




Verbessern Sie Ihre RAG mit Wissensgraphen unter Verwendung von KnowHow
Retrieval Augmented Generation (RAG) ist eine beliebte Technik, die dem LLM zusätzliches Wissen und Langzeitspeicher durch eine Vektordatenbank wie Milvus und Zilliz Cloud (das vollständig verwaltete Milvus) zur Verfügung stellt. Eine einfache RAG kann viele LLM-Probleme lösen, ist aber unzureichend, wenn Sie fortgeschrittenere Anforderungen haben, wie z. B. Anpassung oder größere Kontrolle über die abgerufenen Ergebnisse.
Bei unserem jüngsten Unstructured Data Meetup berichtete Chris Rec, der Mitbegründer von WhyHow, wie er Knowledge Graphs (KG) in die RAG-Pipeline einbindet, um die Leistung und Genauigkeit zu verbessern. Der Blog wird die wichtigsten Punkte seines Vortrags behandeln, einschließlich eines Überblicks über Knowledge Graphs, RAG und wie man Knowledge Graphs in RAG-Systeme integriert, um eine bessere Leistung zu erzielen.
Wenn Sie mehr über dieses Thema erfahren möchten, empfehlen wir Ihnen, sich den gesamten Vortrag auf [YouTube] (https://www.youtube.com/watch?v=6pjObdJdyFs) anzusehen.
Ein Überblick über die RAG und ihre Herausforderungen
RAG ist eine Methode, die die Stärken sowohl von Retrieval-basierten als auch von generativen künstlichen Intelligenzsystemen nutzt. Eine Vanilla RAG umfasst in der Regel eine Vektordatenbank wie Milvus, ein Einbettungsmodell und ein großes Sprachmodell (LLM).
Ein RAG-System verwendet zunächst das Einbettungsmodell, um Dokumente in Vektoreinbettungen umzuwandeln und sie in einer Vektordatenbank zu speichern. Dann ruft es relevante Abfrageinformationen aus dieser Vektordatenbank ab und liefert die abgerufenen Ergebnisse an das LLM. Schließlich verwendet der LLM die abgerufenen Informationen als Kontext, um genauere Ergebnisse zu erzeugen.
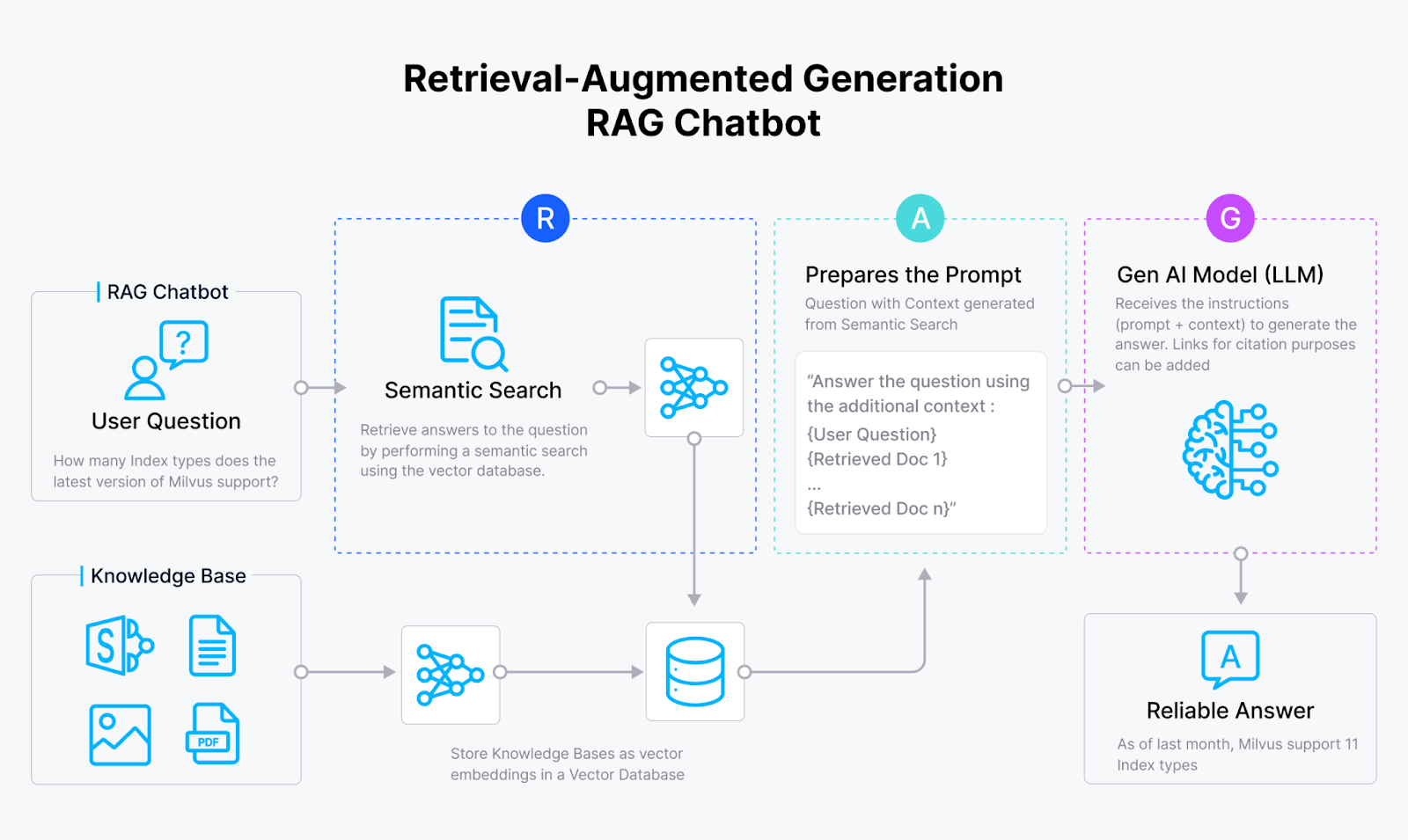 RAG-Arbeitsablauf
RAG-Arbeitsablauf
Abbildung 1: Wie RAG funktioniert
Auch wenn ein reines RAG wunderbar geeignet ist, um aktuellere und genauere Ergebnisse zu erzielen, hat es doch einige Einschränkungen.
