




Milvusのクエリータスクのスケジュール方法
本稿では、Milvusがどのようにクエリタスクをスケジューリングするかについて述べる。また、Milvusスケジューリング実装の問題点、解決策、将来の方向性についても述べます。
背景
大規模ベクトル検索エンジンにおけるデータ管理から、ベクトル類似性検索は高次元空間における2つのベクトル間の距離によって実装されることが分かっている。ベクトル検索の目的は、ターゲットベクトルに最も近いK個のベクトルを見つけることである。
ユークリッド距離のように、ベクトル距離を測定する方法はたくさんあります:
ユークリッド距離](https://assets.zilliz.com/1_euclidean_distance_156037c939.png)
ここで x と y は2つのベクトルであり、n はベクトルの次元である。
データセットからK個の最近接ベクトルを見つけるには、検索対象のベクトルとデータセット内のすべてのベクトルとのユークリッド距離を計算する必要がある。そして、K個の最近接ベクトルを求めるために、ベクトルを距離でソートする。計算量はデータセットのサイズに比例する。データセットが大きければ大きいほど、クエリに必要な計算量は多くなる。グラフ処理に特化したGPUは、必要な計算能力を提供するために多くのコアを持っている。そのため、Milvusの実装ではマルチGPUのサポートも考慮されている。
基本コンセプト
データブロック(TableFile)
大規模データ検索への対応を強化するため、Milvusのデータ格納を最適化した。Milvusはテーブル内のデータをサイズごとに複数のデータブロックに分割する。ベクトル検索では、各データブロック内のベクトルを検索し、その結果をマージする。1回のベクトル検索操作は、N個の独立したベクトル検索操作(Nはデータブロック数)とN-1個の結果のマージ操作から構成される。
タスクキュー(TaskTable)
各Resourceは、そのResourceに属するタスクを記録するタスク配列を持っています。各タスクは、Start、Loading、Loaded、Executing、Executed などの状態を持っています。コンピューティングデバイスのローダとエクゼキュータは、同じタスクキューを共有します。
クエリー・スケジューリング
クエリー・スケジューリング](https://assets.zilliz.com/2_query_scheduling_5798178be2.png)
1.Milvusサーバが起動すると、Milvusはserver_config.yaml設定ファイルのgpu_resource_configパラメータを介して対応するGpuResourceを起動します。DiskResourceとCpuResourceはまだserver_config.yamlでは編集できません。GpuResourceはsearch_resourcesとbuild_index_resourcesの組み合わせで、以下の例では{gpu0, gpu1}と呼ばれています:
サンプルコード](https://assets.zilliz.com/3_sample_code_ffee1c290f.png)
例](https://assets.zilliz.com/3_example_0eeb85da71.png)
2.Milvusはリクエストを受け取る。テーブルメタデータは外部データベースに格納され、シングルホストの場合はSQLiteまたはMySQl、分散ホストの場合はMySQLが使用される。検索要求を受け取ると、Milvusはテーブルが存在し、ディメンションが整合しているかどうかを検証する。その後、MilvusはテーブルのTableFileリストを読み込みます。
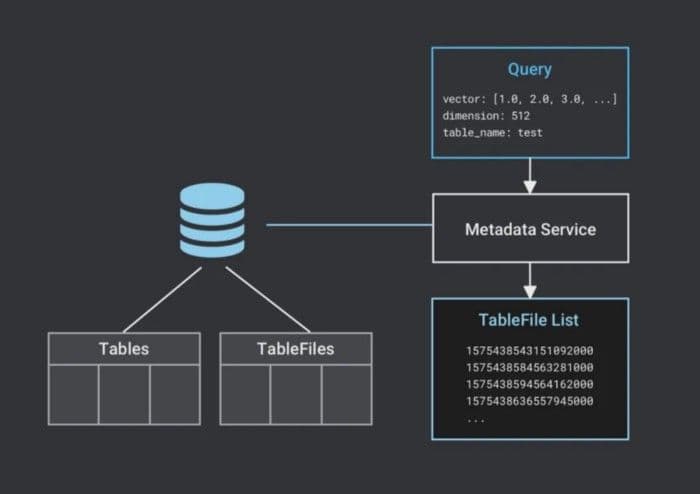 Milvusがテーブルファイルリストを読み込む
