




¿Qué es una ventana de contexto en IA?

¿Qué es una ventana de contexto en IA?
En IA, una ventana de contexto define cuánto texto puede procesar el modelo a la vez, medido en tokens. Comprender la ventana de contexto es crucial, ya que influye en la capacidad de un modelo de IA para generar respuestas precisas y coherentes. Esta guía explorará qué es una ventana de contexto, su importancia en los modelos de IA y los desafíos de gestionar ventanas de contexto más grandes.
Comprender los tokens
Antes de hablar de la ventana de contexto, aprendamos primero el concepto de tokens.
Los tokens son las unidades de datos más pequeñas que los modelos de IA utilizan para procesar y aprender del texto. Son, esencialmente, las partes de una oración—como palabras individuales o signos de puntuación—que una computadora utiliza para comprender y procesar el lenguaje. Cuando una computadora lee una oración, la divide en partes más pequeñas (tokens) para entenderla. Por ejemplo, en la oración "It's sunny!", los tokens serían "It's", "sunny" y "!". Este proceso, llamado tokenización, ayuda a la computadora a analizar texto para tareas como traducir idiomas, detectar spam o responder preguntas.
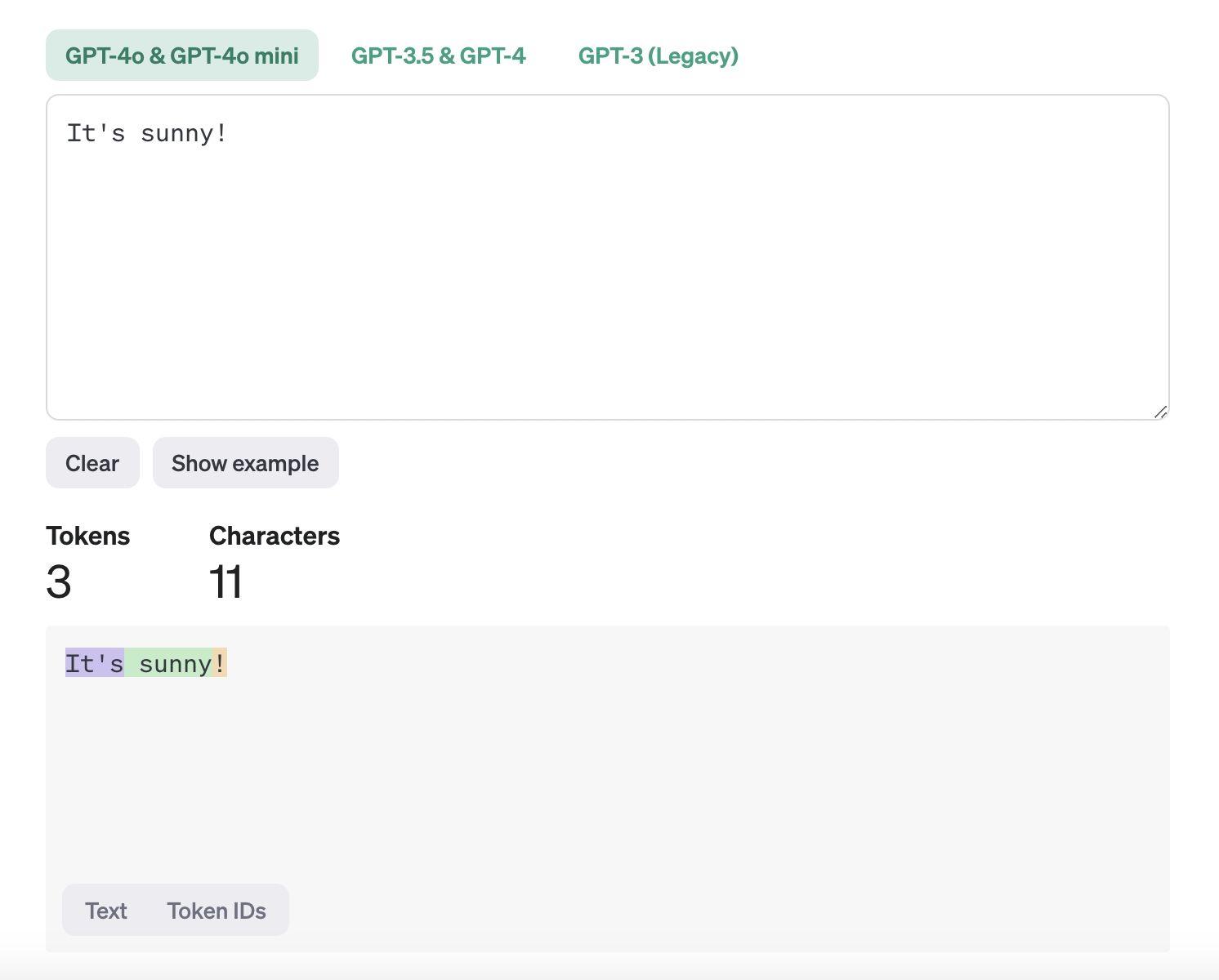 What are tokens.jpeg
What are tokens.jpeg
¿Qué es una ventana de contexto en IA?
La ventana de contexto es un concepto fundamental en IA, particularmente en los modelos de lenguaje grandes (LLMs). Se refiere a la cantidad máxima de texto, medida en tokens, que un modelo de IA puede recordar y usar durante una conversación al generar una respuesta.
Piensa en una ventana de contexto como la capacidad de memoria a corto plazo del modelo. Por ejemplo, si un modelo como ChatGPT tiene una ventana de contexto de 4,096 tokens, puede "recordar" la información de los últimos 4,096 tokens (palabras o signos de puntuación) que procesó. Esto es similar a cómo una persona solo puede seguir cierta cantidad de información mientras lee o escucha. Cuando se alcanza este límite de tokens, la información más antigua comienza a "desvanecerse" a medida que entra nueva información, lo que afecta la capacidad del modelo para hacer referencia a partes anteriores de la conversación. Este concepto es crucial para determinar qué tan bien un modelo puede mantener el contexto en conversaciones o documentos largos.
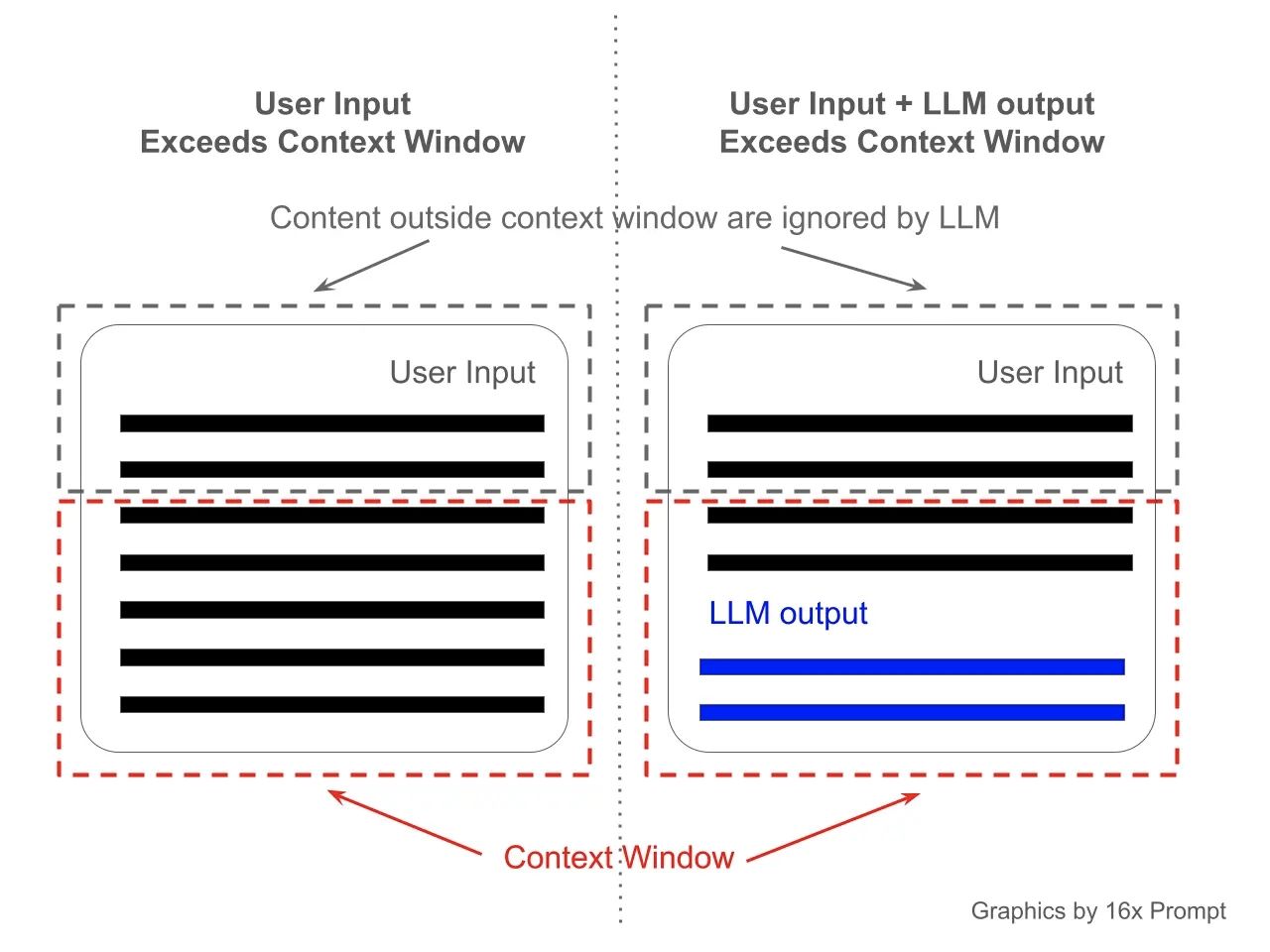 Context Window Visualized, credit 16x Prompt.jpeg
Context Window Visualized, credit 16x Prompt.jpeg
La ventana de contexto no solo se aplica a la entrada o al historial de la conversación en curso, sino también a las respuestas generadas por el modelo. Por ejemplo, si una respuesta contiene 500 tokens, este conteo se deduce del total de tokens disponibles para procesar el historial de la conversación. En consecuencia, si se está cerca del límite de tokens, los primeros 500 tokens de la conversación pueden no considerarse en el procesamiento continuo.
Límites de tokens dentro de la ventana de contexto
El tamaño de la ventana de contexto, o límite de tokens, es el número total de tokens que el modelo puede considerar a la vez. Si la conversación supera este límite, solo se conservan los tokens más recientes y se descartan los tokens más antiguos. Por ejemplo, el modelo avanzado GPT-4o de OpenAI ofrece una ventana de contexto mucho más grande, de hasta 128,000 tokens, lo que permite una interacción más amplia y profunda con el texto.
 GPT-4o's context window and output token limit.jpeg
GPT-4o's context window and output token limit.jpeg
Límites de tokens de salida y entrada
Además de la ventana de contexto, los modelos de IA tienen límites de tokens específicos para salidas y entradas:
- Límite de tokens de salida: Este es el número máximo de tokens que el modelo puede generar en una sola respuesta. Por ejemplo, GPT-4o-mini de OpenAI tiene un límite de tokens de salida de 16,348 tokens. Si la respuesta generada alcanza este límite, el modelo dejará de generar tokens, lo que podría truncar la respuesta.
 GPT-4o-mini's output token limit .jpeg
GPT-4o-mini's output token limit .jpeg
- Límite de tokens de entrada: Esto determina cuántos tokens de la entrada pueden procesarse de una sola vez. Superar este límite significa que el modelo debe segmentar la entrada en partes más pequeñas, lo que podría afectar la coherencia y precisión de la respuesta.
Equilibrar los límites de tokens
El volumen del límite de tokens influye significativamente en el rendimiento de un modelo, dictando su capacidad para analizar e interpretar información compleja de manera efectiva. Equilibrar la cantidad de tokens con la potencia de procesamiento del modelo es esencial, ya que unas capacidades de procesamiento más completas permiten manejar ideas complejas de manera más efectiva, aunque con las compensaciones necesarias en las estrategias de tokenización y procesamiento.
Importancia de ventanas de contexto más grandes en los modelos de IA
 Una representación visual de la importancia de ventanas de contexto más grandes en la IA..jpeg
Una representación visual de la importancia de ventanas de contexto más grandes en la IA..jpeg
Las ventanas de contexto más grandes mejoran significativamente la capacidad de una IA para comprender y analizar documentos extensos, lo que las hace indispensables en campos como la investigación legal y médica. Por ejemplo, en la investigación legal, la IA puede extraer eficientemente información relevante de grandes conjuntos de datos, proporcionando información valiosa rápidamente. De manera similar, en la investigación médica, las ventanas de contexto grandes facilitan el resumen de artículos científicos complejos, ayudando a los investigadores a obtener conocimientos con prontitud.
La mayor capacidad para procesar más de un millón de tokens permite que los modelos de IA manejen diversas tareas de manera efectiva, desde el procesamiento de datos hasta la generación de código. Claude 3.5 Sonnet, por ejemplo, cuenta con un tamaño de ventana de contexto de 200,000 tokens, lo que le permite gestionar instrucciones complejas y tareas matizadas con notable precisión. Esta capacidad subraya el papel crítico de las ventanas de contexto más grandes en la mejora del rendimiento de la IA.
Sin embargo, las ventanas de contexto más grandes en los propios modelos de IA conllevan compensaciones. Pueden generar mayores costos operativos y requieren estrategias de datos sólidas para garantizar la utilización efectiva de datos de entrenamiento relevantes. Además, gestionar una ventana de contexto más grande puede provocar una sobrecarga de información, disminuyendo la eficacia del modelo para identificar puntos clave. Por lo tanto, es esencial un enfoque equilibrado para aprovechar todo el potencial de las ventanas de contexto más grandes mientras se mitigan los desafíos asociados.
En la siguiente sección, exploraremos los desafíos de ampliar las ventanas de contexto.
Desafíos al ampliar las ventanas de contexto en los modelos de IA
Ampliar las ventanas de contexto en los modelos de IA introduce diversas compensaciones que requieren una consideración cuidadosa. Permitir entradas y salidas más largas puede mejorar la riqueza de las respuestas generadas, pero también aumenta la complejidad del procesamiento. El equilibrio entre ventanas de contexto más largas y un procesamiento eficiente es crucial para mitigar posibles inconvenientes en el rendimiento de la IA.
Recursos computacionales
A medida que crecen los tamaños de las ventanas de contexto, el requisito de potencia de procesamiento aumenta sustancialmente, lo que conduce a tiempos de inferencia más lentos. La complejidad de escalar al aumentar las ventanas de contexto surge de que los parámetros aumentan cuadráticamente, lo que plantea desafíos significativos. Cuando la longitud de las secuencias de texto se duplica, las necesidades de memoria y computación se cuadruplican, lo que pone de relieve las mayores demandas de ventanas de contexto más grandes.
Para abordar estos desafíos, se han implementado técnicas como ring attention para mejorar la eficiencia de los modelos que trabajan con ventanas de contexto extendidas. Sin embargo, la teoría de la ‘Zona de Desarrollo Próximo’ sugiere que sobrecargar los modelos de lenguaje con información más allá de sus capacidades actuales puede disminuir su eficacia. Por lo tanto, se necesita una consideración cuidadosa para gestionar los recursos computacionales de manera efectiva.
Implicaciones de costo
Las ventanas de contexto más largas pueden conllevar costos computacionales y financieros significativos, que las organizaciones deben gestionar de manera eficaz. Ampliar la ventana de contexto de 4K a 8K tokens puede provocar un aumento exponencial de los gastos operativos. Por lo tanto, las organizaciones deben sopesar los beneficios de un mejor rendimiento del modelo de IA frente al incremento de los costos de ventanas de contexto más largas.
Las estrategias eficaces de gestión de costos son cruciales para las organizaciones que consideran la expansión de las ventanas de contexto en los modelos de IA. Implementar estas estrategias ayuda a las organizaciones a equilibrar capacidades de IA mejoradas con las implicaciones financieras asociadas, garantizando operaciones de IA sostenibles y eficientes.
Gestión de datos
Gestionar volúmenes más grandes de datos de entrenamiento presenta desafíos significativos para los modelos de IA, particularmente al optimizar el rendimiento sin sobrecargar el sistema. La investigación indica que proporcionar un conjunto enfocado de documentos relevantes ofrece un mejor rendimiento para los modelos de lenguaje que inundarlos con un volumen excesivo de información sin filtrar. Este enfoque garantiza que la IA pueda procesar y responder de manera eficaz, manteniendo la relevancia en sus resultados.
Filtrar y gestionar el contexto de los datos de entrenamiento es esencial para permitir respuestas precisas y un rendimiento eficiente del modelo. Seleccionar y organizar estratégicamente datos relevantes permite a los modelos de IA generar resultados contextualmente apropiados y significativos, incluso con ventanas de contexto más grandes.
RAG: Mejora de los modelos de IA con una base de conocimiento externa para memoria extendida
Las ventanas de contexto más grandes son cruciales en los modelos de IA para mejorar la comprensión y el manejo de tareas complejas. Permiten que los modelos mantengan y aprovechen información más extensa, mejorando la continuidad y la relevancia en las respuestas. Esto resulta especialmente beneficioso para manejar tareas intrincadas. Sin embargo, mantener una ventana de contexto grande puede aumentar las demandas computacionales, los costos y la complejidad en la gestión de datos.
Para dotar a los modelos de IA de capacidades de memoria a largo plazo al mismo tiempo que se abordan estos desafíos, los investigadores han explorado enfoques innovadores como Retrieval-Augmented Generation (RAG). Esta técnica mejora la salida de los modelos de IA al conectarlos a una base de conocimiento externa alojada en una base de datos vectorial. Al hacerlo, proporciona a los modelos un trasfondo contextual más amplio sin la sobrecarga asociada con grandes ventanas de contexto internas. Esta base de conocimiento externa actúa como una memoria extendida, ayudando a los modelos a acceder dinámicamente a un vasto conjunto de información, lo cual es crucial para procesar consultas complejas y mejorar la profundidad y precisión de las respuestas.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) combina el poder generativo de los modelos de lenguaje con la recuperación dinámica de documentos externos. Este enfoque amplía el potencial de los LLM al acceder e integrar una gama más amplia de información, mejorando así la relevancia y precisión de las respuestas generadas.
Un sistema RAG estándar suele integrar un modelo de embedding, una base de datos vectorial como Milvus o su versión gestionada Zilliz Cloud, y un LLM (o un modelo multimodal), donde el modelo de embeddingtransforma el texto en embeddings vectoriales, la base de datos vectorial almacena y recupera información contextual para las consultas de los usuarios, y el LLM genera respuestas basadas en el contexto recuperado.
 Figura- Flujo de trabajo RAG.png
Figura- Flujo de trabajo RAG.png
Aprovechar RAG permite que los modelos de IA recuperen dinámicamente documentos o puntos de datos relevantes durante el proceso de generación, garantizando que los resultados sean ricos en contexto y estén alineados con la intención del usuario. Esta técnica es particularmente útil en escenarios que requieren información detallada y precisa, como la investigación legal o el análisis científico.
Comparación de tamaños de ventana de contexto entre modelos populares
 Un gráfico comparativo de los tamaños de ventana de contexto entre modelos populares de IA
Un gráfico comparativo de los tamaños de ventana de contexto entre modelos populares de IA
Diferentes LLMs vienen con tamaños de ventana de contexto variables, adaptados a diferentes requisitos y tareas. GPT-4o, por ejemplo, cuenta con un tamaño de ventana de contexto de 128,000 tokens, lo que mejora significativamente su capacidad para procesar entradas extensas y generar respuestas contextualmente relevantes. Mientras tanto, Gemini 1.5 Pro puede utilizar una ventana de contexto de más de 2 millones de tokens, ofreciendo ventajas sustanciales en el manejo de grandes conjuntos de datos.
Claude 3.5 Sonnet y Llama 3.2 también muestran tamaños de ventana de contexto variables, cada uno con sus fortalezas y limitaciones. Claude 3.5 Sonnet tiene un tamaño de ventana de contexto de 200,000 tokens, lo que le permite gestionar información extensa en una sola interacción. En contraste, Llama 3.2 admite una ventana de contexto de 128,000 tokens.
| Modelo | Ventana de contexto | Tokens máximos de salida |
|---|---|---|
| GPT-4o | 128,000 tokens | 16,384 tokens |
| GPT-4-turbo | 128,000 tokens | 4,096 tokens |
| GPT-4 | 8,192 tokens | 8,192 tokens |
| Gemini 1.5 Pro | 2,097,152 tokens | 8,192 tokens |
| Claude 3.5 Sonnet | 200,000 tokens | 8192 tokens |
| Llama 3.2 | 128,000 tokens | 2048 tokens |
Resumen
En conclusión, dominar la ventana de contexto es esencial para avanzar en las capacidades de la IA. Las ventanas de contexto más grandes mejoran la capacidad de la IA para procesar y analizar documentos extensos, lo que las hace invaluables en campos como la investigación legal y médica. Sin embargo, ampliar las ventanas de contexto conlleva desafíos, incluidos mayores requisitos computacionales, costos más altos y requisitos complejos de gestión de datos.
Al implementar técnicas como Retrieval-Augmented Generation (RAG) y bases de datos vectoriales, los modelos de IA pueden optimizar la utilización de ventanas de contexto largas con una base de conocimiento externa impulsada por bases de datos vectoriales, garantizando respuestas contextualmente relevantes y precisas. Al mirar hacia el futuro, equilibrar el tamaño de la ventana de contexto con la eficiencia y explorar estrategias innovadoras será crucial para desarrollar aplicaciones avanzadas de IA que puedan manejar tareas complejas de manera efectiva. El camino hacia el dominio de las ventanas de contexto continúa, y las posibilidades son ilimitadas.
Preguntas frecuentes
¿Qué es una ventana de contexto en IA?
Una ventana de contexto en IA es el rango de texto que rodea a un token objetivo que el modelo utiliza para generar respuestas, determinando la cantidad de información que puede procesar a la vez. Comprender este concepto es crucial para optimizar las interacciones con la IA.
¿Por qué son importantes las ventanas de contexto más grandes?
Las ventanas de contexto más grandes son cruciales, ya que mejoran significativamente la comprensión de un modelo de IA y su capacidad para analizar documentos extensos, lo que da como resultado respuestas más coherentes y contextualmente relevantes. Este avance mejora en última instancia la calidad general de la interacción.
¿Cómo afectan los límites de tokens a los modelos de IA?
Los límites de tokens afectan críticamente a los modelos de IA al determinar el tamaño máximo de entrada que pueden manejar. Superar estos límites da como resultado salidas incompletas o inexactas, lo que requiere segmentar el texto en partes más pequeñas.
¿Cuáles son los desafíos de ampliar las ventanas de contexto?
Ampliar las ventanas de contexto plantea desafíos significativos, incluidas demandas computacionales elevadas y mayores costos operativos. Además, complica la gestión de datos, lo que requiere una consideración cuidadosa antes de la implementación.
¿Cómo se pueden mejorar los modelos de IA con ventanas de contexto largas?
Los modelos de IA se pueden mejorar con ventanas de contexto largas utilizando técnicas como la generación aumentada por recuperación (RAG) y integrando vector databases, que ayudan a garantizar respuestas contextualmente relevantes y precisas. Este enfoque mejora significativamente el rendimiento del modelo al manejar información extensa.
Recursos adicionales
- Comprender los tokens
- ¿Qué es una ventana de contexto en IA?
- Importancia de ventanas de contexto más grandes en los modelos de IA
- Desafíos al ampliar las ventanas de contexto en los modelos de IA
- RAG: Mejora de los modelos de IA con una base de conocimiento externa para memoria extendida
- Comparación de tamaños de ventana de contexto entre modelos populares
- Resumen
- Preguntas frecuentes
- Recursos adicionales
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis