




Zilliz Vector Search Algorithm Dominates All Four Tracks of BigANN
The BigANN challenge is a climactic competition in the vector search domain, fostering the development of indexing data structures and search algorithms for practical variants of the Approximate Nearest Neighbor (ANN) problem. Zilliz takes pride in being a key organizer of this significant competition, witnessing ingenious solutions from global participants. As creators of the Milvus vector database, we felt compelled to contribute our insights and solutions to the challenge presented.
Today, we're thrilled to share some great news: our Zilliz solution surpassed all existing submissions and solutions from other vendors across all four tracks of BigANN, achieving a remarkable up to 2.5x performance improvement. This post will introduce BigANN 2023 and delve deep into the Zilliz solution and its performance results.
BigANN 2023
The ANN benchmark is an industry-standard tool for assessing vector search algorithms, but its small-sized evaluation datasets limit its applicability to real-world production challenges. In response, BigANN was born and serves as both a competition and benchmarking initiative, addressing this limitation by evaluating and advancing algorithms on large-scale datasets.
This year, the BigANN 2023 introduces more significant challenges, emphasizing larger datasets (up to 10 million vector points) and more complex scenarios. The competition features four tracks: filtered, out-of-distribution, sparse, and streaming variants of ANNS, providing a realistic testing ground for real-world scenarios.
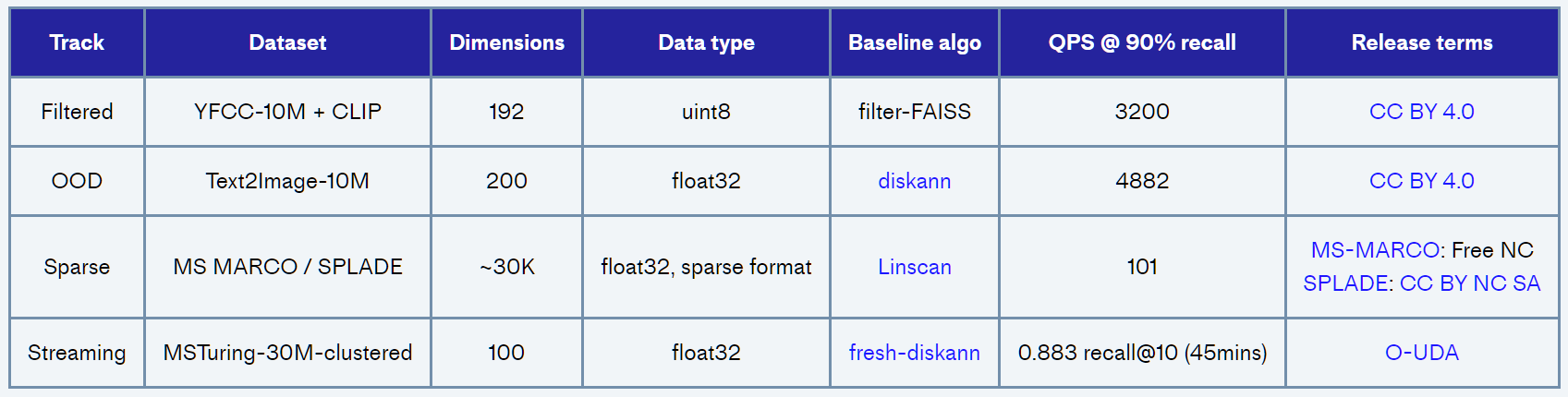 Table1: The four tracks of BigANN 2023
Table1: The four tracks of BigANN 2023
Filtered Track: This task uses the YFCC 100M dataset, selecting 10 million images. It requires extracting CLIP embeddings for each image and generating tags that cover aspects like image description, camera model, capture year, and country, drawn from a diverse vocabulary. The challenge here is to match 100,000 queries proficiently, each comprising an image embedding and specific tags, with their corresponding images and tags in the dataset.
