




Beobachtbarkeit: Verfolgung jenseits der Überwachung

Beobachtbarkeit: Verfolgung jenseits der Überwachung
Was ist Beobachtbarkeit?
Beobachtbarkeit bedeutet zu verstehen, was in einem System vor sich geht, und zwar anhand der Daten, die es produziert. Man kann sich das so vorstellen, dass man in ein Softwaresystem "hineinschauen" kann und seinen Zustand und sein Verhalten versteht. Dies hilft bei der Beantwortung von Fragen wie "Funktioniert alles wie erwartet?" oder "Warum läuft etwas schief?". Anstatt zu raten, was die Ursache von Problemen ist, liefert die Beobachtbarkeit klare Erkenntnisse durch Daten wie Protokolle, Metriken und Traces.
Warum ist Beobachtbarkeit wichtig?
Moderne Softwaresysteme werden immer komplexer. Mit dem Aufkommen von Technologien wie Microservices, Cloud Computing und Containerisierung bestehen Systeme heute aus vielen miteinander verbundenen Teilen, die über verschiedene Standorte verteilt sein können. Das macht es schwierig, sie zu überwachen und Fehler zu beheben.
Herkömmliche Überwachungstools sind oft unzureichend - sie sagen Ihnen vielleicht, dass etwas nicht stimmt, aber nicht warum. Observability füllt diese Lücke, indem es Einblick in den internen Zustand von Systemen gewährt, um Probleme schnell zu erkennen.
Die Grundpfeiler von Observability
Observability besteht aus drei Säulen, die zusammenarbeiten, um ein klares Bild davon zu vermitteln, was in einem System passiert. Schauen wir sie uns genauer an:
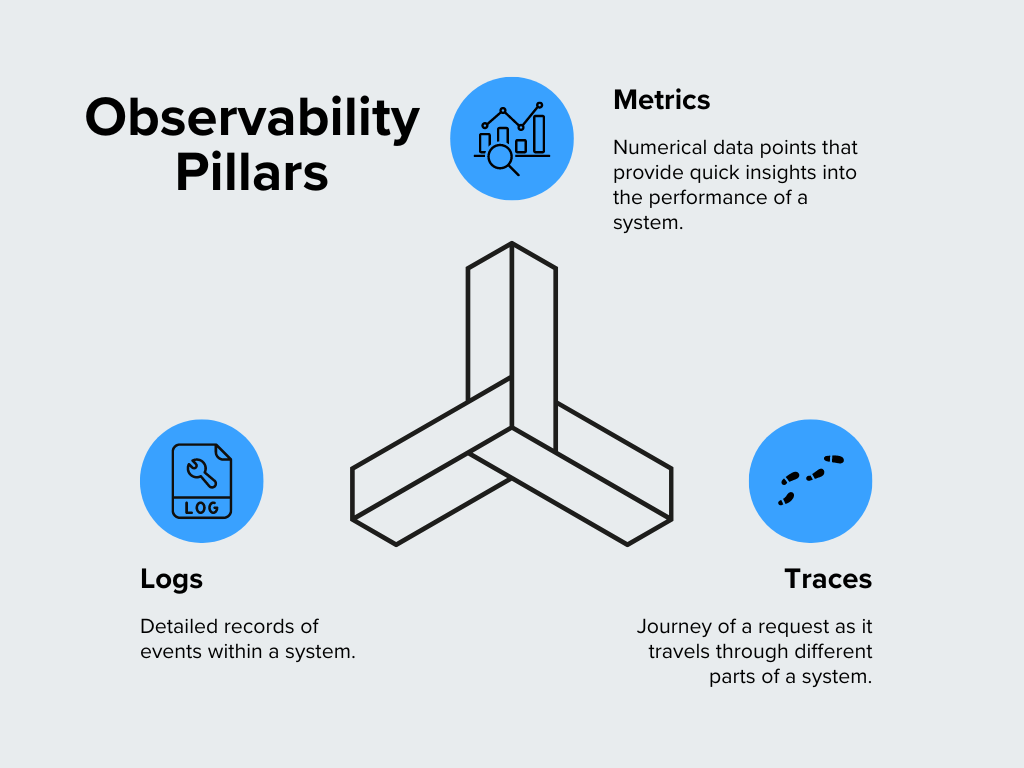 Abbildung- Säulen der Beobachtbarkeit.png
Abbildung- Säulen der Beobachtbarkeit.png
Abbildung: Säulen der Beobachtbarkeit
Metriken
Metriken sind numerische Datenpunkte, die einen schnellen Einblick in die Leistung eines Systems geben. Sie sind die Lebenszeichen Ihres Systems, die zeigen, wie die Dinge funktionieren. Zu den gängigen Metriken gehören CPU-Nutzung, Speicherverbrauch, Anfrageraten und Antwortzeiten. Wenn Sie beispielsweise eine ungewöhnliche Spitze in der CPU-Nutzung feststellen, kann dies auf ein Problem hinweisen, das behoben werden muss. Metriken eignen sich hervorragend, um Trends zu erkennen und zu sehen, wie sich ein System im Laufe der Zeit verhält.
