




How DiDi Food Transformed Grocery Search Across Latin America with Milvus

19% Reduction
in no-result queries achieved through Milvus semantic vector search
4% Increase
in cart conversions from Milvus-powered semantic product matching
15% of Queries
now benefit from vector search, supplementing traditional text search
Sub-second Vector Retrieval
with Milvus IVF_FLAT indexing and inner product similarity
About DiDi Food
DiDi, a global leader in ride-hailing with over 800 million users worldwide, launched DiDi Food—their grocery delivery service—across 12 major cities in Latin America, including Mexico, Colombia, and Costa Rica. Leveraging their existing logistics network and real-time optimization capabilities, they achieved remarkable growth: 2 million monthly active users, 500,000 daily orders, and over $120 million in Q1 2025 GMV—all within just six months.
The platform delivers fresh produce and household essentials in 30-45 minutes, with partner stores offering up to 30 million SKUs each. Operating across diverse markets with multilingual interactions, dynamic pricing, and real-time inventory management, DiDi Food built an impressive business foundation. But as their scale grew, so did the complexity of helping millions of customers find exactly what they needed across massive product catalogs. That's where Milvus vector database transformed their search capabilities, enabling semantic understanding that works across languages and handles the real-world messiness of how people actually search.
The Search Challenge: When Keyword-Based Elasticsearch Breaks Down
DiDi's engineering team faced the limitations that plague their keyword-based Elasticsearch database. Simple misspellings, code-switching, or unconventional descriptions often led to empty result pages, creating friction in the shopping experience.
High "No-Result" Rates: The Hidden Revenue Loss
DiDi Food faced a critical problem: too many customer searches returned zero results, leading to abandoned shopping sessions and lost revenue. Real examples from DiDi's search data revealed three main causes driving these failures.
Typos and misspellings were the most common culprits. Users typed "Genjibr" when searching for "Jengibre" (ginger), "hedaho" instead of "HELADO" (ice cream), or "Kellongs" for "Kelloggs." Their existing keyword search systems, powered by Elasticsearch, couldn't bridge these small but critical spelling gaps.
Input method artifacts created another barrier. Mobile keyboards and different input systems generated unusual Unicode variations like "𝑤𝑖𝑛𝑒" instead of "wine," "𝑏𝑎𝑛𝑎𝑛𝑎" for "banana," or "𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠" for "chocolates." These technical encoding issues left customers unable to find products that were clearly in stock.
Mixed-language queries posed the biggest challenge in Latin American markets. Customers naturally searched for "apple juice orgánico" or "leche sin lactosa," combining English and Spanish terms. Regional variations made this worse—the same product might be called different names across Mexico, Colombia, and Costa Rica.
Each failed search represented a frustrated customer and direct revenue loss. For a platform processing 500,000 daily orders, even a small percentage of no-result queries can translate to a significant business impact.
Scalability and Multilingual Complexity
Beyond individual search failures, DiDi faced systemic challenges that threatened its ability to scale. Indexing tens of millions of distinct SKU names textually inflated storage costs and degraded query performance as their product catalog expanded across multiple countries.
The multilingual complexity ran deeper than mixed-language queries. Operating across Mexico, Colombia, Costa Rica, and other Latin American markets meant the same product could have completely different names in each region. "Palta" in some countries, "aguacate" in others—both referring to avocado. Traditional keyword systems powered by Elasticsearch required maintaining separate indexes for each regional variation, which multiplied storage requirements and complicated maintenance.
Cultural and linguistic nuances created additional barriers. Local slang, brand name variations, and even different measurement systems (metric vs. imperial) all contributed to search failures. A keyword-based approach would require manually mapping thousands of regional variations—an impossible task at DiDi's scale.
DiDi's engineering team urgently needed a solution that could overcome these challenges and understand the intent behind user queries, regardless of language, region, or how customers chose to express their needs.
The Solution: Building a Semantic Search Engine with Milvus
The Elasticsearch-powered system struggles with language diversity and user input variability because it treats words as discrete tokens rather than meaningful concepts. Vector databases, however, can understand the semantic meaning and intent of user queries through vector embeddings and return more accurate and relevant results, regardless of the language or misspellings.
DiDi's engineering team decided to build a semantic search engine by leveraging multilingual embedding models and a vector database. The embedding model converts both product names and descriptions and user queries into vector embeddings that represent their semantic meaning in a high-dimensional space, while the vector database stores these embeddings and performs semantic search by calculating the distances between query vectors and product vectors.
After careful evaluation, they chose jina-embeddings-v3 as their primary embedding model because it maps text from different languages into the same high-dimensional mathematical space. This means that queries for "苹果" (Chinese), "apple" (English), or "manzana" (Spanish) yield nearly identical vectors, enabling accurate cross-lingual matching without the need for complex translation systems. Even misspelled or phonetically similar inputs produce vectors close to the correct terms.
DiDi selected Milvus as their vector database due to its open-source maturity, ability to scale horizontally to billions of vectors, millisecond latency, proven high-throughput architecture, and rich feature set.
Data Architecture and Optimization Strategy
To support low-latency vector retrieval over 30 million SKUs while preserving store-level associations, DiDi's engineers implemented several key optimizations.
Rather than storing individual vectors for each SKU-store combination, they merged identical item names into single vector entries with corresponding store IDs stored in arrays. This approach reduced their vector library from 30 million entries to 200,000 unique vectors, dramatically cutting memory usage while maintaining complete product coverage.
The team chose an
IVF_FLATindex configuration in Milvus, prioritizing search accuracy over compression complexity. When users query the system, Milvus returns the top-k most similar vectors from the aggregated index, followed by a rapid store-ID filter to isolate items available in the shopper's current location.For data freshness, DiDi adopted a T+1 nightly update cycle. New and updated SKUs are batched daily, re-embedded using GPU clusters, and pushed to refresh the Milvus collection. This strategy balances data currency with computational efficiency across their massive product catalog.
Milvus Schema Design
The collection schema reflects DiDi's specific requirements for grocery search, balancing flexibility with performance:
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding using jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
GPU-Accelerated Embedding Generation
Initial CPU-based embedding generation with the jina-embeddings-v3 model resulted in unacceptable latency of 5 seconds per record. To achieve real-time performance, DiDi deployed GPU instances on their Luban platform, reducing embedding time to approximately 50 milliseconds per query:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
Hybrid Search Pipeline Architecture
Rather than replacing their existing infrastructure entirely, DiDi implemented Milvus as an intelligent supplement to their established Elasticsearch system. The dual-pipeline design allows Elasticsearch to handle standard keyword queries while Milvus provides semantic understanding for complex cases.
The search flow operates in the following steps:
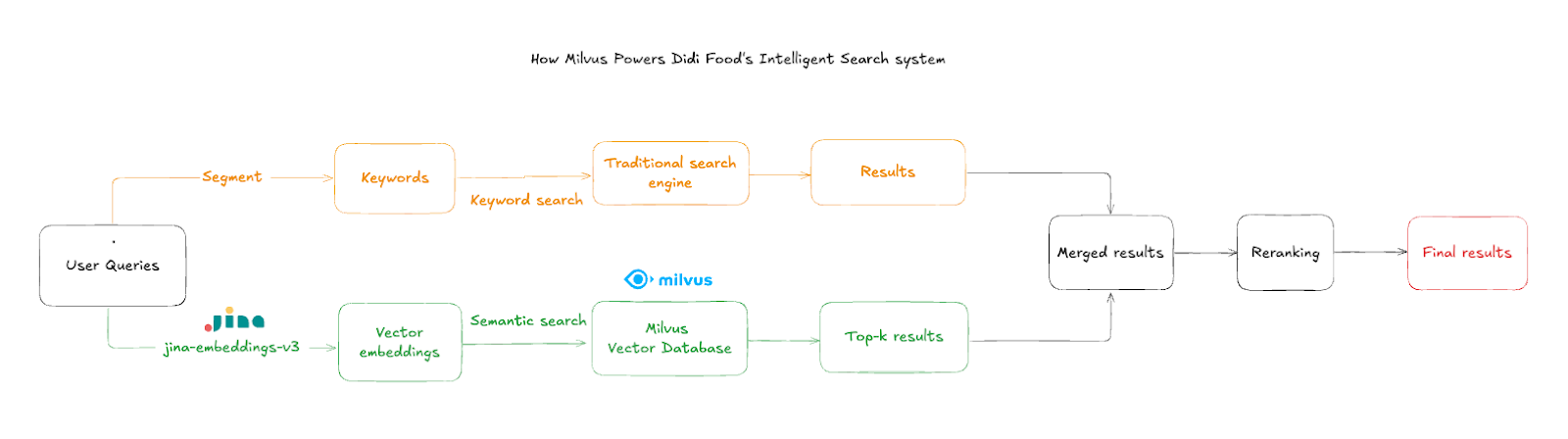
User Query Input: Customers type product names or descriptions, often with typos or mixed languages
Text Embedding: The system uses
jina-embeddings-v3to convert input into high-dimensional semantic vectors within ~50msSimilarity Search: Milvus queries the aggregated product vectors to find the closest semantic matches
Store Filtering: Results are filtered by store ID to ensure only in-stock items at the current store are shown
Result Merging: Vector results are combined with Elasticsearch results when traditional search produces unsatisfactory results, providing a richer, more complete search experience
Critical to the user experience is store-level filtering, which ensures that results belong to the shopper's current location context. The system employs intelligent result aggregation—when Elasticsearch produces unsatisfactory results, Milvus's semantically relevant items supplement the response.
Performance Results and Real-World Impact
DiDi's Milvus implementation delivered concrete improvements across critical business metrics.
The system achieved a 19% reduction in no-result queries, meaning nearly one in five previously failed searches now return relevant products, directly recovering lost revenue opportunities. For a platform processing 500,000 daily orders, this recovery rate represents significant business value.
Vector search triggers for 15% of total queries, supplementing traditional text search precisely when semantic understanding adds value without overwhelming the core query pipeline. Most significantly, users exposed to vector-recalled items show a 4% increase in cart-add conversions, demonstrating that improved search relevance translates to measurable purchasing behavior.
The system now handles queries in multiple languages, including English, Spanish, Chinese, Korean, and Japanese, with particularly notable accuracy improvements for Spanish, crucial for DiDi's Latin American market presence. Multilingual performance testing revealed the power of semantic understanding: searches for "Liquid Foundation" work equally well whether users type the English term, Chinese "液体妆前乳," or Spanish "Base de maquillaje líquida." The system bridges language gaps that would completely stump traditional keyword approaches.
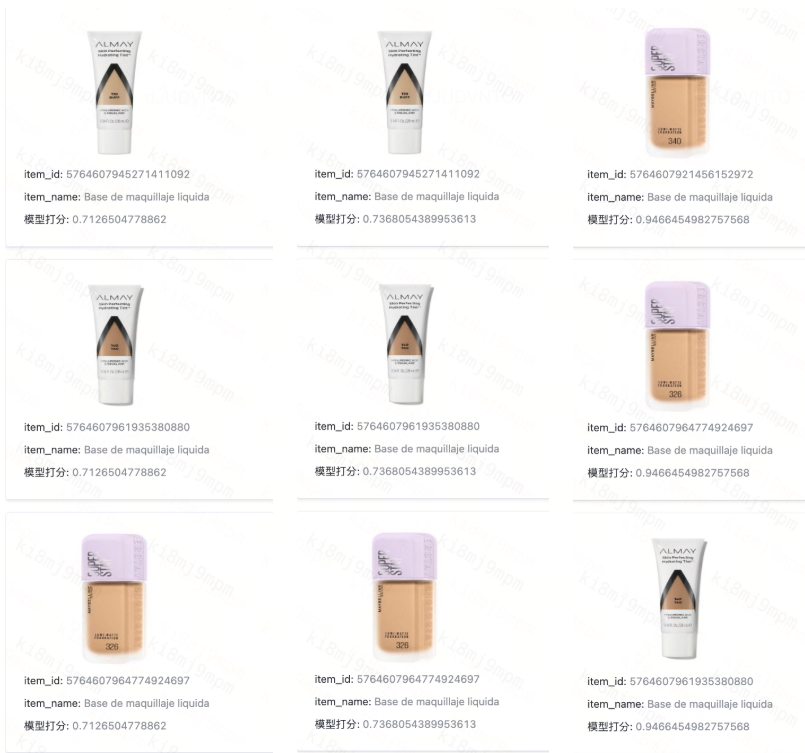
Figure: Searches for "Liquid Foundation" work equally well whether users type the English term, Chinese "液体妆前乳," or Spanish "Base de maquillaje líquida."
Complex product queries demonstrate the contextual understanding of vector search. When users search for "Redac PalancaPara WC Blanca" (a white toilet flush lever), the vector system accurately matches the query despite the compound technical terminology, whereas traditional search fails to parse the multi-word product description.
These gains translate into a smoother shopping experience, higher customer satisfaction, and a definitive competitive advantage in the fresh grocery e-commerce market.
Future Roadmap: Next-Generation Search Capabilities
Building on this solid foundation, DiDi and Milvus are collaborating on several advanced capabilities for the next phase of development.
Real-time catalog synchronization will reduce latency between inventory changes and searchable data through streaming updates, ensuring users never see products that aren't actually available. Behavioral signal integration will merge vector similarity with user history, preferences, and contextual signals to deliver hyper-personalized recommendations that improve over time.
Advanced hybrid search and reranking represent perhaps the most exciting development. This system will blend business metrics, including price, ratings, promotions, and inventory levels, with semantic relevance to surface truly optimal recommendations for each individual shopper.
Enhanced multilingual support will expand language coverage and improve regional dialect handling as DiDi enters new markets. Dynamic embedding optimization will implement continuous learning mechanisms to enhance embedding quality based on actual user interaction patterns, thereby creating a search system that becomes increasingly smarter with use.
By continually innovating, DiDi is redefining the grocery search experience, ensuring that every shopper finds exactly what they need, every time.
Conclusion
DiDi Food's journey with Milvus demonstrates that semantic search represents more than a technical upgrade—it's a fundamental reimagining of how users interact with large product catalogs. By combining thoughtful data architecture, appropriate technology choices, and unwavering focus on user experience, they've created a search system that truly understands intent across languages and cultures.
The results validate this approach: fewer frustrated users, more successful purchases, and a shopping experience that works regardless of how customers choose to express their needs. For DiDi's 2 million monthly users, this means consistently finding what they need, when they need it, in whatever language feels most natural to them.
This success story illustrates what becomes possible when innovative companies embrace semantic understanding at scale. As DiDi continues expanding across Latin America, its Milvus-powered search architecture provides a robust foundation for continued innovation and user satisfaction. The technology works, the business results are clear, and the user experience improvement is tangible—exactly what great engineering should deliver.