はベクトル中心のアクセスパターンをサポートします。Lance は既存の Lance データセットとの互換性のために読み取り専用モードで統合できます。
- Index on Lake。 スカラー統計、フィルタリングインデックス、テキスト転置インデックスは、行範囲ごとの Manifest ベースのプランニングに参加できます。レイクネイティブなベクトルインデックスはより複雑です。HNSW と IVF はオブジェクトストレージ上で異なる挙動を示し、特に HNSW はランダムアクセスとキャッシュ局所性に敏感です。ローカル SSD 向けに設計されたレイアウトを単純に再利用して、同じ結果を期待することはできません。
まだ取り組むべき作業があります
- 外部書き込みパス が重要なのは、Spark と Ray がすべてのバックフィルをクライアント SDK ループに通すことを強制されることなく、ColumnGroups と Manifest コミットを生成できるべきだからです。
- レイクハウスの相互運用性 が重要なのは、多くのチームがすでに Iceberg、Delta Lake、Trino、DuckDB、Athena などのカタログやクエリエンジンを使用しているからです。ベクトルデータは、ベクトル検索性能を失うことなく、そのエコシステムに参加できるべきです。
- インデックスレイアウト が重要なのは、グラフインデックスと転置構造がオブジェクトストレージ上で異なるアクセスパターンを持つからです。
- 大容量オブジェクトのセマンティクス が重要なのは、生の動画、PDF、画像、音声ファイルには、派生したベクトルデータセットと整合する参照管理、バージョニング、削除動作が必要だからです。
正確なリリース時の挙動、デフォルト設定、移行パスについては、関連する Milvus および Zilliz Cloud release notes に従う必要があります。ただし、ストレージの方向性は明確です。ベクトルデータベースには、サービング層の下に、バージョン管理されたレイクネイティブな基盤が必要です。
Zilliz Vector Lakebase で Loon を試す
現在のスタックで、オンラインサービング、オフライン分析、バックフィル、外部データレイクワークフローが異なるシステムに分かれている場合、Zilliz Vector Lakebase は検討する価値があります。Zilliz Cloud で試すことができます。新しい仕事用メールでサインアップすると、$100 の無料クレジットを獲得できます。ユースケースについて お問い合わせ いただくこともできます。
また、Milvus 3.0 release をフォローして、Loon がオープンソースエンジンでどのように進化していくかを確認することもできます。
Zilliz Vector Lakebase が統合するもの:
- さまざまなリアルタイム性能とコストのトレードオフに対応する階層型サービング
- 常時稼働のコンピュートなしで、大規模または探索的なワークロードに対応するオンデマンド検索
- 外部データレイク検索により、既存のレイクデータを直接インデックス化して検索可能
- ベクトル、テキスト、JSON、地理空間データにわたるフルスペクトラム検索(ハイブリッド検索とリランキング対応)
- Vortex 上に構築された統合型レイクネイティブストレージ。Vortex は、ベクトル中心のデータに対するより高速で低コストなランダム読み取りを目的に設計されたオープンフォーマット
読み続けて

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.