Erstens können LLMs Schwierigkeiten haben, den spezifischen Kontext oder die Domäne einer Frage vollständig zu verstehen, was zu falschen oder irrelevanten Antworten führt. Zum Beispiel könnte sich der Begriff "Fahrzeugkapazität" entweder auf die Anzahl der Passagiere beziehen, die ein Auto aufnehmen kann, oder auf die Anzahl der Autos, die auf eine Straße passen, was zu Mehrdeutigkeit führt.
Zweitens ist es schwierig, verschiedene Abfragetypen korrekt zu behandeln. So unterscheidet sich die Beantwortung ortsbezogener Abfragen wie "Ich möchte nach London fahren" erheblich von der Beantwortung abstrakterer, wellnessbezogener Anfragen wie "Ich habe Stress auf der Arbeit und möchte Urlaub machen".
Drittens ist es nicht einfach, zwischen Ähnlichkeit und Relevanz zu unterscheiden. So kann es beispielsweise schwierig sein, zwischen einem "Strandhaus", das eine Meile von der Küste entfernt ist, und einem "Haus am Strand" direkt am Sand zu unterscheiden.
Viertens ist auch die Vollständigkeit der Antworten ein Problem. Das Abrufen aller relevanten Informationen für umfassende Fragen kann eine Herausforderung sein, insbesondere bei komplexen Abfragen, wie z. B. der Auflistung aller Kommanditisten (LPs) eines Fonds, die mindestens 10 Millionen Dollar investiert haben und über besondere Datenzugriffsrechte verfügen.
Multi-Hop-Abfragen schließlich bringen eine weitere Komplexitätsebene mit sich, da sie eine genaue Kombination mehrerer Informationen erfordern. Bei diesem Ansatz muss eine Abfrage in mehrere Unterabfragen mit jeweils spezifischen Bedingungen aufgeteilt werden, um sicherzustellen, dass die endgültige Antwort genau und vollständig ist.
Während Lösungen wie Prompt-Verbesserung, fortschrittliche Chunking-Strategien, bessere Einbettungsmodelle und Reranking viele der mit RAG verbundenen Herausforderungen angehen können, verfolgt WhyHow einen anderen Ansatz, indem es Wissensgraphen in die RAG-Pipeline einbezieht.
Was sind Knowledge Graphs (KGs)?
