




Понимание алгоритма CURE: всестороннее исследование кластеризации с представителями
 Визуальное представление кластеризации
Визуальное представление кластеризации
Рисунок 1: Визуальное представление кластеризации
Как компании могут ориентироваться на постоянно меняющемся рынке и эффективно группировать клиентов со схожими паттернами? Традиционные методы кластеризации часто оказываются недостаточными при работе с нерегулярными формами данных и выбросами. Сложность современных наборов данных требует более умных и адаптивных решений.
Здесь на помощь приходит алгоритм CURE (Clustering Using Representatives) — эффективный метод, который устраняет ограничения стандартных подходов к кластеризации. CURE использует выборку репрезентативных точек, чтобы отличаться от классических методов кластеризации, тем самым повышая свою интеллектуальность при распознавании сложных распределений данных. Эти репрезентативные точки приближаются к среднему значению кластера, что делает алгоритм более продвинутым, позволяя ему работать с кластерами произвольной формы.
CURE может становиться вычислительно затратным при применении к большим наборам данных. Несмотря на это, его подход к обработке аномалий и сложных кластеров остается весьма эффективным. Давайте обсудим работу алгоритма CURE, рассмотрев его основной подход, преимущества и практические применения. Мы также разберем сложности, с которыми вы можете столкнуться при реализации CURE.
Что такое алгоритм CURE?
Алгоритм CURE использует иерархический подход к кластеризации, который выявляет сложные формы кластеров и эффективно обрабатывает выбросы. ****В отличие от алгоритмов на основе центроидов, таких как k-means, CURE представляет кластеры с помощью нескольких репрезентативных точек. Эти точки смещаются к средним значениям кластеров с фиксированным коэффициентом сжатия, чтобы создавать устойчивые представления кластеров.
CURE демонстрирует большую гибкость, чем k-means, поскольку его конструкция позволяет работать с различными типами нерегулярных наборов данных. Его способность преодолевать ограничения традиционных алгоритмов, связанные с выпуклыми или равноудаленными кластерами, приводит к точному обнаружению границ и форм кластеров.
Как это работает
Алгоритмы CURE включают несколько шагов для получения итогового результата. Давайте разберем, как они выбирают данные для создания кластера без выбросов.
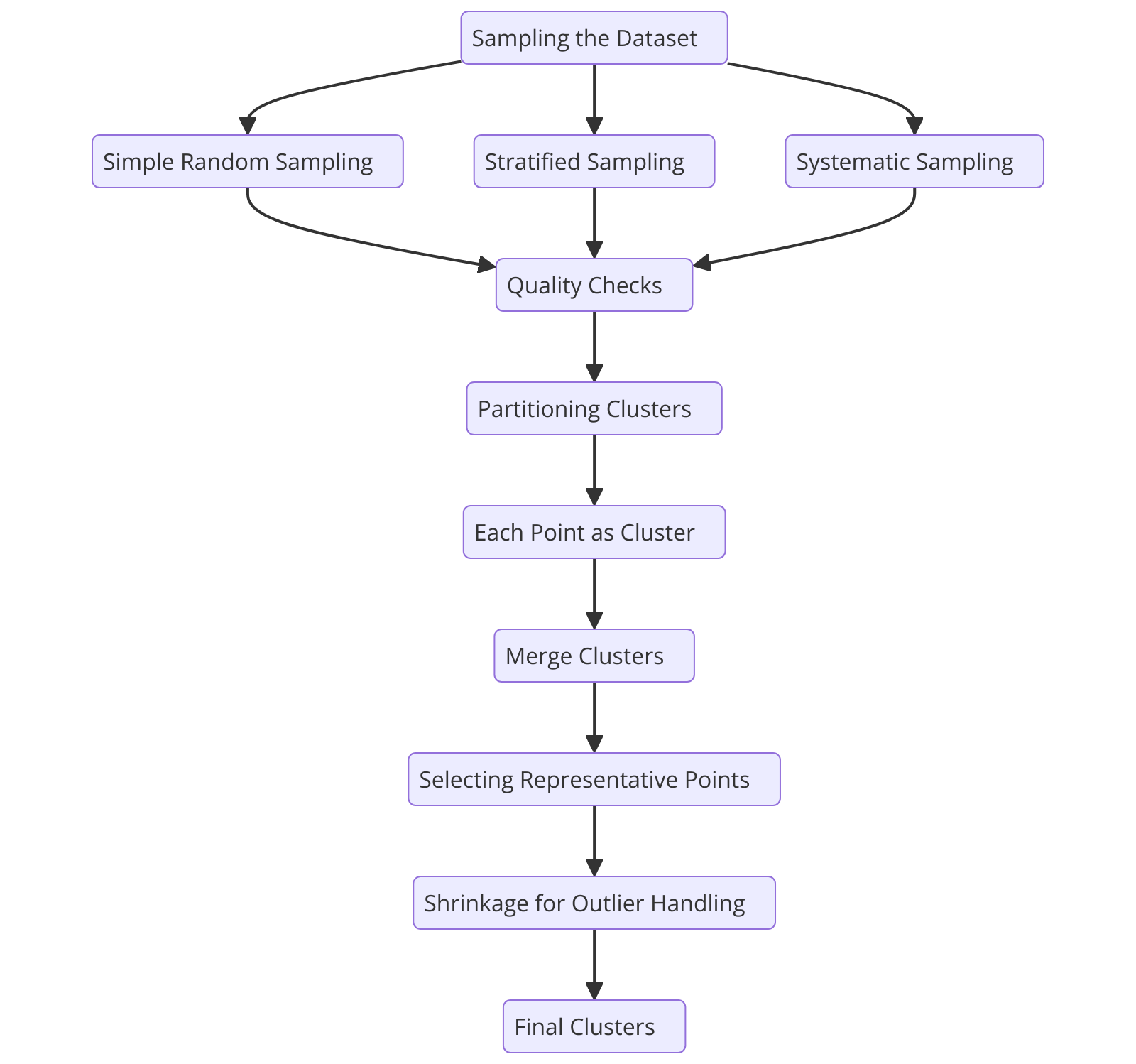 Блок-схема процесса алгоритма кластеризации CURE
Блок-схема процесса алгоритма кластеризации CURE
Рисунок 2: Блок-схема процесса алгоритма кластеризации CURE
Блок-схема процесса алгоритма кластеризации CURE
Чтобы понять, как работает алгоритм CURE, давайте разберем его процесс шаг за шагом, начиная с выборки набора данных.
Выборка набора данных
CURE начинает с выбора репрезентативной случайной выборки из набора данных. Процесс выборки уменьшает количество точек данных, ускоряя вычисления при сохранении целостности кластеров.
Простая случайная выборка обеспечивает быструю реализацию, но не позволяет охватить критически важные граничные случаи. Это приводит к недостаточному представлению миноритарных групп в несбалансированных наборах данных. Стратифицированная выборка становится необходимой, когда требуется сохранить пропорциональное распределение различных классов в данных.
Этот метод гарантирует, что все значимые небольшие подмножества данных остаются видимыми для анализа. Другой метод — систематическая выборка, которая выбирает точки данных через регулярную интервальную систему. Систематическая выборка особенно эффективна для временных рядов и упорядоченных данных, поскольку сохраняет временную природу и последовательный порядок в наборах данных.
Проверки качества подтверждают соответствие выборки распределению исходного набора данных после сбора. Сравнение средних значений, уровней дисперсии и характеристик распределения помогает оценить сходство между полученной выборкой и полным исходным набором данных. Строгие стратегии выборки, реализуемые CURE, позволяют последующей кластеризации точно отражать сложность и разнообразие всего набора данных.
Разбиение кластеров
После выборки набора данных CURE применяет иерархический метод, который делит данные на управляемые подмножества. В частности, он использует стратегию кластеризации слиянием снизу вверх. Алгоритм измеряет сходство точек данных с помощью метрик расстояния, использующих евклидово расстояние или манхэттенское расстояние. Метрики расчета расстояния необходимы для определения близости точек и создания прочной основы для эффективного слияния кластеров.
В начале процесса каждая точка данных функционирует как отдельный кластер, чтобы представить детализированную природу данных. Алгоритм выполняет последовательные слияния кластеров, используя критерии близости для группировки схожих точек. Алгоритм продолжает операции слияния кластеров до тех пор, пока не будет достигнуто заданное число кластеров или не активируется альтернативное условие завершения.
Процесс выбора групп в CURE создает кластеры, которые соответствуют естественным категориям, присутствующим в данных. Используя иерархическое разбиение, CURE преодолевает ограничения традиционных алгоритмов кластеризации, которые требуют, чтобы кластеры имели выпуклые формы.
Выбор репрезентативных точек
CURE выбирает несколько репрезентативных точек для представления каждого кластера, а не полагается на один центроид. Эти точки, тщательно выбранные из кластера, отражают его пространственный диапазон и структуру. CURE достигает лучшего распознавания границ кластеров и понимания внутренней структуры, используя несколько точек для представления каждого кластера.
После выбора репрезентативных точек алгоритм перемещает их к среднему значению кластера с заданной величиной сжатия. Процедура сжатия делает алгоритм менее чувствительным к выбросам, перемещая удаленные точки к центральным точкам кластера.
Успех алгоритма в значительной степени зависит от того, сколько репрезентативных точек используется во время выполнения. Правильный выбор репрезентативных точек имеет решающее значение. Использование малого числа репрезентативных точек может не отразить сложность кластера, тогда как использование слишком большого числа может увеличить вычислительные затраты.
Слияние кластеров
После определения репрезентативных точек алгоритм объединяет кластеры с помощью систематического итеративного подхода. Процедура зависит от измерения расстояния между репрезентативными точками разных кластеров. Предопределенные метрики, такие как евклидово расстояние, используются для измерения расстояний, тем самым устраняя конфликты при поиске ближайших кластеров.
Алгоритм определяет, какие пары кластеров имеют наименьшее расстояние между репрезентативными точками на каждом этапе оценки. Алгоритм принимает точные решения о слиянии кластеров, сохраняя пространственные отношения и естественные шаблоны согласования данных внутри кластеров.
Процесс повторяется до тех пор, пока не будут достигнуты некоторые заранее определенные кластеры или не будет выполнен другой критерий завершения. Критерий завершения зависит от таких факторов, как минимальное расстояние между кластерами или максимально допустимое сходство внутри кластеров. Это гарантирует, что полученные кластеры соответствуют естественным группировкам в данных и достаточно гибки, чтобы отражать нерегулярные и сложные формы.
Обработка выбросов
Когда существуют выбросы, результаты искажаются, поскольку они вызывают неправильные формы кластеров и неверную интерпретацию структуры данных. Алгоритм CURE решает эти ограничения, используя несколько репрезентативных точек, которые точно определяют фактическую форму и распределение кластеров.
Механизм сжатия представляет собой еще одно фундаментальное усовершенствование в CURE, делая систему более устойчивой и повышая ее сложность. Эта намеренная корректировка снижает чувствительность алгоритма к экстремальным значениям, перемещая репрезентативные точки к центральным позициям кластера.
Коэффициент сжатия является настраиваемым параметром, который позволяет пользователям изменять его значение в соответствии с характеристиками набора данных. Это обеспечивает гибкое смягчение влияния выбросов при сохранении естественных границ кластеров.
Сравнение с другими методами кластеризации
Инновационный подход алгоритма CURE отличает его от других популярных методов кластеризации. Вот более глубокое сравнение:
| Аспект | CURE | k-means | DBSCAN |
| Представление | Несколько репрезентативных точек | Один центроид | На основе плотности |
| Обработка выбросов | Отличная | Плохая | Хорошая |
| Гибкость формы | Произвольные формы | Только выпуклые формы | Произвольные формы |
| Масштабируемость | Высокая (с выборкой) | Высокая | Умеренная |
| Сложность | Выше | Ниже | Умеренная |
Преимущества и вызовы
При применении к реальным сценариям CURE предлагает сочетание преимуществ и вызовов. Давайте обсудим, как CURE может приносить пользу, одновременно создавая определенные препятствия в практических приложениях.
Преимущества
Масштабируемость: CURE достигает масштабируемости благодаря своей стратегии выборки данных, которая снижает вычислительную нагрузку без ущерба для точности кластеризации.
Надежность: CURE повышает надежность, используя несколько репрезентативных точек для захвата формы и структуры кластера. Таким образом, кластеризация будет давать надежные и стабильные результаты, даже когда данные зашумлены и непоследовательны.
Универсальность: CURE выявляет кластеры любой формы и обрабатывает нерегулярности или невыпуклые структуры. Это особенно полезно в разнообразных наборах данных, где традиционные методы, такие как k-means, не могут представить их точно.
Вызовы
Чувствительность к параметрам: Алгоритм требует точной настройки параметров для коэффициента сжатия и количества репрезентативных точек. Поиск правильного баланса имеет решающее значение для оптимальной производительности и требует как экспериментов, так и предметной экспертизы.
Смещение выборки: Недостаточные методы выборки приводят к неточному формированию кластеров и плохим результатам. Поддержание несмещенных репрезентативных выборок необходимо для обеспечения сохранения структур набора данных.
Вычислительные требования: Проблемы масштабируемости CURE возрастают при работе с большими, высокоразмерными или неструктурированными наборами данных из-за необходимости многократных вычислений расстояний. Методы, такие как PCA и параллельные вычисления, могут снижать размерность, уменьшая вычислительные затраты при сохранении ключевых взаимосвязей.
Варианты использования
Чтобы увидеть практическое влияние алгоритма CURE, давайте рассмотрим, как он может решать реальные задачи кластеризации в различных областях.
Обнаружение аномалий
CURE эффективно выявляет аномалии, группируя типичные транзакции и изолируя нерегулярные, которые могут указывать на мошенничество. Это позволяет финансовым учреждениям быстро обнаруживать подозрительную активность и усиливать меры безопасности.
Сегментация рынка
В маркетинге CURE может сегментировать клиентов на основе таких атрибутов, как покупательское поведение, демографические данные и предпочтения. Это позволяет проводить целевые маркетинговые кампании, улучшать удержание клиентов и прогнозировать будущие тенденции. Например, ценных клиентов можно объединить в кластер для эксклюзивных предложений, чтобы повысить лояльность.
Анализ геопространственных данных
Градостроители могут применять CURE для категоризации регионов со схожим климатом, плотностью населения или развитием инфраструктуры. Ученые-экологи могут использовать его для кластеризации территорий по их биоразнообразию и доступности ресурсов при изучении экосистем.
Кластеризация документов
CURE демонстрирует отличную эффективность в интеллектуальном анализе текста, группируя обширные каталоги документов на основе их стандартных тем и тематик. Поисковые системы используют этот метод для создания точных категорий результатов, которые позволяют пользователям быстро находить релевантный контент.
CURE позволяет рекомендательным системам выявлять статьи и научные работы со схожей тематикой. Это приводит к персонализированным, содержательным рекомендациям для пользователей. CURE может эффективно кластеризовать разнообразные текстовые структуры, чтобы поддерживать точные результаты группировки независимо от сложности и размера многомерных наборов данных. Алгоритм хорошо адаптируется к многоязычным текстовым наборам данных и неоднородным записям данных, что делает его важным решением для современных платформ информационного поиска.
Заключение
Алгоритм кластеризации CURE представляет собой значительный прорыв в методах кластеризации. Он обеспечивает эффективное и масштабируемое решение для современных задач работы с данными. Алгоритм использует репрезентативные точки наряду с иерархическими принципами, чтобы преодолеть ограничения традиционной кластеризации, обеспечивая при этом гибкие и точные результаты. Хотя алгоритм сталкивается с проблемами оптимизации параметров и вычислительными требованиями, его способность работать с зашумленными данными и сложными паттернами имеет важное значение для множества бизнес-секторов.
Растущая сложность наборов данных в будущем продолжит повышать потребность в гибких алгоритмах кластеризации, таких как CURE. Специалисты по данным и практики машинного обучения, которые понимают принципы CURE, смогут максимально раскрыть его потенциал для получения значимых инсайтов из сложных наборов данных.
Часто задаваемые вопросы
- Что делает CURE уникальным по сравнению с k-means?
CURE отличается от k-means тем, что использует несколько репрезентативных точек вместо одного центроида кластера. Этот метод позволяет обнаруживать нерегулярные формы кластеров и нелинейные закономерности в сложных наборах данных без необходимости предполагать выпуклость кластеров.
- Как CURE работает с большими наборами данных?
CURE управляет большими наборами данных с помощью методов случайной выборки, которые минимизируют требования к вычислительной обработке. Стратегия выборки позволяет алгоритму обрабатывать сокращенные подмножества данных, сохраняя целостность взаимосвязей между кластерами.
- Какова роль коэффициента сжатия в CURE?
Коэффициент сжатия CURE контролирует расстояние, на которое репрезентативные точки перемещаются к среднему положению своего кластера. Этот фактор позволяет пользователям достигать оптимального баланса между точностью и устойчивостью. Успех реализаций CURE в значительной степени зависит от определения правильного коэффициента сжатия для каждого набора данных.
- Может ли CURE работать с многомерными данными?
Использование алгоритмов CURE для многомерных данных требует предварительной обработки с помощью таких методов, как PCA. Обработка многомерных данных требует эффективного сокращения размерности, чтобы находить важные закономерности даже при сохранении простоты данных.
- Каковы типичные применения CURE?
Типичные применения CURE включают обнаружение аномалий, сегментацию рынка, геопространственный анализ и анализ кластеризации документов. Он может выявлять необычные финансовые паттерны для обнаружения мошенничества, группировать клиентов по поведению и анализировать регионы на основе характеристик.
Связанные ресурсы
https://zilliz.com/ai-faq/how-are-embeddings-used-for-clustering
https://zilliz.com/ai-faq/how-does-clustering-improve-vector-search
https://zilliz.com/ai-faq/how-does-swarm-intelligence-improve-data-clustering
https://zilliz.com/ai-faq/what-is-graph-clustering-in-knowledge-graphs
https://zilliz.com/ai-faq/what-are-the-most-common-algorithms-for-anomaly-detection
- Понимание алгоритма CURE: всестороннее исследование кластеризации с представителями
- Что такое алгоритм CURE?
- Как это работает
- Блок-схема процесса алгоритма кластеризации CURE
- Сравнение с другими методами кластеризации
- Преимущества и вызовы
- Варианты использования
- Заключение
- Часто задаваемые вопросы
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно