




Making with Milvus: Detecting Android Viruses in Real Time for Trend Micro
Cybersecurity remains a persistent threat to both individuals and businesses, with data privacy concerns increasing for 86% of companies in 2020 and just 23% of consumers believing their personal data is very secure. As malware becomes steadily more omnipresent and sophisticated, a proactive approach to threat detection has become essential. Trend Micro is a global leader in hybrid cloud security, network defense, small business security, and endpoint security. To protect Android devices from viruses, the company built Trend Micro Mobile Security—a mobile app that compares APKs (Android Application Package) from the Google Play Store to a database of known malware. The virus detection system works as follows:
- External APKs (Android application package) from the Google Play Store are crawled.
- Known malware is converted into vectors and stored in Milvus.
- New APKs are also converted into vectors, then compared to the malware database using similarity search.
- If an APK vector is similar to any of the malware vectors, the app provides users with detailed information about the virus and its threat level.
To work, the system has to perform highly efficient similarity search on massive vector datasets in real time. Initially, Trend Micro used MySQL. However, as its business expanded so did the number of APKs with nefarious code stored in its database. The company’s algorithm team began searching for alternative vector similarity search solutions after quickly outgrowing MySQL.
Comparing vector similarity search solutions
There are a number of vector similarity search solutions available, many of which are open source. Although the circumstances vary from project to project, most users benefit from leveraging a vector database built for unstructured data processing and analytics rather than a simple library that requires extensive configuration. Below we compare some popular vector similarity search solutions and explain why Trend Micro chose Milvus.
Faiss
Faiss is a library developed by Facebook AI Research that enables efficient similarity search and clustering of dense vectors. The algorithms it contains search vectors of any size in sets. Faiss is written in C++ with wrappers for Python/numpy, and supports a number of indexes including IndexFlatL2, IndexFlatIP, HNSW, and IVF.
Although Faiss is an incredibly useful tool, it has limitations. It only works as a basic algorithm library, not a database for managing vector datasets. Additionally, it does not offer a distributed version, monitoring services, SDKs, or high availability, which are the key features of most cloud-based services.
Plug-ins based on Faiss & other ANN search libraries
There are several plug-ins built on top of Faiss, NMSLIB, and other ANN search libraries that are designed to enhance the basic functionality of the underlying tool that powers them. Elasticsearch (ES) is a search engine based on the Lucene library with a number of such plugins. Below is an architecture diagram of an ES plug-in:
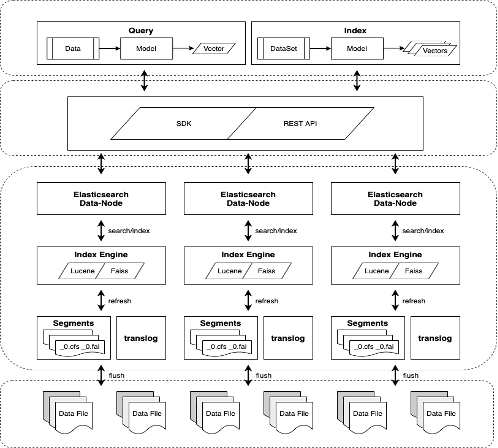 Architecture diagram of an Elasticsearch plug-in.
Architecture diagram of an Elasticsearch plug-in.
Built in support for distributed systems is a major advantage of an ES solution. This saves developers time and companies money thanks to code that doesn’t have to be written. ES plug-ins are technically advanced and prevalent. Elasticsearch provides a QueryDSL (domain-specific language), which defines queries based on JSON and is easy to grasp. A full set of ES services makes it possible to conduct vector/text search and filter scalar data simultaneously.
Amazon, Alibaba, and Netease are a few large tech companies that currently rely on Elasticsearch plug-ins for vector similarity search. The primary downsides with this solution are high memory consumption and no support for performance tuning. In contrast, JD.com has developed its own distributed solution based on Faiss called Vearch. However, Vearch is still an incubation-stage project and its open-source community is relatively inactive.
Milvus
Milvus is an open-source vector database created by Zilliz. It is highly flexible, reliable, and blazing fast. By encapsulating multiple widely adopted index libraries, such as Faiss, NMSLIB, and Annoy, Milvus provides a comprehensive set of intuitive APIs, allowing developers to choose the ideal index type for their scenario. It also provides distributed solutions and monitoring services. Milvus has a highly active open-source community and over 5.5K stars on Github.
Milvus bests the competition
We compiled a number of different test results from the various vector similarity search solutions mentioned above. As we can see in the following comparison table, Milvus was significantly faster than the competition despite being tested on a dataset of 1 billion 128-dimensional vectors.
| Engine | Performance (ms) | Dataset Size (million) |
|---|---|---|
| ES | 600 | 1 |
| ES + Alibaba Cloud | 900 | 20 |
| Milvus | 27 | 1000+ |
| SPTAG | Not good | |
| ES + nmslib, faiss | 90 | 150 |
A comparison of vector similarity search solutions.
After weighing the pros and cons of each solution, Trend Micro settled on Milvus for its vector retrieval model. With exceptional performance on massive, billion-scale datasets, it's obvious why the company chose Milvus for a mobile security service that requires real-time vector similarity search.
Designing a system for real-time virus detection
Trend Micro has more than 10 million malicious APKs stored in its MySQL database, with 100k new APKs added each day. The system works by extracting and calculating Thash values of different components of an APK file, then uses the Sha256 algorithm to transform it into binary files and generate 256-bit Sha256 values that differentiate the APK from others. Since Sha256 values vary with APK files, one APK can have one combined Thash value and one unique Sha256 value.
Sha256 values are only used to differentiate APKs, and Thash values are used for vector similarity retrieval. Similar APKs may have the same Thash values but different Sha256 values.
To detect APKs with nefarious code, Trend Micro developed its own system for retrieving similar Thash values and corresponding Sha256 values. Trend Micro chose Milvus to conduct instantaneous vector similarity search on massive vector datasets converted from Thash values. After similarity search is run, the corresponding Sha256 values are queried in MySQL. A Redis caching layer is also added to the architecture to map Thash values to Sha256 values, significantly reducing query time.
Below is the architecture diagram of Trend Micro’s mobile security system.
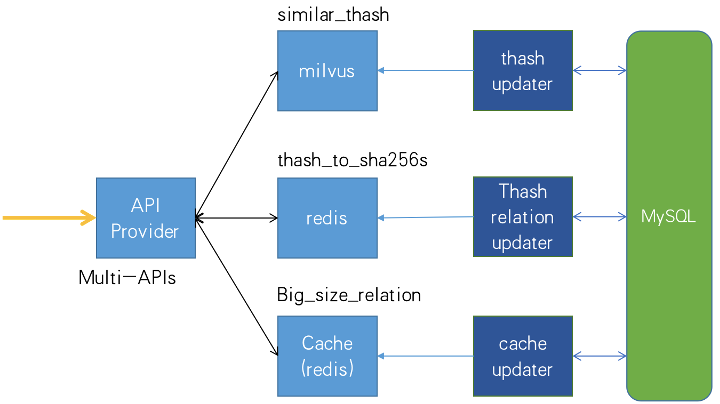 Architecture diagram for Trend Micro Mobile Security.
Architecture diagram for Trend Micro Mobile Security.
Choosing an appropriate distance metric helps improve vector classification and clustering performance. The following table shows the distance metrics and the corresponding indexes that work with binary vectors.
| Distance Metrics | Index Types |
|---|---|
| - Jaccard - Tanimoto - Hamming | - FLAT - IVF_FLAT |
| - Superstructure - Substructure | FLAT |
Distance metrics and indexes for binary vectors.
Trend Micro converts Thash values into binary vectors and stores them in Milvus. For this scenario, Trend Micro is using Hamming distance to compare vectors.
Milvus will soon support string vector ID, and integer IDs won’t have to be mapped to the corresponding name in string format. This makes the Redis caching layer unnecessary and the system architecture less bulky.
Trend Micro adopts a cloud-based solution and deploys many tasks on Kubernetes. To achieve high availability, Trend Micro uses Mishards, a Milvus cluster sharding middleware developed in Python.
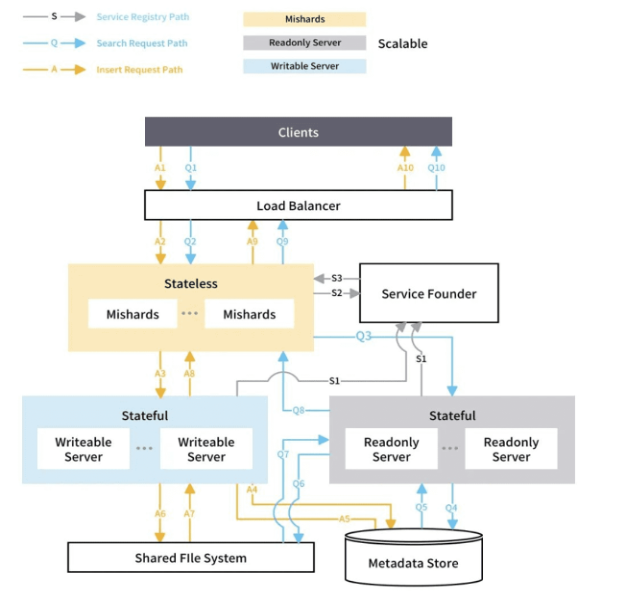 Mishards architecture in Milvus.
Mishards architecture in Milvus.
Trend Micro separates storage and distance calculation by storing all vectors in the EFS (Elastic File System) provided by AWS. This practice is a popular trend in the industry. Kubernetes is used to start multiple reading nodes, and develops LoadBalancer services on these reading nodes to ensure high availability.
To maintain data consistency Mishards supports just one writing node. However, a distributed version of Milvus with support for multiple writing nodes will be available in the coming months.
Monitoring and Alert Functions
Milvus is compatible with monitoring systems built on Prometheus, and uses Grafana, an open-source platform for time-series analytics, to visualize various performance metrics.
Prometheus monitors and stores the following metrics:
- Milvus performance metrics including insertion speed, query speed, and Milvus uptime.
- System performance metrics including CPU/GPU usage, network traffic, and disk access speed.
- Hardware storage metrics including data size and total file number.
The monitoring and alert system works as follows:
- A Milvus client pushes customized metrics data to Pushgateway.
- The Pushgateway ensures short-lived, ephemeral metric data is safely sent to Prometheus.
- Prometheus keeps pulling data from Pushgateway.
- Alertmanager sets the alert threshold for different metrics and raises alarms through emails or messages.
System Performance
A couple months have passed since the ThashSearch service built on Milvus was first launched. The graph below shows that end-to-end query latency is less than 95 milliseconds.
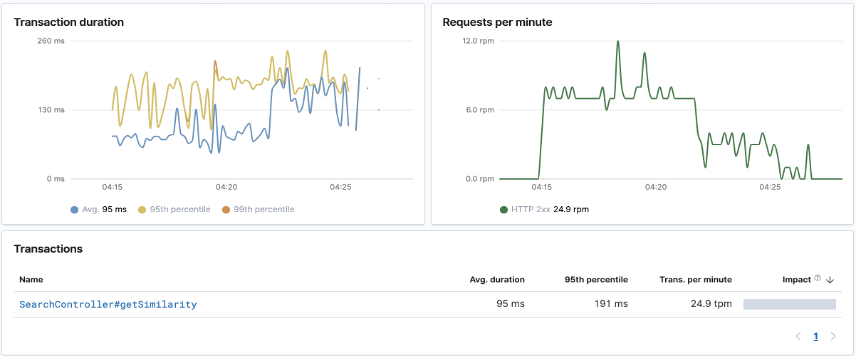 Query latency for Thash search service built on Milvus.
Query latency for Thash search service built on Milvus.
Insertion is also fast. It takes around 10 seconds to insert 3 million 192-dimensional vectors. With help from Milvus, the system performance was able to meet the performance criteria set by Trend Micro.
Don’t be a stranger
Keep Reading

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.