




Как Airtable построила и масштабировала векторную инфраструктуру с помощью Milvus

Запросы с низкой задержкой
предсказуемая производительность критически важна для доверия пользователей
Высокопроизводительные операции записи
базы постоянно меняются, и эмбеддинги должны оставаться синхронизированными
Горизонтальная масштабируемость
система должна поддерживать миллионы независимых баз
Этот пост был изначально опубликован в Airtable Medium и перепубликован здесь с разрешения.
По мере того как семантический поиск в Airtable эволюционировал от концепции до ключевой продуктовой функции, команда Data Infrastructure столкнулась с задачей его масштабирования. Как подробно описано в нашем предыдущем посте о создании системы эмбеддингов, мы уже спроектировали надежный, в конечном счете согласованный прикладной слой для управления жизненным циклом эмбеддингов. Но в нашей архитектурной схеме все еще отсутствовал один критически важный компонент: сама векторная база данных.
Нам был нужен движок хранения, способный индексировать и обслуживать миллиарды эмбеддингов, поддерживать масштабную мультитенантность и сохранять целевые показатели производительности и доступности в распределенной облачной среде. Это история о том, как мы спроектировали, укрепили и развили нашу платформу векторного поиска, чтобы она стала одним из ключевых столпов инфраструктурного стека Airtable.
Контекст
В Airtable наша цель — помогать клиентам работать со своими данными мощными и интуитивно понятными способами. С появлением все более мощных и точных LLM функции, использующие семантическое значение ваших данных, стали центральными для нашего продукта.
Как мы используем семантический поиск
Omni (AI-чат Airtable) отвечает на реальные вопросы по большим наборам данных
Представьте, что вы задаете вопрос на естественном языке к своей базе (базе данных) с полумиллионом строк и получаете правильный, богатый контекстом ответ. Например:
«Что клиенты в последнее время говорят о времени работы батареи?»
На небольших наборах данных можно отправить все строки напрямую в LLM. В масштабе это быстро становится невыполнимым. Вместо этого нам была нужна система, способная:
- Понимать семантическое намерение запроса
- Извлекать наиболее релевантные строки с помощью поиска по векторному сходству
- Передавать эти строки как контекст в LLM
Это требование определило почти каждое последующее проектное решение: Omni должен был ощущаться мгновенным и интеллектуальным даже на очень больших базах.
Рекомендации связанных записей: смысл важнее точных совпадений
Семантический поиск также улучшает ключевую функцию Airtable: связанные записи. Пользователям нужны предложения связей на основе контекста, а не точных текстовых совпадений. Например, описание проекта может подразумевать связь с «Team Infrastructure», ни разу не используя именно эту фразу.
Для предоставления таких предложений по запросу требуется высококачественное семантическое извлечение с согласованной, предсказуемой задержкой.
Наши проектные приоритеты
Чтобы поддерживать эти функции и многое другое, мы выстроили систему вокруг 4 целей:
- Запросы с низкой задержкой (500 мс p99): предсказуемая производительность критически важна для доверия пользователей
- Записи с высокой пропускной способностью: базы постоянно меняются, и эмбеддинги должны оставаться синхронизированными
- Горизонтальная масштабируемость: система должна поддерживать миллионы независимых баз
- Self-hosting: все данные клиентов должны оставаться внутри инфраструктуры, контролируемой Airtable
Эти цели определили каждое последующее архитектурное решение.
Оценка поставщиков векторных баз данных
В конце 2024 года мы оценили несколько вариантов векторных баз данных и в итоге выбрали Milvus на основе трех ключевых требований.
- Во-первых, мы отдали приоритет self-hosted-решению, чтобы обеспечить конфиденциальность данных и сохранить детальный контроль над нашей инфраструктурой.
- Во-вторых, наша write-heavy-нагрузка и всплескообразные паттерны запросов требовали системы, способной эластично масштабироваться, сохраняя низкую и предсказуемую задержку.
- Наконец, нашей архитектуре требовалась строгая изоляция между миллионами клиентских тенантов.
Milvus оказался наиболее подходящим вариантом: его распределенная природа поддерживает масштабную мультитенантность и позволяет нам независимо масштабировать прием данных, индексирование и выполнение запросов, обеспечивая производительность при сохранении предсказуемых затрат.
Архитектурный дизайн
После выбора технологии нам нужно было определить архитектуру для представления уникальной формы данных Airtable: миллионов отдельных “bases”, принадлежащих разным клиентам.
Проблема партиционирования
Мы оценили две основные стратегии партиционирования данных:
Вариант 1: Общие партиции
Несколько bases используют одну партицию, а запросы ограничиваются фильтрацией по base id. Это улучшает использование ресурсов, но добавляет дополнительные накладные расходы на фильтрацию и усложняет удаление base.
Вариант 2: Одна base на партицию
Каждая Airtable base сопоставляется со своей собственной физической партицией в Milvus. Это обеспечивает строгую изоляцию, позволяет быстро и просто удалять base и избегает влияния постфильтрации после запроса на производительность.
Итоговая стратегия
Мы выбрали вариант 2 за его простоту и строгую изоляцию. Однако ранние тесты показали, что создание 100k партиций в одной коллекции Milvus вызывало значительное снижение производительности:
- Задержка создания партиции выросла с ~20 ms до ~250 ms
- Время загрузки партиций превысило 30 секунд
Чтобы решить эту проблему, мы ограничили количество партиций на коллекцию. Для каждого кластера Milvus мы создаем 400 коллекций, в каждой из которых не более 1,000 партиций. Это ограничивает общее количество bases на кластер до 400k, а новые кластеры выделяются по мере подключения дополнительных клиентов.
Индексация и полнота результатов
Выбор индекса оказался одним из самых значимых компромиссов в нашей системе. Когда партиция загружается, ее индекс кэшируется в памяти или на диске. Чтобы найти баланс между показателем полноты, размером индекса и производительностью, мы протестировали несколько типов индексов.
- IVF-SQ8: Обеспечил небольшой объем памяти, но более низкую полноту.
- HNSW: Дает лучшую полноту (99%-100%), но требует много памяти.
- DiskANN: Обеспечивает полноту, схожую с HNSW, но с более высокой задержкой запросов
В конечном итоге мы выбрали HNSW из-за его превосходной полноты и характеристик производительности.
Уровень приложения
На высоком уровне конвейер семантического поиска Airtable включает два основных потока:
- Поток ingest: Преобразовать строки Airtable в embeddings и сохранить их в Milvus
- Поток запросов: Встроить пользовательские запросы, получить релевантные row IDs и предоставить контекст LLM
Оба потока должны работать непрерывно и надежно в масштабе, и ниже мы рассмотрим каждый из них. Ниже мы рассмотрим каждый из них.
Поток ingest: поддержание синхронизации Milvus с Airtable
Когда пользователь открывает Omni, Airtable начинает синхронизацию его base с Milvus. Мы создаем партицию, затем обрабатываем строки блоками, генерируя embeddings и выполняя upsert в Milvus. С этого момента мы фиксируем любые изменения, внесенные в base, и повторно создаем embedding и выполняем upsert этих строк, чтобы поддерживать согласованность данных.
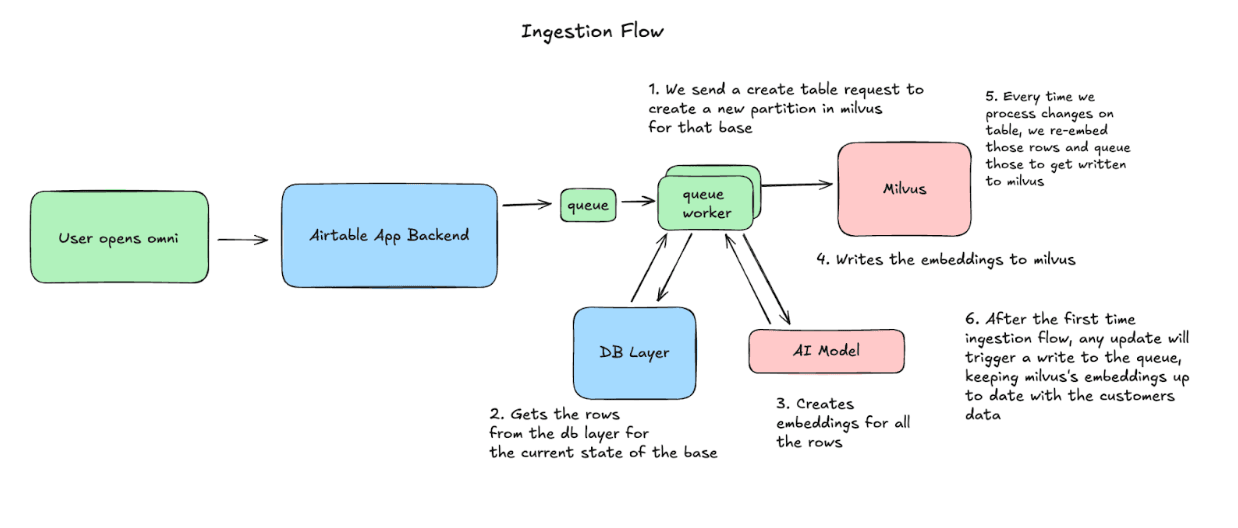
Поток запросов: как мы используем данные
На стороне запросов мы создаем embedding запроса пользователя и отправляем его в Milvus, чтобы получить наиболее релевантные row IDs. Затем мы извлекаем последние версии этих строк и включаем их в качестве контекста в запрос к LLM.
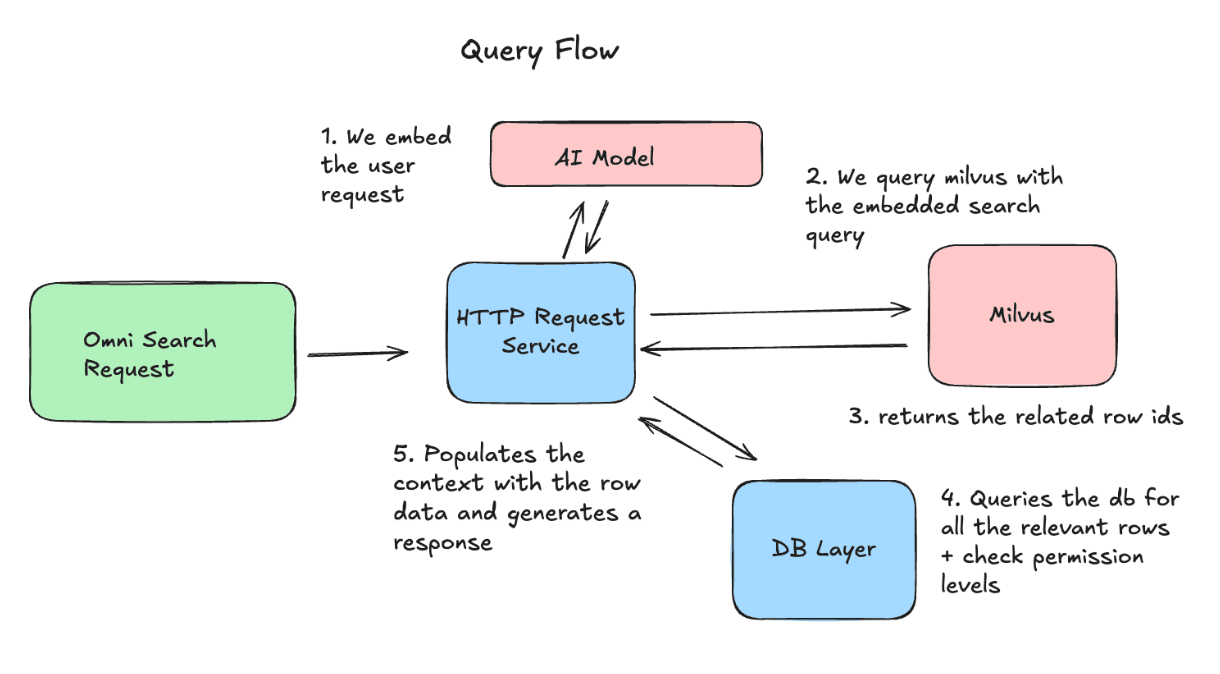
Операционные проблемы и как мы их решили
Построение архитектуры семантического поиска — это одна задача; ее надежная эксплуатация для сотен тысяч bases — совсем другая. Ниже приведены несколько ключевых операционных уроков, которые мы усвоили на этом пути.
Развертывание
Мы развертываем Milvus через его Kubernetes CRD с помощью Milvus operator, что позволяет нам декларативно определять кластеры и управлять ими. Каждое изменение, будь то обновление конфигурации, улучшение клиента или обновление Milvus, проходит через unit tests и нагрузочный тест по требованию, который имитирует production traffic перед развертыванием для пользователей.
В версии 2.5 кластер Milvus состоит из следующих основных компонентов:
- Query Nodes хранят векторные индексы в памяти и выполняют векторный поиск
- Data Nodes обрабатывают загрузку и уплотнение данных, а также сохраняют новые данные в хранилище
- Index Nodes создают и поддерживают векторные индексы, чтобы поиск оставался быстрым по мере роста данных
- Coordinator Node оркестрирует всю активность кластера и назначение шардов
- Proxy nodes маршрутизируют API-трафик и балансируют нагрузку между узлами
- Kafka обеспечивает основу журналирования/потоковой передачи для внутреннего обмена сообщениями и потоков данных
- Etcd хранит метаданные кластера и состояние координации
Благодаря автоматизации на основе CRD и строгому конвейеру тестирования мы можем быстро и безопасно развертывать обновления.
Наблюдаемость: понимание состояния системы от начала до конца
Мы отслеживаем систему на двух уровнях, чтобы семантический поиск оставался быстрым и предсказуемым.
На уровне инфраструктуры мы отслеживаем использование CPU, памяти и состояние pod во всех компонентах Milvus. Эти сигналы показывают, работает ли кластер в безопасных пределах, и помогают нам выявлять такие проблемы, как насыщение ресурсов или неработоспособные узлы, до того как они повлияют на пользователей.
На уровне сервиса мы сосредоточены на том, насколько хорошо каждая база справляется с нашими нагрузками по загрузке данных и запросам. Такие метрики, как пропускная способность уплотнения и индексирования, дают нам представление о том, насколько эффективно загружаются данные. Уровни успешности запросов и задержка дают нам понимание пользовательского опыта при запросах к данным, а рост разделов позволяет понять, как растут наши данные, чтобы мы получили предупреждение, если потребуется масштабирование.
Ротация узлов
По причинам безопасности и соответствия требованиям мы регулярно ротируем узлы Kubernetes. В кластере векторного поиска это нетривиально:
- По мере ротации query nodes координатор будет перераспределять данные в памяти между query nodes
- Kafka и Etcd хранят информацию с состоянием и требуют кворума и непрерывной доступности
Мы решаем это с помощью строгих бюджетов прерываний и политики ротации по одному узлу за раз. Координатору Milvus дается время на перебалансировку, прежде чем следующий узел будет заменен. Такая аккуратная оркестрация сохраняет надежность, не снижая нашу скорость работы.
Выгрузка холодных разделов
Одной из наших крупнейших операционных побед стало осознание того, что наши данные имеют явные паттерны горячего/холодного доступа. Проанализировав использование, мы обнаружили, что только ~25% данных в Milvus записываются или читаются в течение данной недели. Milvus позволяет нам выгружать целые разделы, освобождая память на Query Nodes. Если эти данные понадобятся позже, мы можем загрузить их обратно за считанные секунды. Это позволяет нам держать горячие данные в памяти и выгружать остальные, снижая затраты и позволяя нам со временем масштабироваться эффективнее.
Восстановление данных
Прежде чем широко развернуть Milvus, нам нужно было быть уверенными, что мы сможем быстро восстановиться после любого сценария отказа. Хотя большинство проблем покрывается встроенной отказоустойчивостью кластера, мы также предусмотрели редкие случаи, когда данные могут быть повреждены или система может перейти в невосстановимое состояние.
В таких ситуациях наш путь восстановления прост. Сначала мы поднимаем свежий кластер Milvus, чтобы почти сразу возобновить обслуживание трафика. Как только новый кластер запускается, мы проактивно заново создаем эмбеддинги для наиболее часто используемых баз, затем лениво обрабатываем остальные по мере обращения к ним. Это минимизирует простой для наиболее востребованных данных, пока система постепенно заново создает согласованный семантический индекс.
Что дальше
Наша работа с Milvus заложила прочную основу для семантического поиска в Airtable: обеспечивая быстрые и осмысленные AI-возможности в масштабе. Теперь, когда эта система работает, мы изучаем более богатые конвейеры извлечения и более глубокие AI-интеграции во всем продукте. Впереди много захватывающей работы, и мы только начинаем.
Спасибо всем нынешним и бывшим Airtablets из Data Infrastructure и всей организации, которые внесли вклад в этот проект: Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
Об Airtable
Airtable — ведущая платформа для цифровых операций, которая позволяет организациям создавать пользовательские приложения, автоматизировать рабочие процессы и управлять общими данными в масштабе предприятия. Разработанная для поддержки сложных кросс-функциональных процессов, Airtable помогает командам создавать гибкие системы для планирования, координации и выполнения задач на основе единого источника достоверной информации. По мере расширения своей платформы на базе ИИ Airtable использует такие технологии, как Milvus, которые играют важную роль в укреплении инфраструктуры поиска, необходимой для более быстрых и интеллектуальных продуктовых возможностей.
- Контекст
- Как мы используем семантический поиск
- Наши проектные приоритеты
- Оценка поставщиков векторных баз данных
- Архитектурный дизайн
- Проблема партиционирования
- Индексация и полнота результатов
- Уровень приложения
- Поток ingest: поддержание синхронизации Milvus с Airtable
- Поток запросов: как мы используем данные
- Операционные проблемы и как мы их решили
- Наблюдаемость: понимание состояния системы от начала до конца
- Ротация узлов
- Выгрузка холодных разделов
- Восстановление данных
- Что дальше
- Об Airtable
Контент
Пример использования
Отрасль
AI SaaS