Milvusがテーブルファイルリストを読み込む
3.MilvusはSearchTaskを作成します。各 TableFile の計算は独立して行われるため、Milvus は各 TableFile に対して SearchTask を作成します。タスクスケジューリングの基本単位であるSearchTaskには、ターゲットベクトル、検索パラメータ、TableFileのファイル名が含まれる。
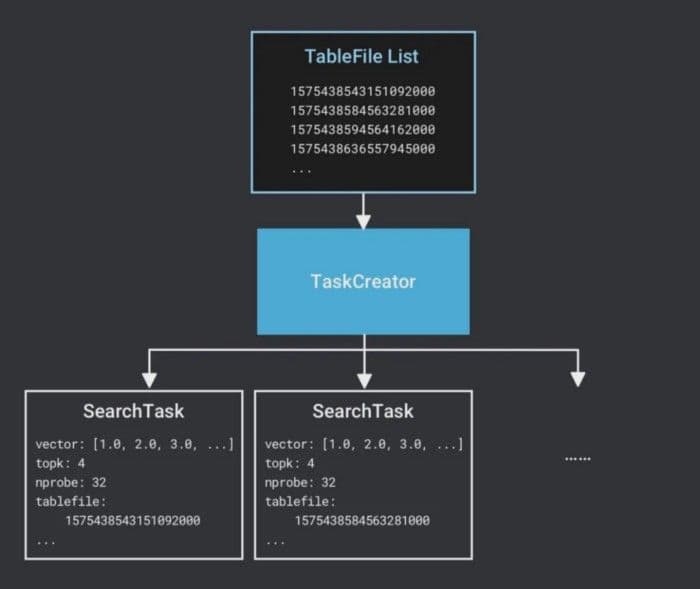 テーブルファイル一覧タスク作成
テーブルファイル一覧タスク作成
4.Milvusは計算装置を選択する。SearchTaskが計算を行うデバイスは、各デバイスの推定完了時間に依存する。推定完了**時間は、現在時刻から計算が完了する推定時刻までの推定間隔を指定する。
たとえば、SearchTaskのデータ・ブロックがCPUメモリにロードされたとき、CPUの計算タスク・キューでは次のSearchTaskが待機しており、GPUの計算タスク・キューはアイドル状態です。CPUの推定完了時間は、前のSearchTaskと現在のSearchTaskの推定時間コストの合計に等しい。GPUの推定完了時間は、データ・ブロックがGPUにロードされる時間と現在のSearchTaskの推定時間コストの合計に等しい。リソース内のSearchTaskの推定完了時間は、リソース内のすべてのSearchTaskの平均実行時間に等しくなります。そして、Milvusは最も推定完了時間の短いデバイスを選択し、そのデバイスにSearchTaskを割り当てます。
ここでは、GPU1の推定完了時間が短いと仮定します。
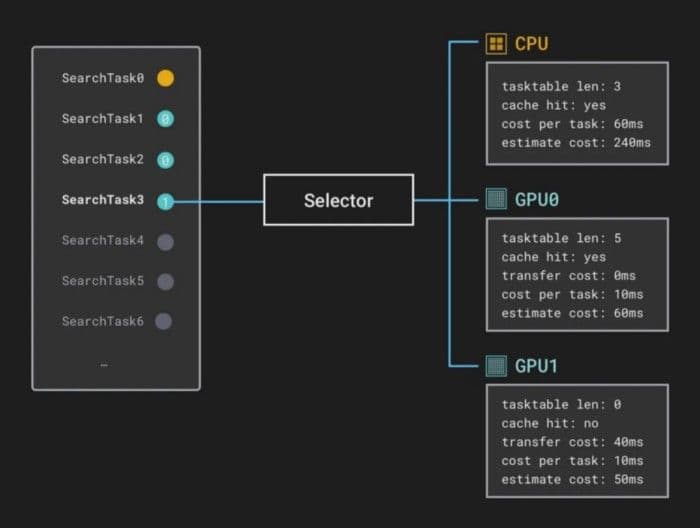 GPU1の方が推定完了時間が短い
GPU1の方が推定完了時間が短い
5.MilvusはSearchTaskをDiskResourceのタスクキューに追加する。
6.MilvusはSearchTaskをCpuResourceのタスクキューに移動する。CpuResourceのロードスレッドがタスクキューから各タスクを順次ロードする。CpuResourceが対応するデータブロックをCPUメモリに読み込む。
7.MilvusはSearchTaskをGpuResourceに移動する。GpuResourceのロードスレッドがデータをCPUメモリからGPUメモリにコピーする。GpuResourceが対応するデータブロックをGPUメモリに読み込む。
8.Milvus は GpuResource 内で SearchTask を実行します。SearchTaskの結果は比較的小さいので、結果は直接CPUメモリに返されます。
スケジューラ](https://assets.zilliz.com/7_scheduler_53f1fbbaba.png)
9.MilvusはSearchTaskの結果を検索結果全体にマージする。
Milvusは検索タスクの結果をマージする](https://assets.zilliz.com/8_milvus_merges_searchtast_result_9f3446e65a.png)
すべてのSearchTaskが終了すると、Milvusは検索結果全体をクライアントに返します。
インデックス作成
インデックス構築は基本的にマージ処理を除いた検索処理と同じです。詳細な説明は省略します。
パフォーマンスの最適化
キャッシュ
前述のように、データブロックは計算前にCPUメモリやGPUメモリなどの対応するストレージデバイスにロードする必要があります。データの繰り返しロードを避けるため、MilvusはLRU(Least Recently Used)キャッシュを導入しています。キャッシュがいっぱいになると、新しいデータ・ブロックが古いデータ・ブロックを押しのけます。キャッシュのサイズは、現在のメモリサイズに基づいて設定ファイルによってカスタマイズすることができます。データのロード時間を効果的に節約し、検索パフォーマンスを向上させるには、検索データを保存するための大きなキャッシュを推奨します。
