




Представляем Loon: новый механизм хранения для векторных данных, которые никогда не перестают меняться
Ключевые выводы
Это длинный и подробный инженерный разбор, поэтому вот ключевые моменты, прежде чем мы перейдем к деталям.
- Наборы данных ИИ — это не статические таблицы. Одни и те же строки постоянно меняются, поскольку команды заменяют embedding-модели, добавляют разреженные векторы, пересматривают captions, дозаполняют labels, перестраивают индексы и запускают офлайн-анализ.
- Традиционные схемы хранения ломаются в трех аспектах: длинные векторные столбцы делают backfill дорогим, один формат файлов не может одинаково хорошо обслуживать и сканирования, и точечные чтения, а закрытое хранилище базы данных вынуждает внешние конвейеры создавать дополнительные копии источника истины.
- Loon — это новый движок хранения для Milvus и Zilliz Vector Lakebase. Он построен вокруг гибридных форматов файлов, выравнивания по row ID и Manifest, который определяет версионированное состояние набора данных.
- Цель — дать одному векторному набору данных возможность поддерживать онлайн-поиск, офлайн-анализ, backfill, compaction и внешние вычисления без постоянного копирования, перезаписи или повторного импорта данных.
Введение
Некоторое время существовал один аргумент против векторных баз данных, который звучал разумно.
Традиционные базы данных уже хранят целые числа, строки, JSON, blobs и индексы. Почему бы не добавить тип _vector_, построить рядом с ним ANN-индекс и на этом закончить?
Для раннего семантического поиска этого достаточно. Векторный столбец плюс индекс могут поддержать демо, небольшое RAG-приложение или внутреннюю функцию поиска. Проблема проявляется позже, когда набор данных начинает вести себя меньше как таблица и больше как система данных ИИ.
Производственный векторный набор данных имеет строки, первичные ключи, скалярные поля и столбцы, по которым можно выполнять запросы. В этом смысле он похож на таблицу базы данных. Но у него также есть масштаб и характер рабочих процессов data lake. Он может содержать сотни миллионов записей. Его многократно читают и переписывают Spark, Ray, DuckDB, обучающие конвейеры, задачи оценки и системы качества данных.
Он также зависит от объектного хранилища. Исходными объектами часто являются видео, изображения, PDF, аудиофайлы или веб-документы, которые остаются в S3, GCS, OSS или другом объектном хранилище. База данных хранит ссылки, метаданные, производные признаки и индексы. Затем она добавляет то, для управления чем традиционные модели хранения не были предназначены как объектами первого класса: dense embeddings, sparse vectors, captions, векторные индексы, текстовые индексы, delete logs, статистику, версии моделей, версии парсеров, ссылки на внешние blobs и версионные связи между всем этим.
Именно здесь подход “просто добавить векторный столбец” начинает ломаться. Вопрос не в том, может ли база данных хранить байты векторов. Многие системы могут. Более сложный вопрос — может ли модель хранения справиться с тем, как меняются векторные данные, как к ним выполняются запросы и как они совместно используются в стеке данных ИИ.
Именно поэтому мы создали Loon, новый движок хранения для Milvus и Zilliz Vector Lakebase (следующей эволюции Zilliz Cloud).
Loon спроектирован вокруг трех идей:
- Использовать разные физические форматы для разных типов столбцов.
- Выравнивать эти столбцы через общее пространство row ID.
- Использовать Manifest для определения версионированного состояния набора данных.
Чтобы понять, почему эти компоненты важны, начнем с типичного мультимодального рабочего процесса.
Векторный набор данных на самом деле никогда не бывает завершенным.
Представьте команду ИИ, создающую видеодатасет для мультимодального обучения.
Длинное видео загружается в объектное хранилище. Конвейер нарезает его на клипы на основе смены сцен, границ кадров или временных окон. Слишком длинные или слишком короткие, размытые, дублирующиеся или низкокачественные клипы отфильтровываются. Оставшиеся клипы оцениваются aesthetic-моделью, captioned другой моделью, embedded vision-language моделью и сохраняются в векторной базе данных для поиска, дедупликации и фильтрации обучающих данных.
На высоком уровне рабочий процесс выглядит просто:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Но набор данных не поступает в полностью сформированном виде.
- В первую неделю таблица может содержать только
clip_id,video_id,start_offsetиduration. - Во вторую неделю команда добавляет
aesthetic_score. - В третью неделю запускается модель для создания подписей, и каждый клип получает
caption. - В четвертую неделю первая модель эмбеддингов выходит в онлайн, и каждый клип получает 768-мерный CLIP-эмбеддинг.
- Месяц спустя команда меняет модели и выполняет обратное заполнение
embedding_v2, теперь уже с 1024 измерениями. - Два месяца спустя гибридный поиск становится обязательным требованием, поэтому команда добавляет столбец разреженного вектора.
- Три месяца спустя подписи проходят ручную проверку и должны быть исправлены на месте.
Набор данных так и не был завершен. Он продолжал накапливать новые интерпретации одних и тех же базовых строк.
Это одно из ключевых различий между векторными данными и традиционными бизнес-данными. Одна и та же строка обрабатывается снова и снова. А масштаб превращает это из неудобства в проблему хранения: мультимодальные наборы данных часто насчитывают не миллионы записей, а сотни миллионов или миллиарды. LAION-5B — полезный ориентир для понимания формы таких данных: миллиарды пар «изображение–текст», каждая с метаданными, подписями и эмбеддингами. Поэтому сложность заключается не в первой вставке. Сложность — во всем, что происходит после того, как набор данных начинает эволюционировать. Эта эволюция выявляет три проблемы.
Первая проблема: длинные столбцы делают усиление записи дорогостоящим
Колоночные форматы, такие как Parquet, отлично подходят для многих аналитических нагрузок. Они хорошо работают, когда схемы довольно стабильны, данные читаются чаще, чем перезаписываются, сканирования затрагивают только часть столбцов, а сжатие имеет значение. Именно для такого мира были оптимизированы многие аналитические форматы.
Векторные строки гораздо шире аналитических строк
TPC-H lineitem — хороший базовый ориентир. В нем 16 столбцов: целочисленные ключи, десятичные значения, даты, короткие строки и небольшое поле комментария. Одна несжатая строка занимает примерно 150 байт. После сжатия она может быть намного меньше. При группе строк размером 64 МБ система хранения может упаковать сотни тысяч строк в одну группу.
Векторные наборы данных выглядят иначе.
Набор данных «изображение–текст» в стиле LAION гораздо ближе к тому, что сегодня создают многие AI-конвейеры. В каждой строке все еще есть обычные метаданные: URL, подпись, ширина, высота, оценки качества, метки и так далее. Но как только добавляется эмбеддинг, физическая форма строки меняется.
768-мерный CLIP-вектор занимает около 1,5 КБ в fp16 или 3 КБ в fp32. Один этот столбец может быть намного больше, чем целая строка TPC-H lineitem.
И 768 измерений — это не что-то необычное или большое по сегодняшним меркам. 1024- или 2048-мерный эмбеддинг распространен в мультимодальных конвейерах. OpenAI’s text-embedding-3-large достигает 3072 измерений, что составляет около 12 КБ на вектор в fp32.
Сравнение выглядит резко:
| Форма набора данных | Приблизительный размер строки | Доминирующее поле |
|---|---|---|
| TPC-H lineitem | ~150 байт без сжатия | скалярные данные и короткие строки |
| Строка в стиле LAION с 768-мерным fp16-вектором | ~1,5 КБ+ | эмбеддинг |
| Строка в стиле LAION с 768-мерным fp32-вектором | ~3 КБ+ | эмбеддинг |
| Строка с 3072-мерным fp32-вектором | ~12 КБ+ только для вектора | эмбеддинг |
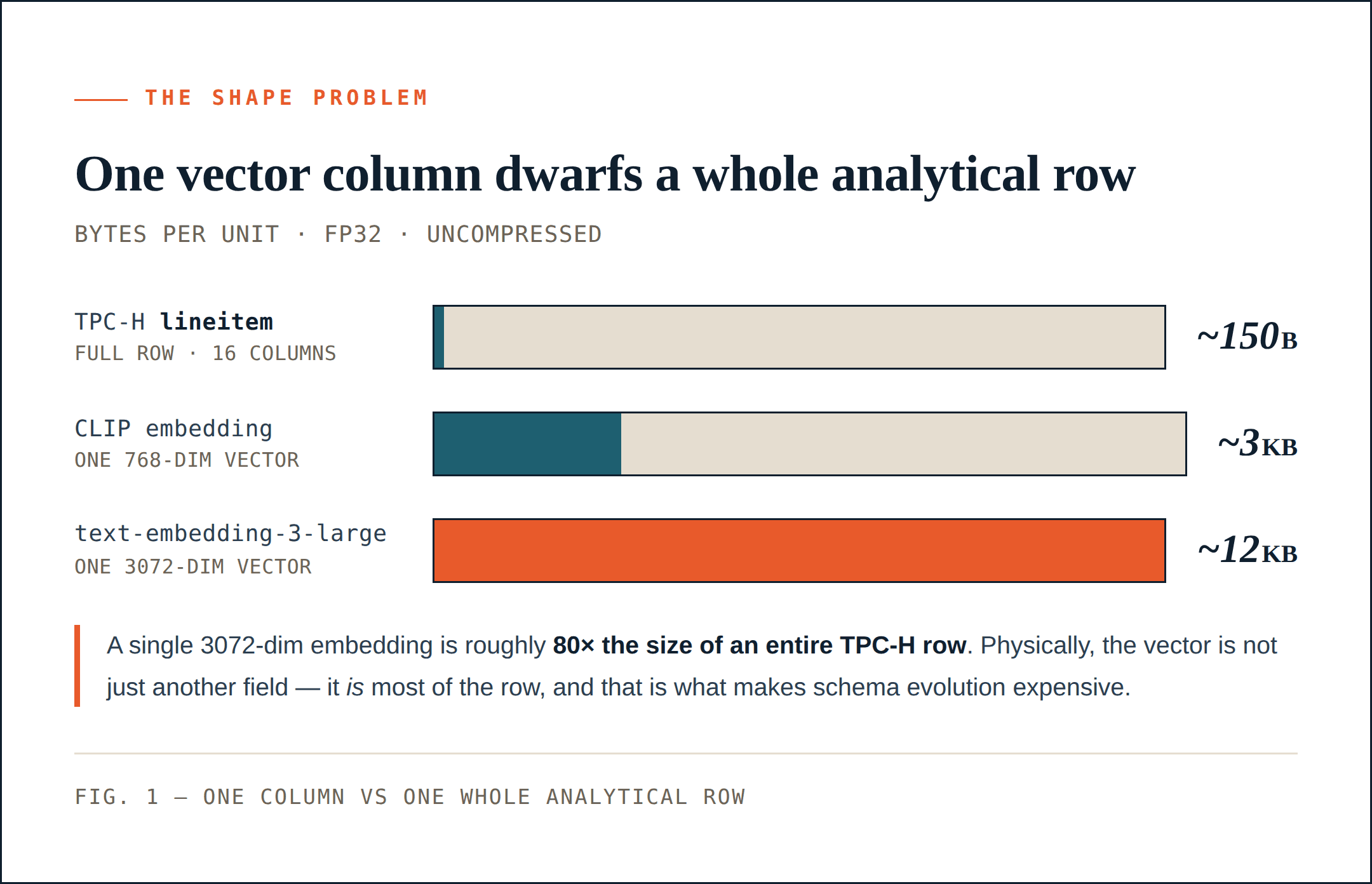
Во многих AI-наборах данных векторный столбец — это не просто еще одно поле. Физически он составляет большую часть строки. Это меняет стоимость эволюции схемы.
Добавление одного векторного столбца может означать сотни гигабайт
Предположим, набор данных содержит 100 миллионов видеоклипов. Добавление нового столбца 1024-мерных fp32-эмбеддингов означает запись примерно 400 ГБ необработанных векторных данных. Это не включает статистику, индексы, обновления метаданных, накладные расходы объектного хранилища, валидацию или интеграцию с путем обслуживания.

Если команда каждый месяц добавляет один или два вектороподобных столбца, таких как embedding_v2, sparse_vector или признаки rerank, эволюция схемы становится повторяющейся задачей дата-инжиниринга, измеряемой сотнями гигабайт или терабайт.
Небольшие логические обновления могут запускать крупные физические перезаписи
Обновления не менее важны.
В колоночных системах старые данные обычно не обновляются на месте. Журнал удалений фиксирует, что изменилось, а компактизация позже перезаписывает актуальные строки в новые файлы. Такая модель управляема, когда строки небольшие.
С векторными данными небольшое логическое обновление может запускать крупную физическую перезапись.
Задача ручной проверки может исправить всего несколько сотен байт в подписи. Но если подпись, плотный вектор, разреженный вектор и другие производные признаки используют один и тот же жизненный цикл физического файла, система в итоге может перезаписать и векторы тоже. Логическое изменение невелико. Физический I/O может быть огромным.
Это проблема усиления записи в векторном хранилище. Дорогая часть не только в том, что векторы большие. А в том, что крупные производные поля и небольшие изменяемые поля часто оказываются связанными вместе из-за схемы хранения, которая рассматривает их как единое целое.
Для AI-наборов данных backfill — рутинная нагрузка
Для традиционных аналитических таблиц эволюция схемы может происходить лишь изредка. Для AI-наборов данных это рутина. Модели подписей обновляются. Модели эмбеддингов заменяются. Разреженные векторы добавляются позже. Появляются признаки rerank. Человеческие метки исправляются. Governance-теги дозаполняются. Индексы перестраиваются.
Эти операции не являются простыми добавлениями. Они часто изменяют или расширяют существующие строки.
Именно поэтому векторное хранилище не может оптимизироваться только под пропускную способность сканирования. Оно также должно удешевлять backfill и частичные обновления.
Вторая проблема: одни и те же данные должны поддерживать сканирования и точечные чтения
После записи данных путь чтения разделяется. Один и тот же векторный набор данных обычно имеет два разных паттерна доступа: аналитическое сканирование и точечные чтения.

Аналитическим нагрузкам нужны широкие сжатые сканирования
Пайплайн может выполнять фильтры вроде:
WHERE aesthetic_score > 0.8 AND duration > 5
Или он может выполнять офлайн-анализ, полную оценку эмбеддингов, статистику BM25, построение битмапов, проверки качества данных, подсчеты и группировки.
Этот паттерн читает много строк, но только несколько столбцов. Ему подходят последовательный I/O, более крупные группы строк, сжатие, отсечение столбцов, пакетное декодирование и векторизованное выполнение.
Крупные группы строк здесь помогают. Они позволяют одному I/O-запросу получить большой объем полезных данных, повышают эффективность сжатия и предоставляют движку выполнения достаточно непрерывных данных, чтобы амортизировать накладные расходы. Когда несколько столбцов читаются вместе, их организация под пропускную способность сканирования также помогает уменьшить промахи кэша во время векторизованного выполнения.
Parquet силен на этом пути.
Результатам ANN нужны узкие построчные выборки
После того как ANN-поиск возвращает ID строк-кандидатов, системе часто нужно получить такие поля, как:
caption
embedding
rerank feature
video_uri
metadata
Этот паттерн читает меньше строк, часто сотни или тысячи, но ему нужен точный доступ по ID строки. Он хочет найти конкретную строку и столбец, получить только требуемый диапазон байтов и избежать чтения целой группы строк только ради получения нескольких записей.
Точечная выборка имеет почти противоположные сканированию предпочтения. Ей нужна меньшая гранулярность чтения. В идеале слой хранения может найти релевантный сегмент или диапазон байтов по ID строки, прочитать только этот диапазон и декодировать только данные, необходимые для результата.
У сжатия здесь тоже другой компромисс. Для сканирований более тяжелое сжатие часто оправдано, потому что система читает много данных и экономит I/O. Для точечной выборки сжатие может стать проблемой, если получение одной строки требует декодирования гораздо более крупного сжатого блока.
Один layout не может оптимизироваться под оба пути
Это центральный конфликт. Скалярная фильтрация и аналитика требуют широких, сжатых, удобных для сканирования компоновок. Векторный поиск требует узких, точных компоновок с адресацией по строкам.
Один файловый формат в некоторой степени может поддерживать и то и другое, но он не может быть оптимальным для обоих сценариев одновременно.
Если все столбцы находятся в Parquet, скалярные сканирования выполняются удобно. Но ANN-поиск после recall становится сложнее. Системе может быть нужно всего несколько сотен векторов, подписей или записей метаданных, тогда как уровню хранения, возможно, придется читать большие группы строк, содержащие в основном нерелевантные строки.
На локальном SSD кэш и mmap могут скрыть часть этой стоимости. Когда данные хранятся в объектном хранилище, стоимость становится заметнее. Каждый промах кэша может превратиться в удаленное чтение диапазона. Если строки-кандидаты разбросаны по множеству групп строк, один запрос может инициировать несколько чтений, каждое из которых извлекает больше данных, чем нужно запросу. При неудачной компоновке получение 1 000 строк-кандидатов легко может привести к десяткам или сотням мегабайт лишнего I/O, а в крайних случаях — намного больше.
Уменьшение групп строк помогает точечному поиску, но вредит сканированиям. Слишком много маленьких фрагментов снижает эффективность сжатия, увеличивает накладные расходы на метаданные и ломает длинные последовательные чтения, от которых зависят аналитические движки.
Так что проблема не в поиске единственного магического размера группы строк. Проблема в том, что один и тот же датасет заставляют вести себя как две разные системы хранения.
Гибридный поиск заставляет оба пути работать в одном запросе
Гибридный поиск делает этот конфликт труднее игнорировать. Один запрос может сначала применить скалярные фильтры:
aesthetic_score > 0.8 AND duration > 5
Затем он выполняет ANN-поиск.
Затем извлекает подпись, вектор и метаданные по ID строки.
Для пользователя это один поисковый запрос. Для уровня хранения это одновременно аналитическое сканирование и низколатентный случайный поиск.
Вот почему векторному хранилищу нужно больше, чем более удачная настройка Parquet. Ему нужен способ размещать разные столбцы в соответствии с тем, как их фактически читают.
Третья проблема: датасет не живет внутри одного движка
Первые две проблемы возникают внутри базы данных. Третья возникает на границе между системами.

Пайплайны AI-данных охватывают множество систем
В видеопроцессе очень мало что происходит внутри самой векторной базы данных.
Сырые видео находятся в объектном хранилище. Генерация клипов может выполняться в Spark или Ray. Оценка эстетичности может выполняться в GPU-сервисе. Создание подписей может выполняться в пайплайне LLM-инференса. Эмбеддинги могут генерироваться другим GPU-заданием. Разреженные векторы могут поступать из SPLADE-сервиса. Офлайн-оценка, фильтрация обучающих данных, человеческая проверка и задачи управления данными могут выполняться где угодно еще.
Векторная база данных обслуживает онлайн-поиск, но датасет создается, исправляется, оценивается и расширяется множеством систем.
Частные форматы хранения создают несколько копий истины
Если база данных использует частный физический формат, который читать и писать может только она, каждой внешней задаче нужны экспорт, конвертация, копия и импорт. Одна и та же коллекция может существовать в базе данных, во временной директории Spark, в выходных данных оценки и в локальной директории backfill. Тогда реальный вопрос становится таким:
- Какая копия является источником истины?
- Какая из них содержит модель подписей за прошлый месяц?
- Какие строки уже были исправлены после человеческой проверки?
- Какой столбец разреженных векторов был сгенерирован какой моделью?
- Какой векторный индекс все еще действителен после backfill?
- На какой исходный видеообъект ссылается эта строка?
В небольшом масштабе команды иногда могут выживать за счет соглашений об именовании и ручных проверок. При сотнях миллионов строк и терабайтах эмбеддингов это превращается в проблему согласованности.
Векторным датасетам нужно общее версионированное состояние
Системы Lakehouse уже решили одну из версий этой проблемы для структурированных данных. Iceberg, Delta Lake и Hudi — это не просто хранение файлов. Их ключевой вклад заключается в том, что они позволяют нескольким движкам координироваться вокруг одного и того же состояния таблицы.
Теперь векторным базам данных нужна похожая возможность, но состояние здесь сложнее. Оно должно включать не только файлы таблиц и разделы, но и векторные индексы, текстовые индексы, разреженные признаки, журналы удалений, статистику, диапазоны ID строк и ссылки на внешние blob-объекты.
Вопрос не просто в том: «Может ли Spark читать файлы Milvus?»
Вопрос в том, как после того, как Spark выполнит backfill столбца разреженных векторов, Milvus поймет, к какой версии относится этот столбец, какие строки он охватывает, какая модель его создала и когда онлайн-запросы смогут безопасно его использовать?
Ответ должен находиться в модели хранения.
Почему патчей недостаточно
Есть соблазн рассматривать это как три отдельные инженерные проблемы.
- Write amplification? Добавить batching.
- Point reads? Добавить cache.
- External systems? Добавить инструменты export и import.
Такие патчи могут помочь, но они не решают фундаментальную проблему: векторный набор данных физически неоднороден.

В примере с видео clip_id, video_id, duration и aesthetic_score — это короткие скалярные поля. Они полезны для фильтрации и анализа.
caption— это текст. Он может использоваться для BM25, проверки, исправления и backfill.embedding— это длинный плотный вектор. Он используется для ANN recall, а позже — для поиска на уровне строк или reranking.embedding_v2— это результат работы новой модели, часто заполняемый через backfill значительно позже вставки исходных данных.sparse_vectorподдерживает hybrid search и имеет собственный паттерн доступа.- Сырые видео должны оставаться в объектном хранилище. База данных должна хранить ссылку, контрольную сумму, MIME-тип, версию парсера и связь на уровне строки.
- Векторные индексы, текстовые индексы, статистика и журналы удалений — это производные объекты со своей собственной семантикой версий.
Эти объекты относятся к одной логической строке, но не должны иметь один и тот же физический layout или жизненный цикл.
- Если их принудительно поместить в один обычный layout таблицы, обновления станут дорогими.
- Если их принудительно поместить в один колоночный файловый формат, point reads станут дорогими.
- Если рассматривать их как несвязанные объектные файлы, управление версиями станет хрупким.
Поэтому модель хранения должна исходить из того, что набор данных неоднороден.
Отсюда следуют три требования к дизайну:
- Во-первых, разные группы столбцов должны храниться в разных физических форматах.
- Во-вторых, этим группам столбцов нужно общее пространство ID строк, чтобы они по-прежнему могли вести себя как единая логическая таблица.
- В-третьих, набору данных нужен версионированный Manifest, который объявляет, какие файлы, индексы, журналы, статистика и ссылки на объекты относятся к текущему представлению.
Именно такой дизайн лежит в основе Loon, нашего нового движка хранения для Milvus и Zilliz Cloud.
Loon: движок хранения для Milvus и Zilliz Cloud для развивающихся векторных наборов данных
Чтобы решить все перечисленные выше проблемы, мы создали Loon, новый движок хранения для Milvus и Zilliz Vector Lakebase (следующей эволюции Zilliz Cloud), предназначенный для развивающихся векторных наборов данных.
Название продолжает традицию Zilliz называть продукты в честь птиц. Loon — это ныряющая птица, которая живет на озерах, что хорошо соответствует цели системы: векторная база данных не должна перемещать, сканировать или перезаписывать целое озеро данных каждый раз, когда выполняет запрос, заполняет столбец через backfill или строит индекс. Сначала она должна понять текущую версию набора данных, включая его столбцы, индексы, статистику, журналы удалений и ссылки на объекты, а затем читать только ту часть, которая действительно нужна.
Гибридные файловые форматы, выравнивание ID строк и Manifest — это не три отдельные функции. Они вытекают из одного и того же предположения дизайна: векторный набор данных по своей природе неоднороден.
Три части, одна модель хранения
Гибридные файловые форматы признают, что у разных столбцов разные шаблоны доступа. Скалярные поля хорошо подходят для сканирований и фильтров. Векторным полям нужен эффективный построчный поиск. Сырые объекты, такие как видео, PDF, изображения и аудиофайлы, должны находиться в объектном хранилище, а не внутри файлов данных базы данных.
Выравнивание Row ID признает, что эти столбцы могут быть физически разделены, но они по-прежнему описывают одни и те же логические строки. Подпись, embedding, разреженный вектор и URI видео могут находиться в разных файлах и форматах, но их всё равно нужно снова собрать вместе как единый результат.
Manifest признает, что набор данных не записывается один раз и не остается без изменений. Он будет изменяться несколькими системами, в нескольких версиях, для нескольких задач. Индексы, статистика, журналы удалений, ссылки на внешние объекты и группы столбцов должны все отображаться в одном и том же версионированном представлении.
Вот почему Loon — это не просто более быстрый файловый формат для векторов. Более быстрый формат помогает при точечном поиске, но он не решает проблему эволюции схемы или координации нескольких движков. Выравнивание Row ID позволяет разделенным столбцам вести себя как единая таблица, но не указывает, какие файлы относятся к текущей версии. Manifest может описывать состояние набора данных, но без групп столбцов и выравнивания Row ID он не может чисто представлять разные физические компоновки внутри одной логической коллекции.
Модели хранения нужны все три компонента: разные форматы для разных групп столбцов, общее пространство Row ID для восстановления строк и версионированный Manifest, который сообщает каждому читателю и писателю, чем сейчас является набор данных.
Где Loon вписывается в Milvus и Zilliz Vector Lakebase
В Milvus он заменяет старый слой хранения segment binlog моделью, построенной вокруг абстракций Manifest, ColumnGroup, файлового формата и файловой системы. В Zilliz Vector Lakebase (следующей эволюции Zilliz Cloud), то же направление применяется к архитектуре Vector Lakebase: сохранить быстрым путь обслуживания векторной базы данных, одновременно делая базовые данные более удобными для развития, анализа и координации с внешними системами.
Компоненты верхнего уровня Milvus по-прежнему сохраняют свои привычные роли. Proxy обрабатывает маршрутизацию. QueryCoord и DataCoord отвечают за планирование. IndexNode строит индексы. API для коллекций, вставок, поисков и гибридных поисков, ориентированные на приложения, не должны раскрывать файлы Manifest или ColumnGroups.
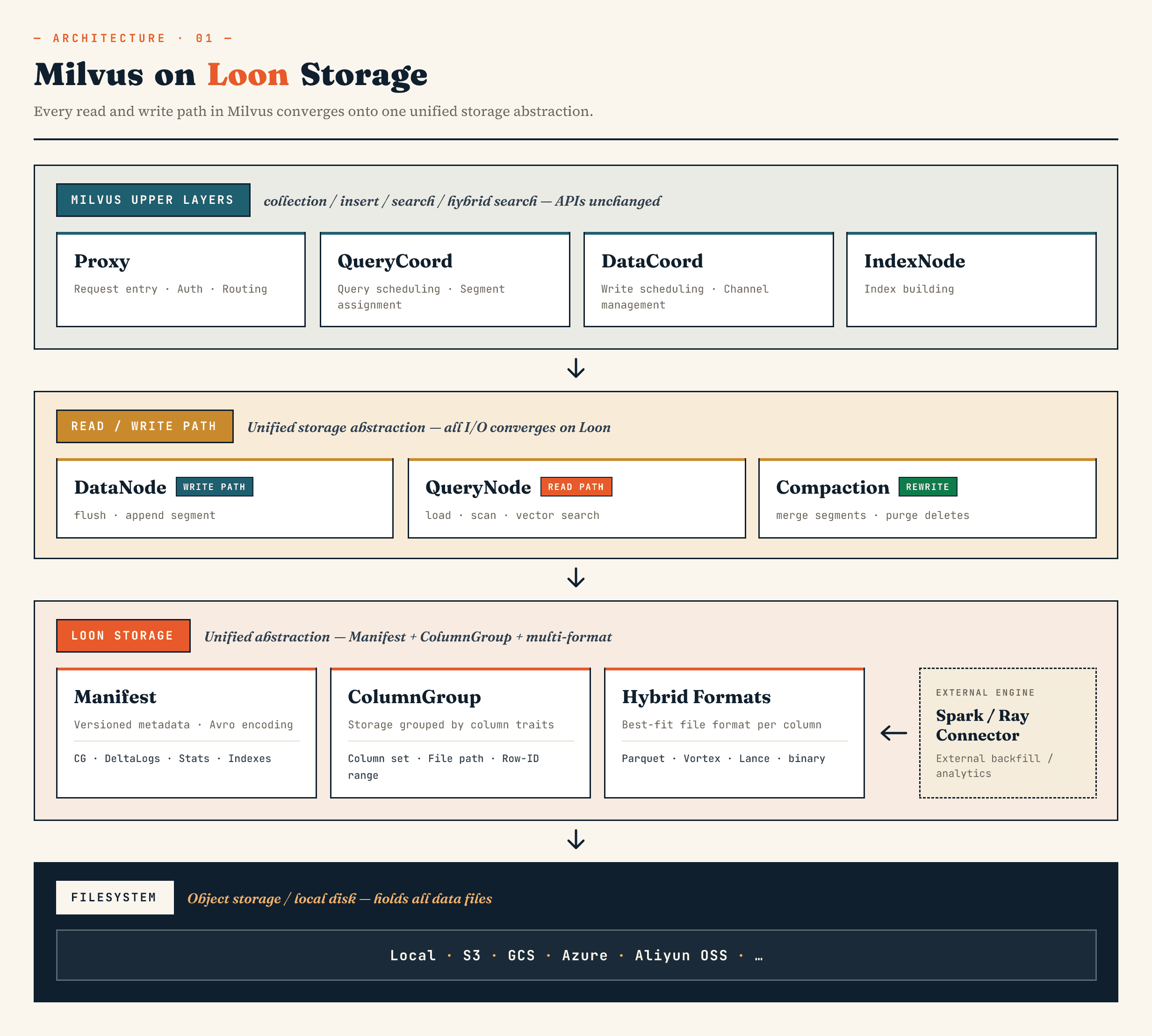
Изменение находится ниже.
DataNode, QueryNode, segcore, compaction и внешние коннекторы могут работать через одну и ту же абстракцию хранения. Это важно, потому что набор данных больше не записывается и читается только базой данных. Он может расширяться внешними вычислительными системами и одновременно потребляться онлайн-поиском.
На высоком уровне слои выглядят так:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
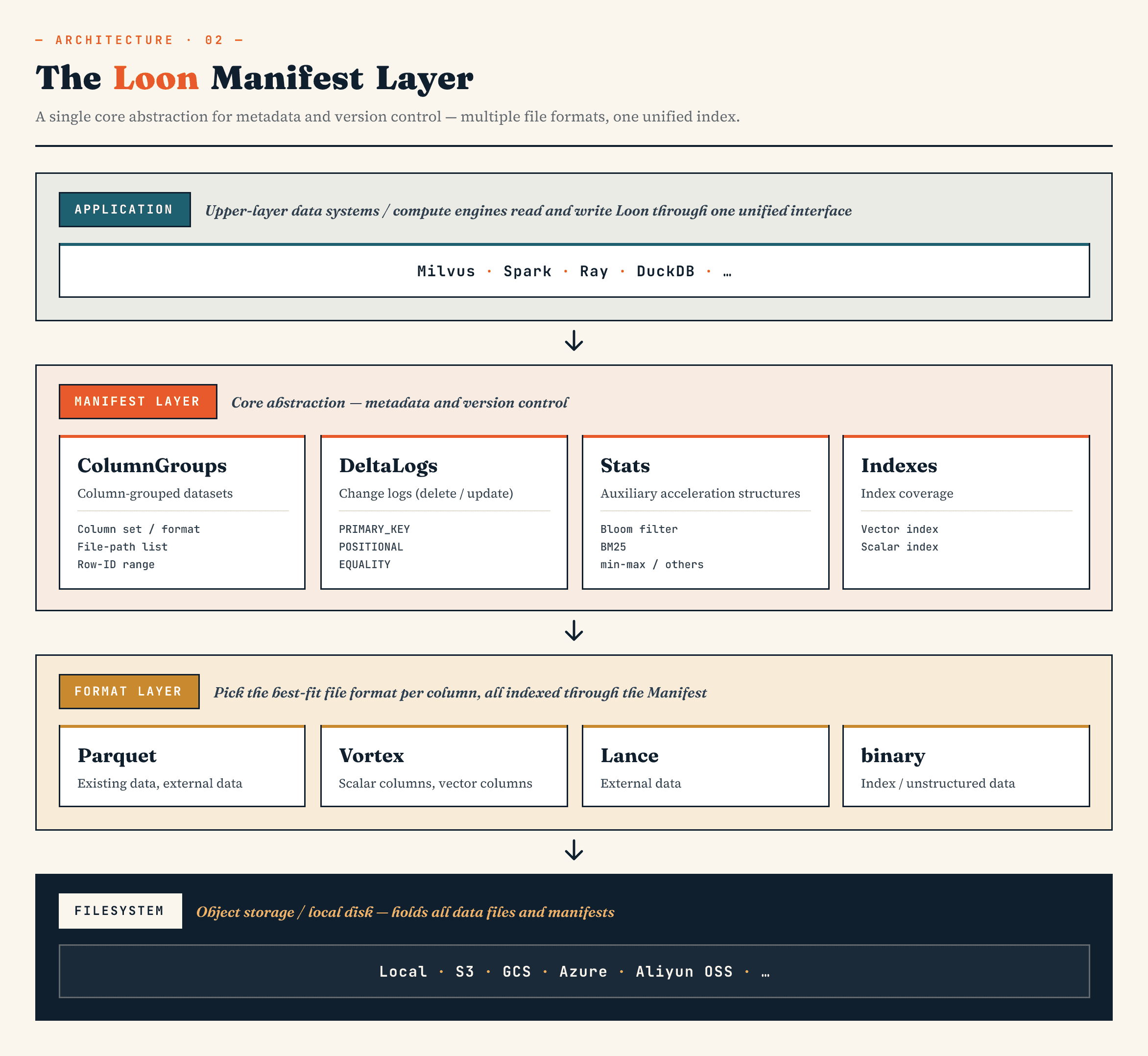
Manifest описывает версионированное состояние набора данных. ColumnGroups отображают логическую коллекцию в физические группы столбцов. Слой файлового формата позволяет каждой ColumnGroup выбрать подходящий формат. Абстракция файловой системы работает поверх объектного и локального хранилища.
Важный момент заключается в том, что гибридные файловые форматы, выравнивание Row ID и Manifest не являются отдельными функциями. Вместе они определяют модель хранения.
Имея такую модель, мы можем рассмотреть три проектных решения по очереди: как Loon хранит разные ColumnGroups, как он выравнивает их обратно в строки и как Manifest превращает эти файлы в версионированный набор данных.
Проектное решение 1: использовать правильный файловый формат для правильной группы столбцов
У разных столбцов разные шаблоны доступа. Их не следует принуждать к одному и тому же файловому формату.
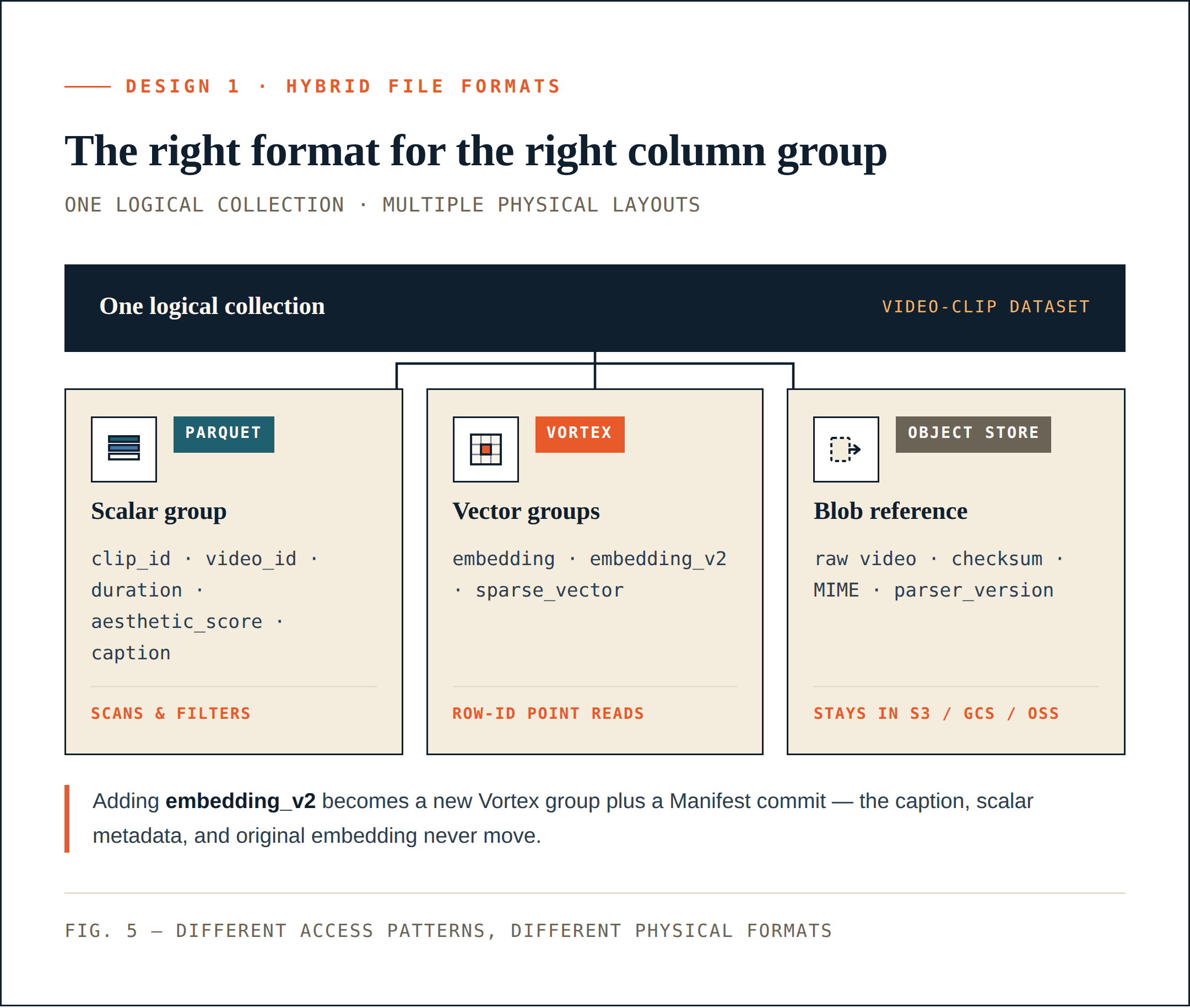
Loon разделяет логическую коллекцию на ColumnGroups.
- Скалярные поля, поля фильтрации, бизнес-ключи и статистические поля часто сканируются, фильтруются, агрегируются или используются для планирования запросов. Им полезны сжатие, отсечение столбцов и совместимость с экосистемой. Parquet хорошо подходит для таких столбцов.
- Плотные векторы, разреженные векторы и признаки для rerank часто считываются после ANN recall по ID строки. Им нужны низкая задержка при случайном доступе, точные чтения диапазонов байтов и выборочное декодирование. Сегментно-ориентированная компоновка подходит лучше. Loon использует Vortex в этом направлении.
- Сырые объекты, такие как видео, PDF, изображения и аудиофайлы, не должны встраиваться в файлы данных векторной базы данных. Они должны оставаться в объектном хранилище. База данных записывает ссылки, контрольные суммы, MIME-типы, версии парсеров и отношения на уровне строк.
Для примера с видео физическая компоновка может выглядеть так:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Для приложения это по-прежнему одна коллекция. Для уровня хранения разные части этой коллекции используют разные физические форматы. Это напрямую сокращает ненужные перезаписи. Добавление embedding_v2 может стать новой векторной ColumnGroup плюс commit в Manifest. Для этого не требуется переписывать столбец caption, скалярные метаданные или существующий столбец embedding.
Та же идея применима к разреженным векторам, признакам rerank или другим производным полям. Если новый столбец может быть физически независимым и выровненным по ID строки, ему не нужно протаскивать несвязанные столбцы через тот же путь перезаписи.
Loon также адаптирует использование файловых форматов.
Для Parquet настройки по умолчанию не всегда идеальны для данных с большим количеством векторов. Row group размером 64 MB может быть слишком большим для точечного поиска, потому что небольшое случайное чтение может подтянуть намного больше данных, чем нужно. Loon уменьшает row groups до 1 MB в соответствующих путях и отключает кодирования, такие как dictionary encoding для векторных столбцов, когда они не помогают данным векторов, выглядящим случайными.
Для Vortex более важная работа — это компоновка. Loon использует компоновку, которая балансирует эффективность сканирования и точечный поиск. Внутри row group сегменты связанных столбцов могут размещаться близко друг к другу, чтобы поддерживать сканирование. Для выполнения операций чтения подсегментов позволяют системе получать только релевантные байты, а не вытягивать весь сегмент.
Loon также поддерживает read-only Lance integration, поэтому существующие наборы данных Lance можно монтировать как ColumnGroups, когда важна совместимость.
Что показывает benchmark
В одном локальном тесте с использованием одного файла с 40 000 строк и схемой {id: int64, name: utf8, value: float64, vector: list<float32>[128]} Vortex показал следующие результаты по сравнению с Parquet с row groups по 1 MB:
| Операция | Vortex | Parquet | Разница |
|---|---|---|---|
| Take, K=1000 случайных строк | 5.8 ms | 144 ms | в 25 раз быстрее |
| Полное сканирование векторного столбца | 21 ms | 142 ms | в 6.76 раза быстрее |
| Размер файла, ~21 MB сырых данных | 6.62 MB | 7.16 MB | на 7% меньше |
Результат take обусловлен сокращением объема нерелевантных данных, которые нужно прочитать и декодировать. Результат сканирования обусловлен выбором сжатия и реализации.
Эти цифры следует рассматривать только вместе с их условиями: 8 vCPU Ubuntu 22.04 KVM, локальная файловая система, один файл, 40 000 строк, row groups по 1 MB и схема выше. В объектном хранилище сетевой I/O может доминировать, поэтому снижение read amplification может быть еще важнее. Фактические результаты зависят от формы набора данных, поведения объектного хранилища, состояния кэша и шаблона запросов.
Более общий вывод не в том, что каждый столбец должен использовать Vortex.
Суть в том, что для векторных наборов данных выбор файлового формата нужен на уровне ColumnGroup.

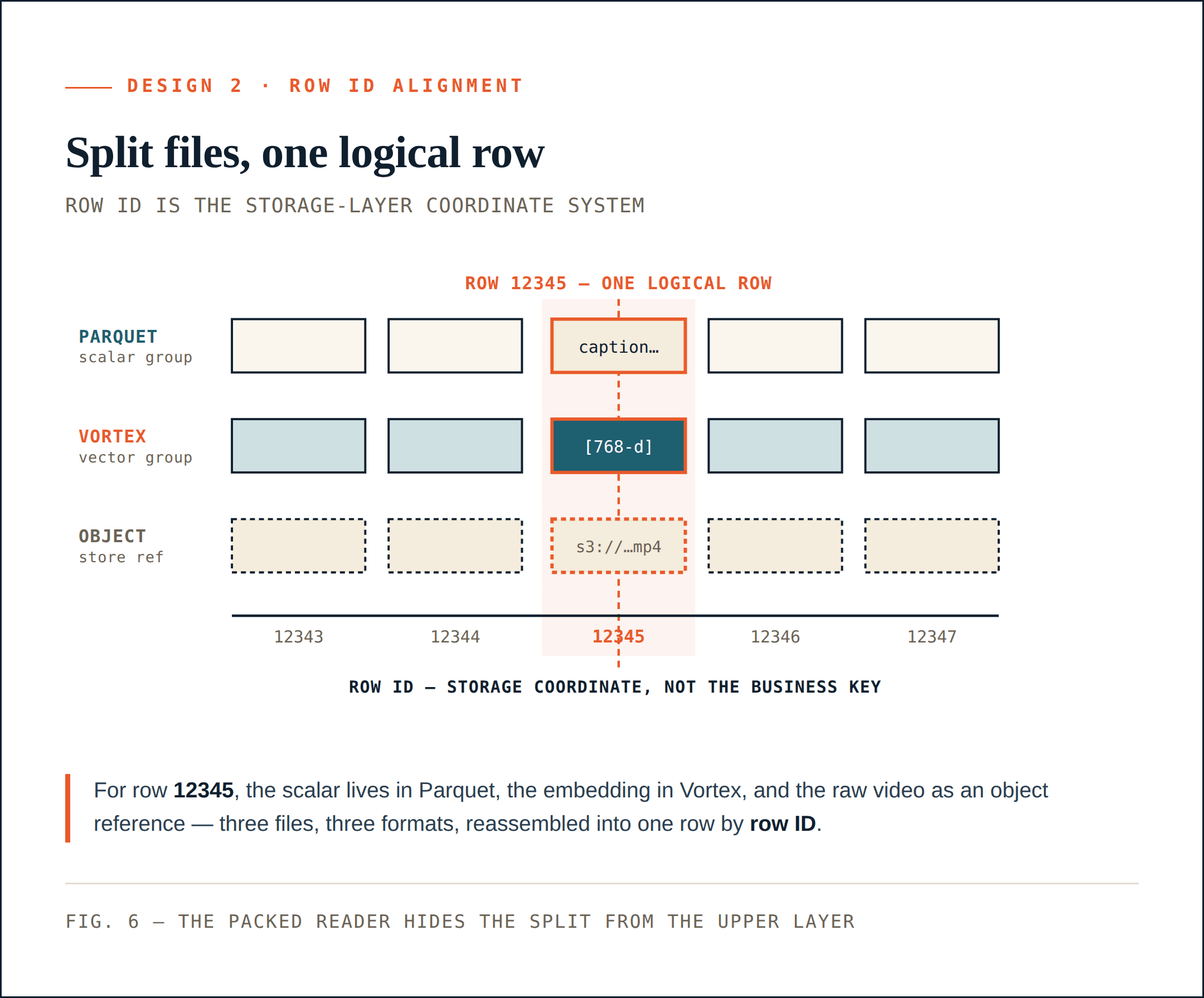
Дизайн 2: выравнивание физических файлов по row ID
Гибридные форматы файлов решают одну проблему: разные столбцы теперь могут храниться в форматах, которые подходят им лучше всего.
Но это создает вторую проблему. Если скалярные поля хранятся в Parquet, векторы — в Vortex, а исходные объекты — в объектном хранилище, как система всё еще рассматривает их как одну коллекцию?
Loon решает это с помощью выравнивания по row ID.
Row ID — это система координат уровня хранения
Каждый физический ColumnGroupFile записывает путь к файлу и диапазон row ID, который он покрывает:
path
start_index
end_index
Разные ColumnGroups могут покрывать одно и то же пространство row ID, даже если они находятся в разных файлах и форматах.
Для row ID 12345 скалярные метаданные могут находиться в ColumnGroup Parquet, embedding — в ColumnGroup Vortex, а исходное видео может быть представлено ссылкой на объектное хранилище. Логически это всё еще одна строка. Это дает уровню хранения стабильную систему координат.
Row ID — это не бизнес-первичный ключ. Это система координат уровня хранения, которая позволяет Loon физически разбивать коллекцию без потери возможности логически ее реконструировать.
Новые столбцы не требуют перезаписи старых столбцов
Добавление embedding_v2 не требует перезаписи исходного caption, metadata или ColumnGroups embedding_v1. Loon может записать новую векторную ColumnGroup, зафиксировать диапазон row ID, который она покрывает, и выполнить commit этого изменения через Manifest.
То же самое относится к разреженным векторам, признакам rerank или другим производным полям, которые появляются позже.
Пока новая ColumnGroup покрывает правильный диапазон row ID, она может присоединиться к той же логической коллекции, не вынуждая несвязанные данные перемещаться.
Удаления и компакция могут быть более точечными
Выравнивание по row ID также помогает с удалениями.
Удаление сначала может быть выражено через лог удаления. Строка становится невидимой на логическом уровне, а физическая очистка откладывается до компакции. Когда компакция в итоге запускается, ей не всегда нужно перезаписывать каждый ColumnGroup, связанный с затронутыми строками. Она может сосредоточиться на тех ColumnGroups, которым нужна очистка.
Это важно, потому что не каждый столбец имеет одинаковый профиль затрат. Перезапись короткого скалярного ColumnGroup сильно отличается от перезаписи сотен гигабайт плотных векторов.
Гибридный поиск может извлекать только нужные ему столбцы
Выравнивание по row ID также делает гибридный поиск практичным поверх гибридных форматов файлов.
После того как ANN-поиск возвращает row ID кандидатов, система может извлечь только поля, необходимые для итогового результата: captions, metadata, vectors, rerank features или object references.
Например, запросу могут понадобиться:
caption
embedding
video_uri
Эти поля могут находиться в разных ColumnGroups. Loon может найти соответствующие файлы по диапазону row ID, прочитать необходимые диапазоны байтов и собрать результат.
Без выравнивания по row ID гибридные форматы были бы просто отдельными файлами, лежащими рядом. С выравниванием по row ID они ведут себя как единая логическая коллекция.
Packed Reader скрывает разделение от верхнего уровня
Компонент времени выполнения, который делает это удобным, — Packed Reader.
Верхний уровень видит единый поток Arrow RecordBatch. Под ним данные могут поступать из нескольких ColumnGroups в разных форматах файлов. Packed Reader скрывает эти различия, выравнивает данные по диапазонам row-ID и планирует многопоточный файловый I/O с контролируемым использованием памяти.
Он также поддерживает прямой take по row ID. Получив набор row ID, он находит соответствующие ColumnGroupFiles, выполняет чтения диапазонов и возвращает запрошенные поля.
Для рабочего процесса с видео ANN-запросу могут понадобиться caption, embedding и video_uri. Packed Reader может извлечь скалярный ColumnGroup и векторный ColumnGroup, не затрагивая несвязанные столбцы.
В этом и заключается разница между «отдельными файлами» и «таблицей с несколькими физическими раскладками».
Дизайн 3: сделать Manifest источником истины
Гибридные файловые форматы определяют, как данные физически хранятся. Выравнивание по ID строк определяет, как разделенные ColumnGroups всё же образуют единую логическую таблицу. Но системе всё равно нужно ответить на более широкий вопрос: какие файлы, журналы, статистики, индексы и ссылки на объекты принадлежат текущей версии набора данных? Это задача Manifest.

Каталогов объектного хранилища недостаточно
Объектное хранилище — это не каталог базы данных. Каталог может содержать старые файлы, новые файлы, результаты неудачных заданий, временные файлы, журналы удалений, файлы, всё ещё используемые более старыми снимками, и файлы, ожидающие очистки. Сам факт существования файла не означает, что он принадлежит текущей версии набора данных.
Набор данных Loon может быть организован в каталоги, такие как:
_metadata/
_data/
_delta/
_stats/
_index/
Но структура каталогов не является источником истины. Им является Manifest. Читатели не должны перечислять каталоги и выводить состояние из любых файлов, которые там случайно существуют. Они должны читать текущий Manifest и следовать объявленному в нём версионированному представлению.
Manifest определяет одно версионированное представление набора данных
Manifest определяет набор данных в заданной версии. Он записывает:
- какие ColumnGroups существуют
- какие диапазоны ID строк они покрывают
- какой физический формат использует каждая ColumnGroup
- где находятся файлы
- какие журналы удалений активны
- какие статистики доступны
- какие индексы существуют
- какие внешние blob-объекты используются по ссылкам
- какие столбцы и диапазоны строк покрывают эти статистики или индексы
Каждое обновление записывает новую версию Manifest. Читатель, открывающий версию N, видит стабильное представление набора данных в версии N. Писатель может подготовить версию N+1, не нарушая работу читателей, которые всё ещё используют версию N.
Manifest отслеживает не только файлы таблицы
В Loon тело Manifest кодируется с помощью Apache Avro и организовано вокруг четырёх основных разделов.
- ColumnGroups описывают столбцы, форматы, файлы и диапазоны ID строк.
- DeltaLogs описывают удаления. Разные типы удалений покрывают разные источники изменений, такие как удаления по первичному ключу от клиентов, позиционные удаления в результате внутренней компакции или удаления по равенству от внешних движков.
- Stats включают метаданные для планирования, такие как bloom filters, статистики BM25 и значения min/max.
- Indexes описывают тип индекса, параметры, покрываемые столбцы и диапазоны ID строк. Это может включать векторные индексы, такие как HNSW или IVF, текстовые индексы, инвертированные индексы, bitmap-индексы и связанные структуры.
Именно здесь Loon отличается от традиционного табличного Manifest.
Векторному набору данных нужно отслеживать не только файлы данных и партиции. Ему также нужно отслеживать векторные индексы, текстовые индексы, разреженные признаки, журналы удалений, статистики, ссылки на внешние объекты и диапазоны ID строк, которые их связывают.
Manifest должен быть доступен для записи не только базе данных
Самая важная часть — не только то, что содержит Manifest. А то, кто может его записывать.
- Если только база данных может записывать Manifest, он остаётся внутренними метаданными. Более чистыми метаданными, но всё ещё приватными для одного движка.
- Если внешние движки могут генерировать новые ColumnGroups, статистики и записи Manifest, Manifest становится интерфейсом координации.
- Например, задание Spark может заполнить разреженный векторный столбец задним числом. Оно записывает новую ColumnGroup, фиксирует покрытие строк и статистики и коммитит новый Manifest. Онлайн-запросы могут продолжать читать старую версию во время выполнения задания. Как только коммит успешно завершается, новая версия становится видимой.
По духу это похоже на Iceberg и Delta Lake, но объектная модель шире. Векторному набору данных нужно отслеживать векторные индексы, текстовые индексы, разреженные признаки, журналы удалений, статистики, ссылки на blob-объекты и диапазоны ID строк, а не только файлы таблицы и партиции.
Оптимистичные коммиты упрощают обновления версий
Каждый коммит записывает новую версию Manifest. Пишущий процесс может построить новое содержимое на основе версии N, а затем попытаться записать manifest-{N+1}.avro. Условная запись в объектном хранилище или семантика generation-match могут привести к сбою коммита, если такая версия уже существует. Затем пишущий процесс может повторить попытку относительно более новой версии.
Это дает Loon оптимистичную конкурентность без необходимости пропускать каждое обновление через тяжелый, строго согласованный координационный путь. Без Manifest хранение в нескольких форматах и для нескольких движков в итоге превращается в соглашения об именовании и ручное согласование. Это может работать для небольших наборов данных. Это не работает для векторных данных терабайтного масштаба.
Manifest — это то, что превращает разнородные файлы в набор данных, который несколько систем могут безопасно читать и обновлять.
Что меняется для пользователей, когда хранилище становится версионированным
Для разработчиков приложений Loon не должен становиться новой API-нагрузкой.
Пользователи по-прежнему должны работать с привычными концепциями Milvus: коллекциями, вставками, поиском и гибридным поиском. Им не нужно думать о файлах Manifest, ColumnGroups, диапазонах идентификаторов строк или раскладке файлов во время обычной разработки приложений.
Изменение происходит внутри. Хранилище становится более осведомленным о том, как на самом деле развиваются AI-наборы данных.
Добавление нового embedding не должно перемещать старые данные
Ранее добавление embedding_v2 в существующую коллекцию часто требовало экспорта данных, обучения новой модели, генерации векторов, а затем повторного импорта или массового обновления коллекции через SDK. Такой путь создает много операционной работы: отслеживание версий, повторные попытки неудачных заданий, перестроение индексов, влияние на обслуживание и проверки согласованности.
С Loon это может стать эволюцией схемы плюс коммитом нового ColumnGroup. Новый столбец embedding может быть записан как отдельный физический ColumnGroup, выровнен по идентификатору строки и сделан видимым через Manifest. Старый столбец caption, столбец скалярных метаданных и исходный столбец embedding перемещать не нужно.
Backfill не должны требовать клиентского цикла обновления
Многие обновления AI-данных — это backfill. Команда может добавить sparse vectors после того, как гибридный поиск становится важным. Она может добавить признаки для rerank после обучения новой модели. Она может исправить captions после проверки человеком. Она может добавить governance tags после обновления политики.
В традиционной раскладке эти изменения часто происходят через обновления клиентского SDK или write paths только базы данных, даже когда данные создаются Spark, Ray или другим внешним движком.
С Loon внешние вычислительные системы могут создавать новые ColumnGroups и коммитить их через Manifest. База данных больше не должна быть единственной точкой входа для каждой перезаписи.
Offline analysis не должен требовать еще одной копии истины
Ранее команды часто выгружали online collection в Parquet для offline evaluation или analysis. Это создает две версии одного и того же набора данных: online collection и analysis copy. После того как captions исправлены, embeddings сгенерированы заново, delete logs применены или индексы перестроены, команде приходится спрашивать, какая копия актуальна.
С моделью хранения на основе Manifest аналитические движки могут читать то же версионированное представление набора данных, что и обслуживающая система. Они могут проецировать только нужные им столбцы, сканировать только релевантные диапазоны строк и работать с объявленной версией набора данных вместо вручную экспортированного snapshot.
Удаления и исправления должны затрагивать только то, что изменилось
Удаления, исправления captions, исправления labels и governance updates являются обычными для AI-наборов данных. Они не должны заставлять каждый длинный векторный столбец проходить через один и тот же путь перезаписи.
С Loon delete logs сначала могут рассматриваться как логическое удаление. Позже compaction может очистить затронутые ColumnGroups без перезаписи несвязанных данных. Если короткое текстовое поле изменяется, уровень хранения не должен переписывать сотни гигабайт dense vectors только потому, что они используют одну и ту же логическую строку.
Внешние движки становятся частью рабочего процесса, а не запасным выходом
Более масштабный сдвиг заключается в том, что внешние движки больше не рассматриваются как системы за пределами векторной базы данных.
Spark, Ray, задачи оценки, системы разметки и конвейеры управления уже создают и изменяют значительную часть данных. Уровень хранения должен позволять им совместно работать вокруг единого источника истины, а не постоянно экспортировать, копировать и повторно импортировать данные.
Именно это делает возможным версия Manifest. Она предоставляет онлайн-обслуживанию, офлайн-анализу, задачам обратного заполнения и компакции общий взгляд на набор данных.
Это может звучать как внутренние детали хранения, но они влияют на то, насколько быстро команды могут итерировать над наборами данных для ИИ. Каждое изменение модели, обратное заполнение признаков, исправление подписи, фильтр качества и перестроение индекса зависят от одного и того же вопроса: "Может ли система обновить набор данных, не перемещая данные, которые ей не нужно перемещать? "
В этом и заключается практическая ценность модели хранения.
Loon доступен в Milvus 3.0 beta и Zilliz Vector Lakebase
Loon доступен в Milvus 3.0 beta, а также является частью уровня хранения в Zilliz Vector Lakebase, следующем этапе развития Zilliz Cloud. Этот выпуск сосредоточен на трех ключевых областях:
- Manifest. Цель состоит в том, чтобы записи, обратные заполнения, удаления, статистика и обновления индексов создавали версионированные представления наборов данных, которые читатели могут открывать согласованно. Для читателей это означает, что запрос может открыть конкретную версию Manifest и увидеть стабильное представление набора данных. Для писателей это означает, что новые файлы данных, журналы удалений, статистика или индексные файлы могут быть сначала подготовлены, а затем сделаны видимыми через версионированный коммит.
- ColumnGroup и поддержка форматов. Parquet поддерживает скалярные и удобные для экосистемы столбцы. Vortex поддерживает шаблоны доступа, ориентированные на интенсивную работу с векторами. Lance может быть интегрирован в режиме только для чтения для совместимости с существующими наборами данных Lance.
- Index on Lake. Скалярная статистика, индексы фильтрации и текстовые инвертированные индексы могут участвовать в планировании на основе Manifest по диапазону строк. Нативные для lake векторные индексы устроены сложнее. HNSW и IVF ведут себя по-разному в объектном хранилище, а HNSW, в частности, чувствителен к случайному доступу и локальности кэша. Он не может просто повторно использовать схему размещения, разработанную для локального SSD, и ожидать того же результата.
Впереди еще есть работа
- Внешние пути записи важны, потому что Spark и Ray должны иметь возможность создавать ColumnGroups и коммиты Manifest, не заставляя каждое обратное заполнение проходить через цикл клиентского SDK.
- Совместимость с lakehouse важна, потому что многие команды уже используют каталоги и движки запросов, такие как Iceberg, Delta Lake, Trino, DuckDB и Athena. Векторные данные должны иметь возможность участвовать в этой экосистеме без потери производительности векторного поиска.
- Схема размещения индекса важна, потому что графовые индексы и инвертированные структуры имеют разные шаблоны доступа в объектном хранилище.
- Семантика крупных объектов важна, потому что необработанные видео, PDF-файлы, изображения и аудиофайлы требуют управления ссылками, версионирования и поведения при удалении, согласованных с производным векторным набором данных.
Точное поведение релиза, настройки по умолчанию и путь миграции должны соответствовать соответствующим заметкам о выпуске Milvus и Zilliz Cloud. Однако направление развития хранения ясно: векторным базам данных нужна версионированная, нативная для lake основа под уровнем обслуживания.
Попробуйте Loon в Zilliz Vector Lakebase
Если ваш текущий стек разделяет онлайн-обслуживание, офлайн-анализ, обратные заполнения и внешние рабочие процессы data lake по разным системам, к Zilliz Vector Lakebase стоит присмотреться. Вы можете попробовать его в Zilliz Cloud. Новые регистрации с рабочей электронной почтой получают $100 бесплатных кредитов. Вы также можете связаться с нами, чтобы обсудить ваш сценарий использования.
Вы также можете следить за релизом Milvus 3.0, чтобы увидеть, как Loon развивается в open-source движке.
Zilliz Vector Lakebase объединяет:
- Многоуровневое обслуживание для разных компромиссов между производительностью в реальном времени и стоимостью
- Поиск по требованию для крупномасштабных или исследовательских рабочих нагрузок без постоянно включенных вычислительных ресурсов
- Поиск по внешнему озеру данных, чтобы вы могли индексировать и искать непосредственно по существующим данным в озере
- Полноспектральный поиск по векторам, тексту, JSON и геопространственным данным, с гибридным извлечением и reranking
- Единое lake-native хранилище на базе Vortex, открытого формата, разработанного для более быстрого и менее затратного произвольного чтения данных с большим количеством векторов
Читать далее

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.