




Migliorare il vostro RAG con i grafici della conoscenza utilizzando KnowHow
La Retrieval Augmented Generation (RAG) è una tecnica popolare che fornisce al LLM conoscenze aggiuntive e memorie a lungo termine attraverso un database vettoriale come Milvus e Zilliz Cloud (il Milvus completamente gestito). Un RAG di base può risolvere molti problemi del LLM, ma è insufficiente se si hanno requisiti più avanzati, come la personalizzazione o un maggiore controllo dei risultati recuperati.
In occasione del nostro recente Unstructured Data Meetup, Chris Rec, cofondatore di WhyHow, ha condiviso il modo in cui incorpora i Knowledge Graph (KG) nella pipeline RAG per ottenere migliori prestazioni e precisione. Il blog tratterà i punti chiave del suo intervento, tra cui una panoramica dei Knowledge Graphs, dei RAG e di come integrare i Knowledge Graphs nei sistemi RAG per migliorare le prestazioni.
Se volete saperne di più su questo argomento, vi consigliamo di guardare l'intero intervento su YouTube.
Una panoramica del RAG e delle sue sfide
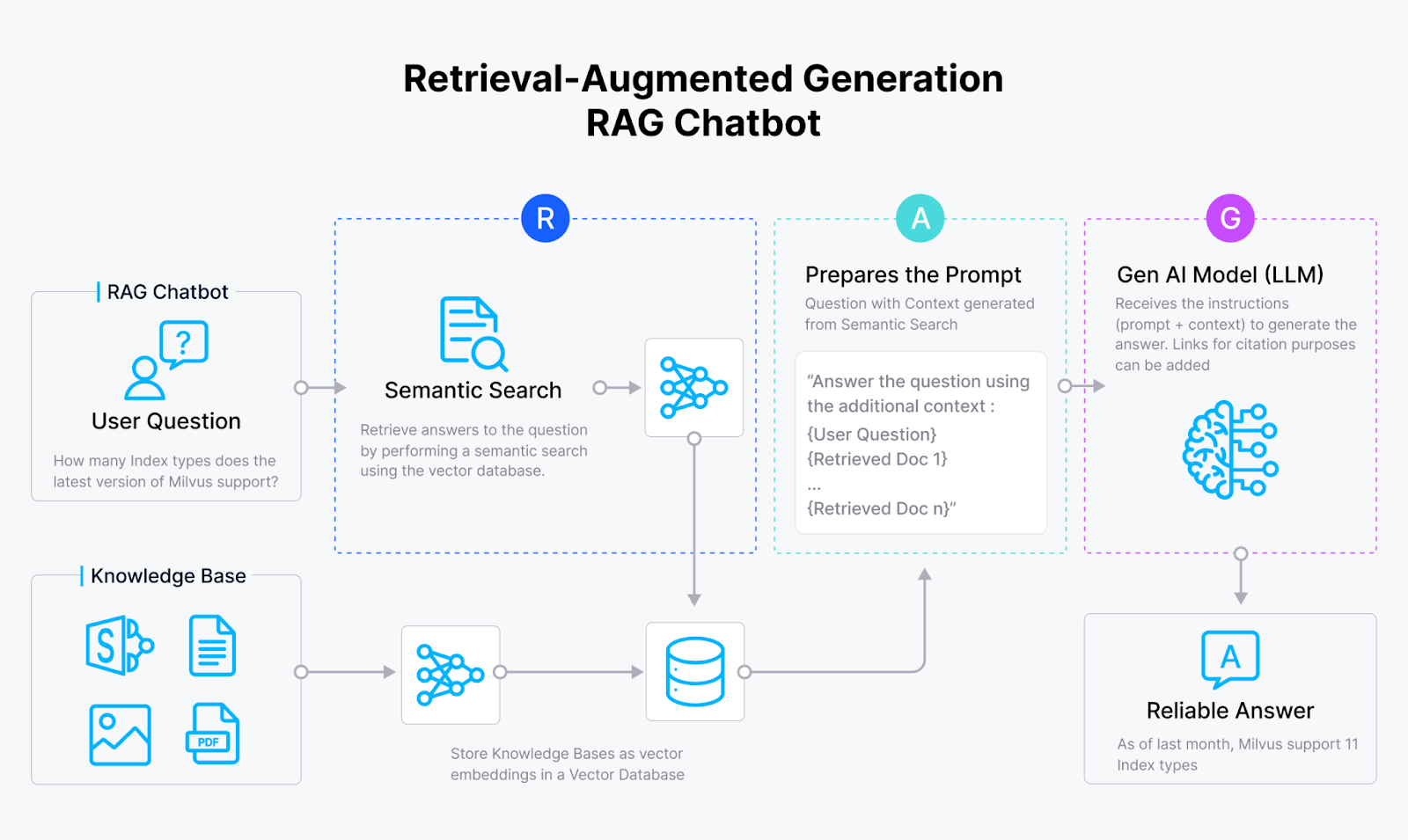
Il RAG è un metodo che sfrutta i punti di forza dei sistemi di intelligenza artificiale basati sul reperimento e di quelli generativi. Un RAG vanilla comprende solitamente un database vettoriale come Milvus, un embedding model e un modello linguistico di grandi dimensioni (LLM.
Un sistema RAG utilizza innanzitutto il modello di embedding per trasformare i documenti in embedding vettoriali e memorizzarli in un database vettoriale. Quindi, recupera le informazioni pertinenti alla query da questo [database vettoriale] (https://zilliz.com/learn/what-is-vector-database) e fornisce i risultati recuperati al LLM. Infine, il LLM utilizza le informazioni recuperate come contesto per generare risultati più accurati.
 Flusso di lavoro RAG
Flusso di lavoro RAG
Figura 1: Come funziona RAG
Sebbene un RAG vanilla sia in grado di generare risultati più aggiornati e accurati, presenta ancora diverse limitazioni.
**Per esempio, il termine "capacità veicolare" potrebbe riferirsi sia al numero di passeggeri che un'auto può contenere sia al numero di auto che possono stare su una strada, creando ambiguità.
In secondo luogo, è difficile gestire in modo accurato i vari tipi di query. Per esempio, rispondere a query basate sulla localizzazione, come "Voglio andare a Londra", è molto diverso dal rispondere a richieste più astratte legate al benessere, come "Sono stressato al lavoro e voglio prendermi una vacanza".
**Per esempio, può essere difficile distinguere tra una "casa al mare" a un miglio dalla riva e una "casa sulla spiaggia" direttamente sulla sabbia.
**Recuperare tutte le informazioni pertinenti per le domande complete può essere difficile, soprattutto per le interrogazioni complesse, come l'elenco di tutti i partner limitati (LP) di un fondo che hanno investito almeno 10 milioni di dollari e che hanno diritti speciali di accesso ai dati.
Infine, le interrogazioni multi-hop aggiungono un ulteriore livello di complessità, poiché richiedono la combinazione accurata di più informazioni. Questo approccio richiede la suddivisione di una query in diverse sotto-query, ciascuna con condizioni specifiche, per garantire che la risposta finale sia accurata e completa.
Mentre soluzioni come il miglioramento della tempestività, le strategie avanzate di chunking, i migliori modelli di embedding e il reranking possono risolvere molte delle sfide associate alle RAG, WhyHow adotta un approccio diverso, incorporando i knowledge graph nella pipeline delle RAG.
Cosa sono i Knowledge Graph (KG)?
Un Knowledge Graph (KG) è un tipo di struttura dati che non solo memorizza i dati, ma collega anche dati simili o dissimili in base alla loro relazione. Questo approccio porta ad avere una collezione di cose (che possono essere qualsiasi tipo di dati) collegate in modo da fornire informazioni correlate o rilevanti.
Un Knowledge Graph è composto da nodi, bordi e proprietà.
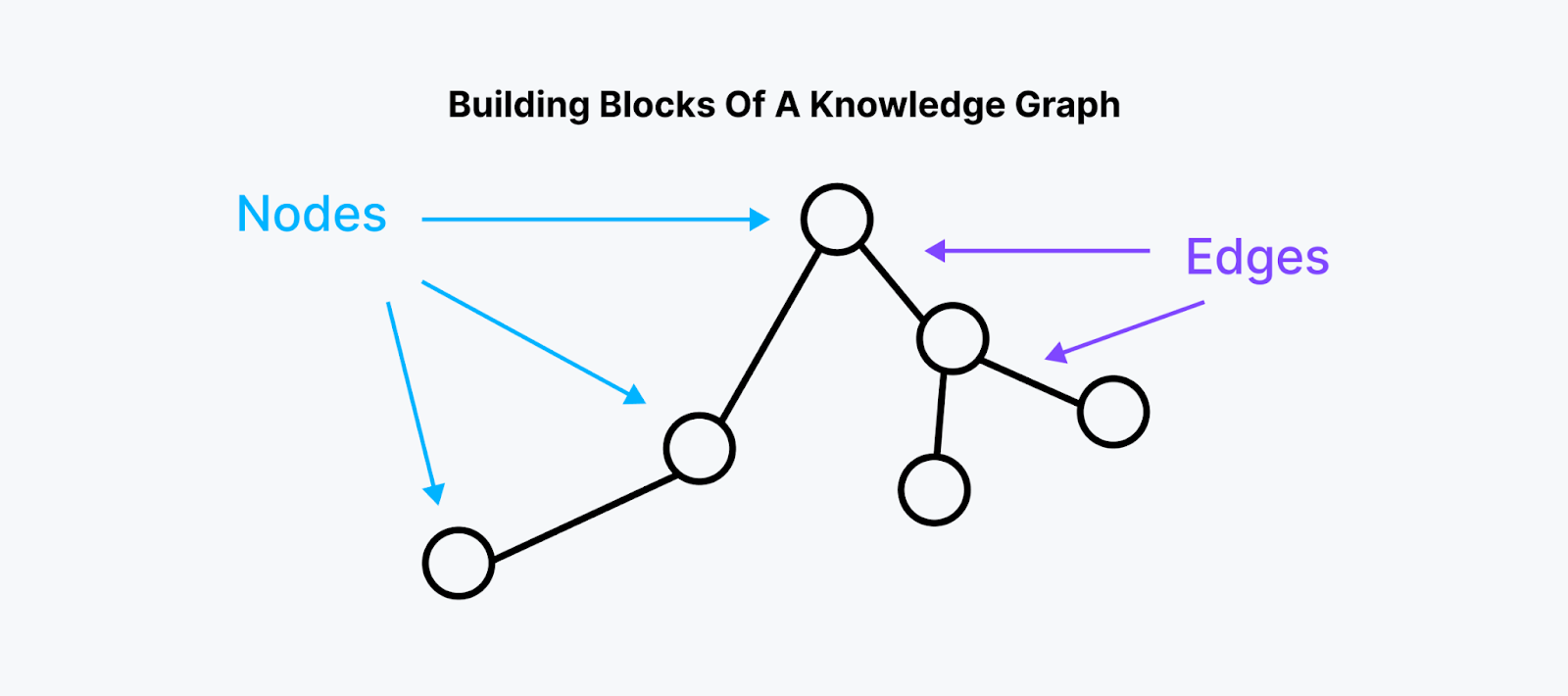 Fig 2- Elementi costitutivi di un Knowledge Graph
Fig 2- Elementi costitutivi di un Knowledge Graph
Figura 2: Elementi costitutivi di un grafico della conoscenza
Nodi:
Rappresentano le entità o gli oggetti del grafo.
I valori di memorizzazione di queste entità possono essere qualsiasi tipo di dati.
Frontiere:
Rappresentano le relazioni tra le entità.
Contengono informazioni sulla natura della relazione tra i nodi collegati.
Proprietà: Caratteristiche o elementi associati alle singole entità.
A differenza dei tradizionali database tabellari, i grafi della conoscenza utilizzano una struttura a grafo per una rappresentazione flessibile delle relazioni e si concentrano sulla comprensione semantica. Questo approccio consente interrogazioni complesse e una più facile estrazione di informazioni specifiche.
Vantaggi dell'integrazione dei grafi della conoscenza nei sistemi RAG
Integrando i grafi della conoscenza nella pipeline RAG, possiamo migliorare significativamente le capacità di reperimento e la qualità delle risposte del sistema, ottenendo prestazioni, accuratezza, tracciabilità e completezza superiori. Ecco i principali vantaggi di un sistema RAG basato sui grafi della conoscenza:
Maggiore comprensione del contesto
I grafi della conoscenza forniscono una rappresentazione ricca e interconnessa delle informazioni, consentendo al sistema RAG di cogliere le relazioni complesse tra le entità. Questa comprensione contestuale più profonda porta a risposte più sfumate e pertinenti.
Miglioramento dell'accuratezza e della coerenza dei fatti
La natura strutturata dei grafi della conoscenza aiuta a mantenere la coerenza fattuale tra i contenuti generati. Ancorando le risposte alle informazioni verificate all'interno del grafico, il sistema può ridurre gli errori e le allucinazioni comuni ai modelli linguistici tradizionali.
Capacità di ragionamento multi-hop
I grafi della conoscenza consentono al sistema RAG di eseguire ragionamenti multi-hop, collegando informazioni diverse attraverso percorsi logici. Questa capacità consente di rispondere a domande più sofisticate e di generare inferenze.
Recupero efficiente delle informazioni
La struttura a grafo facilita il recupero rapido e preciso delle informazioni, anche per query complesse. Questa efficienza si traduce in tempi di risposta più rapidi e nella generazione di contenuti più pertinenti. Inoltre, i sistemi RAG basati sui grafi di conoscenza consentono un approccio di recupero ibrido, combinando l'attraversamento dei grafi con ricerche vettoriali e per parole chiave, capacità fornite da database vettoriali come Milvus e Zilliz Cloud.
Più precisamente, questo approccio ibrido permette di:
corrispondenze precise tra entità e relazioni attraverso l'attraversamento dei grafi
Corrispondenza di similarità semantica utilizzando embeddings vettoriali
Ricerca tradizionale basata su parole chiave per i contenuti di tipo testuale
Questa strategia di reperimento sfaccettata migliora la capacità del sistema di trovare le informazioni più rilevanti tra vari tipi e strutture di dati, portando a risposte più complete e accurate.
Output trasparenti e tracciabili
Con i grafi della conoscenza, il sistema può fornire una chiara provenienza delle informazioni utilizzate per generare le risposte. Questa tracciabilità accresce la fiducia degli utenti e consente un più facile controllo e verifica dei fatti.
Sintesi della conoscenza interdistrettuale
Rappresentando domini diversi all'interno di un'unica struttura a grafo, i sistemi RAG basati sui grafi della conoscenza possono sintetizzare più facilmente le informazioni in campi diversi, portando a intuizioni più complete e interdisciplinari.
Migliore gestione dell'ambiguità
La struttura relazionale dei grafi della conoscenza aiuta a disambiguare entità e concetti, riducendo la confusione in situazioni in cui i termini o i nomi possono avere molteplici significati o riferimenti.
Sfruttando questi vantaggi, le applicazioni RAG potenziate con i grafi della conoscenza possono fornire risposte più accurate, contestualmente rilevanti e complete alle interrogazioni degli utenti.
Cos'è WhyHow? Come migliora la RAG con i grafi della conoscenza?
WhyHow è una piattaforma per la costruzione e la gestione di grafi di conoscenza a supporto del reperimento di dati complessi. La costruzione di Knowledge Graphs completi è impegnativa e richiede molto tempo. WhyHow risolve questo problema creando piccoli KG e iterandoli più volte finché non emerge un KG soddisfacente per un dominio specifico. Questo approccio contribuisce a rendere le KG altamente specifiche per il dominio, più semplici e facili da lavorare, dato che le KG sono complesse.
WhyHow fornisce inoltre agli sviluppatori gli elementi per organizzare, contestualizzare e recuperare in modo affidabile i dati non strutturati per eseguire RAG complessi. Integrando WhyHow nelle pipeline RAG esistenti, alimentate da un database vettoriale, è possibile rendere il sistema RAG più strutturato, coerente e controllato. Il diagramma seguente mostra come funziona un RAG potenziato dal Knowledge Graph.
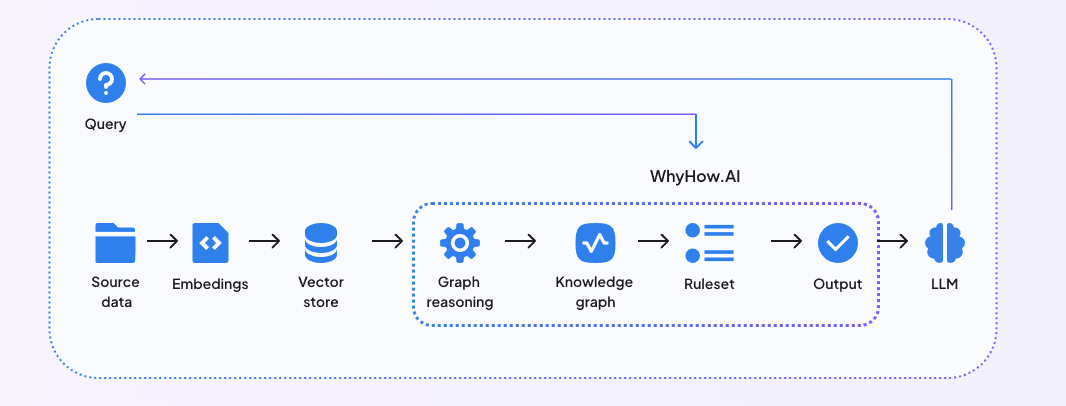 Fig 3- Integrazione di RAG con WhyHow
Fig 3- Integrazione di RAG con WhyHow
Fig 3: Integrazione di RAG con WhyHow
Incorporando WhyHow nel vostro flusso di lavoro RAG, potete adottare un approccio ibrido a grafo e vettoriale, sfruttando il meglio di entrambi i grafi di conoscenza e le capacità di ricerca vettoriale fornite da database vettoriali.
