非構造化データ入門

はじめに
これは「ベクトルデータベース101」コースの最初のチュートリアルで、主にテキストの形で非構造化データに関する概要について記述します。大変面白い話題には見えませんが、このサイトを閉じる前に、ちょっとだけ聞いていただけるなら、幸せの極みです。 新しいデータは日々生成されており、世界中の統合やグローバル経済に対しても重要な推進力です。たとえば心拍数モニター、車両のGPS位置、ソーシャルメディアへの動画投稿などが、膨大な規模で増え続けるデータの例です。この増加するデータの重要性は言うまでもありません。データは既存の顧客により良いサービスを提供し、サプライチェーンの弱点を特定し、労働力の非効率さを明らかにし、新しい市場に参入するための手がかりを提供するなど、企業(そしてあなた)が収益を増やすための手助けとなりえます。 まだ納得できませんか?国際データコーポレーション(IDC)は、2028年までに世界中のデータ量(新しく作成・保存されるデータの総量)が400ゼタバイト(ゼタバイト = 10²¹バイト)に成長すると予測しています。そのうち30%以上はリアルタイムで生成され、生成データ全体の80%は非構造データとなる見込みです。
構造化データ・半構造データ・非構造データの定義
それでは非構造データとは具体的に何でしょうか?その名の通り、非構造データとは既定の形式に保存することができない、あるいは既存のデータモデルに当てはまらないデータを指します。画像や動画、音声、テキストファイルなどの人間が生成したデータが、非構造データの良い例です。また、タンパク質の構造や実行ファイルのハッシュ、さらには人に読めるコードなど、非構造データの多種多様な例に含まれます。 一方、構造化データは、テーブルベースの形式で保存できるデータを指し、半構造データはシングルもしくはマルチレベルの配列やキーバリューストアで保存できるデータです。これがまだピンとこなくとも、心配しなくても大丈夫です。少しお付き合いいただければ、構造化データと非構造データの主な違いを明確にするために、いくつかの例をご紹介します。
構造化データの具体例
もっと勉強したいですか?素晴らしいです。まず構造化データと半構造データについて簡単に説明します。簡単に言えば、伝統的な構造化データは関係モデルを通じて保存されます。例えば、書籍データベースの場合は以下のようになります。
| ISBN | Year | Name | Author |
|---|---|---|---|
| 0767908171 | 2003 | A Short History of Nearly Everything | Bill Bryson |
| 039516611X | 1962 | Silent Spring | Rachel Carson |
| 0374332657 | 1998 | Holes | Louis Sachar |
| ... |
この例では、データベース内の各行が特定の本(ISBN番号で識別)を表し、各列は対応する情報のカテゴリーを示しています。関係モデルに基づいたデータベースでは、複数のテーブルを形成することができ、それぞれ独自の列のセットを持ちます。これらのテーブルは正式には「関係」として知られていますが、友達や家族との関係と混同しないように、ここでは敢えて「テーブル」と呼びます。関係データベースの代表的な例としては、MySQL(1995年リリース)やPostgreSQL(1996年リリース)があります。
半構造データの例
半構造データは、伝統的なテーブルベースのモデルに適合しない構造データのサブセットです。代わりに、データを説明したりインデックス化したりするためのキーやマーカーが付いています。書籍データベースの例を、次のように半構造のJSON形式に展開してみましょう。
{ ISBN: 0767908171 Month: February Year: 2003 Name: A Short History of Nearly Everything Author: Bill Bryson Tags: geology, biology, physics }, { ISBN: 039516611X Name: Silent Spring Author: Rachel Carson }, { ISBN: 0374332657 Year: 1998 Name: Holes Author: Louis Sachar }, ...
