




AWSの障害は、ベクトルデータベースのクロスリージョン災害復旧に対する警鐘だった
クラウドリージョンは障害を起こします。それは「起こるかどうか」の問題ではなく、「いつ、どれほど深刻に起こるか」の問題です。
先週、中東の2つのAWSリージョンが、データセンターインフラへの物理的損傷によりオフラインになりました。AWSのUAEリージョン(ME-CENTRAL-1)にある3つのアベイラビリティゾーンのうち2つが停止し、バーレーン(ME-SOUTH-1)の施設も損傷しました。Lambda、EKS、VPC、S3、CloudWatchを含む60以上のAWSサービスが影響を受けました。同地域最大の配車プラットフォームであるCareemはサービスを失いました。大手決済プロバイダーのAlaanは停止しました。AWSは顧客に対し、ワークロードを他のリージョンへ移行するよう助言しましたが、これは再起動して復旧できるようなインシデントではありませんでした。ハードウェアの交換と施設の修復を伴うため、復旧には数週間かかる可能性があります。
そして物理的損傷は、障害モードの1つにすぎません。 過去12か月の間に、設定変更の不備によりAzureのCentral USリージョンが14.5時間停止しました。Google Cloudのバグにより、Cloud Run、GKE、Firebaseが同時に8時間停止しました。CrowdStrikeのソフトウェア更新の不備――クラウドプロバイダーの問題ですらないもの――がAzure上でホストされたインフラ全体に波及し、Fortune 500企業に推定54億ドルの損失をもたらしました。
Uptime Instituteの2025年レポートでは、影響の大きい停止のコスト中央値は1時間あたり200万ドルとされており、3年前のおよそ2倍です。それにもかかわらず、Veeamの2024 Data Protection Trends Reportによると、実際の災害時に復旧をオーケストレーションできる組織はわずか13%にすぎません。
これらの数字はすでに警戒すべきものでした。そこへAIがリスクをさらに引き上げました。
AIが停止すると、チームは減速するのではなく、止まる
5年前、リージョン単位のクラウド障害が主に痛手となるのは、顧客向けアプリでした。苦痛ではあっても、ほとんどのチームは社内では機能し続けることができました。今日では、AIは部門全体にまたがる業務――コードレビュー、ドキュメント作成、サポートのトリアージ、さらには定型的な分析まで――を取り込んでいます。従業員のほぼ60%が日常業務でAIを使用している中、停止は緩やかな減速を引き起こすのではありません。生産性は崖から落ちるように急落します。
これはすでに現実に起きています――ChatGPTとClaudeはいずれも2026年初頭に大規模な障害に見舞われ、何百万人ものユーザーと企業チームが、自分たちのワークフローの中心に据えていたAIツールを使えなくなりました。
しかし、多くのチームが見落としている点があります。モデルの停止は混乱を招きますが、モデルは大部分がステートレスです。プロバイダーは多くの場合、推論トラフィックを健全なリージョンへ比較的迅速に迂回できます。より難しい問題は、その下にあるデータレイヤー――メモリとコンテキストを供給するデータベース、オブジェクトストア、ベクトルインデックスです。そのレイヤーはステートフルで、リージョンに縛られており、復旧がはるかに困難です。それが停止すると、LLMは依然としてテキストを生成できるかもしれませんが、適切なコンテキストがなければ、汎用的でハルシネーションを起こしやすい出力に戻ってしまいます。AIは単にオフラインになるのではありません。信頼できなくなるのです。
ベクトルデータベースはAIの長期記憶であり、おそらく単一リージョンです
ベクトルデータベースは、エンタープライズAIの基盤となっています。RAGパイプラインやAIエージェントは、そこからコンテキストを取得します。レコメンデーションエンジンはそれらにクエリを投げます。セマンティック検索はそれらに対して実行されます。このレイヤーが利用できなくなると、その上に構築されたすべてのアプリケーションが壊れます――部分的にではなく、完全にです。
そしてステートレスサービスとは異なり、復旧は単純ではありません。
- インデックスの再構築は遅い。 ベクトル検索はHNSWグラフのようなインデックス構造に依存しており、再構築時間はデータセットサイズに対して非線形に増加します。1億以上のベクトルに対するインデックス再構築には、標準的なコンピュートで18時間以上かかることがあります。
- 接続文字列は至るところにある。 古いクラスターに接続していたすべてのアプリケーションは、エンドポイントを更新する必要があります――設定、環境変数、CI/CDパイプラインにまたがり、多くの場合、異なるチームによって管理されています。
- 埋め込みモデルのドリフト。 現在のベクトルを生成した正確な埋め込みモデルのバージョンを特定できない場合、データセット全体を再埋め込みする必要があるかもしれません。
ソフトウェア障害の場合は、再起動を待ちます。しかし、データセンターが物理的に損傷した場合、復旧には数週間かかります。唯一実行可能な戦略は、別リージョンから提供される、ライブでインデックス済みかつクエリ可能なレプリカをすでに用意しておくことです。そして、コード変更を一切必要としないトラフィックの再ルーティングが必要です。
Zilliz Cloud: ネイティブなクロスリージョン災害復旧を備えた世界初のベクトルデータベース
Zilliz Cloud は、ネイティブなクロスリージョン災害復旧を提供する世界初のベクトルデータベースです。自動フェイルオーバー、リアルタイムレプリケーション、そしてリージョン切り替え時にアプリケーション変更を一切必要としないグローバルエンドポイントを備えています。
私たちは、リアルタイムフェイルオーバーのための Global Cluster と、費用対効果の高い災害復旧のための Cross-Region Backup という、相互補完的な2つの機能を提供しています。
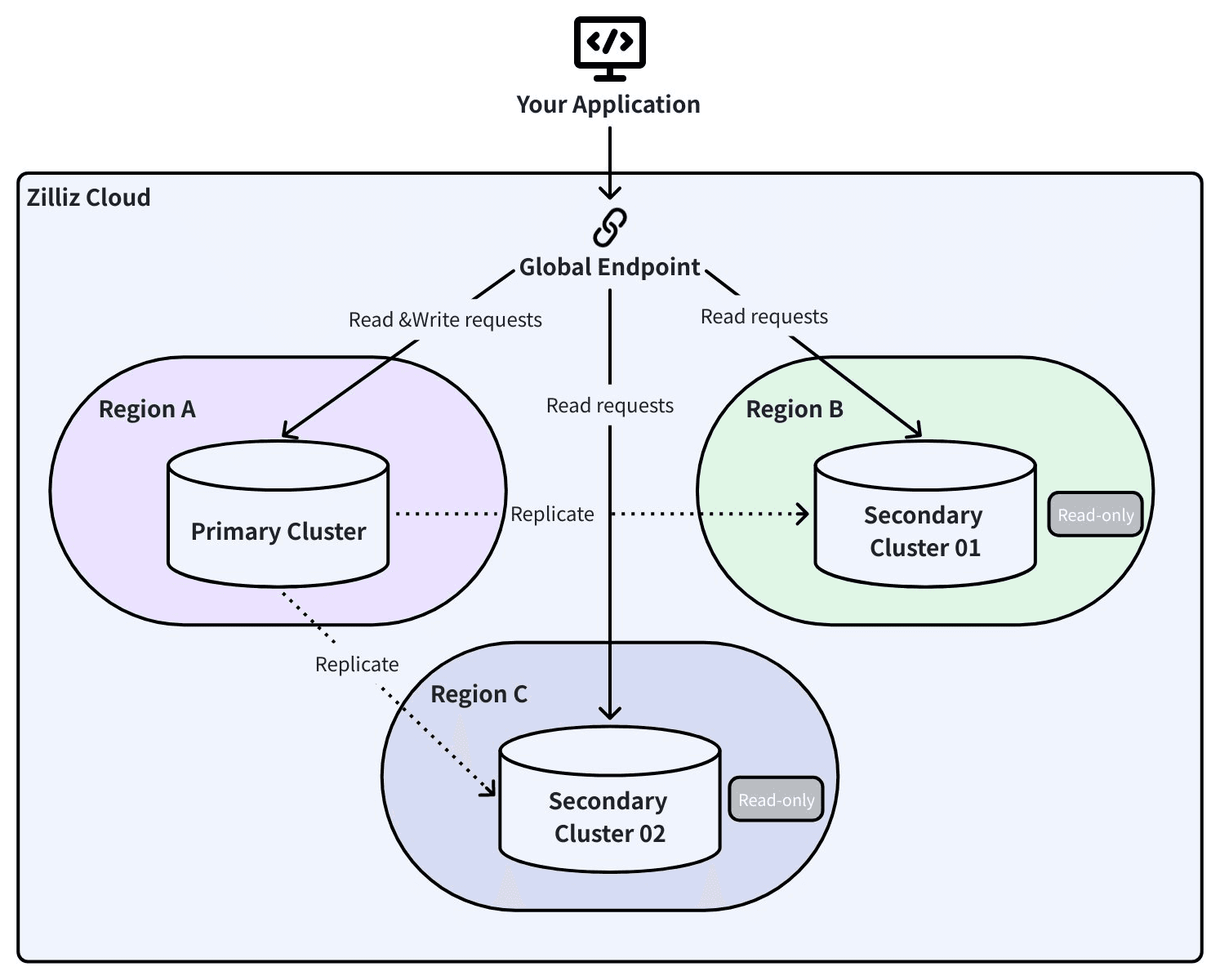
Global Cluster: 自動フェイルオーバーを備えたライブレプリケーション
Global Cluster は Change Data Capture (CDC) を使用して、プライマリクラスタと別リージョンのセカンダリクラスタ間でデータを継続的にレプリケートします。定期的なスナップショットではありません。すべての挿入、更新、削除がリアルタイムで伝播されます。
- 計画的スイッチオーバー(メンテナンス、移行、コンプライアンス): システムは処理中の CDC メッセージを排出し、完全同期を確認してからロールを入れ替えます。RPO はゼロです。RTO は30秒未満です。
- 自動フェイルオーバー(予期しないリージョン障害): セカンダリが自動的に自身を昇格させます。RPO は障害発生時点の CDC ラグに等しく、通常は数秒です。RTO は60秒未満です。
ユニークな機能の1つとして、フェイルオーバー後、旧プライマリは単に消えるわけではありません。7日間保持されるごみ箱に移動され、DumpMessages というストリーミング API によって、旧プライマリに書き込まれたものの、まだレプリケートされていなかった書き込みを取り出すことができます。データ損失を受け入れる代わりに、それを復旧するための猶予期間が得られます。
Global Endpoint: 1つの接続ですべてのリージョンへ
物理的な災害シナリオでアーキテクチャが効果を発揮するのはここです。
アプリケーションは単一のグローバルエンドポイントに接続します。その背後では、SRV DNS レコードがどのクラスタがプライマリで、どのクラスタがセカンダリであるかを追跡します。フェイルオーバーが発生すると、SDK がトポロジー変更を検出し、トラフィックを自動的に再ルーティングします。接続文字列の更新は不要です。アプリケーションの再起動も不要です。コード変更も不要です。
これが長期的なリージョン障害の際に何を意味するかを考えてみてください。グローバルエンドポイントがなければ、復旧には誰かがランブックを探し、クライアントを手動で再設定し、接続文字列を更新し、チーム間で調整する必要があります。午前3時に、プレッシャーの中でです。RTO は秒単位では測れません。適切なエンジニアに連絡がつくまでにかかる時間で測られます。
Global Endpoint を使えば、コードを1行も変更することなく、RAG パイプラインは60秒以内に別リージョンのレプリカへクエリを実行します。
Cross-Region Backup: ライブレプリカのコストなしで実現するレジリエンス
すべてのワークロードがセカンダリクラスタの運用を正当化するわけではありません。Cross-Region Backup は、バックアップデータを1つ以上のターゲットリージョンにレプリケートし、それぞれが独自の保持ポリシーを持ちます。リージョンレベルの障害が発生した場合、ターゲットリージョン内の任意のバックアップポイントから新しいクラスタを起動できます。データはすでにそこにあるため、危機の最中にクロスリージョンのデータ転送は不要です。
トレードオフ:
- Global Cluster → RPO は秒単位、RTO は60秒未満。ダウンタイムを一切許容できないワークロード向け。
- Cross-Region Backup → RPO と RTO は時間単位。即時復旧よりもデータの生存が重要なワークロード向け。
多くのチームは、まず Cross-Region Backup から始めます。これは、データがリージョン障害を生き延びるという重要な保証を得るためです。そして AI ワークロードがミッションクリティカルになるにつれて、Global Cluster にアップグレードします。
他のベクトルデータベースはクロスリージョン DR にどう対応しているか
ほとんどのベクトルデータベースは、レプリカセットとノード冗長化によって単一リージョン内の高可用性を提供しています。これはノード障害には対応しますが、リージョン障害には対応しません。Zilliz Cloud は、グローバルクラスターとグローバルエンドポイントによるネイティブな自動クロスリージョンフェイルオーバーを提供する唯一のベクトルデータベースです。ダウンタイムなし、コード変更なしでリージョン移行を実現します。
| 機能 | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| クロスリージョンレプリケーション | ✅ CDC ベース、リアルタイム | ❌ | ❌ | ❌ | ❌ |
| 計画外フェイルオーバー | ✅ RPO ≈ 秒単位、RTO<= 30s | ❌ | ❌ | ❌ | ❌ |
| 計画的スイッチオーバー | ✅ RPO=0、RTO=0 | ❌ | ❌ | ❌ | ❌ |
| フェイルオーバー後のデータサルベージ | ✅ 未同期のデータを自動的にサルベージ。 | ❌ | ❌ | ❌ | ❌ |
| グローバルエンドポイント | ✅ 1 つのグローバルエンドポイント、コード変更なしで自動再ルーティング | ❌ | ❌ | ❌ | ❌ |
| リージョン障害 RPO/RTO | ✅ RPO ≈ 秒単位、RTO < 30s | ❌ | ❌ | ❌ | ❌ |
| 自動クロスリージョンバックアップ | ✅ リージョンごとの保持期間を持つ任意のリージョン | ❌ | ❌ | ❌ | ❌ |
災害復旧を超えて
チームはまた、障害とは関係のない運用シナリオでも Global Cluster を利用しています。
- レイテンシ最適化: ユーザーにより近いセカンダリリージョンを追加し、100ms 未満のクエリ応答時間を実現します。
- リージョン移行: インフラ統合時にダウンタイムなしでワークロードをリージョン間で移動します。
- データレジデンシー準拠: 規制要件を満たすため、データを特定の地理的境界内に保持します。
障害から保護する同じ CDC パイプラインは、ユーザーにより近い読み取り可能なレプリカも提供します。つまり、パフォーマンス最適化の副次的効果として DR 機能が得られます。
はじめに
Global Cluster と Cross-Region Backup は、Zilliz Cloud の専用クラスターで利用できます。
- すでに Zilliz Cloud アカウントをお持ちの場合は、サインイン するだけで、新機能をすぐに利用開始できます。アップグレードや移行は不要です。
- Zilliz Cloud は初めてですか? 無料でサインアップ して、世界をリードするマネージドベクトルデータベースを体験できる \$100 分のクレジットを入手してください。
- いずれかのアップデートについて質問がありますか?最新の ドキュメント を確認するか、Zilliz Support までお問い合わせください。私たちがお手伝いします。
制限なく構築する: Zilliz Cloud のエンタープライズ対応機能を詳しく見る
Global Cluster は、本番規模の AI のために構築された、より広範なプラットフォームの一部です。Zilliz Cloud はさらに以下も提供します。
- 弾力的なスケーリングとコスト効率 – ワンクリックデプロイ、サーバーレスオートスケーリング、従量課金制。
- 高度な AI 検索 – メタデータフィルタリング、動的スキーマ、マルチテナンシーを備えたベクトル、全文、ハイブリッド(スパース + デンス)検索。
- エンタープライズグレードのセキュリティ – 99.95% SLA、SOC 2 Type II および ISO 27001 認証、GDPR 準拠、HIPAA 対応、RBAC、BYOC、監査ログ。詳細は当社の trust center をご覧ください。
- グローバルな可用性 – AWS、GCP、Azure 全体へのデプロイにより、世界中で 100ms 未満のレイテンシを実現。
- シームレスな移行 – Pinecone、Qdrant、Elasticsearch、PostgreSQL、OpenSearch、Weaviate、またはオンプレミスの Milvus から移行するための組み込みツール。
- 自然言語クエリ – 複雑な API なしで直感的なクエリを可能にする MCP server サポート。
- さらに他にも多数!

読み続けて

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.