




Extração de dados: De dados brutos a informações valiosas

Extração de dados: De dados brutos a informações valiosas
O que é Data Mining?
A extração de dados é uma técnica para descobrir padrões, tendências e conhecimentos valiosos a partir de grandes quantidades de dados. Ajuda as empresas e os investigadores a tomar melhores decisões, descobrindo ligações ocultas que não são óbvias à primeira vista. Ao utilizar técnicas como classificação, agrupamento e extração de regras de associação, a extração de dados transforma dados em bruto em informações valiosas. Quer se trate de prever o comportamento do cliente, detetar fraudes ou melhorar os resultados de pesquisa, a extração de dados desempenha um papel fundamental na formação da tecnologia moderna.
Como funciona a extração de dados?
A extração de dados analisa grandes conjuntos de dados para encontrar padrões, relações e tendências ocultas que podem ser utilizadas para a tomada de decisões. Utiliza métodos estatísticos, algoritmos de aprendizagem automática e técnicas de gestão de bases de dados para transformar dados em bruto em informações acionáveis. O processo segue uma série de passos para limpar, organizar e extrair informações úteis dos dados. Para compreender melhor esta questão, considere uma plataforma de comércio eletrónico que pretende prever quais os clientes que irão provavelmente comprar com base no seu comportamento de navegação.
Passos no processo de extração de dados
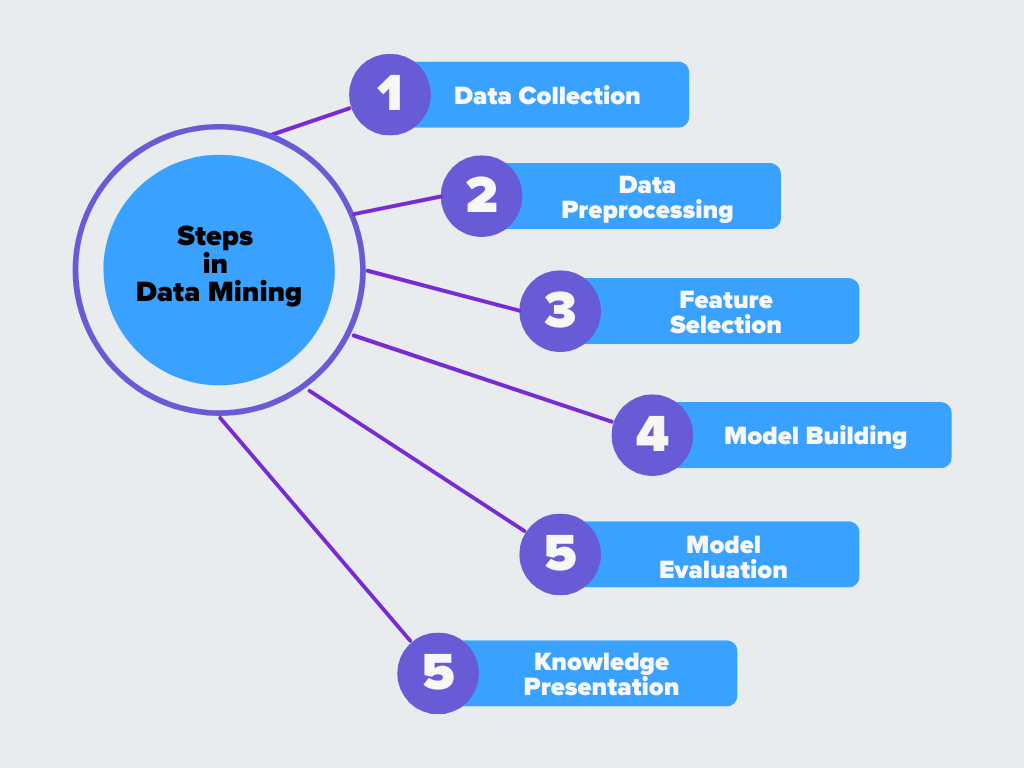 Figura - Etapas da extração de dados
Figura - Etapas da extração de dados
Figura: Etapas da extração de dados
1. Recolha de dados
O primeiro passo é recolher dados de diferentes fontes, como bases de dados, folhas de cálculo, dispositivos IoT ou armazenamento na nuvem. Uma vez que os dados são frequentemente apresentados em vários formatos e estruturas, devem ser integrados num único sistema. Esta etapa também trata os registos duplicados e funde conjuntos de dados para criar uma visão unificada. **Por exemplo, uma plataforma de comércio eletrónico recolhe dados de registos do sítio Web, contas de utilizador e histórico de compras para criar uma visão completa do comportamento do cliente.