Ein Knowledge Graph (KG) ist eine Art von Datenstruktur, die nicht nur Daten speichert, sondern auch ähnliche oder unähnliche Daten auf der Grundlage ihrer Beziehung miteinander verbindet. Dieser Ansatz führt zu einer Sammlung von Dingen (die jede Art von Daten sein können), die auf eine Weise verknüpft sind, die verwandte oder relevante Informationen liefern kann.
Ein Knowledge Graph besteht aus Knoten, Kanten und Eigenschaften.
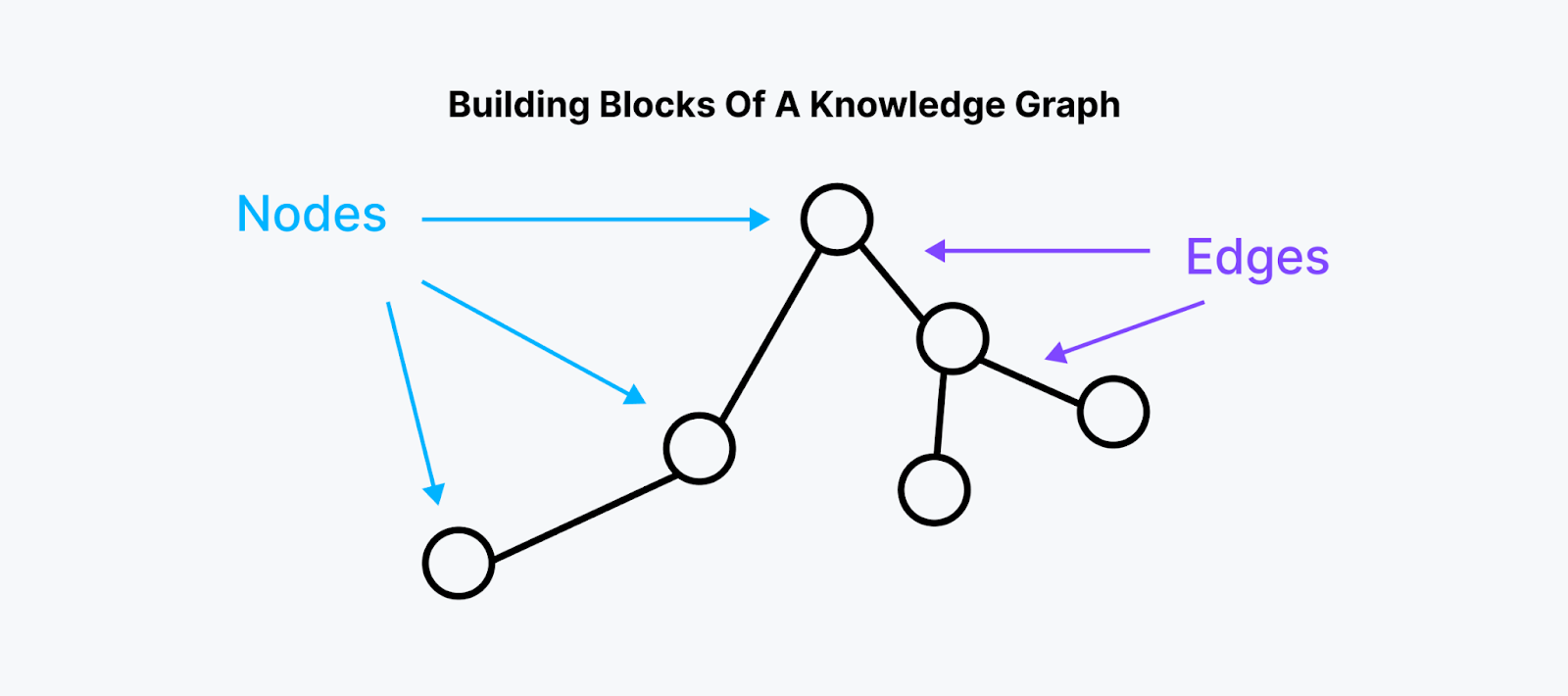 Abb. 2 - Bausteine eines Wissensgraphen
Abb. 2 - Bausteine eines Wissensgraphen
Abb. 2: Bausteine eines Wissensgraphen
Knoten:
Stellen die Entitäten oder Objekte im Graphen dar.
Die Speicherwerte dieser Entitäten können jede Art von Daten sein.
Edges:
Stellen die Beziehungen zwischen den Entitäten dar.
Sie enthalten Informationen über die Art der Beziehung zwischen den verbundenen Knoten.
Eigenschaften: Merkmale oder Eigenschaften, die mit einzelnen Entitäten verbunden sind.
Im Gegensatz zu herkömmlichen tabellarischen Datenbanken verwenden Wissensgraphen eine Graphenstruktur zur flexiblen Darstellung von Beziehungen und konzentrieren sich auf das semantische Verständnis. Dieser Ansatz ermöglicht komplexe Abfragen und eine einfachere Extraktion von spezifischen Informationen.
Vorteile der Integration von Wissensgraphen in RAG-Systeme
Durch die Integration von Wissensgraphen in die RAG-Pipeline können wir die Abfragemöglichkeiten des Systems und die Qualität der Antworten erheblich verbessern, was zu einer besseren Leistung, Genauigkeit, Nachvollziehbarkeit und Vollständigkeit führt. Hier sind die wichtigsten Vorteile eines wissensgraphenbasierten RAG-Systems:
Verbessertes kontextuelles Verständnis
Wissensgraphen bieten eine umfassende, vernetzte Darstellung von Informationen, die es dem RAG-System ermöglicht, komplexe Beziehungen zwischen Entitäten zu erfassen. Dieses tiefere kontextuelle Verständnis führt zu differenzierteren und relevanteren Antworten.
Verbesserte Genauigkeit und faktische Konsistenz
Die strukturierte Natur von Wissensgraphen trägt dazu bei, die faktische Konsistenz der generierten Inhalte aufrechtzuerhalten. Durch die Verankerung von Antworten auf verifizierte Informationen innerhalb des Graphen kann das System Fehler und Halluzinationen reduzieren, die bei herkömmlichen Sprachmodellen üblich sind.
Multi-hop Reasoning-Fähigkeiten
Wissensgraphen ermöglichen dem RAG-System Multi-Hop-Reasoning, d. h. die Verknüpfung unterschiedlicher Informationen über logische Pfade. Diese Fähigkeit ermöglicht eine anspruchsvollere Beantwortung von Anfragen und die Generierung von Schlussfolgerungen.
Effiziente Informationsbeschaffung
Die Graphenstruktur erleichtert den schnellen und präzisen Abruf von Informationen, selbst bei komplexen Abfragen. Diese Effizienz führt zu schnelleren Antwortzeiten und zur Generierung relevanterer Inhalte. Darüber hinaus ermöglichen auf Wissensgraphen basierende RAG-Systeme einen hybriden Retrieval-Ansatz, bei dem Graphentraversal mit [Vektor- und Schlüsselwortsuche] (https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus) kombiniert wird, Fähigkeiten, die von Vektordatenbanken wie Milvus und Zilliz Cloud bereitgestellt werden.
Um genauer zu sein, ermöglicht dieser hybride Ansatz:
Präziser Abgleich von Entitäten und Beziehungen durch Graph Traversal
Traditionelle schlagwortbasierte Suche für textlastige Inhalte
Diese vielschichtige Suchstrategie verbessert die Fähigkeit des Systems, die relevantesten Informationen über verschiedene Datentypen und -strukturen hinweg zu finden, was zu umfassenderen und genaueren Antworten führt.
Transparente und nachvollziehbare Ergebnisse
Mit Wissensgraphen kann das System die Herkunft der Informationen, die bei der Erstellung von Antworten verwendet werden, eindeutig nachweisen. Diese Nachvollziehbarkeit stärkt das Vertrauen der Benutzer und erleichtert die Überprüfung der Fakten.
Domänenübergreifende Wissenssynthese
Durch die Darstellung verschiedener Domänen in einer einzigen Graphenstruktur können wissensgraphenbasierte RAG-Systeme leichter Informationen aus verschiedenen Bereichen zusammenführen, was zu umfassenderen und interdisziplinären Erkenntnissen führt.
Verbesserte Handhabung von Mehrdeutigkeit
Die relationale Struktur von Wissensgraphen hilft bei der Eindeutigkeit von Entitäten und Konzepten und verringert die Verwirrung in Situationen, in denen Begriffe oder Namen mehrere Bedeutungen oder Referenzen haben können.
Durch die Nutzung dieser Vorteile können RAG-Anwendungen, die mit Wissensgraphen erweitert wurden, genauere, kontextuell relevante und umfassende Antworten auf Benutzeranfragen geben.
Was ist WhyHow? Wie verbessert es RAG mit Wissensgraphen?
[WhyHow] (https://www.whyhow.ai/) ist eine Plattform für den Aufbau und die Verwaltung von Wissensgraphen zur Unterstützung komplexer Datenabfragen. Die Konstruktion umfassender Wissensgraphen ist anspruchsvoll und zeitaufwändig. WhyHow löst dieses Problem, indem es kleine KGs erstellt und diese mehrfach durchläuft, bis ein zufriedenstellender KG für eine bestimmte Domäne entstanden ist. Dieser Ansatz trägt dazu bei, dass KGs hochgradig domänenspezifisch, einfacher und leicht zu handhaben sind, da KGs komplex sind.
WhyHow bietet Entwicklern auch die Bausteine, um unstrukturierte Daten zu organisieren, zu kontextualisieren und zuverlässig abzurufen, um komplexe RAG durchzuführen. Durch die Integration von WhyHow in Ihre bestehenden RAG-Pipelines, die auf einer Vektordatenbank basieren, können Sie Ihr RAG-System besser strukturieren, konsistenter gestalten und kontrollieren. Das folgende Diagramm zeigt, wie eine Knowledge Graph-gestützte RAG funktioniert.
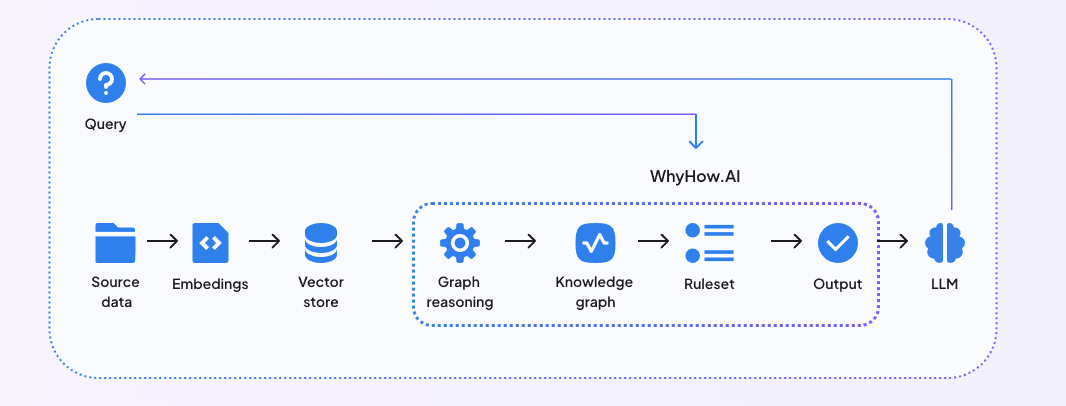 Abb. 3 - Integration von RAG mit WhyHow
Abb. 3 - Integration von RAG mit WhyHow
Abb. 3: Integration von RAG mit WhyHow
Durch die Integration von WhyHow in Ihren RAG-Workflow können Sie einen hybriden Graphen- und Vektoransatz verfolgen, indem Sie das Beste aus den Wissensgraphen und den Vektorsuchfunktionen von Vektordatenbanken nutzen.
Für eine detailliertere Anleitung, wie man eine Knowledge Graph-erweiterte RAG mit WhyHow aufbaut, empfehlen wir Ihnen die Live-Demo, die Chris während des von [Zilliz] veranstalteten Unstructured Data Meetup geteilt hat(https://zilliz.com/).
Mehr Kontrolle über Ihre Retrieval Workflows innerhalb von RAG mit WhyHow und Zilliz Cloud
Viele Entwickler möchten nicht nur die Leistung und Nachvollziehbarkeit von RAG-Anwendungen verbessern, sondern auch eine bessere Kontrolle über die von RAG abgerufenen Daten haben. Der Grund dafür ist, dass RAG-Anwendungen manchmal nicht in der Lage sind, konsistent die richtigen Daten abzurufen, wenn Benutzer schlecht formulierte Abfragen senden oder wenn Benutzer kontextuell relevante, aber semantisch unähnliche Daten in die Antworten aufnehmen müssen.
