




Создание RAG с помощью Milvus, vLLM и Llama 3.1
Калифорнийский университет в Беркли передал vLLM, быструю и простую в использовании библиотеку для вывода и обслуживания LLM, в LF AI & Data Foundation в качестве проекта на стадии инкубации в июле 2024 года. Как проект-участник, мы приветствуем vLLM в семье LF AI & Data! 🎉
Большие языковые модели (LLM) и векторные базы данных обычно используются в паре для создания Retrieval Augmented Generation (RAG), популярной архитектуры приложений ИИ для решения проблемы AI Hallucinations. В этом блоге мы расскажем вам, как построить и запустить RAG с помощью Milvus, vLLM и Llama 3.1. Более конкретно, я покажу вам, как встраивать и хранить текстовую информацию в виде векторных вкраплений в Milvus и использовать это векторное хранилище в качестве базы знаний для эффективного извлечения фрагментов текста, релевантных вопросам пользователя. Наконец, мы задействуем vLLM для использования модели Meta Llama 3.1-8B для генерации ответов, дополненных полученным текстом. Давайте погрузимся!
Введение в Milvus, vLLM и Meta's Llama 3.1
Векторная база данных Milvus
Milvus - это распределенная векторная база данных с открытым исходным кодом, специально созданная для хранения, индексирования и поиска векторов для рабочих нагрузок генеративного ИИ (GenAI). Способность выполнять гибридный поиск, фильтрацию метаданных, реранжирование и эффективно обрабатывать триллионы векторов делает Milvus лучшим выбором для рабочих нагрузок ИИ и машинного обучения. Milvus может работать локально, на кластере или размещаться в полностью управляемом облаке Zilliz Cloud.
vLLM
vLLM - это проект с открытым исходным кодом, начатый в UC Berkeley SkyLab и направленный на оптимизацию производительности LLM-серверов. В нем используется эффективное управление памятью с помощью PagedAttention, непрерывное пакетирование и оптимизированные ядра CUDA. По сравнению с традиционными методами, vLLM повышает производительность обслуживания до 24 раз, сокращая при этом использование памяти GPU вдвое.
Согласно статье "Efficient Memory Management for Large Language Model Serving with PagedAttention", кэш KV использует около 30 % памяти GPU, что приводит к потенциальным проблемам с памятью. Кэш KV хранится в смежной памяти, но изменение его размера может привести к фрагментации памяти, что неэффективно для вычислений.

Изображение 1. Управление кэш-памятью KV в существующих системах (2023 Paged Attention газета)
Используя виртуальную память для кэша KV, vLLM выделяет физическую память GPU только по мере необходимости, устраняя фрагментацию памяти и избегая предварительного распределения. В тестах vLLM превзошел HuggingFace Transformers (HF) и Text Generation Inference (TGI), достигнув пропускной способности в 24 раза выше, чем у HF, и в 3,5 раза выше, чем у TGI, на графических процессорах NVIDIA A10G и A100.
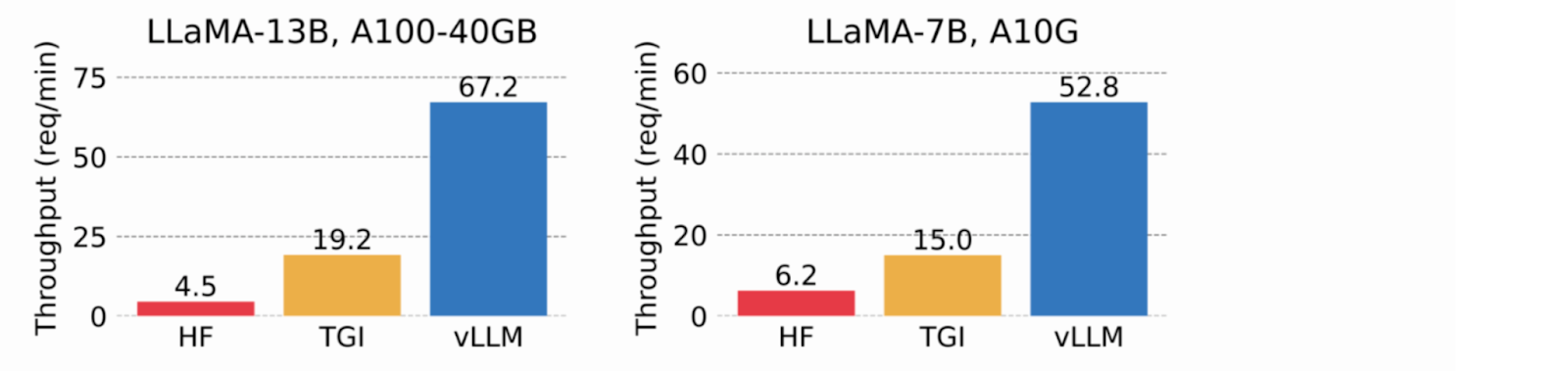
Изображение 2. Пропускная способность сервиса, когда каждый запрос запрашивает три параллельных завершения вывода. vLLM достигает 8,5x-15x более высокой пропускной способности, чем HF, и 3,3x-3,5x более высокой пропускной способности, чем TGI (2023 vLLM blog).
Meta's Llama 3.1
Meta's Llama 3.1 была анонсирована 23 июля 2024 года. Модель 405B демонстрирует высочайшую производительность в нескольких публичных бенчмарках и имеет контекстное окно из 128 000 входных токенов с возможностью различного коммерческого использования. Наряду с моделью с 405 миллиардами параметров, Meta выпустила обновленные версии Llama3 70B (70 миллиардов параметров) и 8B (8 миллиардов параметров). Весовые коэффициенты моделей доступны для загрузки на сайте Meta.
Ключевым моментом стало то, что точная настройка сгенерированных данных может повысить производительность, но некачественные примеры могут ее снизить. Команда Llama провела большую работу по выявлению и удалению таких плохих примеров, используя саму модель, вспомогательные модели и другие инструменты.
Сборка и выполнение RAG-поиска с помощью Milvus
Подготовьте набор данных
В качестве набора данных для этой демонстрации я использовал официальную документацию Milvus, которую я скачал и сохранил локально.
from langchain.document_loaders import DirectoryLoader
# Загрузка HTML-файлов, уже сохраненных в локальном каталоге
path = "../../RAG/rtdocs_new/"
global_pattern = '*.html'
loader = DirectoryLoader(path=path, glob=global_pattern)
docs = loader.load()
# Выведите количество документов и предварительный просмотр.
print(f "загружено {len(docs)} документов")
print(docs[0].page_content)
pprint.pprint(docs[0].metadata)
 loaded 22 docs
loaded 22 docs
Загрузите модель встраивания
Далее загрузите бесплатную модель встраивания с открытым исходным кодом embedding model с сайта HuggingFace.
import torch
from sentence_transformers import SentenceTransformer
# Инициализируем настройки torch для кода, не зависящего от устройств.
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# Загружаем модель из концентратора моделей huggingface.
model_name = "BAAI/bge-large-en-v1.5"
encoder = SentenceTransformer(model_name, device=DEVICE)
# Получаем параметры модели и сохраняем их на потом.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Проверьте параметры модели.
print(f "имя_модели: {имя_модели}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH}")

Разбивайте и кодируйте ваши пользовательские данные в виде векторов.
Я использую фиксированную длину 512 символов с 10-процентным перекрытием.
from langchain.text_splitter import RecursiveCharacterTextSplitter
РАЗМЕР_КУСКА = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# Определите сплиттер.
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap)
# Разбиваем документы на куски.
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)} документов разбиты на {len(chunks)} дочерних документов.")
# Входные данные кодера - doc.page_content в виде строк.
list_of_strings = [doc.page_content for doc in chunks if hasattr(doc, 'page_content')]
# Вывод вложений с использованием кодировщика HuggingFace.
embeddings = torch.tensor(encoder.encode(list_of_strings))
# Нормализуем эмбеддинги.
embeddings = np.array(embeddings / np.linalg.norm(embeddings))
# Milvus ожидает список `numpy.ndarray` из чисел `numpy.float32`.
converted_values = list(map(np.float32, embeddings))
# Создаем dict_list для вставки в Milvus.
dict_list = []
for chunk, vector in zip(chunks, converted_values):
# Соберите вектор встраивания, исходный текстовый фрагмент, метаданные.
chunk_dict = {
'chunk': chunk.page_content,
'source': chunk.metadata.get('source', ""),
'vector': vector,
}
dict_list.append(chunk_dict)

Сохраните векторы в Milvus
Внесите закодированные векторные вложения в базу данных векторов Milvus.
# Подключите клиента к серверу Milvus Lite.
from pymilvus import MilvusClient
mc = MilvusClient("milvus_demo.db")
# Создайте коллекцию с гибкой схемой и AUTOINDEX.
COLLECTION_NAME = "MilvusDocs"
mc.create_collection(COLLECTION_NAME,
EMBEDDING_DIM,
consistency_level="Eventually",
auto_id=True,
overwrite=True)
# Вставьте данные в коллекцию Milvus.
print("Начать вставку сущностей")
start_time = time.time()
mc.insert(
ИМЯ_КОЛЛЕКЦИИ,
data=dict_list,
progress_bar=True)
end_time = time.time()
print(f "Время вставки Milvus для векторов {len(dict_list)}: ", end="")
print(f"{round(end_time - start_time, 2)} секунд")

Выполните векторный поиск
Задайте вопрос и найдите ближайших соседей из вашей базы знаний в Milvus.
SAMPLE_QUESTION = "Что означают параметры для HNSW?"
# Встраиваем вопрос, используя тот же кодер.
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION))
# Нормализуем эмбеддинги к единичной длине.
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
# Преобразуем вкрапления в список np.float32.
query_embeddings = list(map(np.float32, query_embeddings))
# Определите поля метаданных, по которым можно фильтровать.
OUTPUT_FIELDS = list(dict_list[0].keys())
OUTPUT_FIELDS.remove('vector')
# Определите, сколько результатов top-k вы хотите получить.
TOP_K = 2
# Запустите семантический векторный поиск, используя ваш запрос и базу данных векторов.
results = mc.search(
ИМЯ_КОЛЛЕКЦИИ,
data=query_embeddings,
output_fields=OUTPUT_FIELDS,
limit=TOP_K,
consistency_level="Eventually")
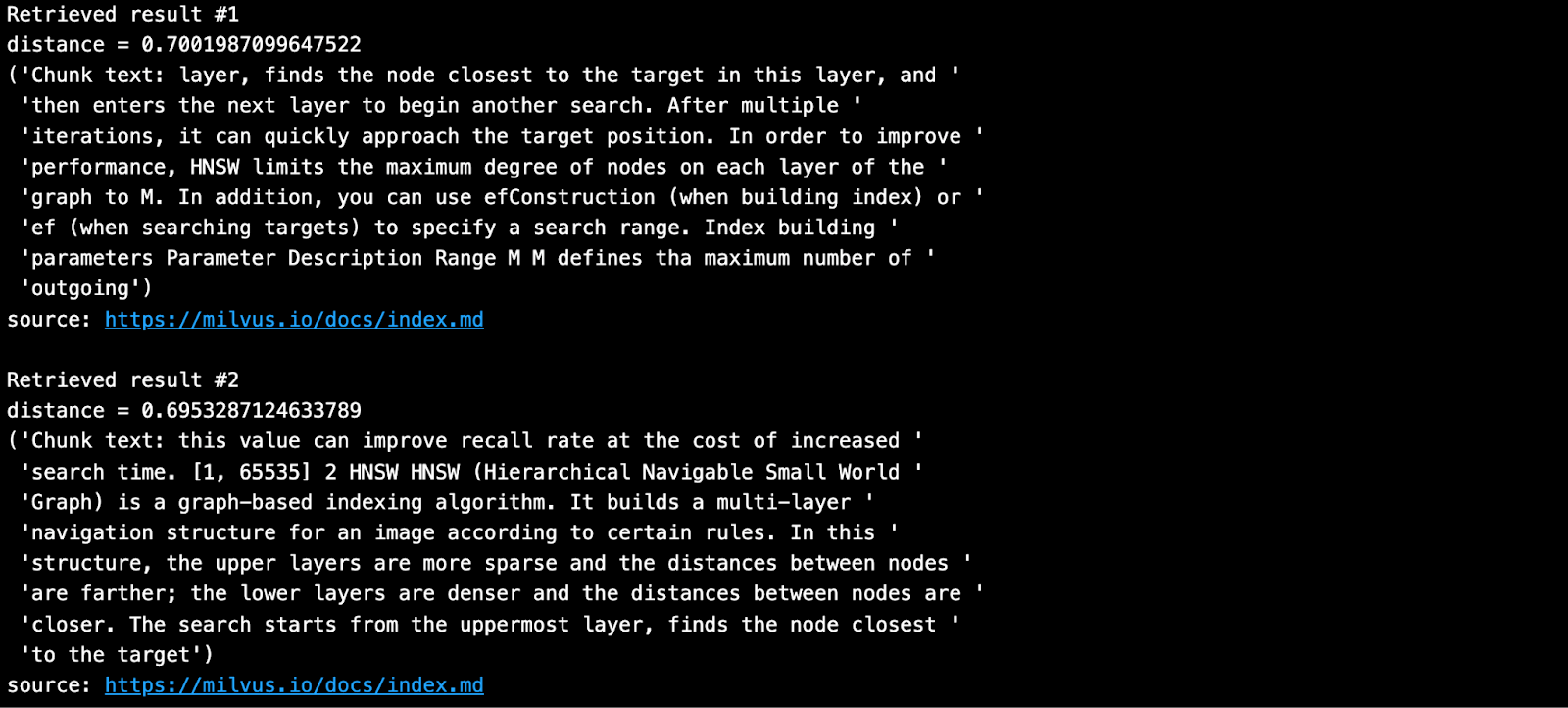
Полученный результат выглядит так, как показано ниже.
Сборка и выполнение RAG-генерации с помощью vLLM и Llama 3.1-8B
Установите vLLM и модели из HuggingFace
vLLM по умолчанию загружает большие языковые модели из HuggingFace. В общем, если вы хотите использовать новую модель на HuggingFace, вам следует выполнить pip install--update или -U. Кроме того, вам понадобится графический процессор, чтобы проводить анализ моделей Meta's Llama 3.1 с помощью vLLM.
Полный список всех моделей, поддерживаемых vLLM, можно найти на этой странице документации.
# (Рекомендуется) Создайте новое окружение conda.
conda create -n myenv python=3.11 -y
conda activate myenv
# Установите vLLM с CUDA 12.1.
pip install -U vllm transformers torch
import vllm, torch
из vllm import LLM, SamplingParams
# Очистите кэш памяти GPU.
torch.cuda.empty_cache()
# Проверьте графический процессор.
!nvidia-smi
Более подробную информацию об установке vLLM можно найти на странице installation.
Получение токена HuggingFace
Некоторые модели на HuggingFace, такие как Meta Llama 3.1, требуют, чтобы пользователь принял их лицензию, прежде чем сможет загрузить грузы. Поэтому вы должны создать учетную запись HuggingFace, принять лицензию модели и сгенерировать токен.
При посещении этой Llama3.1 page на HuggingFace вы получите сообщение с просьбой согласиться с условиями. Нажмите "Accept License", чтобы принять условия Meta перед загрузкой весов модели. Согласие обычно занимает менее суток.
После получения одобрения вы должны сгенерировать новый токен HuggingFace. Ваши старые токены не будут работать с новыми разрешениями.
Перед установкой vLLM войдите в HuggingFace с новым токеном. Ниже я использовал секреты Colab для хранения токена.
# Войдите в HuggingFace, используя свой новый токен.
from huggingface_hub import login
из google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
Запустите генерацию RAG
В демонстрационном примере мы запускаем модель Llama-3.1-8B, которая требует GPU и большого объема памяти для разгона. Следующий пример был запущен на Google Colab Pro ($10/месяц) с графическим процессором A100. Чтобы узнать больше о том, как запустить vLLM, вы можете ознакомиться с Quickstart documentation.
# 1. Выберите модель
MODELTORUN = "meta-llama/Meta-Llama-3.1-8B-Instruct"
# 2. Очистите кэш памяти GPU, он вам еще пригодится!
torch.cuda.empty_cache()
# 3. Создайте экземпляр модели vLLM.
llm = LLM(model=MODELTORUN,
enforce_eager=True,
dtype=torch.bfloat16,
gpu_memory_utilization=0.5,
max_model_len=1000,
seed=415,
max_num_batched_tokens=3000)

Напишите подсказку, используя контексты и источники, взятые из Milvus.
# Разделите все контексты пробелом.
contexts_combined = ' '.join(contexts)
# Лэнс Мартин, LangChain, говорит, что лучшие контексты нужно помещать в конец.
contexts_combined = ' '.join(reversed(contexts))
# Разделите все уникальные источники запятой.
source_combined = ' '.join(reversed(list(dict.fromkeys(sources))))
SYSTEM_PROMPT = f"""Сначала проверьте, имеет ли предоставленный Контекст отношение к
вопросу пользователя. Во-вторых, только если предоставленный Контекст сильно релевантен, ответьте на вопрос, используя Контекст. В противном случае, если Контекст не очень релевантен, ответьте на вопрос без использования Контекста.
Будьте ясными, краткими, релевантными. Отвечайте четко, не более чем в 2 предложениях.
Источники для обоснования: {source_combined}
Контекст: {contexts_combined}
Вопрос пользователя: {SAMPLE_QUESTION}
"""
подсказки = [SYSTEM_PROMPT]
Теперь сгенерируйте ответ, используя полученные фрагменты и исходный вопрос, помещенный в подсказку.
# Параметры выборки
sampling_params = SamplingParams(temperature=0.2, top_p=0.95)
# Вызовите модель vLLM.
outputs = llm.generate(prompts, sampling_params)
# Выведите выходные данные.
for output in outputs:
prompt = output.prompt
сгенерированный_текст = output.outputs[0].text
# !r вызывает функцию repr(), которая печатает строку в кавычках.
print()
print(f "Вопрос: {SAMPLE_QUESTION!r}")
pprint.pprint(f "Сгенерированный текст: {generated_text!r}")

Этот ответ кажется мне идеальным!
Если вас заинтересовало это демо, не стесняйтесь попробовать его сами и сообщить нам о своих мыслях. Вы также можете присоединиться к нашему сообществу Milvus на Discord, чтобы пообщаться со всеми разработчиками GenAI напрямую.
Ссылки
презентация 2023 vLLM на Ray Summit
Блог vLLM: vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
Полезный блог о запуске сервера vLLM: Deploying vLLM: a Step-by-Step Guide

Читать далее

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.