ここではご注意ください。この新しいJSONデータベースの最初の要素には、Months とtag という2つの追加情報が含まれていますが、後続の要素には影響を与えません。半構造データでは、すべての要素に追加の列を設定する手間を省き、柔軟性が高まります。
半構造データは通常、NoSQLデータベース(ワイドカラムストア、オブジェクト/ドキュメントデータベース、キー・バリューストアなど)に保存されます。これは、従来の関係データベースでは直接使用できない非表形式を持っているからです。現在、Cassandra(2008年リリース)、MongoDB(2009年リリース)、Redis(2009年リリース)は、半構造データ用の人気のデータベースとして知られています。興味深いことに、これらの半構造データ用データベースは、構造データ用のデータベースより約10年遅れて登場しています。この理由については後ほど詳しく説明します。
パラダイムシフト — 非構造データの定義
構造化データおよび半構造データの基本がわかったところで、非構造データについて話しましょう。非構造データは構造化データおよび半構造データと異なり、任意の形態を取ったり、ディスク上のサイズが非常に大きくても小さくても構わず、変換やインデックス化に必要なランタイムが非常に異なったりすることも存在します。たとえば、同じジャーマンシェパードの正面写真が3枚あったとして、これらはセマンティクス的には同じものです。 「セマンティクス的に同じ」とはどういう意味でしょうか?まずは、もう少し深掘りして「セマンティック類似性」という概念を説明します。これら3枚の写真は、ピクセル値や解像度、ファイルサイズが異なっているかもしれませんが、内容は同じジャーマンシェパードで、環境も同じです。したがって、画像の内容はほぼ同一であるにもかかわらず、ピクセルの値は大きく異なります。これにより、データを使用する企業や業界1は、非構造データをどのように、構造化データおよび半構造データのように変換、保存、検索するかという新たな課題に直面します。 この時点で、「非構造データには固定サイズやフォーマットがないのに、どのように検索や分析するのか?」と疑問に思っているかもしれません。答えは「機械学習(より具体的にはディープラーニング)」です。過去10年間で、ビッグデータとディープニューラルネットワークの組み合わせは、データ駆動型のアプリケーションに対処する方式を根本的に改変しました。スパムメール検出から迫真のテキスト動画生成まで、様々なタスクで精度が向上し、いくつかのタスクでは人間を超えるレベルに達しています。
1 本質的には、それはつまり全ての産業、全ての企業そして全ての個体。もちろん、あなたも。
非構造データの具体例
非構造データは機械や人間によって生成されます。以下はその例です。 機械生成の非構造データの例:
- センサーデータ:温度センサー、湿度センサー、GPSセンサー、モーションセンサーなどのせんさーから収集されたデータ。
- 機械ログデータ:システムログ、アプリケーションログ、イベントログなど、機械やデバイス、またはアプリケーションによって生成されるデータ。
- モノのインターネット(IoT)データ:スマートサーモスタット、スマートホームアシスタント、ウェアラブルデバイスなどのスマートデバイスから収集されるデータ。
- コンピュータビジョンデータ:画像認識、物体検出、動画解析など、コンピュータビジョン技術によって生成されるデータ。
- 自然言語処理(NLP)データ:音声認識、言語翻訳、感情分析などの自然言語処理(NLP)技術によって生成されるデータ。
- ウェブおよびアプリケーションデータ:ユーザー行動データ、エラーログ、アプリケーションパフォーマンスデータなど、ウェブサーバーやウェブアプリケーション、モバイルアプリケーションによって生成されるデータ。 人間生成の非構造データの例:
- メール:自由形式のテキスト、画像、添付ファイルなどを含み、通常は非構造化。
- テキストメッセージ:略語や絵文字を含む、非公式の非構造化データ。
- ソーシャルメディア投稿:テキスト、画像、動画、ハッシュタグなどを含み、構造と内容が多様。
- 音声録音:電話、ボイスメール、音声ファイル、音声メモなど、人間が生成する音声録音。
- 手書きメモ:図、ダイアグラムや他の要素などを含み、通常は非構造化。
- 会議メモ:非構造化のテキスト、ダイアグラム、アクションアイテムなどを含みます。
- トランスクリプト:正確度が異なる非構造化のテキストを含む、スピーチ、インタビュー、会議の書き起こしなど。
- ユーザー生成コンテンツ:自由形式のテキスト、画像、動画ファイルなどを含み、ウェブサイトやフォーラムでユーザーが生成した非構造化のコンテンツ。
埋め込み(embeddings)の基礎
さて、本題に戻りましょう。多くのニューラルネットワークモデルは、非構造化データを浮動小数点値のリスト、つまり「埋め込み」または「埋め込みベクトル」に変換することができます。ニューラルネットワークが適切に訓練されていれば、画像の意味内容を表す埋め込みを出力できます。2 将来のチュートリアルでは、埋め込みを生成するための既定のアルゴリズムを使用したベクトルデータベースのユースケースについて説明します。
 Eastern Towhee
Eastern Towhee
ワキアカトウヒチョウ 撮影者:Patrice Bouchard
上記の写真は、非構造化データをベクトルに変換する例です。ResNet-50という卓越した畳み込みニューラルネットワークを用いると、この画像を長さ2048のベクトルとして表現できます。ここに最初の3つの要素と最後の3つの要素があります: [0.1392, 0.3572, 0.1988, ..., 0.2888, 0.6611, 0.2909]。適切に訓練されたニューラルネットワークが生成する埋め込みには、検索と分析を容易にする数学的な特性があります。ここで詳細には触れませんが、一般的には、意味的に類似するオブジェクトの埋め込みは、「距離の面において互いに近い」です。したがって、非構造化データの検索と理解はベクトル演算に帰着します。
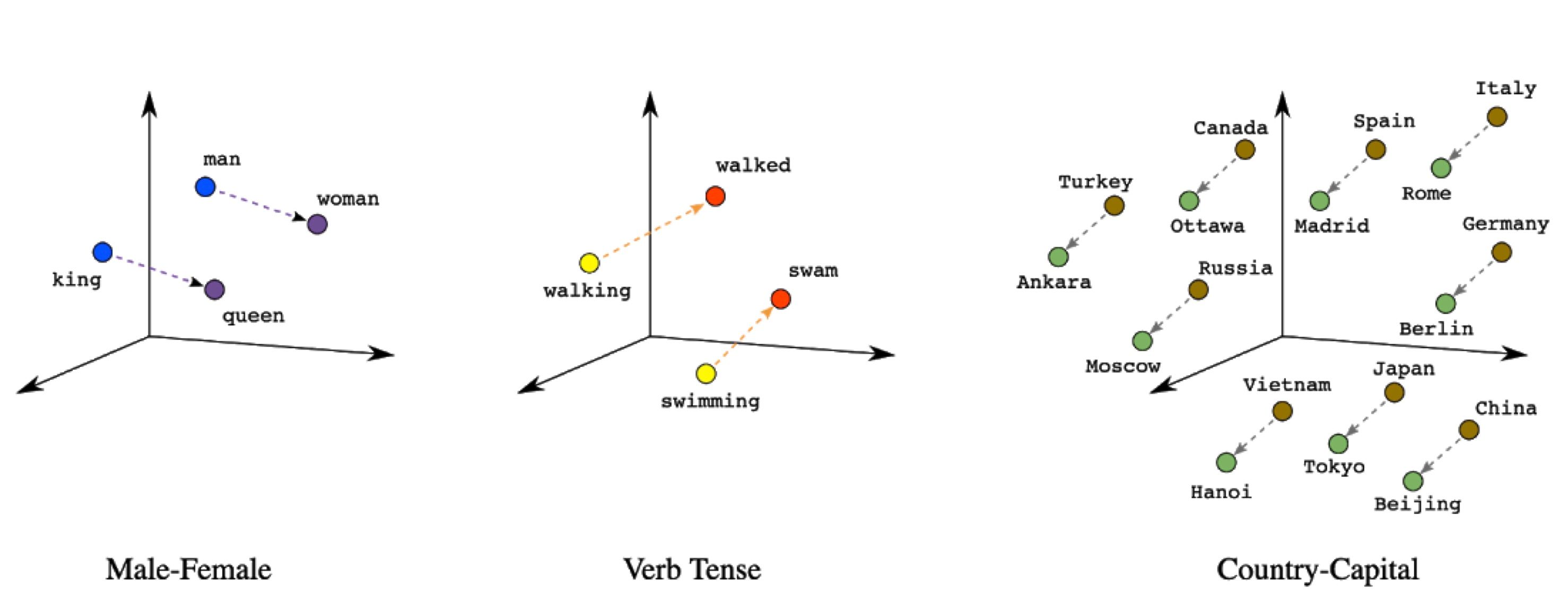 embedding arithmetic
embedding arithmetic
