Harnessing the Power of RAG with Milvus for Troop's Shareholder Activism

Scale
effortlessly
Enhance
unstructured data retrieval
Cost-effective
infrastructure
I can set up Milvus for scale in an hour, not overthinking it, and have a clear architecture path forward to grow my use case much larger without having to redo everything.
Zen Yui
About Troop
Troop is active in the shareholder activism and engagement sector, using technology to build a collaborative environment. Its platform connects shareholders with similar values and interests, allowing them to join or start activism campaigns. Over the past year, Troop has built a community, managing a collective stock portfolio valued between $20 to $30 million, with over 2,500 members. Troop was inspired by coordinated financial movements like WallStreetBets, the GameStop saga, and Engine No.1’s activism against ExxonMobil.
Troop provides a digital space for shareholders to come together, discuss, and act. Their platform encourages dialogue and drives actionable shareholder campaigns, bridging the gap between shareholders and corporate executives. Troop plays an active role in the evolving landscape of shareholder engagement by integrating technology with activism. Their efforts contribute to a shift towards a more inclusive and proactive shareholder ecosystem.
Unraveling Complex Data Streams: Troop's Technological Hurdle
Troop aimed to use Retrieval Augmented Generation (RAG) to identify relevant activism opportunities from a vast SEC database. Initially, using LangChain for PDF parsing, Question/Answer, and FAISS for vector search seemed promising. However, handling thousands of securities, each with numerous SEC filings annually, and the critical context needed for voting in company meetings revealed FAISS's limitations, especially its requirement to fit the entire vector collection into memory.