Um solche Probleme zu lösen, baut WhyHow ein Rule-based Retrieval Package durch Integration mit Zilliz Cloud. Dieses Python-Paket ermöglicht es Entwicklern, präzisere Retrieval-Workflows mit fortschrittlichen Filterfunktionen zu erstellen, wodurch sie mehr Kontrolle über den Retrieval-Workflow innerhalb der RAG-Pipelines erhalten. Dieses Paket integriert sich mit OpenAI für die Texterstellung und Zilliz Cloud für die Speicherung und effiziente Vektorähnlichkeitssuche mit Metadatenfilterung.
Die regelbasierte Retrieval-Lösung führt diese Aufgaben aus:
Erstellung eines Vektorspeichers: Erstellt eine Milvus-Sammlung zur Speicherung von Chunk-Einbettungen.
Splitting, Chunking, und Embedding: Teilt, chunked und erstellt automatisch Embeddings für hochgeladene Dokumente mit LangChains PyPDFLoader und RecursiveCharacterTextSplitter und unterstützt OpenAIs text-embedding-3-small-Modell.
Dateneinfügung: Hochladen von Einbettungen und Metadaten in Milvus oder Zilliz Cloud.
Automatische Filterung: Erstellt einen Metadatenfilter auf der Grundlage benutzerdefinierter Regeln, um Abfragen gegen den Vektorspeicher zu verfeinern.
Der Arbeitsablauf ist wie folgt:
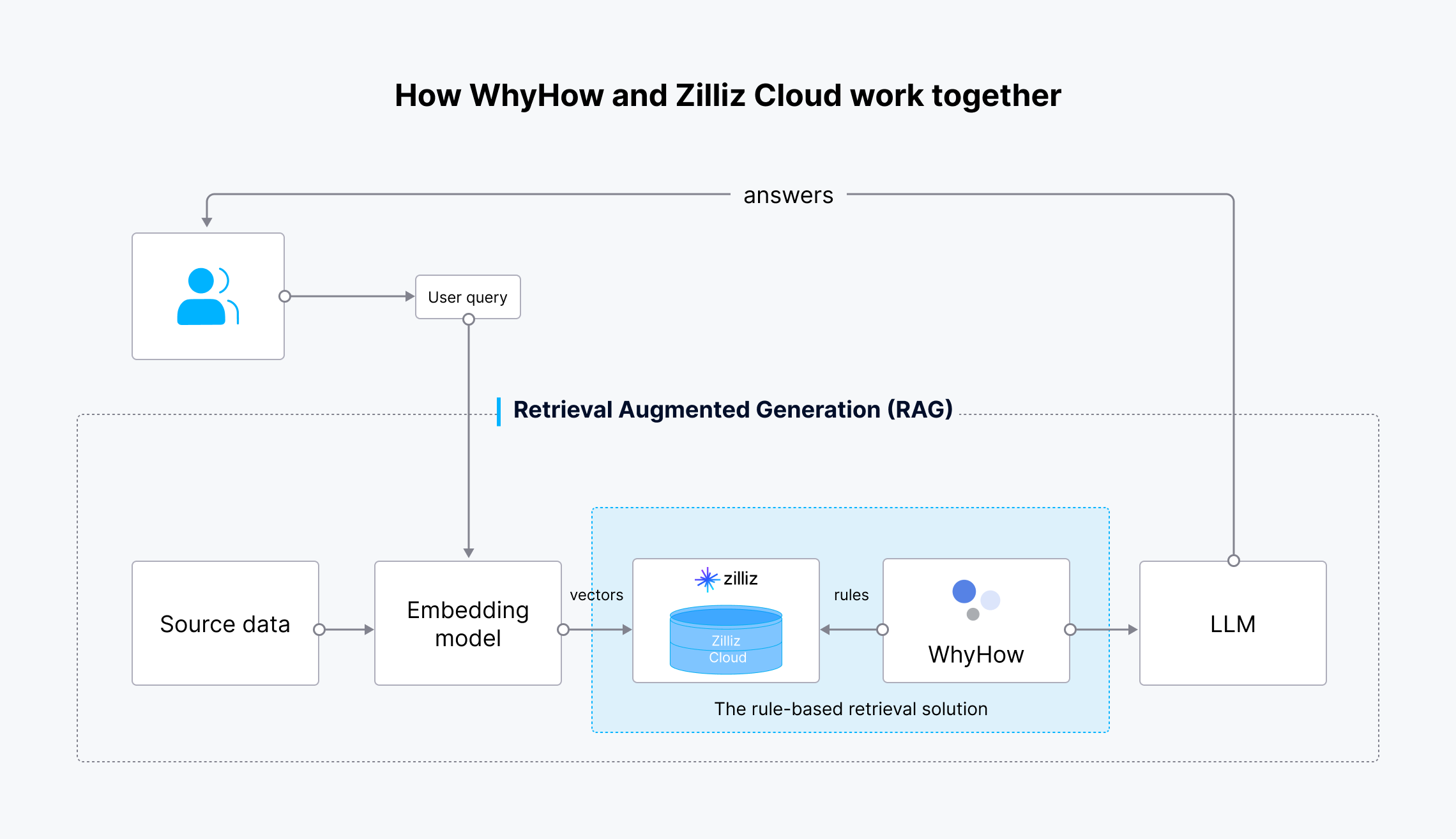 Wie WhyHow und Zilliz Cloud zusammenarbeiten
Wie WhyHow und Zilliz Cloud zusammenarbeiten
Abb. 4: Arbeitsablauf der regelbasierten Retrieval-Lösung
Die Quelldaten werden mit Hilfe des Einbettungsmodells von OpenAI in Vektoreinbettungen umgewandelt und in die Zilliz Cloud zur Speicherung und zum Abruf übertragen. Wenn eine Benutzeranfrage gestellt wird, wird sie ebenfalls in Vektoreinbettungen umgewandelt und an die Zilliz Cloud gesendet, um nach den relevantesten Ergebnissen zu suchen. WhyHow legt Regeln fest und fügt der Vektorsuche Filter hinzu. Die abgerufenen Ergebnisse werden dann zusammen mit der ursprünglichen Benutzeranfrage an den LLM gesendet, der genauere Ergebnisse generiert und sie an den Benutzer sendet.
Schlussfolgerung
LLM hat uns bei der Suche nach Antworten auf verschiedene Probleme wirklich entlastet. Sie sind intelligent genug, um die gestellte Anfrage zu verstehen, aber sie halluzinieren, und es ist schwierig, sie aufgrund von Ressourcenbeschränkungen auf dem neuesten Stand zu halten. Die RAG-Technik (Retrieval Augmented Generation) unterstützt sie daher, indem sie der Abfrage einen Kontext verleiht; allerdings haben RAG-Systeme, wie bereits erwähnt, auch ihre Grenzen.
WhyHow hat diese Grenzen aufgezeigt und betont, dass die Lösung in der Integration von Wissensgraphen in RAG-Pipelines liegt. Durch die Erweiterung von RAG mit Wissensgraphen können Ihre RAG-Systeme relevantere und kontextbezogene Informationen abrufen und besser bestimmbare Antworten mit weniger Halluzinationen und hoher Genauigkeit generieren.
Wenn Sie tiefer in dieses Thema eintauchen möchten, sehen Sie sich [Chris' Präsentation auf YouTube] (https://www.youtube.com/watch?v=6pjObdJdyFs) an.
Weitere Ressourcen
Wie Sie die Leistung Ihrer RAG-Pipeline verbessern können](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Optimierung von RAG mit Rerankern: Die Rolle und die Kompromisse](https://zilliz.com/learn/optimize-rag-with-rerankers-the-role-and-tradeoffs)
Vollständige RAG: Eine moderne Architektur für Hyperpersonalisierung](https://zilliz.com/blog/full-rag-modern-architecture-for-hyperpersonalization)
Erstellung intelligenter RAG-Anwendungen mit LangServe, LangGraph und Milvus](https://zilliz.com/blog/build-intelligent-rag-with-langserve-langgraph-and-milvus)
Aufbau von RAG mit selbstverteilten Milvus und Snowpark Container Services](https://zilliz.com/blog/build-rag-with-self-deployed-milvus-vector-database-and-snowpark-container-service)
DSPy und seine Integration mit Milvus zur Erstellung hocheffizienter RAG-Pipelines](https://zilliz.com/blog/exploring-dspy-and-its-integration-with-milvus-vector-database-for-RAG)

Weiterlesen

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.