




Accelerating AI in Finance with Milvus, an Open-Source Vector Database
Banks and other financial institutions have long been early adopters of open-source software for big data processing and analytics. In 2010, Morgan Stanley began using the open-source Apache Hadoop framework as part of a small experiment. The company was struggling to successfully scale traditional databases to the massive volumes of data its scientists wanted to leverage, so it decided to explore alternative solutions. Hadoop is now a staple at Morgan Stanley, helping with everything from managing CRM data to portfolio analysis. Other open-source relational database software such as MySQL, MongoDB, and PostgreSQL have been indispensable tools for making sense of big data in the finance industry.
Technology is what gives the financial services industry a competitive edge, and artificial intelligence (AI) is rapidly becoming the standard approach to extracting valuable insights from big data and analyzing activity in real-time across the banking, asset management, and insurance sectors. By using AI algorithms to convert unstructured data such as images, audio, or video to vectors, a machine-readable numeric data format, it is possible to run similarity searches on massive million, billion, or even trillion vector datasets. Vector data is stored in high-dimensional space, and similar vectors are found using similarity search, which requires a dedicated infrastructure called a vector database.
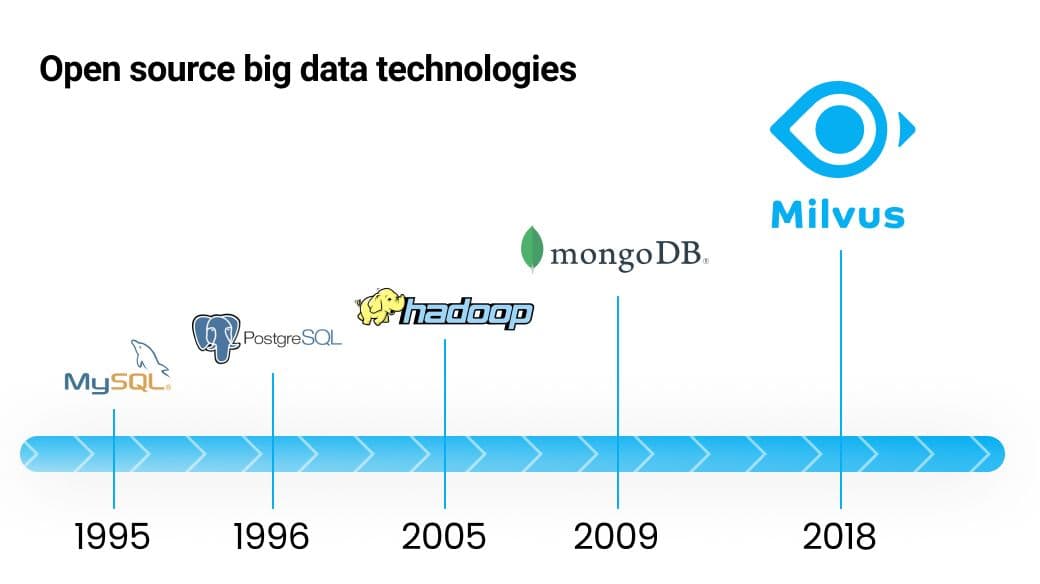 Development of open source big data technologies.
Development of open source big data technologies.
Milvus is an open-source vector database built specifically for managing vector data, which means engineers and data scientists can focus on building AI applications or conducting analysis—instead of the underlying data infrastructure. The platform was built around AI application development workflows and is optimized to streamline machine learning operations (MLOps). For more information about Milvus and its underlying technology, check out our blog.
Common applications of AI in the financial services industry include algorithmic trading, portfolio composition and optimization, model validation, backtesting, Robo-advising, virtual customer assistants, market impact analysis, regulatory compliance, and stress testing. This article covers three specific areas where vector data is leveraged as one of the most valuable assets for banking and financial companies:
- Enhancing customer experience with banking chatbots
- Boosting financial services sales and more with recommender systems
- Analyzing earnings reports and other unstructured financial data with semantic text mining
Enhancing customer experience with banking chatbots
Banking chatbots can improve customer experiences by helping consumers select investments, banking products, and insurance policies. Digital services are rising rapidly in popularity in part due to trends accelerated by the coronavirus pandemic. Chatbots work by using natural language processing (NLP) to convert user-submitted questions into semantic vectors to search for matching answers. Modern banking chatbots offer a personalized natural experience for users and speak in a conversational tone. Milvus provides a data fabric well suited for creating chatbots using real-time vector similarity search.
Learn more in our demo that covers building chatbots with Milvus.
 Demo.
Demo.
Boosting financial services sales and more with recommender systems:
The private banking sector uses recommender systems to increase sales of financial products through personalized recommendations based on customer profiles. Recommender systems can also be leveraged in financial research, business news, stock selection, and trading support systems. Thanks to deep learning models, every user and item is described as an embedding vector. A vector database offers an embedding space where similarities between users and items can be calculated.
Learn more from our demo covering graph-based recommendation systems with Milvus.
Analyzing earnings reports and other unstructured financial data with semantic text mining:
Text mining techniques had a substantial impact on the financial industry. As financial data grows exponentially, text mining has emerged as an important field of research in the domain of finance.
Deep learning models are currently applied to represent financial reports through word vectors capable of capturing numerous semantic aspects. A vector database like Milvus is able to store massive semantic word vectors from millions of reports, then conduct similarity searches on them in milliseconds.
Learn more about how to use deepset's Haystack with Milvus.
Don’t be a stranger
Keep Reading

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.