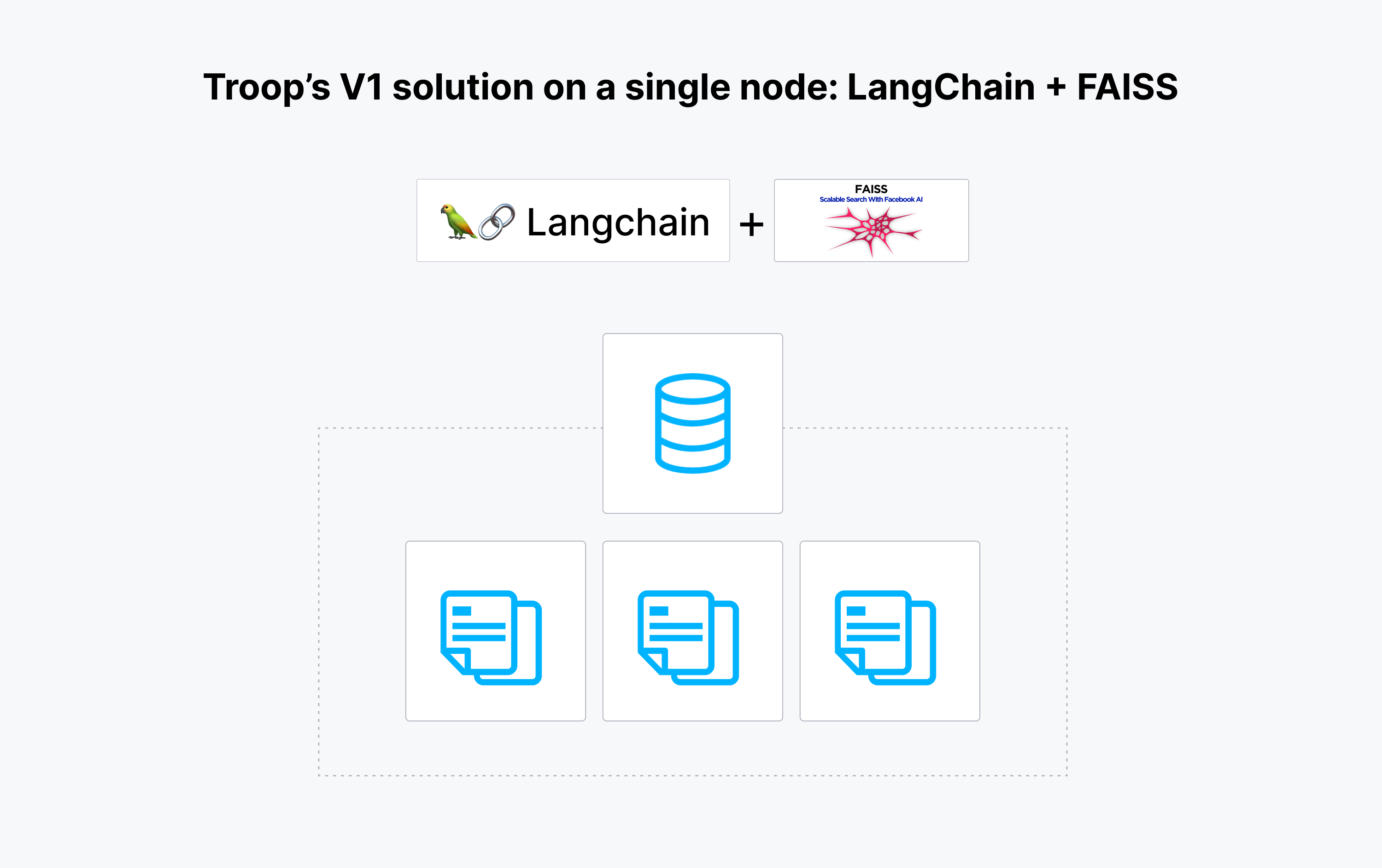
The data volume was too large to manage in memory, and the LangChain and FAISS setup couldn't offer the scalability and production readiness required for personalized voting recommendations. Troop sought a scalable, self-hosted solution to keep up with the growing user base and data volumes without escalating costs. The technical bottleneck emerged from the existing setup, highlighting the need for a robust vector database solution capable of efficiently handling high-dimensional data and decoupling compute from storage, ensuring streamlined data retrieval—a critical requirement for Troop's evolving operational demands.
Solutions: Optimized Vector Data Handling with Milvus
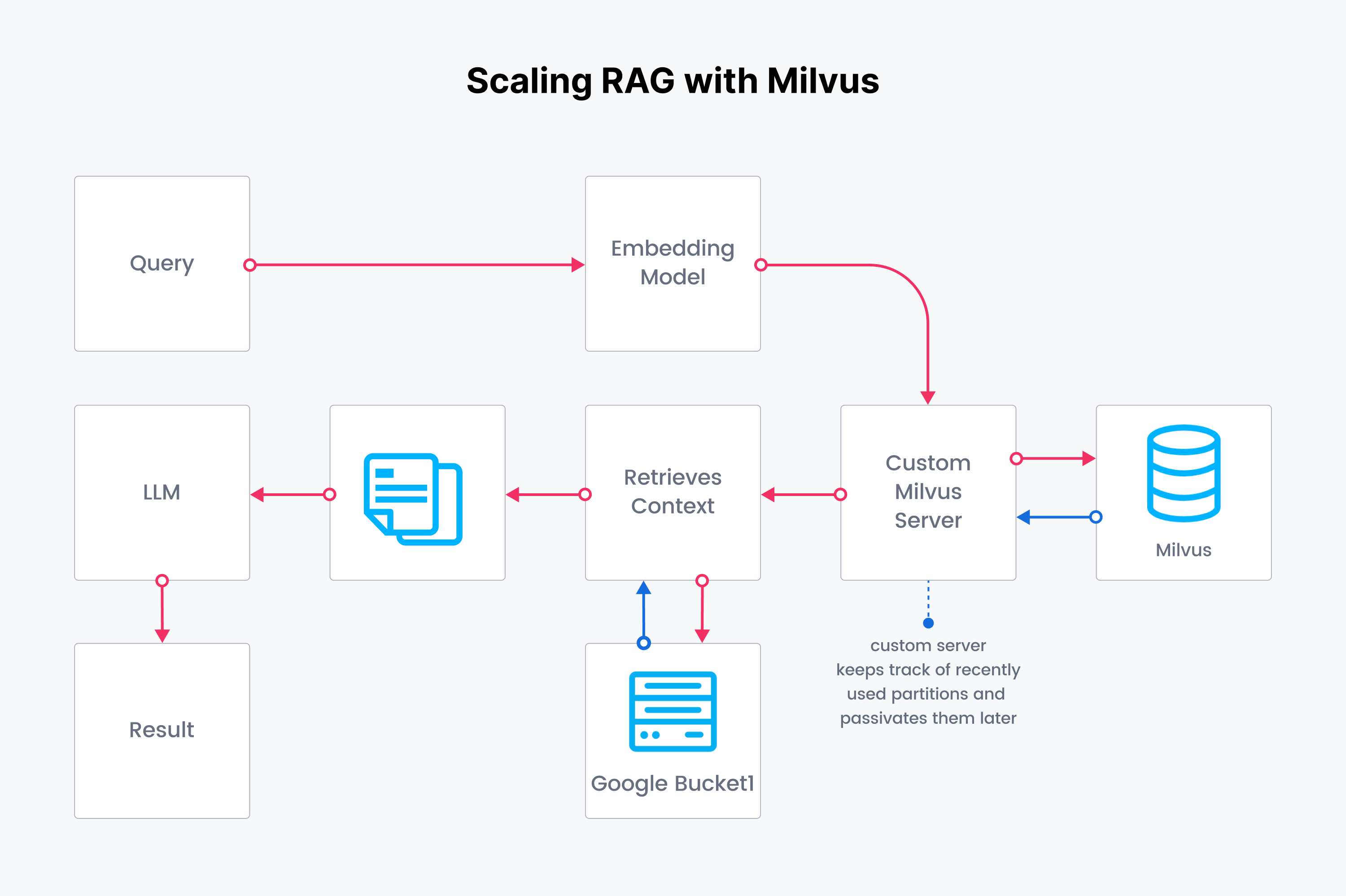
Troop found Milvus while searching for a production-ready vector database. Milvus efficiently managed large-scale data for improved semantic search capabilities. A significant feature was Milvus's ability to separate storage from compute, which was crucial for Troop's data volume. This separation allowed for vector embedding the entire corpus before usage while only loading necessary records into memory, significantly reducing computational overhead and maintaining system responsiveness, even as the data volume increased.
The challenge of scaling nodes as the queries increased was another concern. Milvus's inherent scalability ensured that as the demand for data retrieval surged, the system could scale out to meet these demands without a hitch. This problem was particularly crucial in Troop's environment, where self-hosting and scaling via Kubernetes was paramount. Unlike conventional setups, Milvus's architecture ensured smooth, scalable operations, aligning well with Troop's bursty onboarding process.
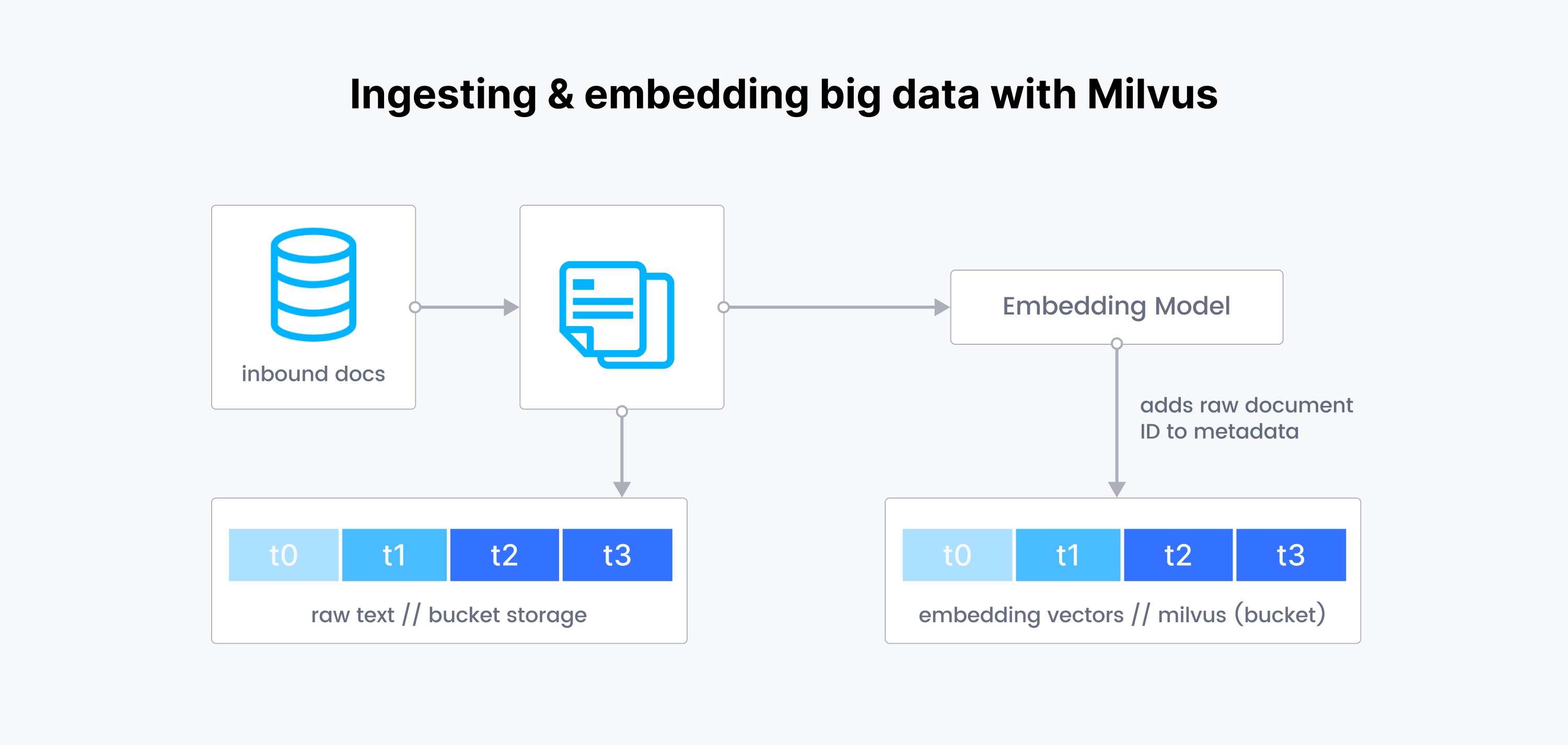
Troop's approach to data management mirrored the concept of handling a data lake. By ingesting new SEC filings and partitioning the raw payloads by time, they could chunk each page and write them into a bucket. Similarly, the embeddings were partitioned by time, targeting specific partitions when needed. This method not only streamlined data retrieval but also showcased the potential of Milvus in big data scenarios. The ability to split data into isolated partitions and control access to each partition for specific Milvus clients demonstrated Milvus' flexibility and adaptability in tackling real-world data challenges, setting a solid foundation for Troop's evolving operational needs.
Scaling with Precision and Ease
Milvus has been crucial in Troop's efficient management of growing data volumes. Integrating Milvus laid down a scalable GenAI infrastructure and facilitated a successful recommendation engine, connecting shareholders with relevant activism campaigns.
Zen Yui, Co-founder and CTO of Troop appreciates the scalability of Milvus. Yui mentioned, "We could drop a hundred times the amount of data tomorrow, and there's a clear path to modify our partitioning and indexes to accommodate that." This sentiment is also reflected in the operational ease experienced: "I can set up Milvus for scale in an hour, not overthink it, and have a clear architecture path forward to grow my use case much larger without having to redo everything."
The nuanced partitioning and indexing schemes of Milvus align seamlessly with Troop's B2B product requirements, catering to an expanding user base and the continuous influx of data from SEC filings. As commended by the team, the partition-by-time and partition-by-customer capabilities present a scalable, straightforward approach to managing diverse data streams. With Milvus, Troop is well-poised to navigate the dynamic landscape of data management and real-time recommendations, ensuring a resilient, future-ready infrastructure that resonates with the evolving demands of the market and the stakeholders.
Future Plan: Advancing Data Democracy with Embeddings
Troop envisions utilizing embeddings to propel data democratization, with Milvus being the cornerstone of this vision. They plan to use advanced models like GPT-4 for evaluating and training more cost-effective models, thereby increasing the accessibility to their extensive data. They aim to apply embedding and semantic search across various data types, including user level, usage, and sentiment data. Milvus' scalability and real-time capabilities are crucial as Troop plans to extend this data access. By segregating expensive foundation model evaluations from cheaper, fine-tuned, or custom-trained models, Troop aims to optimize computational resources while preserving the quality of insights.
An intriguing aspect of Troop's plan is to leverage embeddings to unlock their data lake's potential, filled with information from various sources. The goal is to provide their team, and potentially their user base, with the tools to explore this data lake efficiently. By developing applications atop Streamlit, Troop has begun bridging the gap between unstructured text and structured data, enabling custom RAG pipelines. This approach empowers their team to extract valuable insights and run custom RAG pipelines to process the data further.
Troop sees Milvus as a vital part of their infrastructure to explore and expand on these ideas, allowing for ease of use and the capability to scale as their user base grows.