Build RAG Chatbot with Haystack, OpenSearch, Amazon Bedrock Claude 3.5 Haiku, and Optimum all-mpnet-base-v2
Introduction to RAG
Retrieval-Augmented Generation (RAG) is a game-changer for GenAI applications, especially in conversational AI. It combines the power of pre-trained large language models (LLMs) like OpenAI’s GPT with external knowledge sources stored in vector databases such as Milvus and Zilliz Cloud, allowing for more accurate, contextually relevant, and up-to-date response generation. A RAG pipeline usually consists of four basic components: a vector database, an embedding model, an LLM, and a framework.
Key Components We'll Use for This RAG Chatbot
This tutorial shows you how to build a simple RAG chatbot in Python using the following components:
- Haystack: An open-source Python framework designed for building production-ready NLP applications, particularly question answering and semantic search systems. Haystack excels at retrieving information from large document collections through its modular architecture that combines retrieval and reader components. Ideal for developers creating search applications, chatbots, and knowledge management systems that require efficient document processing and accurate information extraction from unstructured text.
- OpenSearch: An open-source search and analytics suite derived from Elasticsearch. It offers robust full-text search and real-time analytics, with vector search available as an add-on for similarity-based queries, extending its capabilities to handle high-dimensional data. Since it is just a vector search add-on rather than a purpose-built vector database, it lacks scalability and availability and many other advanced features required by enterprise-level applications. Therefore, if you prefer a much more scalable solution or hate to manage your own infrastructure, we recommend using Zilliz Cloud, which is a fully managed vector database service built on the open-source Milvus and offers a free tier supporting up to 1 million vectors.)
- AmazonBedrock Claude 3.5 Haiku: A high-efficiency AI model designed for fast, scalable processing of diverse tasks. Strengths include low-latency responses, cost-effectiveness, and seamless AWS integration. Ideal for real-time applications, high-volume data analysis, and enterprise solutions requiring reliable performance with minimal operational overhead.
- Optimum all-mpnet-base-v2: A high-performance sentence-transformers model optimized for semantic textual similarity, offering robust multilingual embeddings. Its strengths include efficient inference, scalability, and state-of-the-art accuracy in tasks like semantic search, clustering, and retrieval-augmented generation (RAG). Ideal for enterprise applications requiring fast, precise text analysis across diverse languages and domains.
By the end of this tutorial, you’ll have a functional chatbot capable of answering questions based on a custom knowledge base.
Note: Since we may use proprietary models in our tutorials, make sure you have the required API key beforehand.
Step 1: Install and Set Up Haystack
import os
import requests
from haystack import Pipeline
from haystack.components.converters import MarkdownToDocument
from haystack.components.preprocessors import DocumentSplitter
from haystack.components.writers import DocumentWriter
Step 2: Install and Set Up Amazon Bedrock Claude 3.5 Haiku
Amazon Bedrock is a fully managed service that makes high-performing foundation models from leading AI startups and Amazon available through a unified API. You can choose from various foundation models to find the one best suited for your use case.
To use LLMs on Amazon Bedrock for text generation together with Haystack, you need to initialize an AmazonBedrockGenerator with the model name, the AWS credentials (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_DEFAULT_REGION) should be set as environment variables, be configured as described above or passed as Secret arguments. Note, make sure the region you set supports Amazon Bedrock.
Now, let's start installing and setting up models with Amazon Bedrock.
pip install amazon-bedrock-haystack
from haystack_integrations.components.generators.amazon_bedrock import AmazonBedrockGenerator
aws_access_key_id="..."
aws_secret_access_key="..."
aws_region_name="eu-central-1"
generator = AmazonBedrockGenerator(model="anthropic.claude-3-5-haiku-20241022-v1:0")
Step 3: Install and Set Up Optimum all-mpnet-base-v2
Haystack's OptimumTextEmbedder embeds text strings using models loaded with the HuggingFace Optimum library. It uses the ONNX runtime for high-speed inference. Similarly to other Embedders, this component allows adding prefixes (and suffixes) to include instructions. For more details, refer to the Optimum API Reference.
pip install optimum-haystack
from haystack_integrations.components.embedders.optimum import OptimumTextEmbedder
from haystack.dataclasses import Document
from haystack_integrations.components.embedders.optimum import OptimumDocumentEmbedder
text_embedder = OptimumTextEmbedder(model="sentence-transformers/all-mpnet-base-v2")
text_embedder.warm_up()
document_embedder = OptimumDocumentEmbedder(model="sentence-transformers/all-mpnet-base-v2")
document_embedder.warm_up()
Step 4: Install and Set Up OpenSearch
If you have Docker set up, we recommend pulling the Docker image and running it.
docker pull opensearchproject/opensearch:2.11.0
docker run -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" -e "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" opensearchproject/opensearch:2.11.0
Once you have a running OpenSearch instance, install the opensearch-haystack integration:
pip install opensearch-haystack
from haystack_integrations.components.retrievers.opensearch import OpenSearchEmbeddingRetriever
from haystack_integrations.document_stores.opensearch import OpenSearchDocumentStore
document_store = OpenSearchDocumentStore(hosts="http://localhost:9200", use_ssl=True,
verify_certs=False, http_auth=("admin", "admin"))
retriever = OpenSearchEmbeddingRetriever(document_store=document_store)
Step 5: Build a RAG Chatbot
Now that you’ve set up all components, let’s start to build a simple chatbot. We’ll use the Milvus introduction doc as a private knowledge base. You can replace it your own dataset to customize your RAG chatbot.
url = 'https://raw.githubusercontent.com/milvus-io/milvus-docs/refs/heads/v2.5.x/site/en/about/overview.md'
example_file = 'example_file.md'
response = requests.get(url)
with open(example_file, 'wb') as f:
f.write(response.content)
file_paths = [example_file] # You can replace it with your own file paths.
indexing_pipeline = Pipeline()
indexing_pipeline.add_component("converter", MarkdownToDocument())
indexing_pipeline.add_component("splitter", DocumentSplitter(split_by="sentence", split_length=2))
indexing_pipeline.add_component("embedder", document_embedder)
indexing_pipeline.add_component("writer", DocumentWriter(document_store))
indexing_pipeline.connect("converter", "splitter")
indexing_pipeline.connect("splitter", "embedder")
indexing_pipeline.connect("embedder", "writer")
indexing_pipeline.run({"converter": {"sources": file_paths}})
# print("Number of documents:", document_store.count_documents())
question = "What is Milvus?" # You can replace it with your own question.
retrieval_pipeline = Pipeline()
retrieval_pipeline.add_component("embedder", text_embedder)
retrieval_pipeline.add_component("retriever", retriever)
retrieval_pipeline.connect("embedder", "retriever")
retrieval_results = retrieval_pipeline.run({"embedder": {"text": question}})
# for doc in retrieval_results["retriever"]["documents"]:
# print(doc.content)
# print("-" * 10)
from haystack.utils import Secret
from haystack.components.builders import PromptBuilder
retriever = OpenSearchEmbeddingRetriever(document_store=document_store)
text_embedder = OptimumTextEmbedder(model="sentence-transformers/all-mpnet-base-v2")
text_embedder.warm_up()
prompt_template = """Answer the following query based on the provided context. If the context does
not include an answer, reply with 'I don't know'.\n
Query: {{query}}
Documents:
{% for doc in documents %}
{{ doc.content }}
{% endfor %}
Answer:
"""
rag_pipeline = Pipeline()
rag_pipeline.add_component("text_embedder", text_embedder)
rag_pipeline.add_component("retriever", retriever)
rag_pipeline.add_component("prompt_builder", PromptBuilder(template=prompt_template))
rag_pipeline.add_component("generator", generator)
rag_pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
rag_pipeline.connect("retriever.documents", "prompt_builder.documents")
rag_pipeline.connect("prompt_builder", "generator")
results = rag_pipeline.run({"text_embedder": {"text": question}, "prompt_builder": {"query": question},})
print('RAG answer:\n', results["generator"]["replies"][0])
Optimization Tips
As you build your RAG system, optimization is key to ensuring peak performance and efficiency. While setting up the components is an essential first step, fine-tuning each one will help you create a solution that works even better and scales seamlessly. In this section, we’ll share some practical tips for optimizing all these components, giving you the edge to build smarter, faster, and more responsive RAG applications.
Haystack optimization tips
To optimize Haystack in a RAG setup, ensure you use an efficient retriever like FAISS or Milvus for scalable and fast similarity searches. Fine-tune your document store settings, such as indexing strategies and storage backends, to balance speed and accuracy. Use batch processing for embedding generation to reduce latency and optimize API calls. Leverage Haystack's pipeline caching to avoid redundant computations, especially for frequently queried documents. Tune your reader model by selecting a lightweight yet accurate transformer-based model like DistilBERT to speed up response times. Implement query rewriting or filtering techniques to enhance retrieval quality, ensuring the most relevant documents are retrieved for generation. Finally, monitor system performance with Haystack’s built-in evaluation tools to iteratively refine your setup based on real-world query performance.
OpenSearch optimization tips
To optimize OpenSearch in a Retrieval-Augmented Generation (RAG) setup, fine-tune indexing by enabling efficient mappings and reducing unnecessary stored fields. Use HNSW for vector search to speed up similarity queries while balancing recall and latency with appropriate ef_search and ef_construction values. Leverage shard and replica settings to distribute load effectively, and enable caching for frequent queries. Optimize text-based retrieval with BM25 tuning and custom analyzers for better relevance. Regularly monitor cluster health, index size, and query performance using OpenSearch Dashboards and adjust configurations accordingly.
AmazonBedrock Claude 3.5 Haiku optimization tips
Optimize chunk size for retrieved context to balance relevance and processing efficiency, aiming for 500-800 tokens. Structure inputs with clear separators between user queries and retrieved documents, and use system prompts like "Base responses on the provided context" to reduce hallucinations. Fine-tune parameters: lower temperature (0.2-0.4) for factual accuracy, adjust max_tokens to trim verbose outputs, and enable caching for repeated queries. Preprocess retrieved data to remove noise, validate outputs against source relevance, and implement batch processing for cost-effective scaling. Monitor latency and error rates via Amazon CloudWatch to refine performance.
Optimum all-mpnet-base-v2 optimization tips
To optimize Optimum all-mpnet-base-v2 in a RAG setup, preprocess input text by trimming redundant whitespace, normalizing casing, and splitting long documents into smaller chunks (≤512 tokens) to align with the model’s max sequence length. Use batch processing for embeddings to leverage GPU parallelism, adjusting batch size based on GPU memory. Quantize the model via ONNX Runtime or FP16 precision for faster inference. Cache frequently accessed embeddings to reduce recomputation, and pair with efficient vector search libraries (e.g., FAISS) for low-latency retrieval. Regularly update and prune the document corpus to maintain relevance.
By implementing these tips across your components, you'll be able to enhance the performance and functionality of your RAG system, ensuring it’s optimized for both speed and accuracy. Keep testing, iterating, and refining your setup to stay ahead in the ever-evolving world of AI development.
RAG Cost Calculator: A Free Tool to Calculate Your Cost in Seconds
Estimating the cost of a Retrieval-Augmented Generation (RAG) pipeline involves analyzing expenses across vector storage, compute resources, and API usage. Key cost drivers include vector database queries, embedding generation, and LLM inference.
RAG Cost Calculator is a free tool that quickly estimates the cost of building a RAG pipeline, including chunking, embedding, vector storage/search, and LLM generation. It also helps you identify cost-saving opportunities and achieve up to 10x cost reduction on vector databases with the serverless option.
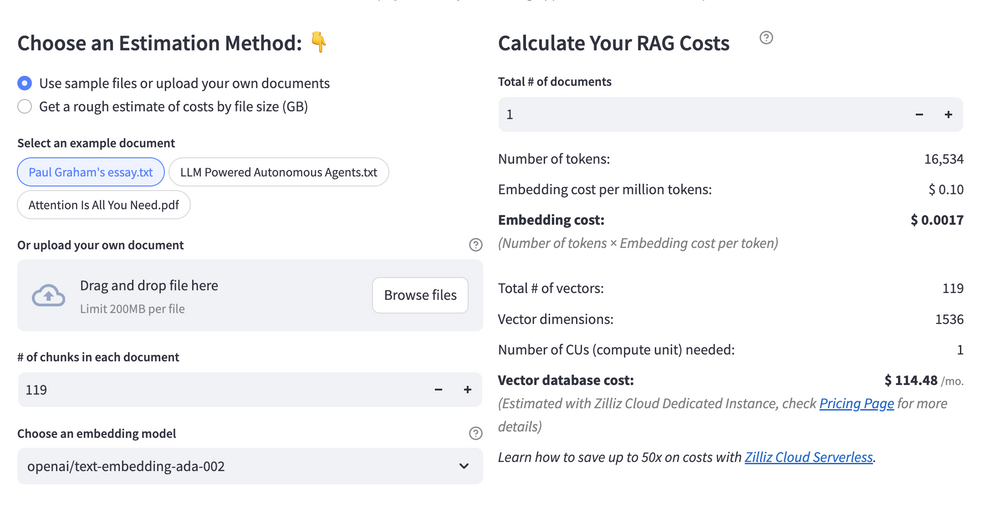 Calculate your RAG cost
Calculate your RAG cost
What Have You Learned?
By diving into this tutorial, you’ve unlocked the power of combining cutting-edge tools to create a robust RAG system! You’ve learned how Haystack acts as the glue, seamlessly connecting your pipeline components with its flexible framework. OpenSearch steps in as your trusty vector database, storing and retrieving dense embeddings generated by the Optimum all-mpnet-base-v2 model—a powerhouse for creating semantic-rich representations of text. Then there’s Claude 3.5 Haiku, Amazon Bedrock’s lightning-fast LLM, which transforms retrieved context into human-like answers while keeping costs low. Together, they form a dynamic trio: your embedding model understands meaning, your vector database finds relevant data at scale, and your LLM crafts responses that feel almost magical. You’ve also seen how tweaking chunk sizes, experimenting with hybrid search strategies, and leveraging metadata filtering can supercharge performance. And let’s not forget that handy RAG cost calculator—your secret weapon for balancing quality and budget!
But here’s the best part: you’re now equipped to turn this knowledge into real-world solutions. Imagine building customer support bots that pull from technical docs instantly, creating research assistants that summarize decades of papers, or prototyping tools that help teams innovate faster. The tutorial didn’t just teach you steps—it handed you a toolkit for creativity. So what’s next? Fire up your IDE, experiment with those optimization tricks, and let Claude 3.5 Haiku’s efficiency inspire you to build fearlessly. Every line of code you write brings us closer to smarter, more intuitive AI applications. The future of search and generation is literally at your fingertips—go make something awesome with it! 🚀
Further Resources
🌟 In addition to this RAG tutorial, unleash your full potential with these incredible resources to level up your RAG skills.
- How to Build a Multimodal RAG | Documentation
- How to Enhance the Performance of Your RAG Pipeline
- Graph RAG with Milvus | Documentation
- How to Evaluate RAG Applications - Zilliz Learn
- Generative AI Resource Hub | Zilliz
We'd Love to Hear What You Think!
We’d love to hear your thoughts! 🌟 Leave your questions or comments below or join our vibrant Milvus Discord community to share your experiences, ask questions, or connect with thousands of AI enthusiasts. Your journey matters to us!
If you like this tutorial, show your support by giving our Milvus GitHub repo a star ⭐—it means the world to us and inspires us to keep creating! 💖
- Introduction to RAG
- Key Components We'll Use for This RAG Chatbot
- Step 1: Install and Set Up Haystack
- Step 2: Install and Set Up Amazon Bedrock Claude 3.5 Haiku
- Step 3: Install and Set Up Optimum all-mpnet-base-v2
- Step 4: Install and Set Up OpenSearch
- Step 5: Build a RAG Chatbot
- Optimization Tips
- RAG Cost Calculator: A Free Tool to Calculate Your Cost in Seconds
- What Have You Learned?
- Further Resources
- We'd Love to Hear What You Think!
Content
Vector Database at Scale
Zilliz Cloud is a fully-managed vector database built for scale, perfect for your RAG apps.
Try Zilliz Cloud for Free