Protokolle
**Logs sind detaillierte Aufzeichnungen von Ereignissen innerhalb eines Systems. Stellen Sie sich diese wie ein Tagebuch vor, das festhält, was in Ihrer Software passiert. Wann immer ein Fehler auftritt, ein Benutzer sich anmeldet oder eine Transaktion verarbeitet wird, wird dies normalerweise in einem Protokoll festgehalten. Protokolle liefern den Kontext für die Diagnose von Problemen und das Verständnis des Systemverhaltens. Wenn zum Beispiel etwas schief läuft, können Protokolle dabei helfen, genau festzustellen, was unmittelbar vor und nach dem Auftreten des Problems passiert ist.
Traces
**In einem komplexen System mit mehreren Diensten, die zusammenarbeiten, zeigt Ihnen ein Trace den Weg einer einzelnen Anfrage und die Zeit, die sie in jedem Dienst verbringt. Traces zeigen Engpässe oder Verzögerungen im Prozess auf. Wenn Sie feststellen, dass eine Anfrage länger dauert als erwartet, können Sie mit Hilfe von Traces feststellen, wo die Verzögerung auftritt.
Wie funktioniert Observabilität?
Observability folgt ein paar wichtigen Schritten. So funktioniert es:
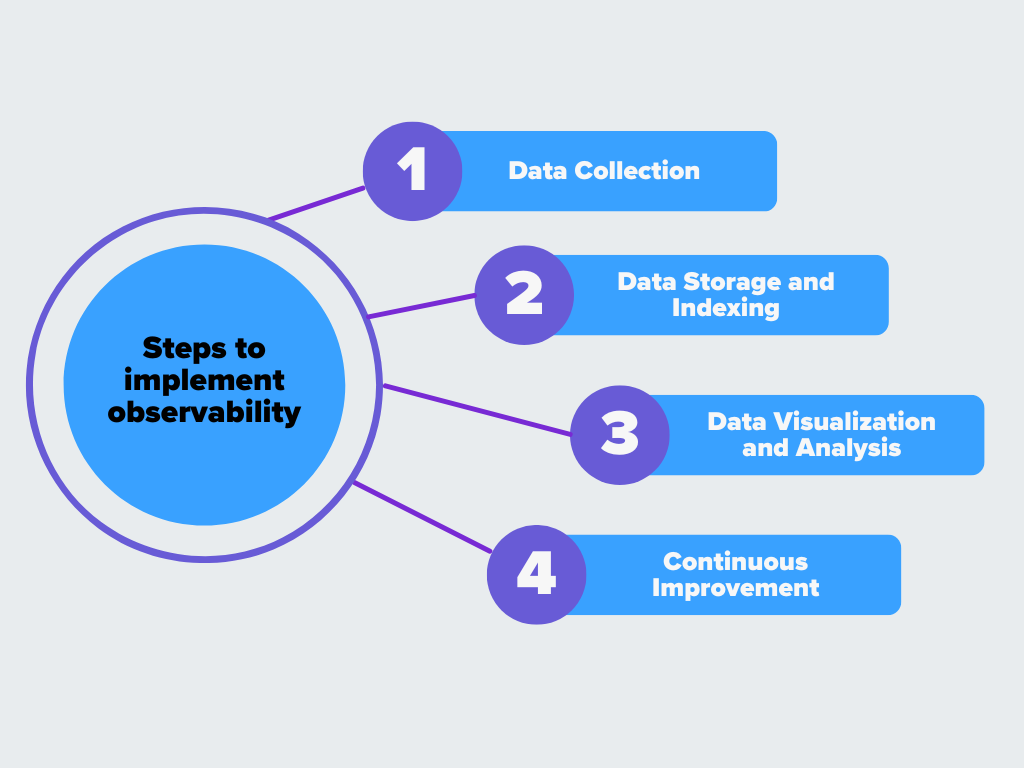 Abbildung- Schritte zur Umsetzung der Beobachtbarkeit.png
Abbildung- Schritte zur Umsetzung der Beobachtbarkeit.png
Abbildung: Schritte zur Umsetzung der Beobachtbarkeit
Datenerhebung
Der erste Schritt ist die Erfassung von Daten aus allen Teilen des Systems. Dazu gehört das Sammeln von Metriken (wie
CPU-Nutzung), Logs (detaillierte Ereignisaufzeichnungen) und Traces (der Weg, den Anfragen durch Dienste nehmen). Ziel ist es, alles zu erfassen, was Aufschluss über die Leistung des Systems, Probleme oder das allgemeine Verhalten geben kann. Diese Daten stammen aus verschiedenen Quellen, z. B. von Servern, Anwendungen, Datenbanken und Benutzerinteraktionen.