Out-Of-Distribution(OOD) Track: This track presents participants with the Yandex Text-to-Image 10M dataset, highlighting the integration of cross-modal data. The base dataset includes 10 million image embeddings from the Yandex visual search database, generated using the Se-ResNext-101 model. In contrast, the query embeddings are based on textual searches, processed through a different model. The primary challenge here is to bridge the gap between these different modalities of data effectively.
Sparse Track: This track leverages the MSMARCO passage retrieval dataset, featuring an extensive collection of over 8.8 million text passages encoded into sparse vectors using the SPLADE model. These vectors have about 30,000 dimensions but exhibit a sparse nature. Simultaneously, the nearly 7,000 queries are processed through the same model, albeit with fewer non-zero elements due to their concise length. The primary task in this track is to accurately retrieve the top results for a given query, with a specific emphasis on the maximal inner product between the query vectors and the database vectors.
Streaming Track: This track is based on a segment of the MS Turing dataset, comprising 30 million data points. Participants need to follow a provided "runbook" which intricately outlines a sequence of data insertion, deletion, and search operations. These operations must be completed within an hour and under 8GB of DRAM. This track focuses on optimizing the process of handling these operations and maintaining a streamlined index of the dataset.
In this competition, each track has distinct criteria for algorithm ranking:
In the Filters, OOD, and Sparse tracks, algorithms are assessed based on QPS, provided they achieve a minimum of 90% recall@10.
In the Streaming track, algorithms are ranked according to recall@10, with the additional requirement to complete the runbook within an hour.
All performance tests, including our Zilliz solution, were conducted on an Azure D8lds_v5 (8 vCPUs and 16 GiB memory).
Zilliz solution and its performance results
All the following results adhere to the evaluation framework and guidelines set forth by the BigANN competition, ensuring a fair and comprehensive comparison.
Filtered Track
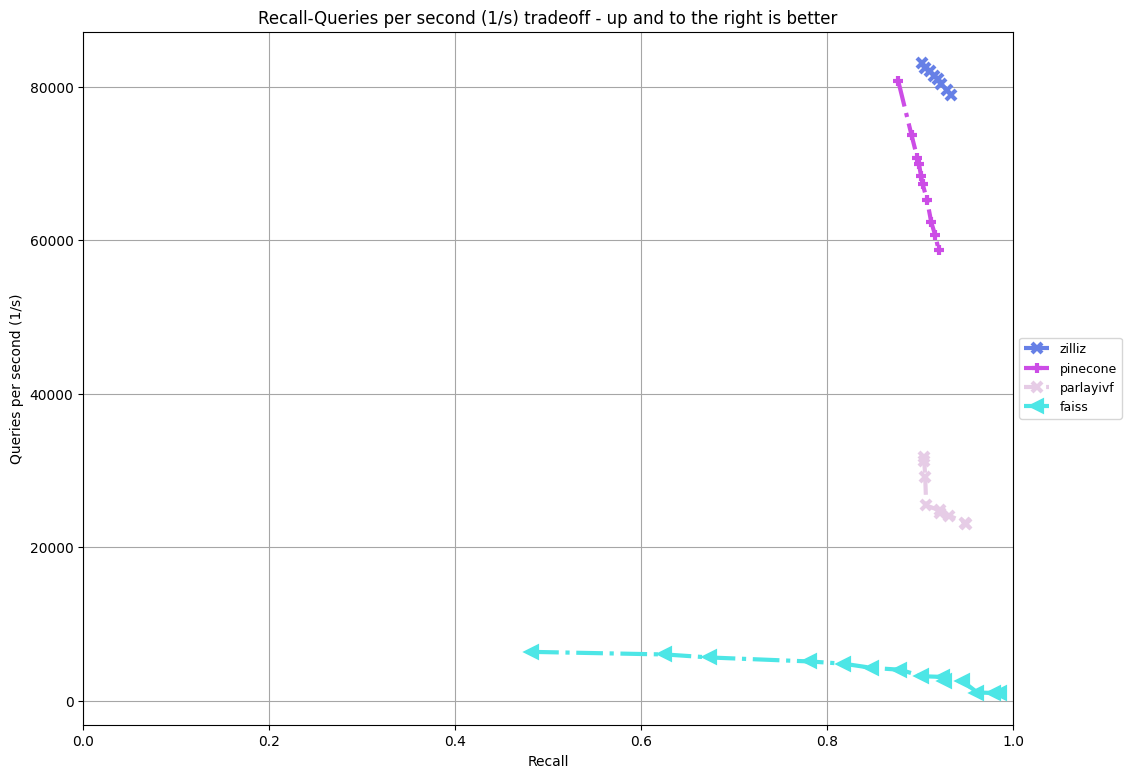
Comparison of our Filter track solution (zilliz) against the official baseline (faiss), the winner (parlayivf), and the Pinecone solution. At 90% recall, our throughput is roughly 82,000 QPS, approximately 25x the baseline at 3,200 QPS, 2.5x the track winner at 32,000 QPS, and much higher than the Pinecone solution at 68,000 QPS.
Our solution is based on graph algorithms and tag classification. During the build phase, we analyze the cardinality of each potential tag combination. We construct graphs for combinations with a large number of vectors while establishing inverted indexes for others. When searching, we choose the appropriate search method based on the unique characteristics of each tag combination.
In parallel, we classify queries according to their associated tags. During searching, we search for each query based on its corresponding tag. This approach offers two benefits: 1) it maximizes the usage of the cache, and 2) it enables acceleration through matrix multiplication, which is particularly beneficial during exhaustive searches.
We quantize data to accelerate computations and use SIMD to fine-tune distance calculations, ensuring high computational efficiency.
OOD Track
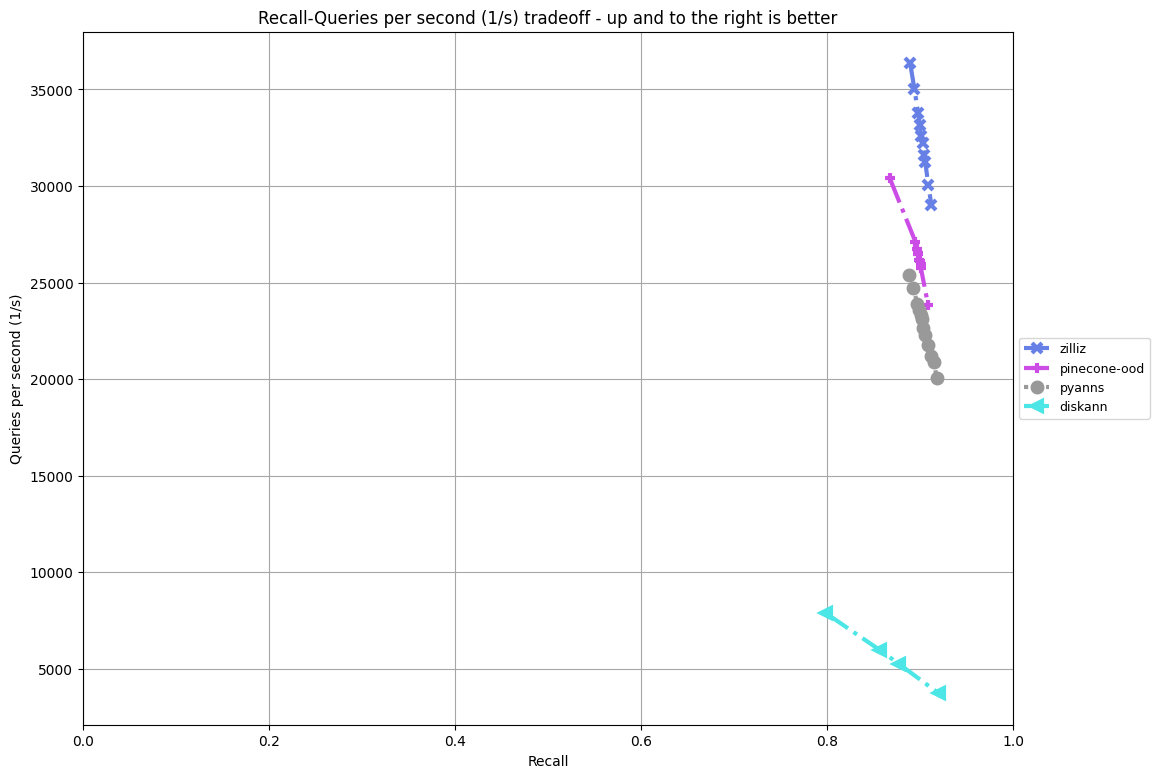
Comparison of our OOD track solution against the official baseline (diskann), the track winner (pyanns), and the Pinecone solution (pinecone-odd). At 90% recall, our throughput is roughly 33,000 QPS, 8x the baseline at around 4,000 QPS and outperforms the tracker winner at approximately 23,000 QPS and the Pinecone solution at 26,000 QPS.
Note: We make this comparison using the public query set since there is no hidden query set on this track.
Our solution is based on the synergy of graph algorithms and a highly optimized search process.
For computation, we use quantization at different precision levels for both search and refinement and harness the power of SIMD for accelerated calculations. Before searching, we cluster query vectors. During graph search, each cluster of queries is assigned distinct initial points, paving the way for sequential searches within each cluster.
This clustering strategy has two advantages: 1) a sequential exploration of different clusters maximizes cache utilization, and 2) the allocation of adaptive initial points to diverse clusters mitigates challenges arising from varying vector distributions.
In addition, we also implement a multi-level bitset data structure. We need a data structure to mark visited points in the intricate image search process. Conventional methods often resort to a bitset or a hash table, but each has drawbacks. Bitsets often lead to inefficient memory usage and cache misses, while hash tables perform poorly due to unfavorable constants. We've innovated a multi-level bitset data structure that draws inspiration from multi-level page tables in memory. This design optimizes CPU cache utilization, resulting in a significant enhancement in read and write performance.
Sparse Track
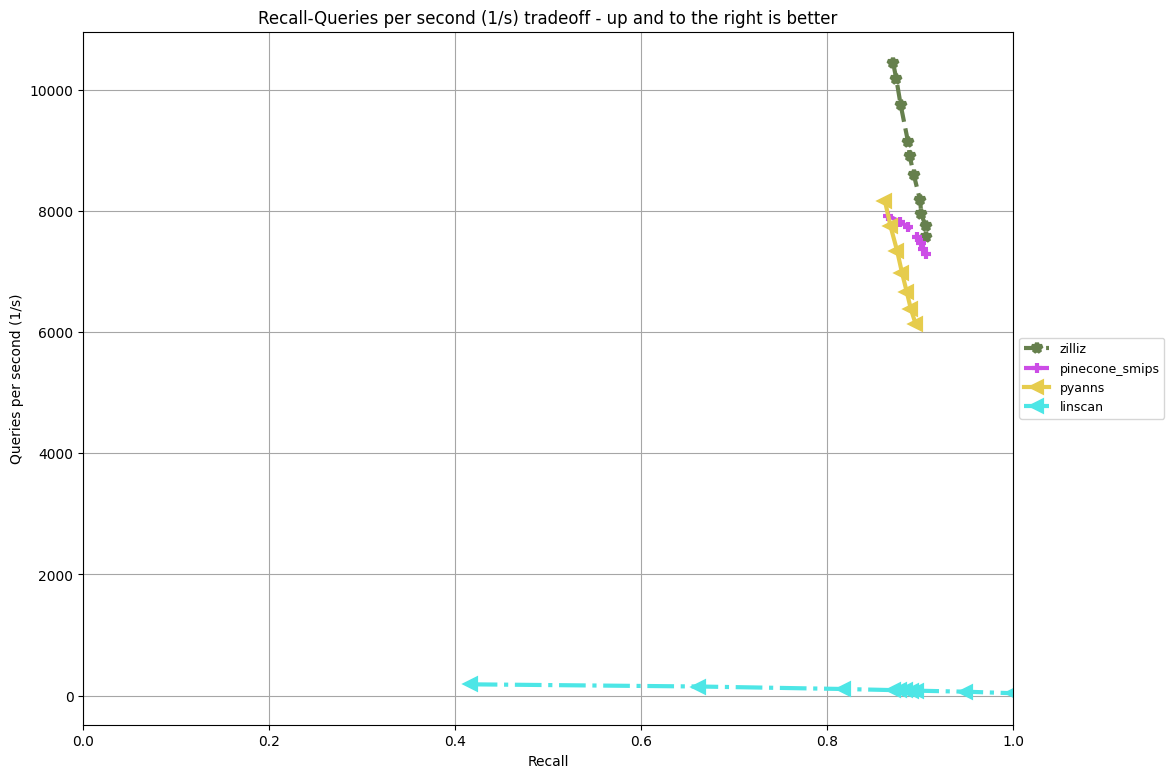
Comparison of our Sparse track solution (zilliz) against the official baseline (linscan), and track winner (pyanns), and the Pinecone solution (pinecone_smips). At 90% recall, our throughput is around 8,200 QPS, which is 82x the baseline at around 100 QPS, and outperformed both the track winner at 6,000 QPS and the Pinecone solution at 7,400 QPS.
In this track, our solution is based on the synergy of graph algorithms and optimizations driven by sparse vectors. Each sparse vector is represented as a list of tuples (data[float32], index[int32]). We introduce multi-precision quantization to process the data, catering to computations during graph search and the subsequent refinement. Additionally, we optimize memory bandwidth by representing the index using int16.
The task is about maximizing inner product search. In inner product calculations, their magnitudes influence the importance of values. Larger magnitudes hold greater significance, while smaller ones are less important. Leveraging this insight, we implement a pruning strategy during the graph search, discarding values with smaller absolute magnitudes. Following the graph search, we conduct refinement using the complete vectors. Experimental results indicate that we can prune over 80% of data in query vectors without significantly compromising recall.
We employ SIMD technology for the rapid intersection of sorted lists for expeditious computations, thereby achieving highly efficient calculations for sparse vector inner products.
Streaming Track
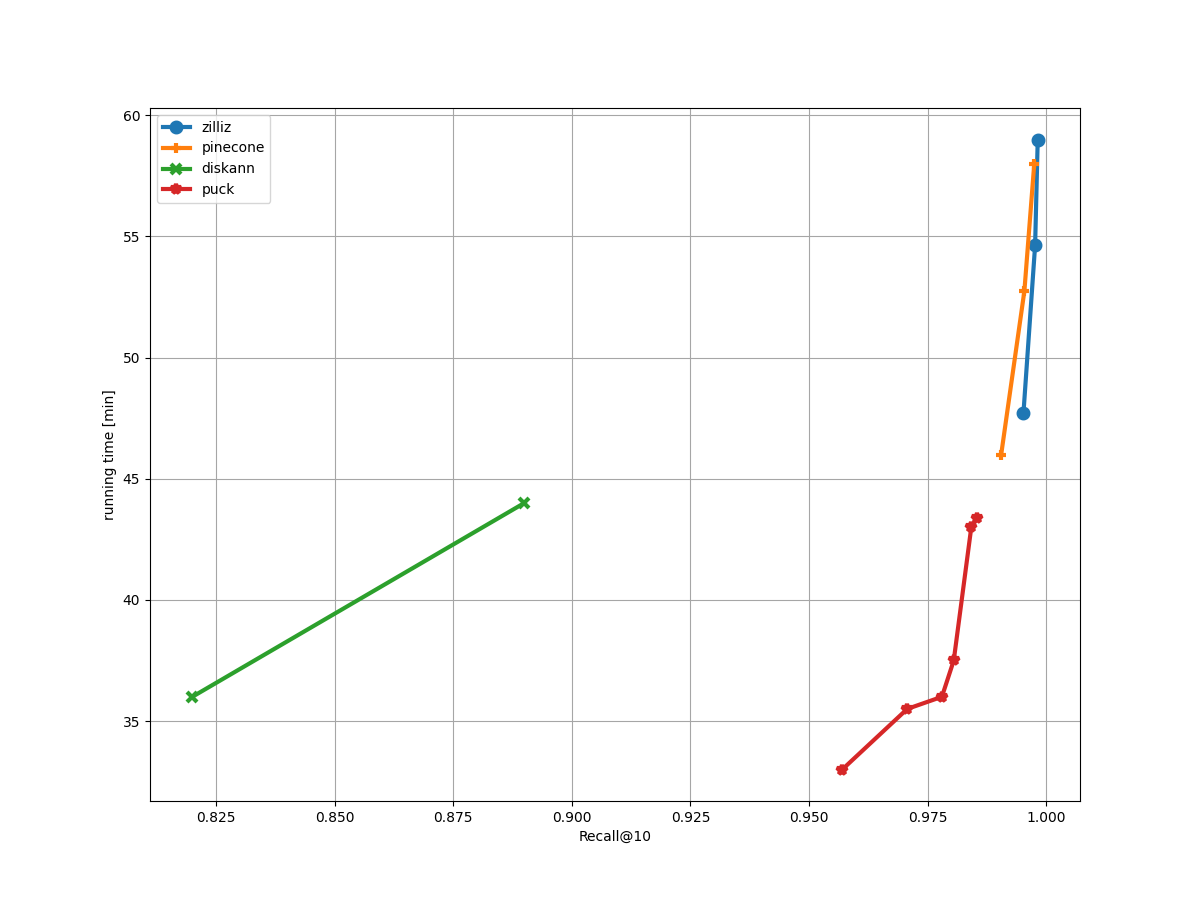
Comparison of our Streaming track solution (zilliz) against the official baseline (diskann), the track winner (puck), and the Pinecone solution (pinecone). Our algorithm achieves a recall of 0.9982, surpassing the track winner and the Pinecone solution with recalls of 0.986 and 0.9975, respectively.
Our streaming track solution is based on graph algorithms and SQ quantization.