データの読み込みと計算の重複
キャッシュは、検索パフォーマンスを向上させるためのニーズを満たすことはできない。メモリが不足したり、データセットのサイズが大きすぎたりすると、データを再ロードする必要がある。データロードが検索性能に与える影響を減らす必要がある。ディスクからCPUメモリへ、あるいはCPUメモリからGPUメモリへのデータロードは、IOオペレーションに属し、プロセッサによる計算作業はほとんど必要ありません。そこで、データのロードと計算を並列に実行することで、リソースをより有効に利用することを考えます。
データブロックの計算を3ステージ(ディスクからCPUメモリへのロード、CPU計算、結果マージ)または4ステージ(ディスクからCPUメモリへのロード、CPUメモリからGPUメモリへのロード、GPU計算と結果検索、結果マージ)に分割します。3ステージの計算を例にとると、3つのステージを担当する3つのスレッドを起動し、命令パイプラインとして機能させることができます。結果セットはほとんど小さいので、結果のマージにはそれほど時間がかからない。場合によっては、データロードと計算のオーバーラップにより、検索時間を1/2に短縮できる。
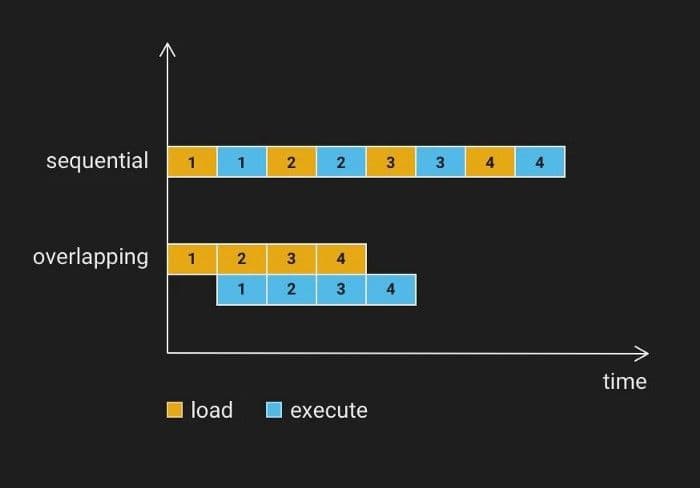 シーケンシャル・オーバーラッピング・ロード・ミルバス
シーケンシャル・オーバーラッピング・ロード・ミルバス
問題点と解決策
伝送速度の違い
以前、MilvusはマルチGPUタスクのスケジューリングにラウンドロビン戦略を使用していました。この戦略は4GPUサーバでは完璧に機能し、検索性能は4倍向上した。しかし、2GPUのホストでは2倍の性能向上には至りませんでした。私たちはいくつかの実験を行い、あるGPUのデータコピー速度が11GB/秒であることを発見しました。しかし、別のGPUでは3GB/秒でした。メインボードのドキュメントを参照した結果、メインボードがPCIe x16経由で1つのGPUに、PCIe x4経由でもう1つのGPUに接続されていることを確認した。つまり、これらのGPUはコピー速度が異なる。その後、コピー時間を加えて、各SearchTaskに最適なデバイスを測定した。
今後の課題
複雑化するハードウェア環境
実際の環境では、ハードウェア環境はより複雑になる可能性があります。複数の CPU、NUMA アーキテクチャーを持つメモリ、NVLink、NVSwitch などのハードウェア環境では、CPU/GPU をまたいだ通信が最適化の機会を多くもたらします。
クエリの最適化
実験中に、パフォーマンス向上の機会をいくつか発見しました。例えば、サーバーが同じテーブルに対する複数のクエリを受信した場合、条件によってはクエリをマージすることができます。データの局所性を利用することで、パフォーマンスを向上させることができます。これらの最適化は今後の開発で実装される予定です。 シングルホスト、マルチGPUのシナリオで、クエリがどのようにスケジューリングされ、実行されるかはすでに分かっている。次回以降もMilvusの内部メカニズムを紹介していく予定である。
読み続けて

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

Top 5 AI Search Engines to Know in 2025
Discover the top AI-powered search engines of 2025, including OpenAI, Google AI, Bing, Perplexity, and Arc Search. Compare features, strengths, and limitations.