Datenspeicherung und Indizierung
Nachdem die Daten gesammelt wurden, müssen sie effizient gespeichert werden. Eine ordnungsgemäße Speicherung bedeutet, dass Sie die Daten bei Bedarf schnell finden und verwenden können. Die Indizierung der Daten hilft, bestimmte Informationen schneller zu suchen und abzurufen. Wenn beispielsweise ein Problem auftritt, sollten die Techniker in der Lage sein, die Protokolle oder Metriken zu diesem Vorfall ohne Verzögerung abzurufen. Gute Speichermethoden sind entscheidend für die Organisation und den Zugriff auf die Daten.
Datenvisualisierung und -analyse
Daten zu sammeln ist eine Sache, sie sinnvoll zu nutzen eine andere. Visualisierungswerkzeuge und Dashboards spielen hier eine wichtige Rolle. Sie verwandeln Rohdaten in leicht verständliche Grafiken, Diagramme und Warnmeldungen. Die Visualisierung hilft den Teams, Trends, Muster oder ungewöhnliches Verhalten im System schnell zu erkennen. Anhand von Dashboards lassen sich Leistungsprobleme leicht erkennen und Details aufschlüsseln, wenn etwas nicht in Ordnung zu sein scheint. Warnsysteme können Teams auch in Echtzeit benachrichtigen, wenn Messwerte bestimmte Schwellenwerte überschreiten oder Fehler auftreten.
Kontinuierliche Verbesserung
Die Daten aus der Beobachtung dienen nicht nur der Problembehebung, sondern auch der Verbesserung des Systems. Durch regelmäßige Überprüfung der gesammelten Daten können die Teams Bereiche ermitteln, die verbessert oder optimiert werden müssen. In der kontinuierlichen Feedbackschleife werden Verbesserungen vorgenommen, damit das System effizienter läuft. Die Daten zur Beobachtbarkeit können als Entscheidungshilfe für die Skalierung von Ressourcen dienen, was die Benutzerfreundlichkeit verbessert und zukünftige Probleme verhindert.
Anwendungsfälle von Observability
Observability hat einen starken Einfluss auf reale Anwendungen. Hier sind einige praktische Anwendungsfälle, die zeigen, wie Beobachtbarkeit einen Unterschied macht:
Leistungsüberwachung in verteilten Systemen
In einem verteilten System, in dem mehrere Dienste zusammenarbeiten, kann es schwierig sein, Leistungsprobleme zu erkennen. Observability hilft durch die Bereitstellung von Metriken, Protokollen und Traces, die ein klares Bild von der Interaktion der verschiedenen Dienste vermitteln. Wenn zum Beispiel ein einzelner Microservice die gesamte Anwendung verlangsamt, können Observability-Tools schnell aufzeigen, welcher Service die Verzögerung verursacht.
Debugging und Fehlerbehebung bei Fehlern
Wenn ein System ausfällt, müssen die Teams herausfinden, was schief gelaufen ist. Observability erleichtert diesen Prozess durch die Bereitstellung detaillierter Protokolle und Spuren von Ereignissen. Wenn beispielsweise ein Server abstürzt oder eine Anfrage fehlschlägt, können die Protokolle genau aufzeigen, was unmittelbar vor dem Fehler passiert ist. Anhand der Traces können die Teams erkennen, wie sich das Problem über verschiedene Dienste hinweg auswirkt.
Zuverlässigkeit und Verfügbarkeit
Die Beobachtbarkeit spielt eine große Rolle bei der Erfüllung von Service-Level-Zielen (SLOs) und Service-Level-Agreements (SLAs). Dabei handelt es sich um Zusagen darüber, wie zuverlässig und verfügbar ein System sein sollte. Durch die Verfolgung des Systemzustands anhand von Metriken und Warnmeldungen können Teams diese Ziele einhalten. Wenn sich beispielsweise die Antwortzeiten verlangsamen, können die Teams dank der Beobachtungsfunktion reagieren, bevor die Benutzer beeinträchtigt werden, und so einen zuverlässigen Dienst aufrechterhalten.
Kapazitätsplanung und Skalierung
Wenn Systeme wachsen, benötigen sie mehr Ressourcen wie Server oder Speicher. Die Beobachtbarkeit hilft bei der Kapazitätsplanung, indem sie Metriken verfolgt, die zeigen, wie das System genutzt wird. Die Überwachung der CPU-Nutzung oder der Datenbankauslastung über einen längeren Zeitraum hinweg kann beispielsweise dabei helfen, vorherzusagen, wann mehr Kapazität benötigt wird. Mit Kapazitätsplanung und Skalierung läuft das System gut und ohne Überraschungen.
Proaktive Erkennung von Problemen
Einer der besten Nutzen der Beobachtbarkeit besteht darin, Probleme zu erkennen, bevor sie zu großen Problemen werden. Durch Echtzeit-Überwachung und -Warnungen können Teams ungewöhnliche Muster oder Spitzen, wie erhöhte Fehlerraten oder Reaktionszeiten, erkennen. Durch diesen proaktiven Ansatz können Ausfallzeiten verhindert und eine reibungslose Benutzererfahrung gewährleistet werden. Wenn Observability-Tools beispielsweise ein Speicherleck frühzeitig erkennen, können Teams es beheben, bevor das System abstürzt.
Überwachung der Benutzerfreundlichkeit
Bei der Beobachtbarkeit geht es nicht nur um das Backend, sondern auch um die Überwachung von Benutzerinteraktionen und -verhalten. Die Überwachung von Metriken zur Benutzerfreundlichkeit wie Seitenladezeiten, Reaktionszeiten auf Schaltflächen und Fehlermeldungen hilft den Teams, Probleme mit dem Benutzer schnell zu erkennen und zu beheben. Wenn zum Beispiel eine neue Funktion dazu führt, dass Seiten langsamer geladen werden, zeigen die Observability-Daten dies sofort an.
Kostenoptimierung in Cloud-Umgebungen
In Cloud-Umgebungen wird oft nach dem Pay-as-you-go-Prinzip abgerechnet, d. h., Sie zahlen für die Ressourcen, die Sie nutzen. Observability kann Teams bei der Kostenoptimierung helfen, indem sie verfolgen, welche Teile des Systems die meisten Ressourcen verbrauchen. Wenn zum Beispiel ein bestimmter Microservice eine große Menge an Bandbreite verbraucht, können Observability-Tools dies aufzeigen, so dass das Team den Service optimieren oder überarbeiten kann, um die Kosten zu senken.
Tools und Technologien für Observabilität
Prometheus] (https://prometheus.io/) ist ein Open-Source-Überwachungstool, das Metriken als Zeitreihendaten sammelt und speichert. Durch seine flexiblen Abfragefunktionen wird es häufig zur Überwachung der System- und Anwendungsleistung eingesetzt.
Grafana ist ein Visualisierungstool, das häufig mit Prometheus kombiniert wird. Es erstellt interaktive Dashboards, die dabei helfen, Prometheus-Metriken zu visualisieren, Daten einfach zu interpretieren, Trends zu überwachen und Alarme für das Systemverhalten einzurichten.
Jaeger ist ein verteiltes Tracing-Tool, mit dem sich Anfragen verfolgen lassen, während sie durch Microservices fließen. Es hilft auch bei der Verfolgung von Latenzen und der Ermittlung von Engpässen in komplexen, verteilten Systemen.
AWS CloudWatch ist Amazons Überwachungs- und Beobachtungstool, das Metriken verfolgt, Protokolle sammelt und Warnmeldungen für AWS-Cloud-Ressourcen bereitstellt. Es lässt sich gut mit anderen AWS-Services integrieren, um Ihre Infrastruktur zu überwachen und zu verwalten.
Google Cloud Monitoring] (https://cloud.google.com/monitoring) bietet Einblick in Anwendungen und Dienste, die auf Google Cloud laufen. Es bietet Metriken, Dashboards und Warnmeldungen zur Überwachung des Zustands und der Leistung von Cloud-Ressourcen.
Azure Monitor](https://azure.microsoft.com/en-us/products/monitor) ist ein Tool, das vollständige Beobachtbarkeit von Azure-Cloud-Ressourcen und -Anwendungen bietet. Es sammelt Metriken, Protokolle und Traces, um Teams bei der Analyse der Leistung und der schnellen Behebung von Problemen zu unterstützen.
Moderne Observability-Tools nutzen KI und maschinelles Lernen, um Anomalien zu erkennen und zukünftige Probleme vorherzusagen. Diese fortschrittlichen Tools können automatisch Muster erkennen und Teams auf ungewöhnliches Verhalten hinweisen.
Herausforderungen für die Beobachtbarkeit
Skalierbarkeit und Datenvolumen
Das Sammeln, Speichern und Verarbeiten großer Mengen von Metriken, Protokollen und Traces kann in einem wachsenden System zu einer Herausforderung werden. Effizientes Datenmanagement und skalierbare Speicherlösungen sind der Schlüssel zur Bewältigung dieses Wachstums.
Datenüberlastung
Zu viele Daten können Teams überwältigen und es schwierig machen, nützliche Erkenntnisse zu gewinnen. Um Rauschen zu vermeiden, ist es wichtig, Daten zu filtern und sich auf verwertbare Daten zu konzentrieren, die direkt zur Diagnose und Lösung von Problemen beitragen, anstatt jedes kleine Detail zu verfolgen.