2. Pré-processamento de dados
Os dados em bruto raramente são perfeitos. Podem conter valores em falta, inconsistências ou erros que podem afetar a exatidão dos resultados. O pré-processamento de dados envolve a limpeza dos dados através da remoção de duplicados, do preenchimento de valores em falta e da correção de erros. As técnicas de pré-processamento, como a normalização e a transformação, ajudam a estruturar os dados para que estejam prontos para análise. **Por exemplo, alguns clientes podem ter perfis incompletos, histórico de compras em falta ou registos duplicados que precisam de ser limpos antes da análise.
3. Seleção de caraterísticas
Nem todos os pontos de dados são úteis para a extração. Na [seleção de caraterísticas] (https://zilliz.com/ai-faq/what-is-feature-extraction), os dados são transformados num formato mais adequado e as caraterísticas essenciais são selecionadas, enquanto as irrelevantes são removidas. A engenharia de caraterísticas cria novas variáveis com base nos dados existentes, o que também faz parte desta etapa para melhorar o desempenho do modelo. **Por exemplo, podem ser selecionadas caraterísticas como o tempo passado em páginas de produtos, compras anteriores e taxa de abandono de carrinhos, enquanto dados menos úteis, como endereços IP, podem ser removidos.
4. Construção do modelo
Depois de os dados serem limpos e preparados, são aplicados algoritmos para encontrar padrões e relações. Técnicas como o agrupamento, a classificação e a extração de regras de associação ajudam a identificar informações significativas. Os modelos de aprendizagem automática podem ser treinados nesta fase para reconhecer tendências, classificar dados ou fazer previsões com base em padrões históricos. **Por exemplo, a plataforma pode utilizar um modelo de classificação para prever se um utilizador irá provavelmente efetuar uma compra com base no seu comportamento de navegação e compras anteriores.
5. Avaliação do modelo
Nem todos os padrões descobertos durante a extração são úteis. Esta etapa valida os resultados para garantir que são exactos e significativos. Os analistas comparam as descobertas com dados conhecidos, utilizam [métricas de desempenho] (https://zilliz.com/learn/information-retrieval-metrics) como a exatidão e a recuperação, e aperfeiçoam os modelos, se necessário. O objetivo é confirmar que os padrões encontrados são fiáveis e aplicáveis a cenários do mundo real. **Por exemplo, a plataforma testa o modelo de previsão comparando os seus resultados com compras reais para verificar a sua exatidão.
6. Apresentação de conhecimentos
O passo final é apresentar os conhecimentos de forma clara e compreensível. Isto pode incluir relatórios visuais, painéis de controlo ou resumos que os decisores possam utilizar. O conhecimento extraído é então aplicado para melhorar os processos, tomar decisões comerciais ou melhorar os sistemas orientados para a IA.
**Por exemplo, a plataforma de comércio eletrónico utiliza este conhecimento para criar recomendações personalizadas de produtos, anúncios direcionados e ofertas promocionais para aumentar as vendas.
Técnicas e algoritmos de extração de dados
As técnicas de extração de dados estão divididas em categorias com base na forma como analisam os dados e extraem padrões significativos. Estas técnicas incluem aprendizagem supervisionada, aprendizagem não supervisionada, aprendizagem semi-supervisionada e [deteção de anomalias] (https://zilliz.com/ai-faq/how-does-machine-learning-improve-anomaly-detection). Cada abordagem é adequada para diferentes tipos de problemas, desde a classificação e previsão até à descoberta de estruturas ocultas nos dados.
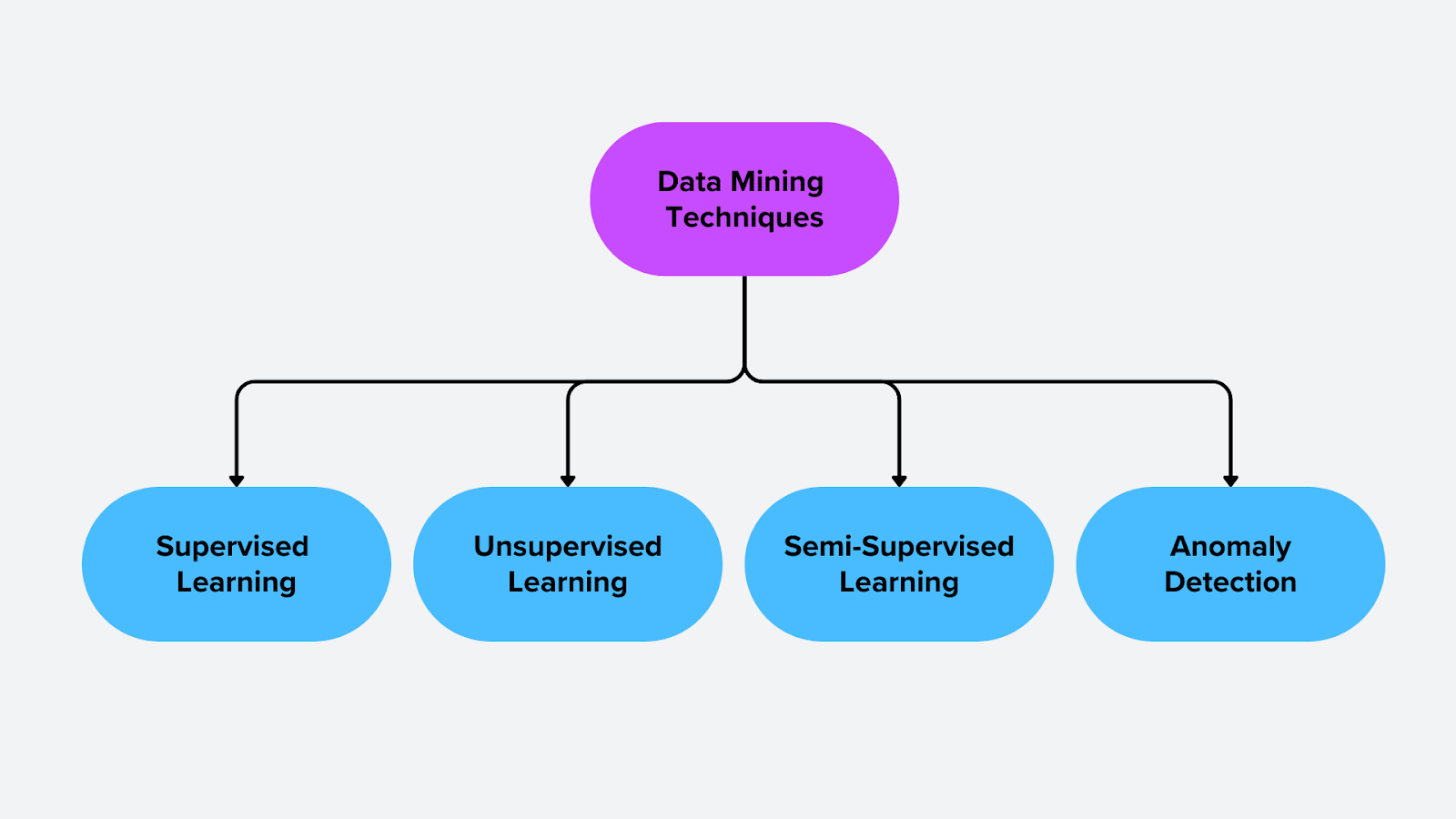 Figura - Técnicas de extração de dados
Figura - Técnicas de extração de dados
Figura: Técnicas de extração de dados
1. Aprendizagem supervisionada
A aprendizagem supervisionada treina um modelo em dados rotulados, em que cada entrada tem uma saída conhecida correspondente. O modelo aprende com esses exemplos a prever resultados para dados novos e não vistos. Esta abordagem é normalmente utilizada em tarefas de classificação, regressão e previsão de séries temporais.
Figura - Técnicas de aprendizagem automática supervisionada](https://assets.zilliz.com/Figure_Supervised_machine_learning_techniques_ac73a06b9a.png)
Figura: Técnicas de aprendizagem automática supervisionada
Árvores de decisão:** Um modelo baseado em regras que divide os dados em subconjuntos mais pequenos com base nos valores das caraterísticas, formando uma estrutura em forma de árvore para a tomada de decisões.
Florestas aleatórias: Um conjunto de várias árvores de decisão que melhora a precisão e reduz o sobreajuste, calculando a média das previsões de vários modelos.
Árvores com reforço de gradiente (GBTs):** Uma abordagem de árvore de decisão sequencial que corrige erros anteriores em cada iteração, levando a um maior desempenho preditivo.
Máquinas de vectores de suporte (SVMs):** Um algoritmo de classificação que encontra o limite ideal (hiperplano) para separar diferentes categorias de dados.
K-Nearest Neighbors (K-NN): Um algoritmo baseado na distância que classifica novos pontos de dados com base na classe maioritária dos seus vizinhos mais próximos.
Redes neuronais: Modelos de várias camadas inspirados no cérebro humano que aprendem relações complexas entre dados de entrada e de saída.
Regressão de vectores de suporte (SVR):** Uma variação do SVM utilizada para prever valores contínuos em vez de rótulos categóricos.
2. Aprendizagem não supervisionada
A aprendizagem não supervisionada analisa dados sem resultados rotulados, identificando estruturas e relações ocultas num conjunto de dados. É normalmente utilizada para agrupamento, deteção de anomalias e redução da dimensionalidade.
Figura - Técnicas de aprendizagem automática não supervisionada] (https://assets.zilliz.com/Figure_Unsupervised_Machine_Learning_Techniques_ecd834bff8.png)
Figura: Técnicas de aprendizagem automática não supervisionada
K-Means Clustering: Um algoritmo de partição que divide os dados em K clusters, atribuindo cada ponto ao centro do cluster mais próximo.
Hierarchical Clustering: Constrói uma hierarquia de clusters através de métodos bottom-up (aglomerativos) ou top-down (divisivos).
Agrupa pontos de dados densamente compactados ao mesmo tempo que trata os valores atípicos como ruído, tornando-o útil para distribuições de dados irregulares.
Análise de componentes principais (PCA): Uma técnica de redução de dimensionalidade que transforma os dados num espaço de dimensão inferior, preservando a variância.
Autoencoders: Um tipo de rede neural que aprende representações comprimidas de dados para deteção de anomalias e extração de caraterísticas.
Association Rule Mining: Identifica relações entre itens num conjunto de dados, normalmente utilizado na análise de cabazes de compras.
Algoritmo Apriori:** Uma técnica de extração de padrões frequentes que encontra relações entre itens através da identificação iterativa de conjuntos de itens frequentes.
Algoritmo FP-Growth:** Uma alternativa mais eficiente ao Apriori que usa uma estrutura de árvore (FP-tree) para extrair padrões frequentes com computação reduzida.
3. Aprendizagem Semi-Supervisionada
A aprendizagem semi-supervisionada é uma abordagem híbrida que combina uma pequena quantidade de dados rotulados com uma grande quantidade de dados não rotulados para melhorar a precisão da aprendizagem. Esta técnica é útil quando a rotulagem de dados é dispendiosa ou demorada.
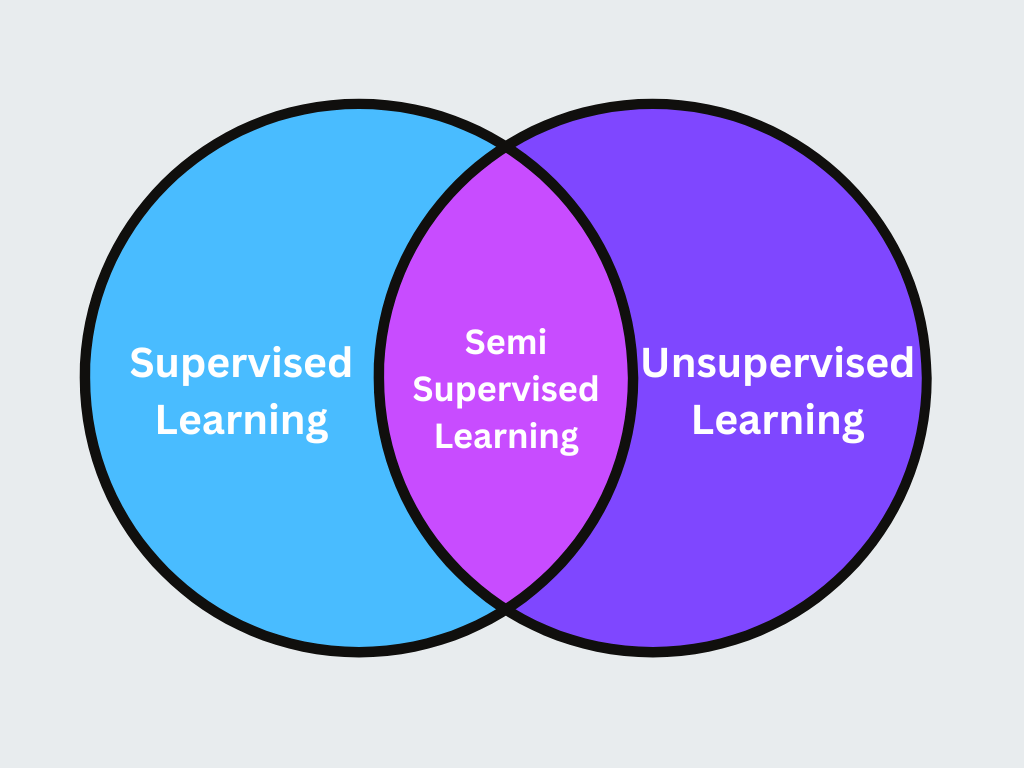 Figura- Aprendizagem semi-supervisionada.png
Figura- Aprendizagem semi-supervisionada.png
Figura: Aprendizagem semi-supervisionada
Auto-treinamento:** Um modelo é inicialmente treinado em dados rotulados e, em seguida, faz previsões em dados não rotulados, adicionando previsões de alta confiança ao conjunto de dados rotulados para treinamento adicional.
Aprendizagem semi-supervisionada baseada em grafos:** Utiliza estruturas de grafos para propagar etiquetas através de uma rede de pontos de dados relacionados, o que é normalmente utilizado em [sistemas de recomendação] (https://zilliz.com/learn/Introduction-to-Recommendation-systems).
Redes Adversariais Generativas (GANs)](https://zilliz.com/glossary/generative-adversarial-networks):** As GANs geram novas amostras rotuladas para melhorar a aprendizagem em cenários com poucas etiquetas, o que as torna úteis no reconhecimento de imagens e de voz.
Regularização de consistência:** Assegura que as previsões de um modelo permanecem consistentes mesmo quando são introduzidas ligeiras variações na entrada, melhorando a robustez na aprendizagem semi-supervisionada.
4. Deteção de anomalias e análise de outlier
A deteção de anomalias identifica pontos de dados que se desviam significativamente dos padrões normais. Estes algoritmos são normalmente utilizados na deteção de fraudes, na cibersegurança e na deteção de falhas industriais.
Figura - Deteção de anomalias](https://assets.zilliz.com/Figure_Anomaly_detection_b7353e3dd5.png)
Figura: Deteção de anomalias
Método Z-Score:** Detecta anomalias medindo o número de desvios padrão de um ponto em relação à média.
Intervalo interquartil (IQR):** Identifica anomalias analisando o intervalo entre o primeiro e o terceiro quartis, assinalando valores extremos.
Floresta de isolamento: Um modelo baseado em árvore que isola anomalias mais rapidamente através da partição aleatória de pontos de dados.
Fator de anomalia local (LOF):** Mede a densidade relativa dos pontos de dados para identificar anomalias num conjunto de dados.
SVM de uma classe: Uma variação do SVM concebida para detetar desvios da classe maioritária, normalmente utilizada para a deteção de fraudes.
Deteção de anomalias baseada em autocodificador:** Utiliza a aprendizagem profunda para reconstruir dados de entrada, assinalando anomalias quando o erro de reconstrução é elevado.
Aplicações de Data Mining em todos os sectores
O Data Mining é utilizado em vários sectores para analisar grandes conjuntos de dados, descobrir padrões e melhorar a tomada de decisões. Abaixo estão alguns casos de uso específicos da indústria:
1. Finanças
Deteção de fraude:** Os bancos utilizam a extração de dados para analisar padrões de transação e detetar actividades suspeitas, tais como comportamentos de despesa invulgares ou várias tentativas de início de sessão falhadas.
Pontuação de crédito e avaliação de risco:** As instituições financeiras avaliam o nível de risco de um mutuário analisando o histórico de crédito, os padrões de renda e os reembolsos de empréstimos anteriores.
Negociação algorítmica:** As empresas de investimento utilizam a análise preditiva para analisar as tendências do mercado e automatizar estratégias de negociação de alta frequência.
2. Cuidados de saúde
Previsão e diagnóstico de doenças:** Os hospitais analisam os registos e sintomas dos pacientes para prever doenças precocemente, melhorando os planos de tratamento e reduzindo os internamentos.
Descoberta e desenvolvimento de medicamentos:** As empresas farmacêuticas utilizam a extração de dados para identificar potenciais candidatos a medicamentos através da análise de dados genéticos e de ensaios clínicos.
Previsão de readmissão de pacientes:** Os prestadores de cuidados de saúde analisam o historial dos pacientes para prever a probabilidade de readmissão e tomar medidas preventivas.
3. Comércio eletrónico e retalho
Recomendações personalizadas:** Os retalhistas em linha analisam o histórico de navegação e de compras dos clientes para oferecer recomendações de produtos personalizadas.
Estratégias dinâmicas de preços:** As plataformas de comércio eletrónico ajustam os preços com base na procura, nos preços da concorrência e no comportamento dos clientes.
Previsão de rotatividade:** Os retalhistas utilizam a prospeção de dados para identificar os clientes em risco de abandono e dirigem-lhes ofertas especiais para melhorar a retenção.
4. Segurança cibernética
Sistemas de deteção de intrusão (IDS):** As organizações utilizam a prospeção de dados para detetar actividades de rede invulgares, tais como tentativas de acesso não autorizado ou infecções por malware.
Inteligência de ameaças e avaliação de riscos:** As equipas de segurança analisam dados históricos de ataques para prever e prevenir futuras ameaças cibernéticas.
Deteção de phishing e fraude:** Os modelos de aprendizagem automática identificam tentativas de phishing através da análise de padrões de correio eletrónico, URLs e comportamentos do remetente.
5. Fabrico e IoT industrial
Manutenção Preditiva:** As fábricas analisam os dados dos sensores das máquinas para prever falhas antes que elas ocorram, reduzindo o tempo de inatividade e os custos de reparo.
Otimização da cadeia de suprimentos: os fabricantes usam a mineração de dados para prever as flutuações da demanda, otimizar o estoque e reduzir o desperdício.
Controlo de qualidade e deteção de defeitos:** A análise de dados ajuda a identificar defeitos de produção antecipadamente, detectando anomalias nos processos de fabrico.
6. Telecomunicações
Otimização da rede:** As empresas de telecomunicações analisam os padrões de utilização para otimizar a atribuição de largura de banda e reduzir o congestionamento.
Segmentação e retenção de clientes:** As operadoras classificam os clientes com base no comportamento de uso e oferecem planos personalizados para melhorar a retenção.
Deteção de spam e Robocall:** Técnicas de data mining ajudam a filtrar chamadas e mensagens de spam com base em padrões de chamadas e relatórios de utilizadores.
7. Energia e serviços públicos
Previsão do consumo de energia:** As empresas de energia analisam padrões de consumo passados para prever a procura futura e otimizar o desempenho da rede.
Deteção de falhas em redes de energia: Sensores monitoram linhas de energia e detectam anomalias para evitar interrupções e melhorar a manutenção.
Análise de contadores inteligentes:** Os fornecedores de serviços públicos utilizam a extração de dados para detetar padrões de utilização de energia invulgares e identificar potenciais roubos de energia.
8. Educação
Previsão do desempenho dos alunos:** As escolas analisam os dados dos alunos para identificar alunos em risco e fornecer apoio personalizado à aprendizagem.
Sistemas de aprendizagem adaptáveis: As plataformas educativas utilizam a extração de dados para personalizar os materiais de aprendizagem com base nos pontos fortes e fracos dos alunos.
Sistemas de recomendação de cursos:** As universidades analisam o desempenho dos alunos para recomendar cursos adequados com base nos interesses e objectivos de carreira.
Vantagens da extração de dados
Descobre padrões ocultos:** Ajuda as empresas e os investigadores a descobrirem informações que não são imediatamente óbvias nos dados em bruto.
Melhora a tomada de decisões:** Fornece informações baseadas em dados que melhoram o planeamento estratégico e a precisão das previsões.
Análise automatizada de tendências:** Esta ferramenta identifica tendências e mudanças no comportamento do consumidor, condições de mercado e padrões financeiros sem intervenção manual.
Aumenta a personalização do cliente:** Permite um marketing altamente direcionado, analisando as preferências do cliente e as interações anteriores.
Optimiza as operações comerciais:** Melhora a eficiência da cadeia de fornecimento, reduz o desperdício e aumenta a produtividade através da previsão da procura e das necessidades de recursos.
Melhora os diagnósticos na área da saúde:** Ajuda na deteção precoce de doenças e planos de tratamento personalizados, analisando os dados dos pacientes.
Acelera a investigação científica:** Acelera a descoberta de medicamentos, a análise genética e a modelação climática através da análise rápida de vastos conjuntos de dados.
Como é que o Milvus ajuda na extração de dados?
A extração de dados requer frequentemente a análise de grandes quantidades de dados estruturados e [dados não estruturados] (https://zilliz.com/learn/introduction-to-unstructured-data) para descobrir padrões significativos. As bases de dados relacionais tradicionais debatem-se com dados altamente dimensionais e não estruturados, tornando-as ineficientes para aplicações modernas como sistemas de recomendação, deteção de anomalias e pesquisa semântica. A Milvus, uma base de dados vetorial de código aberto desenvolvida por Zilliz **** engenheiros, foi especificamente concebida para tratar dados de grande escala e de elevada dimensão, o que a torna uma ferramenta poderosa para tarefas de extração de dados.
1. Manipulação de dados de alta dimensão
As aplicações modernas de extração de dados baseiam-se em dados de elevada dimensão, como imagens embeddings, representações de texto e dados de séries temporais, para extrair informações significativas. As bases de dados relacionais tradicionais são ineficientes no tratamento destes tipos de dados, uma vez que foram concebidas para tabelas estruturadas e não para representações vectoriais multidimensionais.
O Milvus fornece uma base de dados vetorial dedicada para armazenar e gerir incorporações de alta dimensão, o que o torna um componente de infraestrutura essencial para a extração de dados orientada para a IA.
Suporta vários formatos de dados, incluindo vectores densos e esparsos, para garantir flexibilidade para diferentes modelos de aprendizagem automática e aprendizagem profunda.
As estruturas de indexação de vectores optimizadas (como IVF, HNSW e PQ) aumentam a eficiência do armazenamento, reduzindo a redundância e melhorando o desempenho da consulta em grandes conjuntos de dados.
As capacidades de Batch processing e de paralelização permitem a rápida inserção e recuperação de milhões de vectores para aplicações de IA que requerem actualizações contínuas.
**Por exemplo, uma empresa de análise de vídeo armazena embeddings fotograma a fotograma no Milvus, permitindo uma pesquisa e recuperação eficientes com base no conteúdo para marcação e classificação automatizadas de vídeos.
2. Escalabilidade para aplicações de extração de grandes volumes de dados
A extração de grandes volumes de dados requer bases de dados que possam ser escaladas com volumes crescentes de informação. Milvus fornece:
Arquitetura nativa da nuvem para implementações em grande escala em ambientes distribuídos.
Utilização eficiente de recursos para um desempenho de consulta económico, mesmo em conjuntos de dados maciços.
É fácil de integrar com pipelines de extração de dados baseados em IA porque está integrado com estruturas de aprendizagem automática, como TensorFlow, PyTorch e Hugging Face.
**Por exemplo, na genómica, o Milvus armazena e pesquisa sequências de ADN incorporadas para ajudar os investigadores a encontrar rapidamente semelhanças genéticas em milhões de registos.
3. Pesquisa semântica e de similaridade eficiente
As pesquisas semânticas e por semelhança são essenciais para as aplicações modernas de extração de dados que envolvem dados não estruturados, como imagens, texto e multimédia. Ao contrário das pesquisas tradicionais baseadas em palavras-chave, a pesquisa por semelhança baseia-se em incorporações vectoriais para obter os resultados mais relevantes com base no significado e não em correspondências exactas.
O Milvus permite uma pesquisa por semelhança de elevado desempenho, tirando partido das incorporações vectoriais. Permite aos utilizadores encontrar resultados baseados no contexto e não em palavras exactas.
Suporta algoritmos de pesquisa Approximate Nearest Neighbor (ANN), como HNSW, IVF e PQ, para acelerar a recuperação em conjuntos de dados de grande escala.
As capacidades de pesquisa multimodal permitem a pesquisa entre domínios em texto, imagens e vídeos, tornando-o ideal para sistemas de recomendação, recuperação de conteúdos e aplicações de PNL.
**Por exemplo, um sistema de pesquisa de documentos jurídicos pode utilizar o Milvus para recuperar jurisprudência com base no significado semântico e não apenas em correspondências de palavras-chave, melhorando a precisão da investigação jurídica.
Conclusão
A prospeção de dados é um processo transformador que transforma vastos conjuntos de dados em informações acionáveis, impulsionando a inovação nos sectores financeiro e da saúde. As organizações podem descobrir padrões ocultos, otimizar operações e tomar decisões baseadas em dados, tirando partido de técnicas avançadas como a aprendizagem supervisionada e não supervisionada, a deteção de anomalias e a extração de padrões frequentes. O Milvus melhora estas capacidades, fornecendo uma plataforma robusta para armazenar e recuperar dados de elevada dimensão, potenciando pesquisas semânticas e de semelhança eficientes. A sua capacidade de escalar sem problemas com aplicações de grandes volumes de dados torna-o uma ferramenta inestimável para as necessidades modernas de extração de dados.
FAQs sobre extração de dados
1. Quais são as principais técnicas utilizadas na extração de dados?
A extração de dados utiliza várias técnicas, incluindo aprendizagem supervisionada (árvores de decisão, SVMs, redes neurais), aprendizagem não supervisionada (agrupamento, extração de regras de associação), deteção de anomalias e extração de padrões frequentes (Apriori, FP-Growth). Cada técnica ajuda a extrair informações significativas de grandes conjuntos de dados.
**2. Em que é que a extração de dados difere da análise de dados tradicional?
A análise de dados tradicional baseia-se em consultas predefinidas e na interpretação humana, ao passo que a extração de dados utiliza algoritmos automatizados para descobrir padrões, tendências e relações ocultas nos dados. A extração de dados é também mais escalável, o que a torna adequada para lidar com grandes volumes de dados e aplicações de IA.
**3. Quais são os maiores desafios da extração de dados?
Alguns dos principais desafios na extração de dados incluem o tratamento de dados ruidosos e incompletos, preocupações com a privacidade e a segurança dos dados, a gestão da complexidade computacional e o escalonamento para conjuntos de dados maciços. Um pré-processamento eficaz e a utilização de modelos avançados de IA ajudam a mitigar estes problemas.
**4. Como é que a extração de dados é utilizada em aplicações do mundo real?
A extração de dados é amplamente utilizada na deteção de fraudes na banca, em sistemas de recomendação no comércio eletrónico, na manutenção preditiva na indústria transformadora, no diagnóstico de doenças nos cuidados de saúde e na deteção de ameaças à cibersegurança. Ajuda as organizações a otimizar a tomada de decisões e a automatizar processos.
**5. Que papel desempenham as bases de dados vectoriais na prospeção de dados?
As bases de dados vectoriais, como o Milvus, ajudam a armazenar e a recuperar dados de elevada dimensão de forma eficiente, tornando mais rápida a pesquisa de semelhanças, o agrupamento e a deteção de anomalias. Estas bases de dados são benéficas para aplicações orientadas para a IA, como o reconhecimento de imagens, o processamento de linguagem natural e os sistemas de recomendação.
Recursos relacionados
O que é uma base de dados vetorial e como funciona?](https://zilliz.com/learn/what-is-vetor-database)
Classificação em Aprendizado de Máquina: Tudo o que você deve saber](https://zilliz.com/glossary/classification)
Criar aplicações de IA com Retrieval Augmented Generation (RAG)
Redução da dimensionalidade: simplificar dados complexos para uma análise fácil
- O que é Data Mining?
- Como funciona a extração de dados?
- Técnicas e algoritmos de extração de dados
- Aplicações de Data Mining em todos os sectores
- Vantagens da extração de dados
- Como é que o Milvus ajuda na extração de dados?
- Conclusão
- FAQs sobre extração de dados
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis