




How TAL Education Group Scales AI-Powered Learning with Milvus

Millisecond semantic search
Instant retrieval across billions of vectors, replacing slow fuzzy matching
Higher grading accuracy
More precise semantic understanding for open-ended and multimodal student responses
Stronger recommendation quality
High-recall vector search surfaces relevant content that keyword search misses
End-to-end speedups
Faster grading, retrieval, and recommendation pipelines with reduced overall latency
About TAL Education Group
TAL Education Group (NYSE: TAL) is one of Asia’s leading education technology companies, serving millions of students and families. Founded in 2003 and listed on the New York Stock Exchange in 2010, TAL has grown from its Xueersi tutoring business into a broad portfolio of digital learning products—including Xueersi.com, Xueersi Smart Devices, MathGPT, and other technology-driven education brands—all designed to support students at home and in digital classroom environments.
As TAL expanded deeper into AI-driven learning—spanning personalized tutoring, automated grading, content recommendation, and multimodal knowledge retrieval—the company needed a new data infrastructure capable of supporting these compute-intensive workloads at scale. By choosing Milvus as the foundation for its vector retrieval platform, TAL gained the performance, scalability, and flexibility required to power faster grading, more accurate recommendations, and more intelligent semantic search across its products. Milvus now plays a key role in supporting TAL’s broader mission: delivering high-quality, technology-powered learning experiences that are accessible, efficient, and effective for every student.
Challenges Facing TAL’s AI-Powered Learning Systems
TAL is deploying AI across several core teaching scenarios—automated grading, learning-resource recommendations, and vector-based document retrieval. But as these services scaled, the company quickly reached the limits of traditional data systems. Modern online education generates massive volumes of complex, multimodal content, while AI-powered grading requires both high throughput and a deep understanding of student responses. These pressures surfaced structural issues that legacy infrastructure simply couldn’t address.
1. Explosive Growth of Multimodal Data
TAL processes hundreds of thousands of new questions and answers every day across subjects, grade levels, and formats, including images, diagrams, and handwritten formulas. This constant influx of data pushes traditional databases beyond their capacity to index and retrieve data efficiently. As TAL’s digital learning platforms grow, the backend must seamlessly scale to support rising storage demands, high-throughput vector retrieval, and sudden traffic spikes during exams and peak learning periods, all without compromising performance or availability.
2. Operational Inefficiencies in the Grading Pipeline
Human grading cannot keep up with the scale of modern online learning. A single test can take a teacher 15–20 minutes to evaluate, and subjective questions often yield inconsistent scoring across graders. At TAL’s scale, this results in grading bottlenecks and consumes valuable teacher time that could be redirected toward personalized instruction.
Additionally, TAL maintains a vast library of explanations, solutions, and learning materials—but these assets are scattered across systems. Without intelligent retrieval, high-quality resources remain underutilized, creating gaps between content creation and real learner needs.
3. High Accuracy Requirements for AI-Powered Feedback
AI grading must do more than match keywords—it must understand meaning. TAL’s systems need to identify semantic equivalence, interpret diverse phrasing, and score students fairly and consistently. Any explanations generated must be accurate, pedagogically sound, and age-appropriate. To support this, TAL requires a robust knowledge graph that links each question to the appropriate concepts and maps their relationships. Traditional systems are not designed to support this level of semantic reasoning at scale.
Powering TAL’s AI Grading and Learning Systems with Milvus
As TAL scaled its AI-driven grading and learning services, it needed a vector infrastructure capable of supporting massive embedding workloads with high accuracy and real-time responsiveness. After evaluating multiple solutions, TAL selected Milvus as the core engine of its vector data platform.
On top of Milvus, TAL built a modular architecture that ensures high data quality, seamless integration with applications, and continuous system improvement.
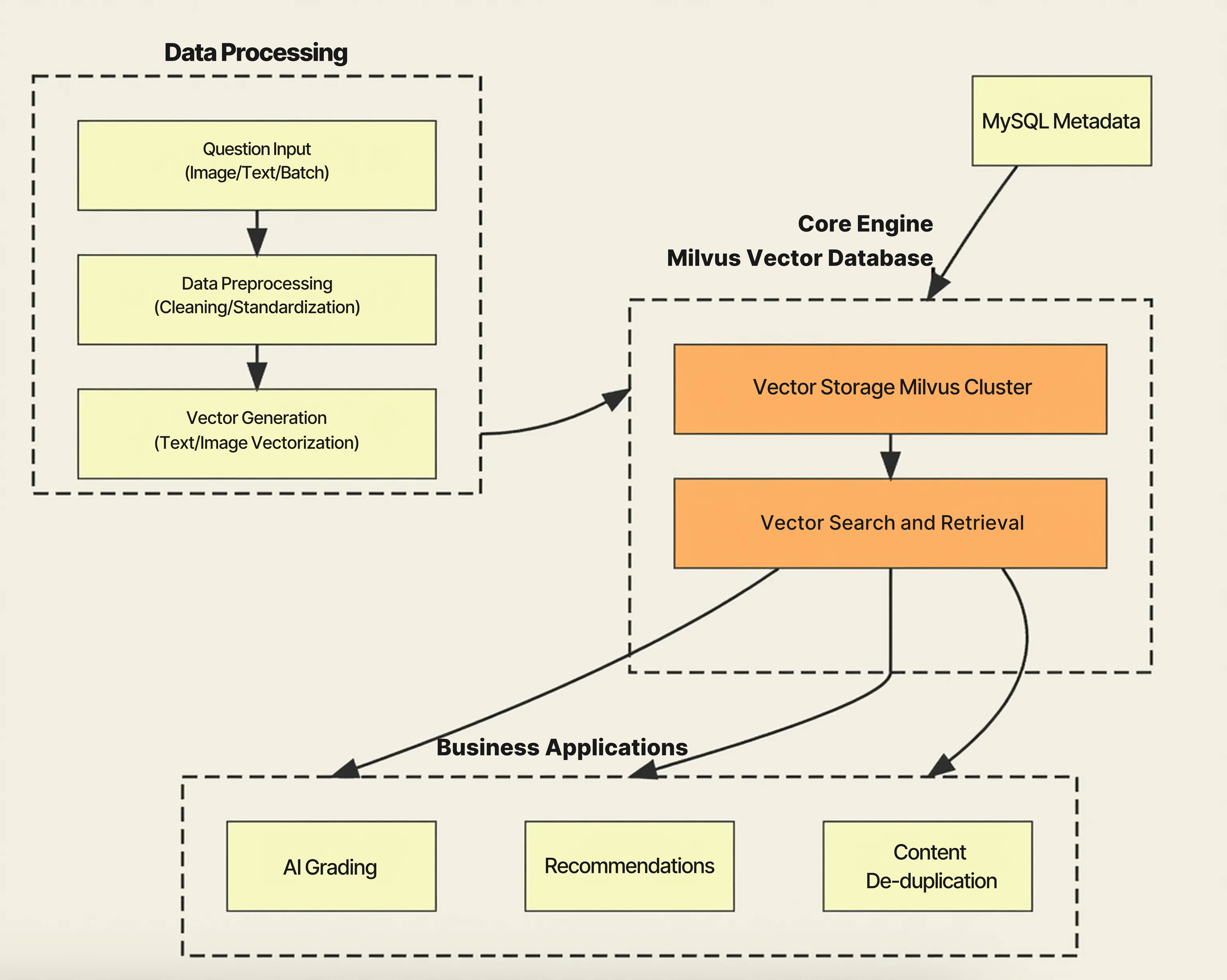
Data Processing Pipeline: Clean, Consistent, Vector-Ready Data
TAL’s data processing pipeline forms the foundation of the entire system. Questions, answers, and learning materials are ingested from multiple sources—including APIs, batch uploads, and OCR extraction from images or handwriting. Once ingested, all content goes through normalization, feature extraction, and quality checks before being transformed into vector embeddings. This pipeline ensures that everything stored in Milvus is clean, consistent, and optimized for high-quality semantic retrieval.
Milvus Vector Database: High-Performance Retrieval at Billion-Scale
At the heart of TAL’s architecture is the Milvus Vector Database, which delivers billion-scale vector storage and high-performance semantic search. Milvus’ distributed architecture and Approximate Nearest Neighbor (ANN) indexing allow TAL to serve similarity queries in milliseconds—even across hundreds of millions to billions of embeddings. The multi-index strategy of Milvus helps TAL balance speed and accuracy, while MySQL stores structured metadata such as versioning and index mappings. This keeps vector data and relational data tightly synchronized.
Today, this Milvus deployment manages 1B+ vectors across 20+ collections, with a single cluster handling millions of retrieval requests per day.
Application Services: Turning Vector Retrieval Into Educational Impact
The application services layer turns Milvus’ capabilities into real educational impact.
AI Grading: Uses semantic similarity to evaluate student answers and generate explanations.
Recommendations: Finds similar questions tailored to a student’s learning level and progress.
Content De-duplication: Detects repetitive or redundant content to maintain question bank quality.
Each service depends on Milvus’ ability to deliver fast, accurate retrieval at scale—ensuring students and educators receive timely, personalized, and consistent results.
Quality Evaluation Framework: A Closed Loop for Continuous Improvement
To maintain reliability at scale, TAL built a continuous quality evaluation framework across the system. Each AI-generated grading result receives a confidence score based on semantic similarity, historical performance, and teacher feedback. These signals feed a structured feedback loop that identifies anomalies, adjusts scoring logic, updates model parameters, and improves retrieval quality over time.
This closed-loop mechanism ensures the system becomes more accurate as usage grows, rather than degrading under heavier workloads.
Real Performance Gains and New Possibilities Powered by Milvus
After deploying Milvus across its hybrid cloud environments, TAL quickly saw major improvements in system performance and the quality of AI-powered learning experiences.
Millisecond-Level Retrieval at Billion Scale
Milvus now handles billions of vectors with millisecond-level semantic search, replacing the slow fuzzy-matching methods that once held back AI grading, recommendations, and content retrieval. With Milvus in place, results come back faster, accuracy increases, and teachers and students get more consistent answers across the board.
Higher Accuracy and Greater Stability
Milvus’ vector similarity search gives TAL a far deeper understanding of student responses. Compared with its previous systems, Milvus delivers:
More accurate retrieval results, especially for open-ended and multimodal questions
Higher-quality recall, surfacing relevant content that keyword search cannot match
Stable performance at a billion-scale, even during peak exam periods
Faster end-to-end processing, reducing latency for grading and recommendations
These advances elevate not just system efficiency but also instructional quality—enabling AI to better understand student intent and respond with greater pedagogical relevance.
Unlocking New AI Capabilities Across the Ecosystem
Beyond speeding up existing processes, Milvus enabled a wave of new functionality across TAL’s learning platforms:
AI Grading: More precise semantic matching improves scoring consistency and explanation quality.
Internal IM Platform: Faster and more relevant document retrieval enhances collaboration and content reuse.
Knowledge-Base QA: Accurate, chunk-level recall delivers answers that keyword search could never surface.
Advancing Educational Fairness and Efficiency
Milvus’ improvements translate into real gains in the classroom. Faster, more reliable AI grading reduces teacher workload and creates more consistent scoring for large groups of students. Better semantic retrieval makes high-quality learning resources easier to find and reuse. Together, these enhancements help TAL deliver more personalized, equitable support to every student.
Stronger Operational Efficiency and Observability
For engineering teams, Milvus also simplifies day-to-day operations. The Attu web console, Milvus’ official management tool, makes vector inspection and collection management more intuitive, reducing operational overhead. At the same time, integrations with Prometheus + Alertmanager provide deep visibility into latency, node health, storage utilization, and error patterns. This observability helps TAL maintain stable, predictable services—even during traffic surges and large exam cycles.
What’s Next: Growing with Milvus and the Community
With Milvus firmly in place across several teams, TAL is now looking ahead to how vector search can support even more of its AI initiatives. Running Milvus at a billion-scale has given TAL engineers a clear view of what works well and where new improvements could make an even bigger impact.
TAL plans to stay active in the Milvus community—sharing real production insights, giving feedback on new features, and working closely with contributors to shape the next wave of vector-database capabilities. Improvements such as simpler cross-cluster data migration and continued performance tuning would make it even easier for TAL to introduce Milvus across more products.
To keep critical services running smoothly, TAL also operates Zilliz Cloud, the fully managed Milvus service, alongside its open-source Milvus deployment. This dual-active setup provides the team with extra reliability during upgrades or heavy-traffic periods and ensures students and teachers always have a stable learning experience.
As TAL continues to build more intelligent and scalable AI tools for education, Milvus will remain a key part of its technology stack—helping the company deliver faster, smarter, and more reliable learning solutions for millions of families.
Note: This case study was written by Zhiming Huang and Muzi Lee, the senior data scientists at TAL Education Group, and is translated, edited, and reposted here with permission.