




HKU NLP / instructor-large
Задача: Встраивание
Модальность: Текст
Метрика сходства: Косинус
Лицензия: Apache 2.0
Размерности: 768
Максимальное количество входных токенов: 512
Цена: Бесплатно
Введение в семейство моделей инструкторов
Модель Instructor от NKU NLP - это модель встраивания текста с точной настройкой инструкций. Она создает вкрапления для конкретных задач (классификация, поиск, кластеризация, оценка текста и т. д.) в различных областях (например, наука и финансы), просто предоставляя инструкции по задаче - дополнительная настройка не требуется. Он показал лучшие результаты в 70 задачах встраивания!
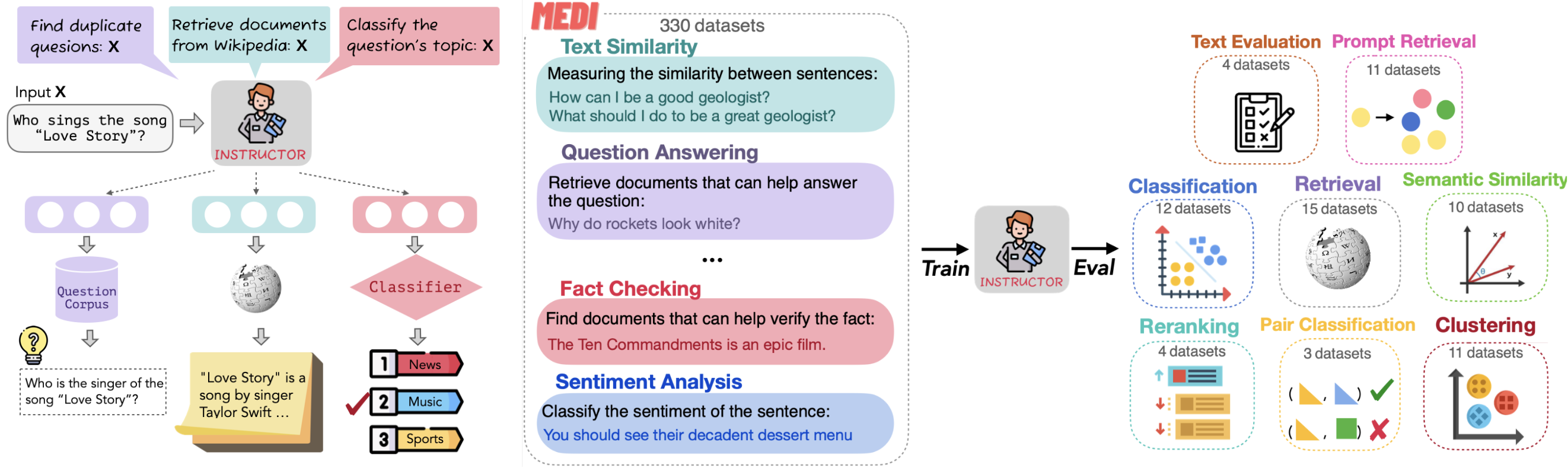 Рисунок "Как работает модель инструктора"
Рисунок "Как работает модель инструктора"
Рисунок: Как работает модель инструктора (иллюстрация NKU NLP)
Модель инструктора существует в трех вариантах: instructor-base, instructor-xl и instructor-large. Каждая версия предлагает различные уровни производительности и масштабируемости для удовлетворения различных потребностей во встраивании.
Введение в instructor-large
instructor-large - это модель встраивания текста среднего размера в семействе моделей Instructor. Она может генерировать текстовые вкрапления, специфичные для конкретной задачи и домена, предоставляя инструкции на естественном языке без дополнительной настройки. Она идеально подходит для любых задач (например, классификация, поиск, кластеризация, оценка текста и т. д.) и доменов (например, наука, финансы и т. д.). instructor-large достигает SOTA на 70 различных задачах встраивания в бенчмарке MTEB.
Он работает лучше, чем instructor-base, но хуже, чем instructor-xl.
Сравнение instructor-base, instructor-xl и instructor-large:
| Feature | instructor-base | instructor-large | instructor-xl | |
|---|---|---|---|---|
| Размер параметров | 86 миллионов | 335 миллионов | 1,5 миллиарда | |
| Размерность встраивания | 768 | 768 | 768 | 768 |
| Avg. MTEB Score | 55.9 | 58.4 | 58.8 |
Как создать векторные вкрапления с помощью модели instructor-large
Мы рекомендуем использовать библиотеку InstructorEmbedding для создания векторных вкраплений.
После создания векторных вкраплений их можно хранить в Zilliz Cloud (полностью управляемый сервис векторных баз данных на базе Milvus) и использовать для поиска семантического сходства. Вот четыре ключевых шага:
- Зарегистрируйтесь для получения бесплатной учетной записи Zilliz Cloud.
- Настройте бессерверный кластер и получите Публичную конечную точку и ключ API.
- Создайте коллекцию векторов и вставьте в нее свои векторные вкрапления.
- Запустите семантический поиск по сохраненным вкраплениям.
Генерировать векторные вкрапления с помощью библиотеки InstructorEmbedding и вставлять их в Zilliz Cloud для семантического поиска
from InstructorEmbedding import INSTRUCTOR
from pymilvus import MilvusClient
модель = ИНСТРУКТОР('hkunlp/instructor-large')
docs = [["Представьте документ Википедии для поиска: ", "Искусственный интеллект был основан как академическая дисциплина в 1956 году"],
["Представьте документ Википедии для поиска: ", "Алан Тьюринг был первым человеком, который провел серьезные исследования в области искусственного интеллекта"],
["Представьте документ Википедии для поиска: ", "Тьюринг родился в Майда-Вейл, Лондон, и вырос в южной Англии"]].
# Генерируем вкрапления для документов
docs_embeddings = model.encode(docs, normalize_embeddings=True)
queries = [["Представьте вопрос Википедии для поиска подтверждающих документов: ", "Когда был основан искусственный интеллект"]
["Представьте вопрос Википедии для поиска подтверждающих документов: ", "Где родился Алан Тьюринг?"]]
# Генерируем вкрапления для запросов
query_embeddings = model.encode(queries, normalize_embeddings=True)
# Подключение к облаку Zilliz с помощью публичной конечной точки и ключа API
client = MilvusClient(
uri=ZILLIZ_PUBLIC_ENDPOINT,
token=ZILLIZ_API_KEY)
КОЛЛЕКЦИЯ = "документы"
if client.has_collection(collection_name=COLLECTION):
client.drop_collection(collection_name=COLLECTION)
client.create_collection(
имя_коллекции=COLLECTION,
dimension=768,
auto_id=True)
для doc, embedding в zip(docs, docs_embeddings):
client.insert(COLLECTION, {"text": doc, "vector": embedding})
results = client.search(
имя_коллекции=КОЛЛЕКЦИЯ,
data=query_embeddings,
consistency_level="Strong",
output_fields=["text"])
- Введение в семейство моделей инструкторов
- Введение в instructor-large
- Как создать векторные вкрапления с помощью модели instructor-large
Контент
Беспрерывные AI рабочие процессы
От встраиваний до масштабируемого AI поиска—Zilliz Cloud позволяет вам хранить, индексировать и извлекать встраивания с непревзойденной скоростью и эффективностью.
Попробуйте Zilliz Cloud Бесплатно