「はじめに」で述べたように、非構造データは2028年までに新たに生成されるデータの80%を占めるようになる見込みです。産業が成熟し、非構造化データ処理の方法が導入されるにつれ、この割合は80%を超え、増加し続けるでしょう。これは私たち全員、つまり私やあなた、私たちが働く会社やボランティアで関わる組織など全体に影響を与えます。2010年以降のユーザー向けアプリケーションにとって、従来の表形式データとは異なる半構造データを保存するデータベースが必要になってきたように、この10年では、膨大な量(エクサバイト)の非構造データをインデックス化して検索するためのデータベースが求められています。 その解決策は、AI時代のためのデータベース、つまりベクトルデータベースです。私たちの世界へようこそ。オープンソースのベクトルデータベースであるMilvusの世界へようこそ。 2 ほとんどのチュートリアルでは、ニューラルネットワークによって生成された埋め込みに焦点を当てますが、手作業で設計されたアルゴリズムによって埋め込みを生成することも可能ですのでご留意ください。
非構造データ処理
ワクワクしていますか?素晴らしいです。それではベクトルデータベースとMilvusについて詳しく掘り下げる前に、非構造化データを処理・分析する方法について少しお話ししましょう。構造化および半構造データの場合、データベース内の項目を検索またはフィルタリングすることは比較的簡単です。簡単な例として、特定の著者の最初の本をMongoDBで取得する場合、次のコードスニペットを使用できます(pymongoを使用)。
>>> document = collection.find_one({'Author': 'Bill Bryson'})
この種類のクエリ手法は、SQLステートメントを使用してデータをフィルタリングおよび取得する従来の関係データベースの方法と類似しています。その概念は同じです:構造化/半構造データ用のデータベースは、数値および/または文字列に対して数学的(例:<=、文字列距離)または論理(例:EQUALS、NOT)演算子を使用してフィルタリングとクエリを実行します。従来の関係データベースの場合、これは関係代数と呼ばれます。関係代数をよく知らない方にとっては、線形代数よりもずっと難しいと感じるかもしれません。関係代数を通じて、極めて複雑なフィルタが構築される例を見たことがあるかもしれませんが、基本的な概念は同じで、伝統的なデータベースは、特定のフィルタのセットに対して常に正確な一致を返す「決定論的」なシステムです。
構造化および半構造データ用のデータベースとは異なり、ベクトルデータベースのクエリは、SQLステートメントやデータフィルタ({'Author': 'Bill Bryson'}など)を指定する代わりに、入力クエリベクトルを指定することで行います。このベクトルは非構造化データの埋め込みベースの表現です。簡単な例として、Milvusでは次のスニペットで実行できます(pymilvusを使用)。
>>> results = collection.search(embedding, 'embedding', params, limit=10)
内部的には、大規模な非構造化データのコレクションに対するクエリは、「近似最近傍探索」(ANN)として知られる一連のアルゴリズムを使用して実行されます。簡単に言えば、ANN探索は、指定されたクエリベクトルに「最も近い」ポイントまたはポイントセットを見つけるために最適化された形態の一つです。「近似」という言葉に注意してください。巧妙なインデックス方法を利用することで、ベクトルデータベースは明確な精度/性能のトレードオフを持っています:検索時間を増やすと、決定論的なシステムに近いパフォーマンスを発揮し、クエリの値に対して常に絶対的な最も近い隣接点を返す一貫性のあるデータベースが得られます。逆に、クエリ時間を短縮するとスループットが向上しますが、クエリの真の最近値の一部を捉えなくなる可能性があります。この意味で、非構造データの処理は「確率論的」なプロセスです。3
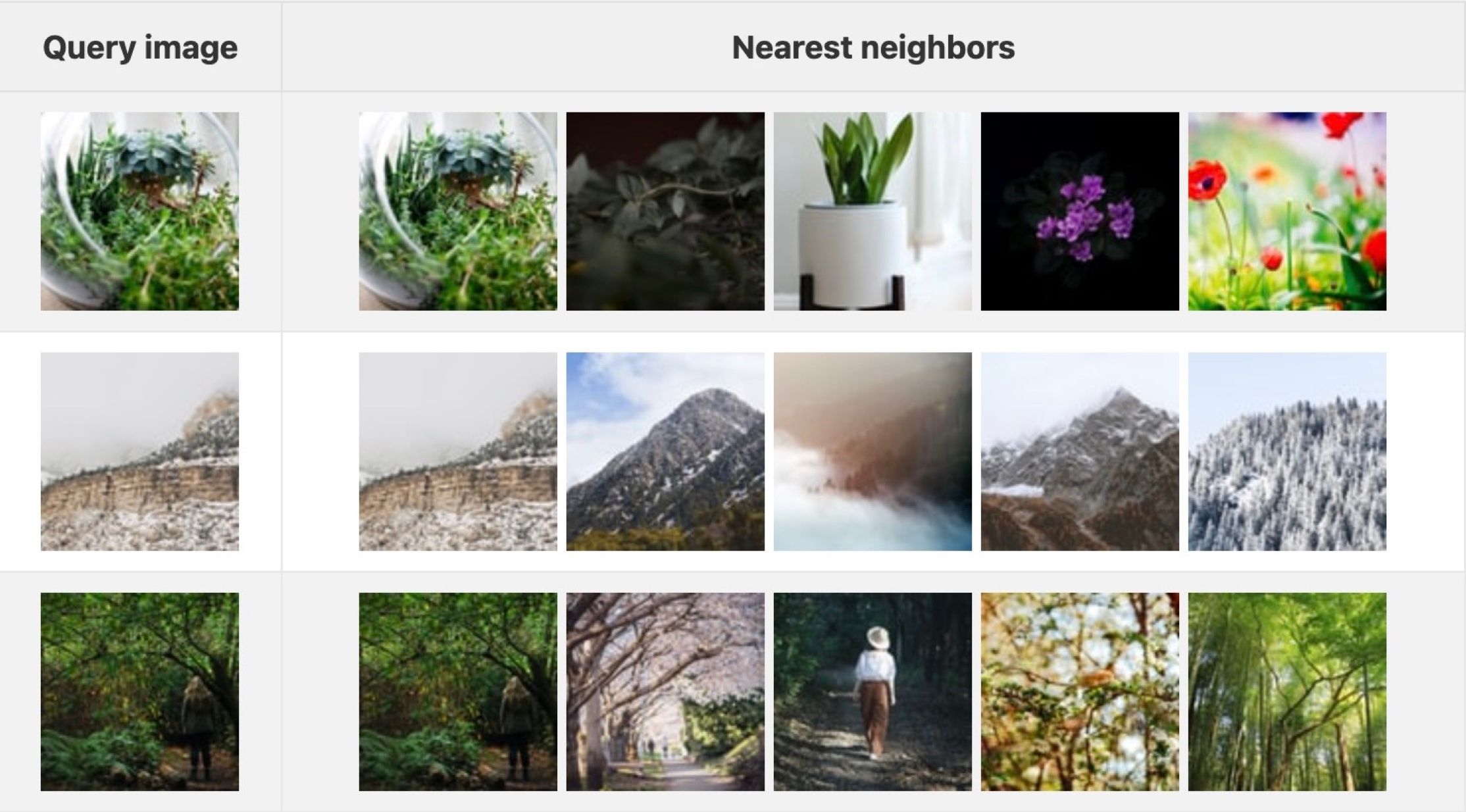 Approximate nearest neighbor search visualized
Approximate nearest neighbor search visualized
ANN探索はベクトルデータベースの中核を成す要素であり、それ自体が大きな研究分野です。そのため、Milvusで利用可能なさまざまなANN探索手法については、今後の一連の記事で詳しく掘り下げていきます。 可視化された近似最近傍探索。
まとめ
ここまでお読みいただきありがとうございます!このチュートリアルの重要なポイントは以下の通りです:
- 構造化データおよび半構造化データは、数値、文字列、または時間データ型に限られます。現代の機械学習の力を借りて、非構造化データは高次元ベクトルの数値として表現されます。
- これらのベクトルは、埋め込みとして一般的に知られ、非構造化データの意味的な内容を表現するのに非常に有効です。一方、構造化データおよび半構造化データは意味的にそのままであり、つまりコンテンツ自体が意味に相当します。
- 非構造化データの検索と分析は、ANN検索という確率論的なプロセスを通じて行われます。一方、構造化データおよび半構造化データに対するクエリは決定論的です。
- 非構造化データの処理は半構造化データの処理とは非常に異なり、完全なパラダイムシフトを必要とします。これにより、新しいタイプのデータベースであるベクトルデータベースが必要とされます。
これで、イントロダクションシリーズの第一部が終了です。ベクトルデータベースに初めて触れる方へ、Milvusの世界へようこそ!次のチュートリアルでは、ベクトルデータベースについてさらに詳しく説明します:
- 最初に、Milvusベクトルデータベースの概要を提供します。
- 次に、Milvusがベクトル検索ライブラリ(FAISS、ScaNN、DiskANNなど)とどのように異なるかを解説します。
- また、ベクトルデータベースがベクトル検索プラグイン(伝統的なデータベースや検索システム用)とどのように異なるかについても議論します。
- 最後に、現代のベクトルデータベースに関連する技術的課題を取り上げます。 次回のチュートリアル「ベクトルデータベースとは?」でお会いしましょう。
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
読み続けて

How Zilliz Saw the Future of Vector Databases—and Built for Production
Zilliz anticipated vector databases early, building Milvus to bring scalable, reliable vector search from research into production AI systems.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.