We implement a lazy deletion strategy for deletion operations, marking vectors for deletion without immediately changing the graph structure. The graph is not restructured until a specified number of deletion operations accumulate.
We quantize vectors at various precisions for both the graph search and refinement. First, we use lower-precision vectors for graph search. However, due to our lazy deletion strategy, deleted vectors may appear in search results. So, we leverage a post-filtering strategy to eliminate these deleted vectors. Finally, we use higher-precision quantized vectors to refine the results.
Note: While our solution is not open-sourced, we’ve explained our methodology and released the binaries on the BigANN's GitHub repo for broad accessibility and reproduction.
BigANN algorithms will be integrated into Zilliz products
As AI progresses, vector search has become essential for supporting intricate production scenarios. BigANN's coverage of multiple scenarios adds significant practical value. We're thrilled to be actively involved in this BigANN competition and enjoy tackling these challenging algorithmic problems. We’ll incorporate the insights from this process into our products, extending their impact on a broader range of issues.
Come and join us!
At Zilliz, we're committed to building the world's best vector database, using vector search to tackle real-world problems. We're also on an ongoing journey exploring challenging use cases inspired by BigANN and beyond. We're inviting like-minded individuals interested in vector search, database systems, or AI technologies to join us on this path. If you're interested, get in touch! Explore opportunities on our career page for more information and to apply.
This post is written by Li Liu and Zihao Wang.

Keep Reading

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.