Integration über Dienste hinweg
Moderne Systeme verwenden oft mehrere Tools und Komponenten. Um die nahtlose Beobachtbarkeit dieser verschiedenen Dienste zu gewährleisten, ist eine angemessene Integration erforderlich. Andernfalls können kritische Informationen übersehen werden, und es wird viel Zeit mit dem Wechsel zwischen verschiedenen Tools verschwendet.
Best Practices zur Beobachtbarkeit
Um die Vorteile der Beobachtbarkeit optimal zu nutzen, sollten Sie die folgenden Best Practices befolgen:
Bauen mit Beobachtbarkeit im Hinterkopf
Entwerfen Sie Systeme von Anfang an so, dass sie leicht zu beobachten sind. Integrieren Sie Metriken, Protokolle und Traces in Ihre Architektur, um das Systemverhalten leichter verfolgen und verstehen zu können. Dieser proaktive Ansatz vereinfacht die künftige Fehlersuche und Leistungsoptimierung.
Einheitliche Ansicht über alle Systeme hinweg
Konsolidieren Sie alle Beobachtbarkeitsdaten in einer Plattform oder einem Dashboard. Eine einheitliche Ansicht hilft Teams, Probleme schnell zu erkennen und ein ganzheitliches Verständnis der Interaktion zwischen verschiedenen Diensten zu erlangen, wodurch der Zeitaufwand für die Zusammenstellung von Informationen aus verschiedenen Quellen reduziert wird.
Strategien für Alarmierung und Benachrichtigung
Richten Sie Warnmeldungen ein, die klar, aussagekräftig und umsetzbar sind. Vermeiden Sie Ermüdungserscheinungen, indem Sie sich nur auf kritische Ereignisse konzentrieren, die mit spezifischen, notwendigen Maßnahmen verbunden sind. Ziel ist es, das Team effektiv zu informieren und es nicht mit Lärm zu überfordern.
Beobachtbarkeit vs. Überwachung
Obwohl oft zusammen erwähnt, sind Beobachtbarkeit und Überwachung nicht dasselbe. Die nachstehende Tabelle zeigt die wichtigsten Unterschiede zwischen den beiden Begriffen:
| Beobachtung | Beobachtbarkeit | Überwachung |
|---|---|---|
| Zweck | Ermöglicht ein tieferes Verständnis des internen Zustands des Systems. | Verfolgt spezifische Metriken, um Probleme oder Anomalien zu erkennen. |
| Gesammelte Daten | Sammelt Metriken, Protokolle und Spuren für eine detaillierte Analyse. | Sammelt vordefinierte Metriken wie CPU-Nutzung, Speicher und Fehler. |
| Ansatz | Explorativ; hilft zu verstehen, "warum" ein Problem aufgetreten ist. | Reaktiv; benachrichtigt, wenn ein bekanntes Problem auftritt. |
| Umfang | Konzentriert sich auf das Gesamtsystemverhalten und Einblicke in die Leistung. | Konzentriert sich auf einzelne Metriken zur Messung des Systemzustands. |
| Problemlösung | Hilft, unbekannte Probleme und Grundursachen schnell zu identifizieren. | Weist auf bekannte Probleme hin, aber möglicherweise fehlt der Kontext für eine tiefere Analyse. |
| Echtzeitanalyse | Unterstützt die Datenanalyse in Echtzeit, um das Systemverhalten live zu verfolgen. | Verlässt sich auf voreingestellte Prüfungen und Schwellenwerte, oft mit verzögertem Kontext. |
| Datenflexibilität | Ermöglicht eine flexible, tiefgehende Untersuchung von Daten über vordefinierte Metriken hinaus. | Überwacht spezifische, vorausgewählte Metriken ohne breiteren Kontext. |
Unterschiede in der Beobachtbarkeit und Überwachung
Beobachtbarkeit in Milvus und Zilliz Cloud: Verfolgung der Leistung der Vektordatenbank
Milvus ist eine Open-Source-Vektordatenbank, die entwickelt wurde, um unstrukturierte Daten in Milliardengröße effizient zu verarbeiten. Sie ist ideal für semantische Suche, Ähnlichkeitssuche und GenAI Anwendungen. Die Beobachtbarkeit spielt eine entscheidende Rolle bei der Verwaltung und Optimierung der Leistung von Milvus. Mithilfe von Observability-Praktiken können Sie sicherstellen, dass Ihre Vektordatenbank reibungslos und effektiv läuft, sei es für Echtzeit-Empfehlungen oder Retrieval-augmented Generation (RAG) -Aufgaben.
