




Milvus 2.4 представляет CAGRA: повышение эффективности векторного поиска с помощью индексирования на GPU нового поколения
Что такое индекс на базе GPU?
Векторный поиск по своей сути требует больших вычислений. Занимая лидирующие позиции в качестве самой производительной векторной базы данных, Milvus выделяет более 80 % вычислительных ресурсов на свои векторные базы данных и поисковую систему, Knowhere. Учитывая требования высокопроизводительных вычислений, графические процессоры становятся ключевым элементом нашей платформы векторных баз данных, особенно в области векторного поиска.
Milvus создал прецедент, став первой векторной базой данных, использующей GPU-ускорение в своей Milvus version 1.1 в 2021 году. В версии 2.3, используя библиотеку NVIDIA RAFT для векторного поиска, Milvus представил индексы с GPU-ускорением и интеграцию с рекомендательным фреймворком NVIDIA Merlin (используется для создания рекомендательных систем). Внедрение индексов IVFFLAT и IVFPQ в этой версии продемонстрировало значительный прирост производительности.
Несмотря на эти достижения, такие проблемы, как оптимизация производительности для небольших партий запросов и повышение рентабельности индексов на базе GPU, остаются, что побуждает к постоянному поиску инновационных решений. Переход отрасли к алгоритмам [векторного поиска] на основе графов (https://zilliz.com/learn/popular-machine-learning-algorithms-behind-vector-search), признанным за их превосходную производительность над методами на основе ЭКО, знаменует собой поворотную эволюцию. Однако адаптация этих алгоритмов к графическим процессорам не является простой из-за их последовательного выполнения и случайного доступа к памяти, что делает эффективную реализацию на GPU сложной для таких алгоритмов, как GGNN и SONG.
Решение этих проблем - последняя инновация NVIDIA, графовый индекс на базе GPU CAGRA, представляет собой значительную веху. При содействии NVIDIA Milvus интегрировал поддержку CAGRA в свою версию 2.4, что стало значительным шагом на пути к преодолению препятствий эффективной реализации векторного поиска на GPU.
Что такое CAGRA?
Сборка CAGRA
CAGRA (CUDA Anns GRAph-based) представляет новый подход к построению графов, отличающийся от итеративного метода вставки-обновления, используемого в иерархических навигационных малых мирах (HNSW) графов на центральных процессорах. Это изменение решает проблему полного использования высокопараллельных возможностей GPU по построению графов, которые не используются в процессе построения HNSW на CPU. CAGRA начинает с создания исходного графа с помощью IVFPQ или NN-DESCENT, где каждый узел связан с множеством соседей. Следующие шаги включают сортировку этих связей по важности, обрезку менее важных ребер и объединение направленных графов для окончательного формирования структуры и построения исходного графа. В исходном графе каждый узел имеет большое количество соседних узлов. Затем CAGRA сортирует все соседние ребра по их важности на основе исходного графа и обрезает неважные ребра.