Per una guida più dettagliata su come costruire un RAG potenziato dal Knowledge Graph con WhyHow, vi consigliamo di guardare la demo live condivisa da Chris durante l'Unstructured Data Meetup ospitato da Zilliz.
Maggiore controllo sui flussi di lavoro di recupero all'interno di RAG con WhyHow e Zilliz Cloud
Oltre a rendere le applicazioni RAG più performanti e tracciabili, molti sviluppatori sperano anche di avere un maggiore controllo su ciò che le loro RAG recuperano. Questo perché le applicazioni RAG a volte non riescono a recuperare in modo coerente i dati corretti quando gli utenti inviano query mal formulate o quando gli utenti devono includere nelle risposte dati contestualmente rilevanti ma semanticamente dissimili.
Per risolvere questi problemi, WhyHow ha creato un Rule-based Retrieval Package integrandosi con Zilliz Cloud. Questo pacchetto Python consente agli sviluppatori di creare flussi di lavoro di recupero più accurati con funzionalità di filtraggio avanzate, dando loro un maggiore controllo sul flusso di lavoro di recupero all'interno delle pipeline RAG. Questo pacchetto si integra con OpenAI per la generazione del testo e Zilliz Cloud per l'archiviazione e l'efficiente ricerca di similarità vettoriale con filtraggio dei metadati.
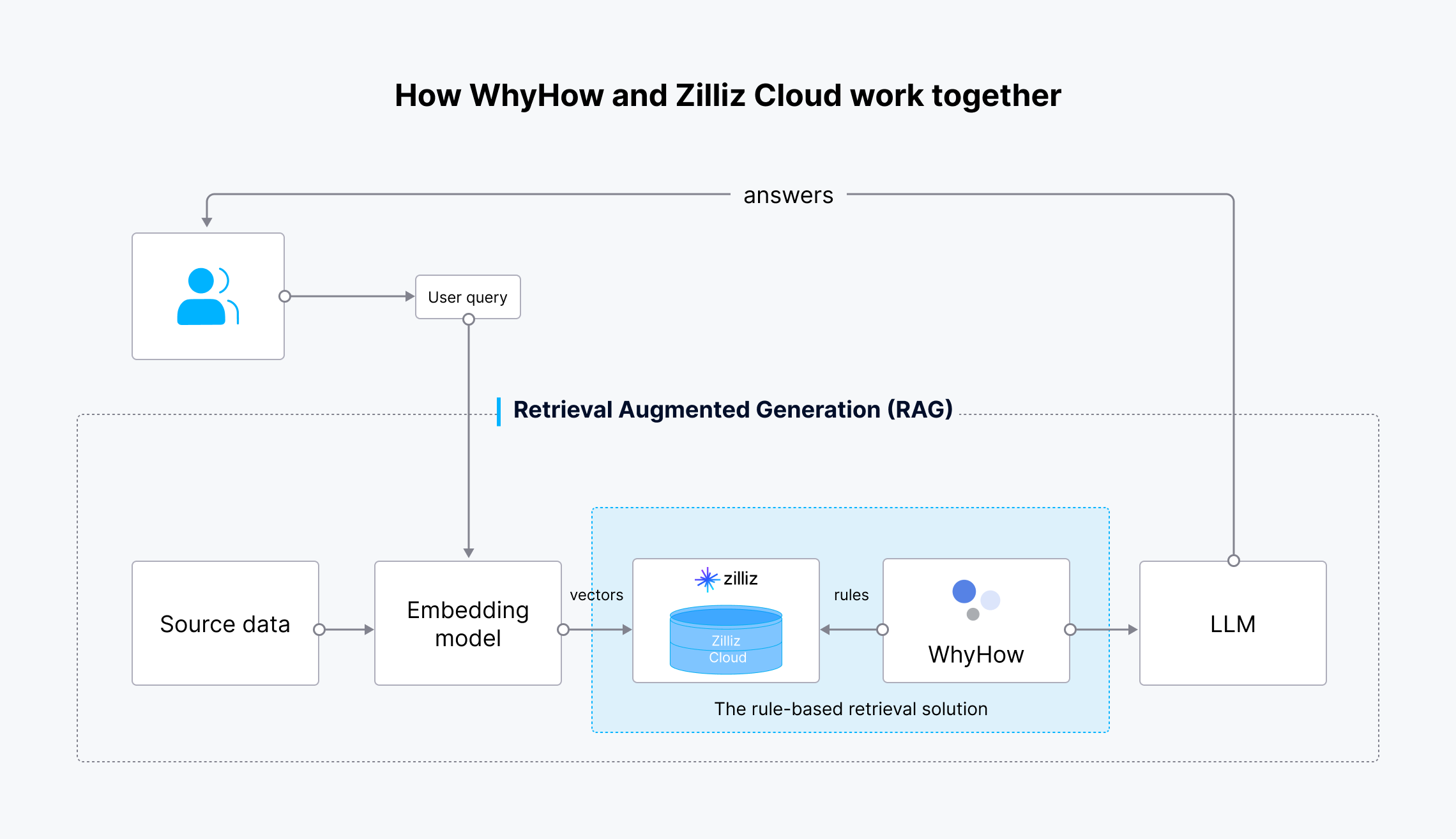
La soluzione di reperimento basata su regole esegue questi compiti:
**Creazione di un archivio vettoriale ** Crea una collezione Milvus per la memorizzazione di chunk embeddings.
Splitting, Chunking, and Embedding: Divide automaticamente, suddivide e crea embeddings per i documenti caricati usando LangChain's PyPDFLoader e RecursiveCharacterTextSplitter, e supporta il modello text-embedding-3-small di OpenAI.
Inserimento dei dati: Carica gli embeddings e i metadati su Milvus o Zilliz Cloud.
Filtrazione automatica: Costruisce un filtro di metadati basato su regole definite dall'utente per affinare le interrogazioni sull'archivio vettoriale.
Il flusso di lavoro è il seguente:
 Come lavorano insieme WhyHow e Zilliz Cloud
Come lavorano insieme WhyHow e Zilliz Cloud
Figura 4: Flusso di lavoro della soluzione di recupero basata su regole
I dati di partenza vengono trasformati in embeddings vettoriali utilizzando il modello di embedding di OpenAI e inseriti in Zilliz Cloud per l'archiviazione e il recupero. Quando viene effettuata una richiesta da parte dell'utente, anch'essa viene trasformata in embedding vettoriali e inviata a Zilliz Cloud per la ricerca dei risultati più rilevanti. WhyHow stabilisce regole e aggiunge filtri alla ricerca vettoriale. I risultati recuperati, insieme alla domanda originale dell'utente, vengono poi inviati al LLM, che genera risultati più accurati e li invia all'utente.
Conclusione
LLM ha davvero alleggerito il nostro compito di trovare risposte a vari problemi. Sono abbastanza intelligenti da comprendere la query fornita, ma allucinati, ed è difficile tenerli aggiornati a causa dei limiti delle risorse. Per questo motivo, la tecnica della retrieval augmented generation (RAG) li potenzia fornendo un contesto alla query; tuttavia, i sistemi RAG hanno anche dei limiti, come discusso.
WhyHow ha identificato questi limiti, evidenziando che la soluzione sta nell'incorporare i Knowledge Graph nelle pipeline RAG. Migliorando la RAG con i Knowledge Graph, i sistemi RAG possono recuperare informazioni più pertinenti e contestuali e generare risposte più determinabili con meno allucinazioni e un'elevata precisione.
Se volete approfondire questo argomento, guardate la presentazione di Chris su YouTube.
Ulteriori risorse
Ottimizzazione della RAG con i reranker: ruolo e compromessi
RAG completa: un'architettura moderna per l'iperpersonalizzazione
Costruire applicazioni RAG intelligenti con LangServe, LangGraph e Milvus
Costruire RAG con Milvus e Snowpark Container Services distribuiti autonomamente
Esplorare DSPy e la sua integrazione con Milvus per creare pipeline RAG altamente efficienti

Continua a leggere

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.