Das Open-Source-Projekt Milvus integriert Prometheus zur Überwachung der Leistung und Grafana zur Visualisierung aller Metriken. Milvus lässt sich nahtlos mit Prometheus integrieren:
Prometheus Endpoint: Sammelt Daten von verschiedenen Exportern.
Prometheus-Bediener: Vereinfacht die Verwaltung von Prometheus-Überwachungskonfigurationen.
Kube-Prometheus: Vereinfacht die vollständige Überwachung von Kubernetes-Clustern für einen stabilen Betrieb.
Mit Prometheus können Sie kritische Metriken der Milvus-Leistung wie Abfrage-Antwortzeiten und Ressourcennutzung (CPU, GPU und Speicher) verfolgen und so proaktive Problemlösungen und Systemoptimierung ermöglichen. Darüber hinaus wird durch die Integration von Prometheus mit Grafana Ihr Überwachungs-Framework weiter verbessert, indem detaillierte Dashboards für eine eingehende Analyse und effiziente Wartung von Milvus-Bereitstellungen bereitgestellt werden, die auf GenAI und Ähnlichkeitssuche Anwendungen zugeschnitten sind.
Umfassende Anleitungen zur Einrichtung von Prometheus für Milvus und zur Visualisierung von Metriken mit Grafana finden Sie in den nachstehenden Ressourcen:
How to Spot Search Performance Bottleneck in Vector Databases using Prometheus and Grafana
Visualisierung von Milvus-Metriken mit Grafana | Milvus-Dokumentation
Zilliz Cloud ist die verwaltete Version von Milvus mit erweiterten Funktionen und 10x höherer Leistung. Sie bietet noch klarere und einfachere Überwachungs- und Beobachtungsfunktionalitäten. Zilliz Cloud hat kürzlich robuste Überwachungs- und Beobachtungsfunktionen eingeführt, um den Nutzern zu helfen, die Leistung der Vektordatenbank zu verfolgen. Das Metrics-Dashboard bietet einen Überblick über den Zustand des Clusters, einschließlich der Ressourcennutzung (CPU, Speicher, Storage), der Leistung (QPS, VPS, Latenzen) und der Datenmetriken (Collection und Entity Counts), die alle für eine tiefere Analyse angepasst werden können. Das Dashboard stellt die Metriken auf eine sehr intuitive Weise dar, um schnelle Einblicke zu ermöglichen.
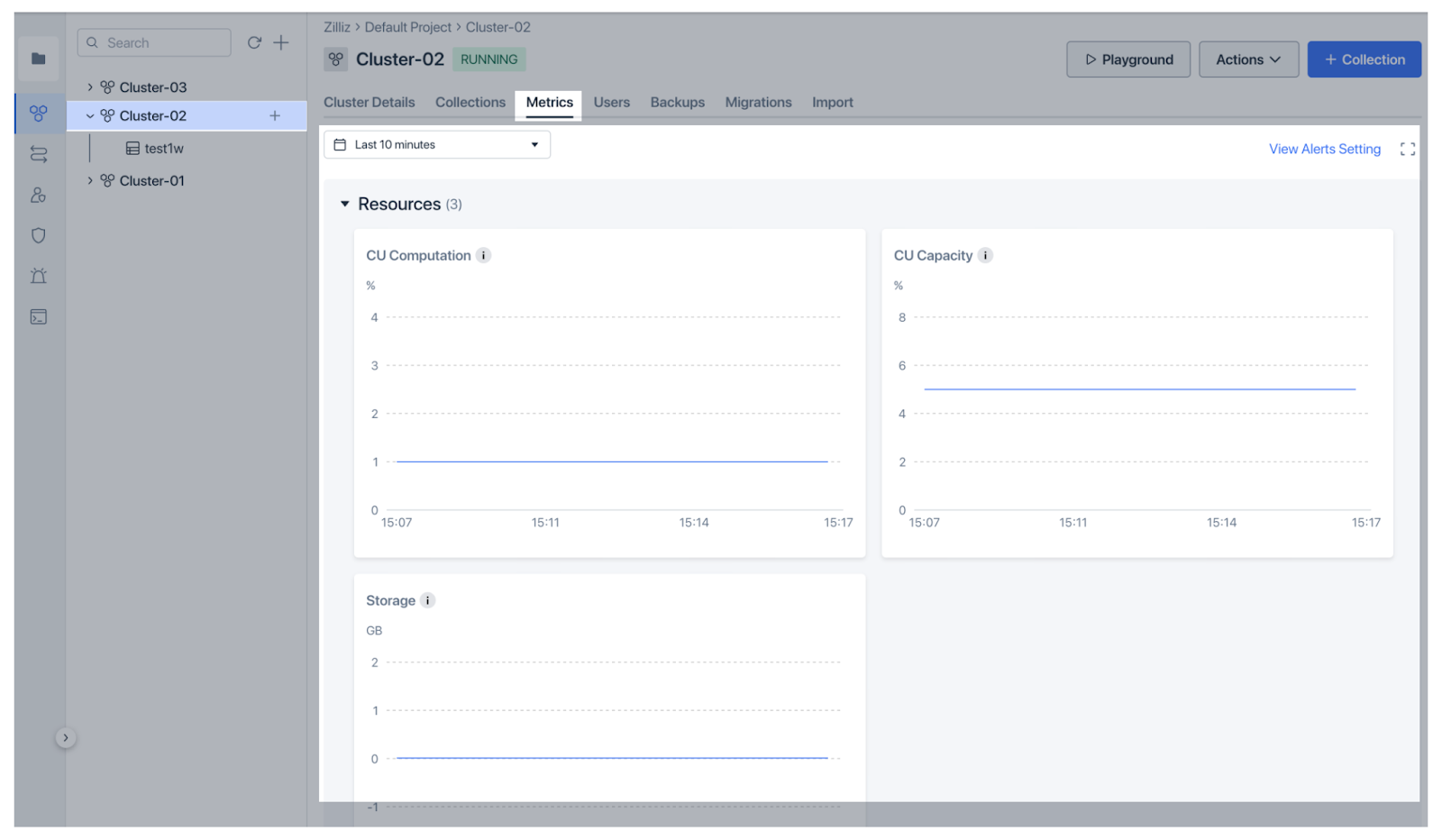 Abbildung: Zilliz Cloud Monitoring Metrics
Abbildung: Zilliz Cloud Monitoring Metrics
Abbildung: Zilliz Cloud Überwachung Metriken
Um Probleme frühzeitig zu erkennen, bietet Zilliz Cloud Organisationswarnungen für Abrechnungsfragen und Projektwarnungen für operative Faktoren wie CU-Nutzung und Latenz, mit flexiblen Schwellenwerten und Schweregradeinstellungen.
Abbildung: Organisationswarnungen in Zilliz Cloud (https://assets.zilliz.com/Figure_2_Screenshot_of_Organization_Alerts_493efb0dbc.png)
Abbildung: Organisationswarnungen in Zilliz Cloud
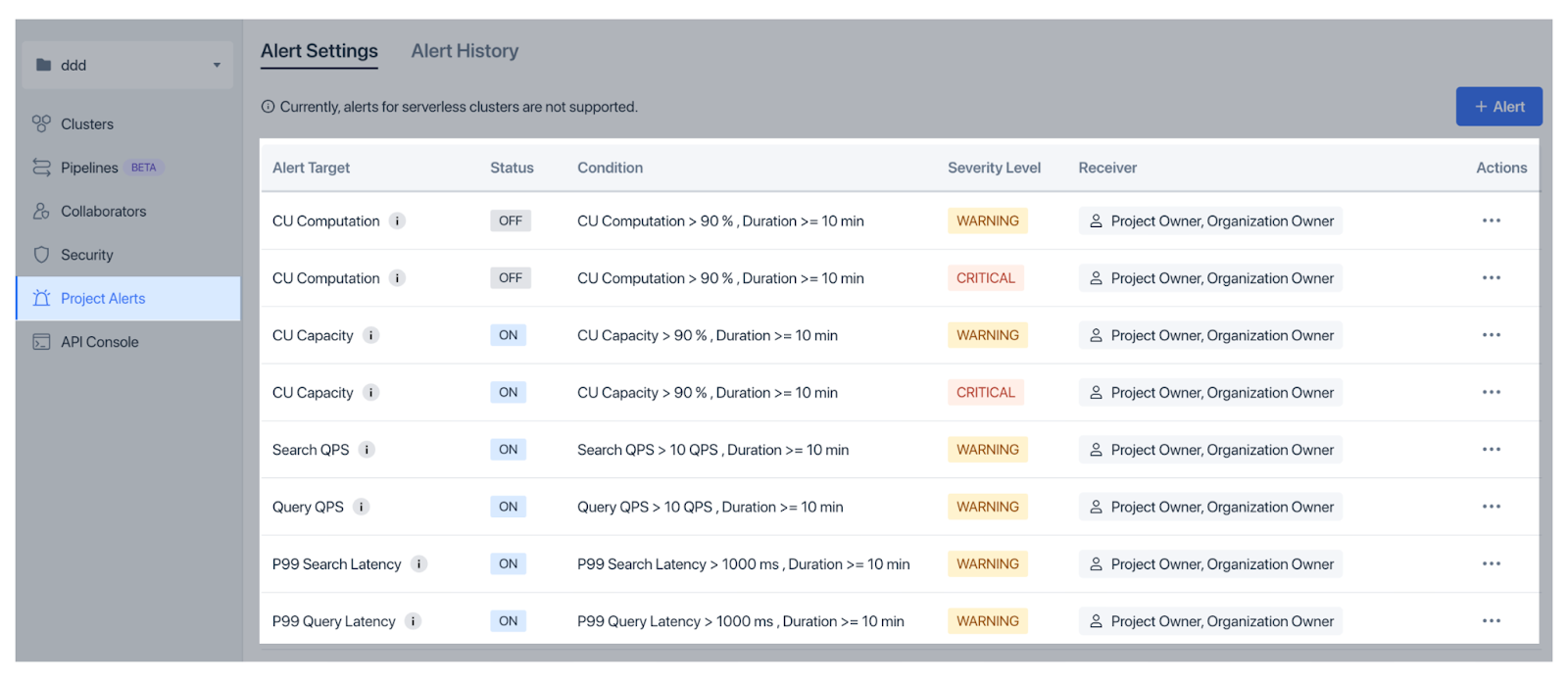 Abbildung: Projektwarnungen in der Zilliz-Cloud
Abbildung: Projektwarnungen in der Zilliz-Cloud
Abbildung: Projektwarnungen in der Zilliz-Cloud
Hauptmerkmale
Echtzeit-Monitoring für sofortiges Feedback zur Clusterleistung.
Anpassbare Dashboards, die auf Ihre wichtigsten Metriken zugeschnitten sind.
Flexible Alerts für die frühzeitige Erkennung potenzieller Probleme.
Mehrere Benachrichtigungskanäle (E-Mail, Slack, PagerDuty).
Historische Daten zur Analyse von Leistungstrends für die langfristige Planung.
Fazit
Observability ist ein Ansatz zum Verständnis und zur Erhaltung des Zustands moderner, komplexer Systeme. Mithilfe von Metriken, Protokollen und Traces können Teams eine zuverlässige Leistung sicherstellen, Probleme schnell beheben und das Benutzererlebnis verbessern. Da Systeme wachsen und sich weiterentwickeln, ist die Anwendung von Best Practices für die Beobachtbarkeit wichtig, um Problemen voraus zu sein und effizient zu skalieren. Ganz gleich, ob Sie verteilte Microservices ausführen oder KI-gesteuerte Anwendungen mit Tools wie Milvus entwickeln - Observability bietet die nötige Transparenz, damit alles reibungslos und zuverlässig läuft.
FAQs zu Observabilität
Was ist Observabilität und warum ist sie wichtig?** Observabilität ist die Praxis, den internen Zustand eines Systems durch das Sammeln und Analysieren von Daten wie Metriken, Protokollen und Traces zu verstehen. Sie ist wichtig für die Diagnose von Problemen, die Überwachung der Leistung und die Aufrechterhaltung der Systemzuverlässigkeit, insbesondere bei komplexen modernen Setups wie Microservices und Cloud-nativen Anwendungen.
Wie unterscheidet sich die Beobachtbarkeit von der Überwachung? Während die Überwachung bestimmte Metriken verfolgt, um Probleme zu erkennen, geht die Beobachtbarkeit tiefer, indem sie Einblicke in das "Warum" hinter diesen Problemen bietet. Die Überwachung ist wie eine Checkliste, während die Beobachtbarkeit eine umfassende Untersuchung des Systemverhaltens und -zustands darstellt.
Was sind die Kernkomponenten der Beobachtbarkeit? Die drei Säulen der Beobachtbarkeit sind Metriken (numerische Daten zur Systemleistung), Protokolle (detaillierte Ereignisaufzeichnungen) und Spuren (Pfade, die von Anfragen über Dienste hinweg genommen werden). Zusammen bieten sie einen umfassenden Überblick über den Zustand und die Leistung eines Systems.
Warum ist Beobachtbarkeit für verteilte Systeme unerlässlich? Verteilte Systeme, wie solche, die auf Microservices oder Cloud-Plattformen aufbauen, haben mehrere interagierende Komponenten. Beobachtbarkeit hilft bei der Überwachung und Fehlersuche in all diesen Komponenten und erleichtert die Verfolgung von Leistungsproblemen, die Ermittlung von Engpässen und die Aufrechterhaltung des Systemzustands.
Zusätzliche Ressourcen
- Einführung in die umfassende Überwachung und Beobachtbarkeit in der Zilliz Cloud](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
- Was ist Beobachtbarkeit?
- Warum ist Beobachtbarkeit wichtig?
- Die Grundpfeiler von Observability
- Wie funktioniert Observabilität?
- Anwendungsfälle von Observability
- Tools und Technologien für Observabilität
- Herausforderungen für die Beobachtbarkeit
- Best Practices zur Beobachtbarkeit
- Beobachtbarkeit vs. Überwachung
- Beobachtbarkeit in Milvus und Zilliz Cloud: Verfolgung der Leistung der Vektordatenbank
- Fazit
- FAQs zu Observabilität
- Zusätzliche Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren