




Fog Computing: Bringing the Cloud Closer to Real-Time Data

Quick answer: Fog computing is a decentralized computing infrastructure that brings data storage, processing, and applications closer to devices and users at the network’s edge rather than relying solely on centralized cloud servers. This approach reduces latency, improves response times, and enhances the efficiency of applications that require real-time data processing, such as autonomous vehicles, smart cities, and industrial IoT. By processing data closer to its source, fog computing minimizes the amount of information sent to the cloud, reducing bandwidth and increasing security. It essentially bridges edge devices and the cloud, making data management faster and more efficient.
Fog Computing: Bringing the Cloud Closer to Real-Time Data
What is Fog Computing?
Fog computing is a way to process data closer to where it’s created rather than sending it to a central cloud server. It acts as a middle layer between local devices and the cloud, handling data locally to reduce delays. This setup is ideal for applications that need fast responses, like traffic monitoring, smart factories, or healthcare sensors. By processing data nearby, fog computing minimizes network load and speeds up response times.
Evolution from Cloud Computing to Fog Computing
Cloud computing has changed how we handle data through its centralized storage and processing power, which makes it accessible from anywhere. However, as more devices connect to the internet—especially in the Internet of Things (IoT) era—relying solely on cloud computing starts showing limits. Sending all data to distant servers creates delays, or “latency,” which becomes a problem for applications needing quick responses, like autonomous vehicles or smart healthcare.
Fog computing emerged as a solution to address this. Instead of sending everything to the cloud, fog computing processes data closer to where it’s generated. This approach reduces latency, improves response times, and makes data handling more efficient in environments with many connected devices. Fog computing builds on cloud computing by adding a local processing layer, making it better suited for real-time, data-intensive applications.
Layer Hierarchy
The more commonly accepted hierarchy of fog computing in industry and research is as follows:
Cloud Layer: The central data center where large-scale data storage, management, and long-term analytics occur.
Fog Layer: An intermediary layer closer to the devices than the cloud. Fog nodes could be located on local servers, gateways, or routers and handle local data aggregation and initial processing.
Edge Layer: The layer below the fog layer and above the IoT devices is the edge layer. It includes individual devices (like routers or small computing devices) located physically close to the IoT sensors and actuators. Sometimes IoT devices can also be regarded as edge devices if they possess the processing power.
IoT/Device Layer: This is the layer of data-generating devices like sensors, cameras, and other IoT devices.
Edge Computing refers to processing that occurs very close to the data source, which can mean directly on the data-generating device itself (like a sensor with computing capabilities) or a nearby device, e.g., a router or a gateway that still comes within the “edge” environment.
How Does Fog Computing Work?
Fog computing relies on specific components to handle data close to its source:
Fog Nodes: It includes devices like routers, gateways, or local servers, acting as intermediaries. They perform the initial data processing and manage immediate tasks without contacting the cloud.
Fog Services: Within the fog layer, these services offer computing power, storage, and networking abilities. This setup allows quick data processing and reduces the need for continuous cloud connectivity.
Protocols and Communication Standards: To support smooth and efficient data transfer, fog computing relies on protocols like MQTT, CoAP, and the high-speed 5G network. These ensure that data flows quickly and securely between devices and nodes.
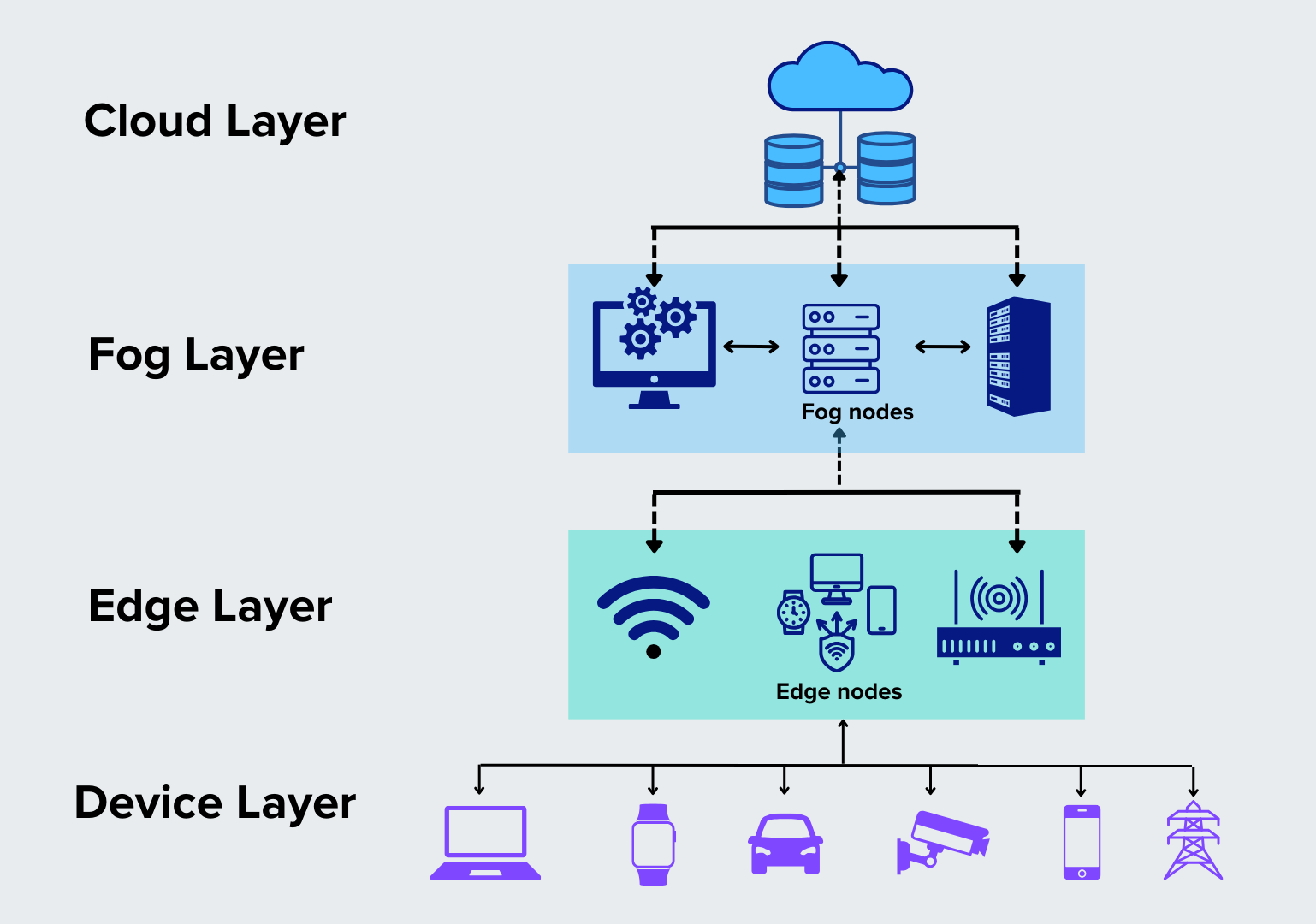 Figure- Fog computing layers.png
Figure- Fog computing layers.png
Figure: Fog computing layers
With these components in place, fog computing creates a layered network that manages data from collection to processing. The data starts at the device level, generated by sensors or connected devices. Instead of sending everything directly to the cloud, this data is directed to nearby fog nodes, where initial analysis and quick processing occur. For instance, in a smart city, traffic cameras might instantly process footage through a local fog node to monitor congestion rather than relying on the cloud.
Fog nodes determine which data requires immediate response and which can be saved later. Urgent information is handled locally, while non-urgent data is sent to the cloud for long-term storage and further analysis.
Applications of Fog Computing
Fog computing has practical uses across many fields to process and manage data near where it’s generated. Here are some key applications:
Smart Cities: Fog computing supports real-time data management in cities for applications like traffic monitoring, energy management, and waste control. For example, fog nodes can analyze data from traffic cameras to manage congestion instantly or adjust street lighting based on local foot traffic, reducing energy waste.
Healthcare: In healthcare, it facilitates real-time monitoring and patient diagnostics. Wearable devices can track patient vitals, sending immediate data to nearby fog nodes that alert healthcare providers if something abnormal is detected. This setup is also useful for remote surgeries, where precise and quick responses are critical.
Industrial IoT (IIoT): Manufacturing and industrial environments use fog computing for predictive maintenance and automated processes. For instance, sensors on machinery can send data to fog nodes to detect potential issues early for timely maintenance without halting production.
Autonomous Vehicles: Fog computing facilitates faster decision-making in autonomous vehicles, processing real-time data from sensors and cameras locally within the vehicle or through nearby fog nodes. This local processing is critical for quick responses to sudden events, such as a pedestrian crossing the street, reducing the reliance on cloud-based decision-making that could introduce dangerous delays.
Agriculture: Farmers benefit from fog computing through precision farming, where data from soil sensors, weather forecasts, and crop health monitoring can be processed locally. Fog nodes analyze this data to provide insights into the best times for planting, watering, or harvesting, which makes farming more efficient and responsive to current conditions.
Retail: Fog computing also enhances customer experiences by processing data from in-store devices, such as beacons or cameras, to personalize shopping experiences. For example, stores can use fog nodes to analyze customer behavior and send personalized promotions or information to their mobile devices while they shop.
Energy Management: In energy systems, fog computing helps monitor and control energy grids. Energy providers can manage power flows, detect outages, and balance loads in real-time by processing data locally for a stable and responsive community energy supply.
Smart Homes: Fog computing supports home automation systems by processing data from devices like thermostats, security cameras, and appliances within the home network. This setup provides instant responses, such as adjusting the thermostat or alerting homeowners to unusual activity, without depending on cloud latency.
Benefits of Fog Computing
Fog computing brings several key advantages to data processing and management:
Reduced Latency: By handling data closer to its source, fog computing significantly reduces processing delays. This setup enhances the response times, essential for real-time applications like autonomous vehicles or smart healthcare monitoring.
Enhanced Security and Privacy: Since data is processed locally within a controlled network, fog computing reduces the need to send sensitive information to the cloud. This enhances data privacy and limits exposure to potential external threats.
Improved Reliability: Fog computing reduces dependency on cloud availability. If cloud access is temporarily lost, fog nodes can continue to operate and manage local data processing, ensuring continuity for critical applications.
Challenges and Limitations of Fog Computing
Fog computing faces several challenges:
Infrastructure Complexity: Implementing fog computing requires a diverse and scalable infrastructure that securely handles data across multiple locations. Setting up and maintaining this complex network can be resource-intensive, especially for large-scale deployments.
Security and Privacy Concerns: While fog computing enhances privacy by keeping data local, it also introduces risks. Data flows across multiple fog nodes, which can become points of vulnerability if not properly secured. Ensuring consistent security across these nodes is critical but challenging.
Standardization Issues: Fog computing lacks universal standards and protocols, leading to interoperability challenges between devices and platforms. Managing and integrating fog systems can become difficult without standard guidelines, especially as new devices are added.
Resource Constraints: Unlike the cloud, fog nodes have limited processing power and storage. This limitation can impact the ability to handle large volumes of data or perform complex analyses that require efficient resource management to ensure smooth operation.
Fog Computing vs. Edge vs Cloud Computing
| Feature | Cloud Computing | Fog Computing | Edge Computing |
| Data Processing Location | Centralized, distant servers (cloud) | Intermediate nodes between cloud and devices | Directly on the data-generating devices (sensors, routers) |
| Latency | Higher, due to distance | Moderate, as data is processed near the source | Lowest, with data processed directly at the source |
| Scalability | Highly scalable | Moderately scalable, suitable for large but localized networks | Limited to device capacity, ideal for single-device scenarios |
| Data Transmission | Continuous data flow to and from the cloud | Limited data transfer to the cloud, mostly for non-urgent data | Minimal to no data transfer to cloud, primarily local processing |
| Reliability | Dependent on network connectivity | Less reliant on cloud, can continue locally | High reliability, local processing reduces dependency on cloud |
| Best Use Cases | Big data analysis, storage, and backup | Real-time analytics, IoT, smart cities, connected vehicles | Real-time processing on individual devices, like wearables |
Table: Cloud vs Fog vs Edge computing
Future of Fog Computing
The future of fog computing looks promising, driven by the expanding needs of IoT and AI, advances in networking, and ongoing research.
Growth in IoT and AI Applications: As IoT devices become more widespread, fog computing is essential for handling the massive amounts of data they generate. Fog’s ability to manage data locally allows for quick responses in smart cities, healthcare, manufacturing, and more, which makes it a key enabler of IoT growth. Similarly, AI applications, which require fast data processing, benefit from fog computing’s proximity to the data source, reducing the time it takes to deliver actionable insights.
5G and Beyond: The rollout of 5G and future network advancements will further enhance fog computing's capabilities. With faster data speeds and lower latency, 5G will support fog nodes in managing more data at higher speeds. This improvement is critical for real-time applications, such as autonomous vehicles and remote healthcare, where quick processing and decision-making are crucial. Fog computing will be better positioned to handle these demands as 5G networks expand.
Research and Innovation: Researchers continue to explore ways to improve fog computing’s security, scalability, and power efficiency. Key areas of innovation include developing stronger security measures to protect data across distributed nodes, creating standardized protocols to ensure compatibility, and optimizing power usage to make fog nodes more energy-efficient. These advancements will help fog computing adapt to growing demands and make it more reliable for industries needing secure, efficient, and scalable solutions.
Conclusion
Fog computing bridges the gap between cloud and edge computing by offering a practical solution for applications that need quick, local data processing. Bringing computation closer to the source reduces latency, improves reliability, and lowers bandwidth costs, making it ideal for IoT, smart cities, healthcare, and other data-intensive fields. As IoT expands and technologies like 5G advance, fog computing’s role will only grow, supporting faster, smarter, and more responsive systems in our connected world.
FAQs on Fog Computing
- What is fog computing?
Fog computing is a decentralized computing model that processes data closer to where it’s generated rather than relying on distant cloud servers. It acts as an intermediary layer between devices and the cloud, reducing latency and enabling faster data processing.
- How does fog computing differ from cloud and edge computing?
Cloud computing processes data in remote data centers, while edge computing handles it directly on devices like sensors or nearby servers. Fog computing sits between the two, processing data on local nodes (e.g., routers or gateways) to reduce latency and improve efficiency for real-time applications.
- What are the main benefits of fog computing?
Key benefits of fog computing include reduced latency, improved security by keeping data local, greater reliability by reducing dependency on the cloud, and cost efficiency by minimizing data transmission to the cloud.
- What are some practical applications of fog computing?
Fog computing is widely used in areas like smart cities for traffic management, healthcare for real-time monitoring, industrial IoT for predictive maintenance, autonomous vehicles for fast decision-making, and agriculture for precision farming.
- What challenges does fog computing face?
Challenges include the complexity of setting up and managing diverse infrastructure, security and privacy concerns across distributed nodes, lack of standardization for interoperability, and resource constraints in local nodes compared to cloud resources.
Related Resources
- What is Fog Computing?
- Evolution from Cloud Computing to Fog Computing
- How Does Fog Computing Work?
- Applications of Fog Computing
- Benefits of Fog Computing
- Challenges and Limitations of Fog Computing
- Fog Computing vs. Edge vs Cloud Computing
- Future of Fog Computing
- Conclusion
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free