




Build RAG Chatbot with LangChain, Zilliz Cloud, Mistral AI Mistral Nemo, and Google Vertex AI text-embedding-004
Introduction to RAG
Retrieval-Augmented Generation (RAG) is a game-changer for GenAI applications, especially in conversational AI. It combines the power of pre-trained large language models (LLMs) like OpenAI’s GPT with external knowledge sources stored in vector databases such as Milvus and Zilliz Cloud, allowing for more accurate, contextually relevant, and up-to-date response generation. A RAG pipeline usually consists of four basic components: a vector database, an embedding model, an LLM, and a framework.
Key Components We'll Use for This RAG Chatbot
This tutorial shows you how to build a simple RAG chatbot in Python using the following components:
- LangChain: An open-source framework that helps you orchestrate the interaction between LLMs, vector stores, embedding models, etc, making it easier to integrate a RAG pipeline.
- Zilliz Cloud: a fully managed vector database-as-a-service platform built on top of the open-source Milvus, designed to handle high-performance vector data processing at scale. It enables organizations to efficiently store, search, and analyze large volumes of unstructured data, such as text, images, or audio, by leveraging advanced vector search technology. It offers a free tier supporting up to 1 million vectors.
- Mistral AI Mistral Nemo: This model is designed for high-performance natural language processing, emphasizing interpretability and adaptability. It excels in tasks involving text generation, dialogue systems, and content creation. Ideal for industries like marketing and entertainment, Mistral Nemo delivers rich, coherent narratives while allowing for fine-tuning to specific domain requirements.
- Google Vertex AI text-embedding-004: This model specializes in creating high-quality text embeddings for diverse natural language processing tasks. Its strength lies in capturing semantic meaning and relationships effectively, making it suitable for applications such as semantic search, clustering, and recommendation systems. Ideal for developers seeking to enhance AI-driven insights from textual data.
By the end of this tutorial, you’ll have a functional chatbot capable of answering questions based on a custom knowledge base.
Note: Since we may use proprietary models in our tutorials, make sure you have the required API key beforehand.
Step 1: Install and Set Up LangChain
%pip install --quiet --upgrade langchain-text-splitters langchain-community langgraph
Step 2: Install and Set Up Mistral AI Mistral Nemo
pip install -qU "langchain[mistralai]"
import getpass
import os
if not os.environ.get("MISTRAL_API_KEY"):
os.environ["MISTRAL_API_KEY"] = getpass.getpass("Enter API key for Mistral AI: ")
from langchain.chat_models import init_chat_model
llm = init_chat_model("open-mistral-nemo", model_provider="mistralai")
Step 3: Install and Set Up Google Vertex AI text-embedding-004
pip install -qU langchain-google-vertexai
from langchain_google_vertexai import VertexAIEmbeddings
embeddings = VertexAIEmbeddings(model="text-embedding-004")
Step 4: Install and Set Up Zilliz Cloud
pip install -qU langchain-milvus
from langchain_milvus import Zilliz
vector_store = Zilliz(
embedding_function=embeddings,
connection_args={
"uri": ZILLIZ_CLOUD_URI,
"token": ZILLIZ_CLOUD_TOKEN,
},
)
Step 5: Build a RAG Chatbot
Now that you’ve set up all components, let’s start to build a simple chatbot. We’ll use the Milvus introduction doc as a private knowledge base. You can replace it with your own dataset to customize your RAG chatbot.
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import List, TypedDict
# Load and chunk contents of the blog
loader = WebBaseLoader(
web_paths=("https://milvus.io/docs/overview.md",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("doc-style doc-post-content")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Index chunks
_ = vector_store.add_documents(documents=all_splits)
# Define prompt for question-answering
prompt = hub.pull("rlm/rag-prompt")
# Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
# Define application steps
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
# Compile application and test
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
Test the Chatbot
Yeah! You've built your own chatbot. Let's ask the chatbot a question.
response = graph.invoke({"question": "What data types does Milvus support?"})
print(response["answer"])
Example Output
Milvus supports various data types including sparse vectors, binary vectors, JSON, and arrays. Additionally, it handles common numerical and character types, making it versatile for different data modeling needs. This allows users to manage unstructured or multi-modal data efficiently.
Optimization Tips
As you build your RAG system, optimization is key to ensuring peak performance and efficiency. While setting up the components is an essential first step, fine-tuning each one will help you create a solution that works even better and scales seamlessly. In this section, we’ll share some practical tips for optimizing all these components, giving you the edge to build smarter, faster, and more responsive RAG applications.
LangChain optimization tips
To optimize LangChain, focus on minimizing redundant operations in your workflow by structuring your chains and agents efficiently. Use caching to avoid repeated computations, speeding up your system, and experiment with modular design to ensure that components like models or databases can be easily swapped out. This will provide both flexibility and efficiency, allowing you to quickly scale your system without unnecessary delays or complications.
Zilliz Cloud optimization tips
Optimizing Zilliz Cloud for a RAG system involves efficient index selection, query tuning, and resource management. Use Hierarchical Navigable Small World (HNSW) indexing for high-speed, approximate nearest neighbor search while balancing recall and efficiency. Fine-tune ef_construction and M parameters based on your dataset size and query workload to optimize search accuracy and latency. Enable dynamic scaling to handle fluctuating workloads efficiently, ensuring smooth performance under varying query loads. Implement data partitioning to improve retrieval speed by grouping related data, reducing unnecessary comparisons. Regularly update and optimize embeddings to keep results relevant, particularly when dealing with evolving datasets. Use hybrid search techniques, such as combining vector and keyword search, to improve response quality. Monitor system metrics in Zilliz Cloud’s dashboard and adjust configurations accordingly to maintain low-latency, high-throughput performance.
Mistral AI Mistral Nemo optimization tips
Mistral Nemo is designed for domain-specific knowledge retrieval and response generation, making retrieval efficiency a top priority. Optimize performance by fine-tuning retrieval pipelines to ensure domain-relevant embeddings are used for similarity searches. Use a ranking layer to prioritize the most contextually relevant passages before passing them to the model, reducing token waste. Adjust temperature settings (0.1–0.3) to maintain consistent, structured responses. In latency-sensitive applications, use token streaming to provide incremental responses rather than waiting for full completion. If running Nemo in a production environment, consider distributed inference techniques to manage large-scale workloads effectively. Monitor retrieval accuracy continuously and fine-tune embeddings periodically to keep responses aligned with domain-specific updates.
Google Vertex AI text-embedding-004 optimization tips
Google Vertex AI text-embedding-004 offers high-quality embeddings suitable for a wide range of RAG applications. To improve retrieval efficiency, reduce redundancy in input text by preprocessing data and focusing on key concepts and relevant context. For large-scale deployments, utilize batch processing to generate embeddings in parallel, reducing latency. Optimize search performance by implementing hybrid search strategies that combine traditional keyword matching with dense vector similarity. Fine-tune temperature settings to balance between creativity and precision, and adjust the model’s top-k and top-p parameters to control the variability of results. Cache embeddings for high-demand queries to reduce unnecessary processing, and refresh embeddings periodically to maintain relevance as new data is ingested.
By implementing these tips across your components, you'll be able to enhance the performance and functionality of your RAG system, ensuring it’s optimized for both speed and accuracy. Keep testing, iterating, and refining your setup to stay ahead in the ever-evolving world of AI development.
RAG Cost Calculator: A Free Tool to Calculate Your Cost in Seconds
Estimating the cost of a Retrieval-Augmented Generation (RAG) pipeline involves analyzing expenses across vector storage, compute resources, and API usage. Key cost drivers include vector database queries, embedding generation, and LLM inference.
RAG Cost Calculator is a free tool that quickly estimates the cost of building a RAG pipeline, including chunking, embedding, vector storage/search, and LLM generation. It also helps you identify cost-saving opportunities and achieve up to 10x cost reduction on vector databases with the serverless option.
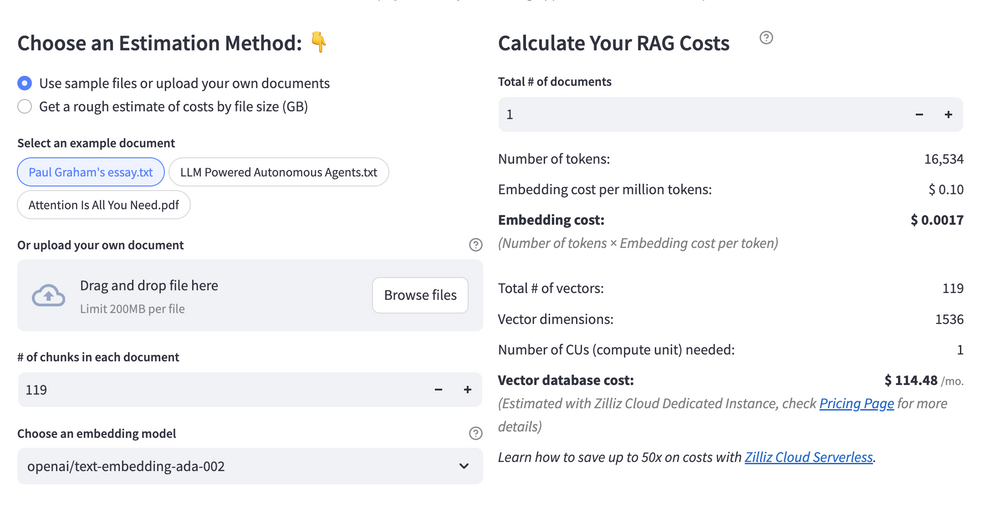 Calculate your RAG cost
Calculate your RAG cost
What Have You Learned?
What have you learned? Throughout this tutorial, you've embarked on an exciting journey through the intricacies of building a cutting-edge RAG (Retrieval-Augmented Generation) system by combining a powerful framework with a vector database, a sophisticated LLM, and a unique embedding model. You’ve seen firsthand how the framework seamlessly integrates these components, ensuring that everything works in perfect harmony. The vector database has empowered you with the ability to perform lightning-fast searches, making it easier than ever to retrieve relevant data from vast amounts of information.
By leveraging the conversational intelligence of the LLM, you've been equipped to create interactive and engaging user experiences. And let's not forget the embedding model's role in generating rich semantic representations—this capability unlocks a world of understanding, allowing your applications to grasp context and nuance like never before. Plus, with the optimization tips you picked up and the handy free cost calculator, you’re now armed with the tools to streamline your process and manage resources effectively.
As you wrap up this tutorial, let your imagination run wild! The world of RAG applications is ripe with possibilities, and now it's your turn to innovate. So go ahead—start building, optimizing, and exploring the incredible potential of what you can create. Your journey in the realm of intelligent applications awaits, and we can’t wait to see what you come up with!
Further Resources
🌟 In addition to this RAG tutorial, unleash your full potential with these incredible resources to level up your RAG skills.
- How to Build a Multimodal RAG | Documentation
- How to Enhance the Performance of Your RAG Pipeline
- Graph RAG with Milvus | Documentation
- How to Evaluate RAG Applications - Zilliz Learn
- Generative AI Resource Hub | Zilliz
We'd Love to Hear What You Think!
We’d love to hear your thoughts! 🌟 Leave your questions or comments below or join our vibrant Milvus Discord community to share your experiences, ask questions, or connect with thousands of AI enthusiasts. Your journey matters to us!
If you like this tutorial, show your support by giving our Milvus GitHub repo a star ⭐—it means the world to us and inspires us to keep creating! 💖
- Introduction to RAG
- Key Components We'll Use for This RAG Chatbot
- Step 1: Install and Set Up LangChain
- Step 2: Install and Set Up Mistral AI Mistral Nemo
- Step 3: Install and Set Up Google Vertex AI text-embedding-004
- Step 4: Install and Set Up Zilliz Cloud
- Step 5: Build a RAG Chatbot
- Optimization Tips
- RAG Cost Calculator: A Free Tool to Calculate Your Cost in Seconds
- What Have You Learned?
- Further Resources
- We'd Love to Hear What You Think!
anchor.title
Vector Database at Scale
Zilliz Cloud is a fully-managed vector database built for scale, perfect for your RAG apps.
Try Zilliz Cloud for Free