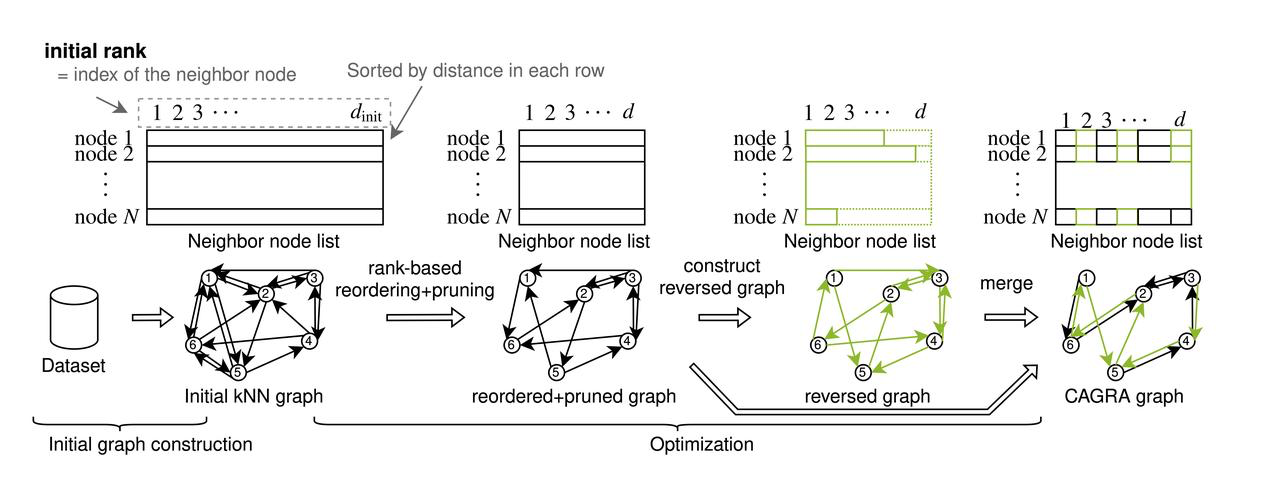 Процесс построения CAGRA
Процесс построения CAGRA
Построение начального графа
IVFPQ
В режиме IVFPQ CAGRA использует набор данных для построения индекса IVFPQ, используя функцию квантования индекса Product Quantization (PQ) для минимизации использования видеопамяти. После создания этого индекса CAGRA выполняет поиск каждой точки в наборе данных, используя приблизительные ближайшие соседи, определенные индексом IVFPQ, в качестве поиска ближайших соседей смежных точек. Этот процесс является основой для построения исходного графа, обеспечивая эффективную настройку без значительного увеличения объема памяти.
NN-DESCENT
В CAGRA используется алгоритм NN-DESCENT для другого подхода к построению начального графа, который включает в себя следующие подробные шаги:
Инициализация: Случайным образом выбираем k точек из набора данных v для создания начального списка смежности B[v].
**Обратный список B[v] для создания обратного списка смежности R[v], а затем объедините B и R, чтобы сформировать H[v].
Расширение соседей: Для любого узла v в наборе данных определите всех соседей соседей на основе H[v], выбрав ближайшие верхниеk узлов в качестве его новых соседей.
Итерация: Повторяйте процессы Изменение и слияние и Расширение соседей до тех пор, пока B не стабилизируется и не перестанет изменяться, или пока не будет достигнут заданный порог итерации.
По сравнению с HNSW, NN-Descent обеспечивает более легкое распараллеливание и меньшее взаимодействие данных между задачами, что значительно увеличивает время построения графа и эффективность графа смежности CAGRA на графических процессорах. Однако следует отметить, что начальное качество графа в NN-DESCENT может несколько отставать от качества, достигаемого в режиме IVFPQ.
Оптимизация CAGRA
Стратегия оптимизации графов в CAGRA основана на двух основных предположениях:
Сортировка по важности: Для определения важности ребер предпочтение отдается сортировке на основе путей, а не традиционной сортировке на основе расстояний. Этот метод утверждает, что связность графа может не обязательно выиграть от сортировки по важности на основе расстояния.
Слияние обратных графов: Принцип, согласно которому узел, считающийся важным для одного, может оказаться важным и для другого, лежит в основе стратегии слияния обратных графов.
Процесс оптимизации включает два основных этапа:
- Рунификация: Первоначально смежным ребрам каждого узла присваиваются различные веса ('w'), основанные на расстоянии. CAGRA использует стратегию обрезки, при которой ребра обрезаются, если они соединяют узлы, которые являются наиболее "неблагоприятными", на основе условия "max(w_{x to z},w_{z to y}) < w_{x to y}". Это позволяет устранить менее критичные связи, чтобы упорядочить граф.
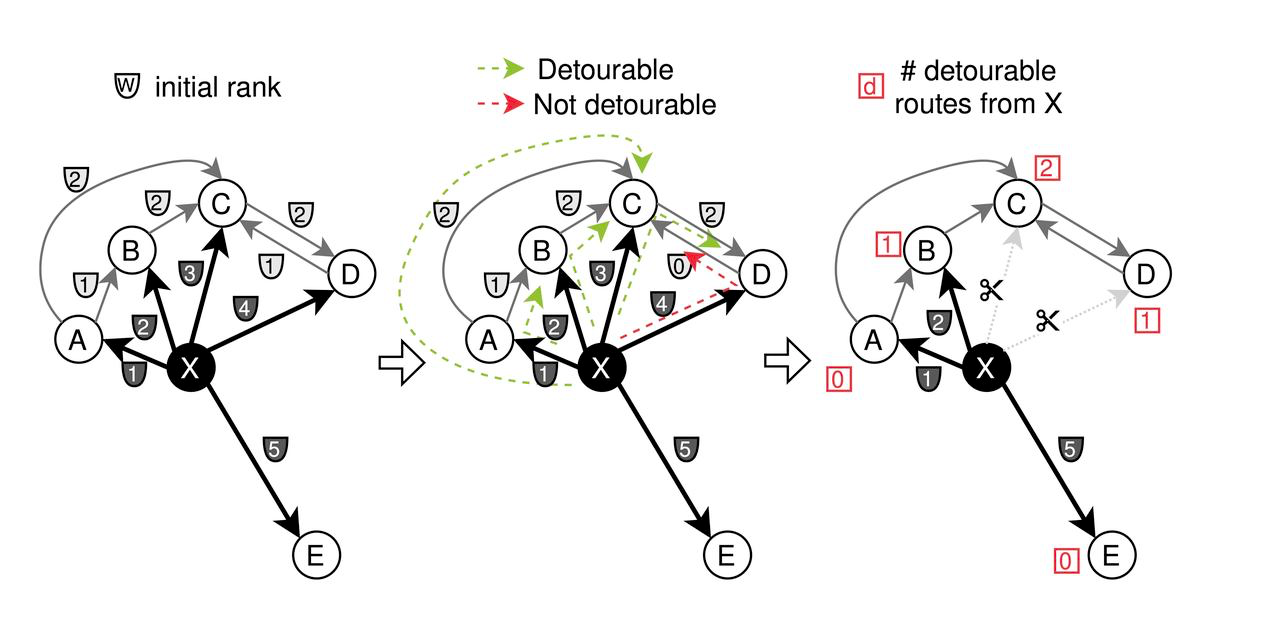 Процесс обрезки для CAGRA-оптимизации
Процесс обрезки для CAGRA-оптимизации
- Слияние: После обрезки прямого графа на основе значимости путей, ребра инвертируются и объединяются. В частности, половина ребер выбирается из прямого и обратного графов для создания окончательного оптимизированного графа CAGRA.
Такой детальный подход к построению и оптимизации графа обеспечивает эффективность и результативность CAGRA в операциях векторного поиска, используя уникальные возможности графических процессоров и решая проблемы, присущие алгоритмам поиска на основе графов.
Поиск с помощью CAGRA
Механизм поиска CAGRA использует методичный подход с применением упорядоченной приоритетной очереди фиксированного размера для эффективной навигации по графу. Этот подробный процесс описывается в виде серии шагов в структурированной системе:
CAGRA Search Framework
CAGRA работает с последовательным буфером памяти, состоящим из внутреннего списка Top-M и списка кандидатов. Внутренний список top-M действует как приоритетная очередь, его длина установлена на M (где M ≥ k), что позволяет хранить наиболее релевантные результаты до желаемого количества ближайших соседей, k. Размер списка кандидатов определяется p × d, где p представляет собой количество исходных вершин, исследуемых в каждой итерации, а d - степень графа. Каждый элемент в этих списках сопрягает индекс узла с расстоянием до запроса, что позволяет эффективно управлять поиском.
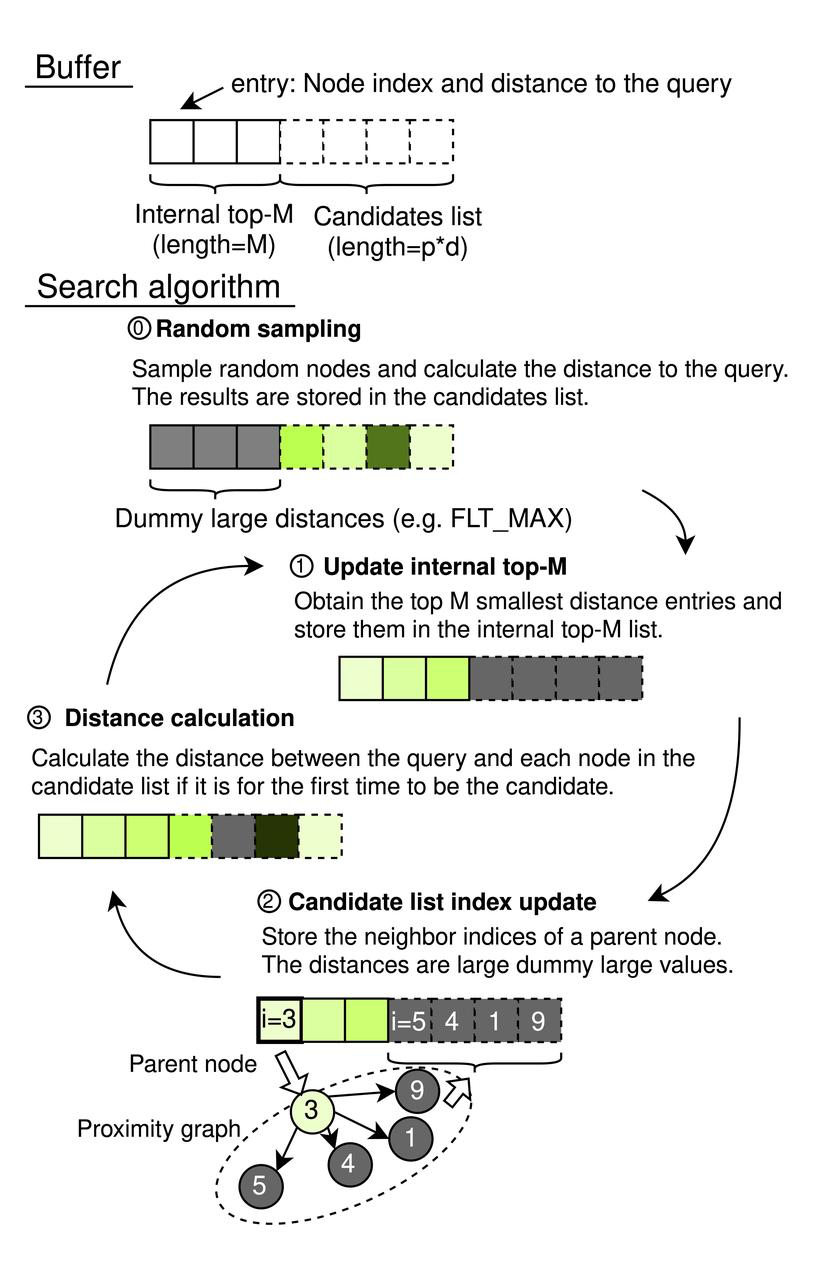 Процесс поиска CAGRA
Процесс поиска CAGRA
Этапы процесса поиска
- Случайная выборка (инициализация).
- Используется псевдослучайный генератор для выбора p × d случайных индексов узлов, вычисляя расстояние между каждым узлом и запросом.
- Результаты заполняют список кандидатов, а внутренний список top-M инициализируется виртуальными элементами (установленными на FLT_MAX), чтобы не влиять на исходные результаты сортировки.
Обновление внутреннего списка Top-M: Выбор узлов Top-M на основе наименьших расстояний по всему буферу для включения во внутренний список Top-M.
Обновление индекса списка кандидатов (обход графа):
- Определяет все соседние узлы верхних p узлов из внутреннего списка top-M, исключая ранее использованные узлы с помощью фильтра хэш-таблицы.
- Добавляет этих соседей в список кандидатов, не пересчитывая расстояния на этом этапе.
- Вычисление расстояния:
- Выполняет расчет расстояний для узлов, вновь появляющихся в списке кандидатов, избегая избыточных вычислений для узлов, оцененных в предыдущих итерациях.
- Обеспечивает добавление узлов в список Top-M только в том случае, если их расстояния оправдывают их значимость, исходя из того, являются ли они достаточно малыми, чтобы принадлежать, или слишком большими, чтобы их рассматривать.
Алгоритм итеративно выполняет эти шаги, перебирая все узлы во внутреннем списке top-M, пока все они не станут отправными точками для поиска. Поиск завершается извлечением k лучших записей из внутреннего списка top-M, предоставляя результаты Approximate Nearest Neighbor Search (ANNS).
Производительность
Решение использовать индексы на GPU было продиктовано в первую очередь соображениями производительности. Мы провели комплексную оценку производительности Milvus, используя open-source vector database benchmark tool, сосредоточившись на сравнении между HNSW, GPU-based IVFFLAT и индексами CAGRA.
Установка для бенчмаркинга
Для реалистичной оценки наши бенчмарки проводились на машинах, размещенных в AWS и оснащенных графическими процессорами NVIDIA T4 и A10G, при этом тестовые среды отражали общедоступные ресурсы. Выбранные машины были сопоставимы по цене, что обеспечило равные условия для оценки производительности. Все тесты были направлены на достижение top100@98% recall, в качестве клиента использовался экземпляр AWS m6i.4xlarge (16C64G).
 Основная информация о выбранной машине
Основная информация о выбранной машине
Информация о производительности
** Производительность малых партий:**
В ситуациях с небольшими партиями поиска (размер партии 1), где GPU обычно используются недостаточно эффективно, CAGRA значительно превзошла свои аналоги. Наши тесты показали, что в таких условиях CAGRA может почти в 10 раз превзойти традиционные методы.
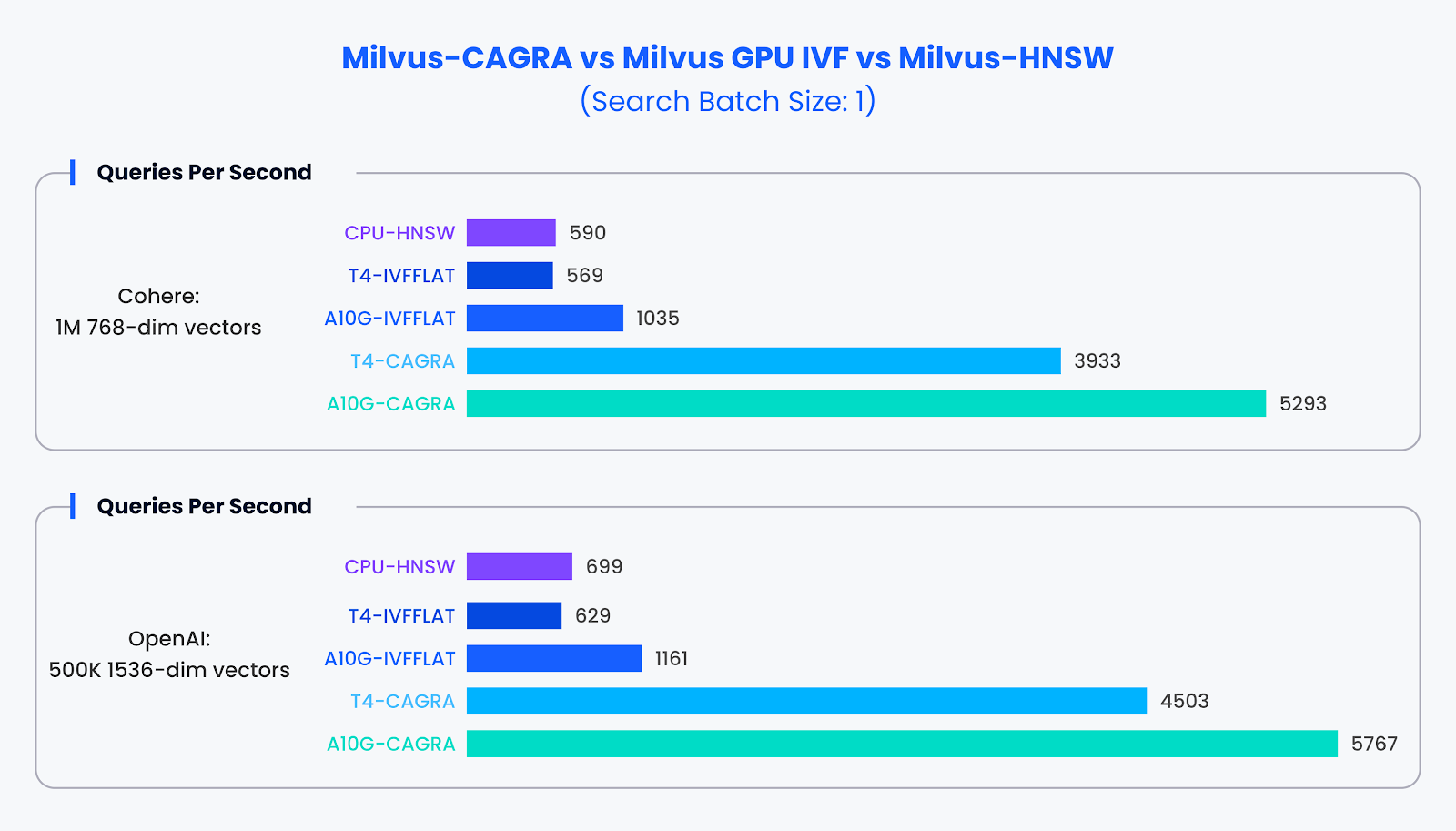 Сравнение производительности для малого набора данных
Сравнение производительности для малого набора данных
Большая производительность:
При рассмотрении больших поисковых партий (размером 10 и 100) преимущество CAGRA стало еще более заметным. По сравнению с HNSW CAGRA продемонстрировала значительный рост производительности, улучшив эффективность поиска в десятки раз.
 Сравнение производительности для большого набора данных
Сравнение производительности для большого набора данных
Индекс эффективности зданий:
Помимо возможностей поиска, мастерство CAGRA распространяется и на построение индексов. С помощью GPU-ускорения CAGRA продемонстрировала способность строить индексы примерно в 10 раз быстрее, чем альтернативные методы.
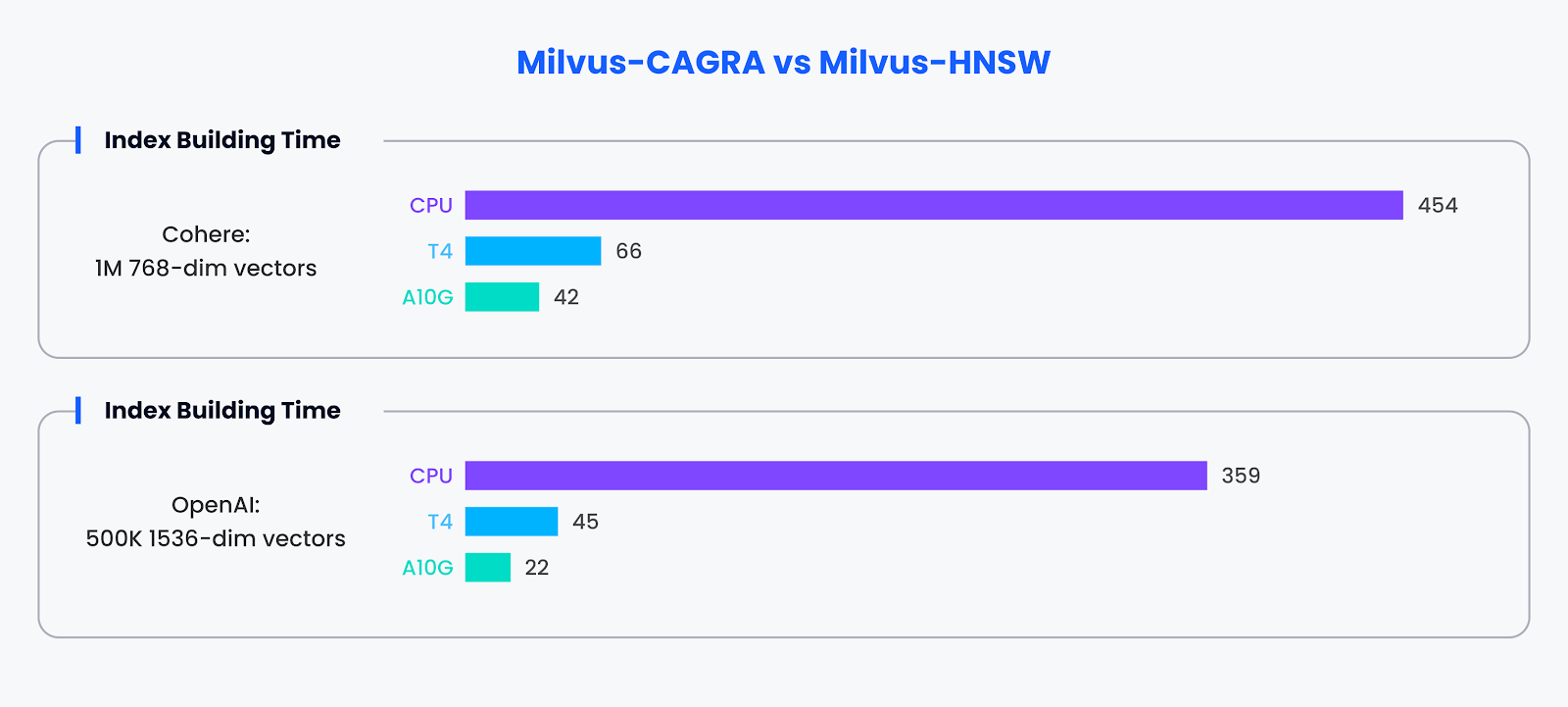 Сравнение производительности при построении индексов
Сравнение производительности при построении индексов
Результаты бенчмарков подчеркивают значительные преимущества в производительности при использовании индексов с GPU-ускорением, таких как CAGRA, в Milvus. Он не только ускоряет выполнение поисковых задач при разных размерах пакетов, но и значительно повышает скорость построения индексов, подтверждая ценность GPU для оптимизации производительности векторных баз данных.
Что дальше?
CAGRA - это значительный шаг вперед в нашем стремлении переопределить границы векторного поиска, продемонстрировав потенциал поиска на базе GPU для решения самых сложных производственных задач. По мере продвижения вперед Milvus намерена глубже изучить аспекты high recall, низкой задержки, экономической эффективности и масштабируемости векторного поиска. Наши обязательства выходят за рамки текущих достижений и включают в себя более гибкое управление данными, расширенные возможности поиска и революционные оптимизации производительности.
Это видение побуждает нас к постоянным инновациям, гарантируя, что Milvus будет лидером и первопроходцем в области ускоренного поиска неструктурированных данных. Расширяя границы возможного сегодня, мы стремимся раскрыть новые возможности завтрашнего дня, делая векторный поиск более мощным, эффективным и доступным.
 Практические советы и рекомендации для разработчиков по использованию векторных баз данных.png
*Не уверены, какой индекс выбрать для своего решения? У нас есть блог, который поможет вам сделать правильный выбор! *
Практические советы и рекомендации для разработчиков по использованию векторных баз данных.png
*Не уверены, какой индекс выбрать для своего решения? У нас есть блог, который поможет вам сделать правильный выбор! *

Читать далее

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.