




LangGraph 및 Llama 3.2를 사용한 로컬 에이전트 RAG
2024년 9월 25일, Llama 3.2로 업데이트됨
이 글에서는 LangGraph와 Llama 3를 사용하여 특정 작업을 수행하기 위해 도구를 지능적으로 호출할 수 있는 에이전트를 구축하는 방법과 효율적인 데이터 저장을 위해 Milvus Lite를 활용하는 방법을 보여드리겠습니다. 이러한 에이전트는 계획, 메모리, 도구 호출 등 몇 가지 중요한 기능을 통합하여 검색 증강 생성(RAG) 시스템의 성능을 향상시킵니다.
**랭그래프와 라마 3 소개****
LangGraph는 대규모 언어 모델(LLM)을 사용하여 강력한 상태 저장 멀티액터 애플리케이션을 구축하도록 설계된 LangChain의 확장입니다. LangChain은 다양한 워크플로우에 LLM을 통합하기 위한 프레임워크를 제공하지만, LangGraph는 작업을 그래프 구조의 노드와 에지로 모델링하여 이를 발전시킵니다. 이를 통해 보다 복잡한 제어 흐름이 가능해지며, LLM이 당면한 작업을 계획하고, 학습하고, 적응할 수 있게 됩니다. LangGraph는 에이전트가 다단계 추론을 사용하여 각 단계에 적합한 도구를 동적으로 선택하는 시스템을 구현할 수 있는 유연성을 제공합니다. 또한 LangGraph는 실행될 때마다 사용자 정의 제어 흐름을 따르는 안정적인 RAG 에이전트를 구축하여 응답의 일관성과 예측 가능성을 보장하는 데 사용할 수 있습니다.
또한 LangGraph는 워크플로우에 주기를 통합할 수 있게 함으로써 보다 복잡하고 에이전트와 유사한 동작을 구현할 수 있습니다. 이러한 주기를 통해 에이전트는 필요한 경우 이전 단계로 되돌아갈 수 있으므로 새로운 정보나 반영에 따라 에이전트가 취하는 조치를 동적으로 조정할 수 있습니다. 그 결과 시간이 지남에 따라 추론을 개선할 수 있는 더욱 지능적인 에이전트가 탄생하여 더욱 강력하고 적응력이 뛰어난 RAG 시스템을 구축할 수 있습니다.
오픈 소스 대규모 언어 모델인 Llama 3는 에이전트 메모리 핵심 추론 엔진 역할을 합니다. 랭그래프와 결합하면 라마 3는 입력을 분석하고, 취할 조치를 결정하고, 필요한 도구를 호출할 수 있습니다. 단순히 텍스트를 생성하는 데 그치지 않고 LangGraph 기반의 Llama 3는 에이전트가 자신의 작업을 계획, 실행, 반성할 수 있도록 지원하여 더욱 지능적이고 유능한 에이전트로 만들어 줍니다.
이 글에서는 랭그래프와 라마 3 및 밀버스 라이트를 사용하여 에이전트 래그 시스템을 만드는 방법을 보여드리겠습니다. 이 설정을 사용하면 외부 서버 없이도 모든 것을 로컬에서 실행할 수 있으므로 개인정보 보호에 민감한 사용자 및 오프라인 환경에 이상적입니다.
**랭그래프로 도구 호출 에이전트 구축하기****
LangGraph의 워크플로는 각 노드가 특정 작업이나 도구를 나타내는 노드 개념을 중심으로 구축됩니다. 이러한 작업에는 LLM 호출, 정보 검색 또는 사용자 지정 도구 호출이 포함될 수 있습니다. 도구 호출 에이전트에는 두 가지 핵심 요소가 작용합니다:
LLM 노드: 이 노드는 사용자의 입력에 따라 사용할 도구를 결정합니다. 쿼리를 분석하여 도구 이름과 관련 인수를 출력합니다.
도구 노드: LLM 노드에서 도구 이름과 인수를 가져와 적절한 도구를 호출하고 결과를 LLM에 반환하는 노드입니다.
웹 검색과 같은 작업을 노드와 에지로 구조화함으로써 LangGraph는 LLM이 어떤 작업을 수행할지, 어떤 도구를 사용할지, 어떤 질문에 답할지, 어떻게 답을 구체화할지에 대한 사용자 질문을 추론할 수 있는 지능적인 다단계 워크플로우를 생성할 수 있도록 지원합니다. 밀버스 라이트는 벡터화된 데이터를 로컬에 효율적으로 저장하고 검색할 수 있는 기능을 제공함으로써 여기서 핵심적인 역할을 합니다.
**밀버스 라이트가 로컬 도구 호출 에이전트를 향상시키는 방법****
Milvus Lite는 Milvus의 경량 로컬 버전으로, 작동에 Docker나 Kubernetes가 필요하지 않습니다. 따라서 노트북, Jupyter 노트북, 심지어 Google Colab에서도 Milvus를 쉽게 실행할 수 있습니다. Milvus Lite의 로컬 배포를 사용하면 외부 데이터베이스에 의존할 필요 없이 다양한 웹 소스나 문서에서 생성된 벡터를 저장할 수 있습니다. LangGraph와 원활하게 통합되어 벡터 검색을 처리하므로 로컬 RAG 시스템에 이상적인 솔루션입니다.
예를 들어 밀버스 라이트는 웹 검색 중에 에이전트가 검색하는 색인화된 문서를 저장하는 데 사용할 수 있습니다. 에이전트가 정보를 쿼리할 때 벡터 데이터베이스를 통해 관련 문서를 빠르고 정확하게 검색할 수 있습니다.
LangGraph와 Llama 3로 로컬 RAG 시스템 만들기
우리는 LangGraph를 사용하여 다양한 접근 방식을 사용하는 맞춤형 로컬 Llama 3.2 기반 RAG 에이전트를 구축합니다:
각 접근 방식을 LangGraph에서 제어 흐름으로 구현합니다:
라우팅(적응형 RAG)** - 에이전트가 사용자 쿼리를 질문 자체에 따라 가장 적합한 검색 방법으로 지능적으로 라우팅할 수 있도록 합니다. LLM 노드는 쿼리를 분석하고 키워드 또는 질문 구조에 따라 특정 검색 노드로 라우팅할 수 있습니다.
예시 1: 사실적인 답변이 필요한 질문은 사전 색인된 지식창고(Milvus에서 제공)를 검색하는 문서 검색 노드로 라우팅될 수 있습니다.
예 2: 개방형, 창의적인 프롬프트는 생성 작업을 위해 LLM으로 전달될 수 있습니다.
폴백(수정 RAG)** - 초기 검색 방법이 관련 결과를 제공하지 못할 경우 에이전트에 백업 계획이 있는지 확인합니다. 초기 검색 노드(예: 지식창고에서 문서 검색)가 만족스러운 답변을 반환하지 못한다고 가정해 보세요(관련성 점수 또는 신뢰도 임계값 기준). 이 경우 에이전트는 웹 검색 노드로 돌아갑니다.
- 웹 검색 노드는 외부 검색 API를 활용할 수 있습니다.
자체 수정(Self-RAG)** - 에이전트가 자체적으로 오류나 잘못된 출력을 식별하고 수정할 수 있습니다. LLM 노드가 답변을 생성한 다음 평가를 위해 다른 노드로 라우팅됩니다. 이 평가 노드는 다양한 기술을 사용할 수 있습니다:
리플렉션_: 에이전트는 원래 쿼리와 비교하여 답변이 모든 측면을 다루고 있는지 확인할 수 있습니다.
신뢰도 점수 분석_: LLM은 답변에 신뢰도 점수를 할당할 수 있습니다. 점수가 특정 임계값 미만이면 답변은 수정을 위해 LLM으로 다시 라우팅됩니다.
상담원을 위한 일반적인 아이디어
반성- 자체 수정 메커니즘은 LangGraph 에이전트가 검색 및 생성에 대해 반성하는 일종의 반성입니다. 이는 평가를 위해 정보를 다시 반복하고 에이전트가 초보적인 형태의 반성을 통해 시간이 지남에 따라 출력 품질을 개선할 수 있도록 합니다.
계획-** 그래프에 배치된 제어 흐름은 일종의 계획으로, 에이전트는 쿼리에 단순히 반응하는 것이 아니라 최상의 답변을 검색하거나 생성하기 위한 단계별 프로세스를 배치합니다.
도구 사용-** LangGraph 에이전트의 제어 흐름에는 다양한 도구에 대한 특정 노드가 통합되어 있습니다. 여기에는 방대한 정보 풀을 활용하는 능력을 보여주는 지식 기반(예: Milvus)을 위한 검색 노드와 외부 정보를 위한 웹 검색 노드가 포함될 수 있습니다.
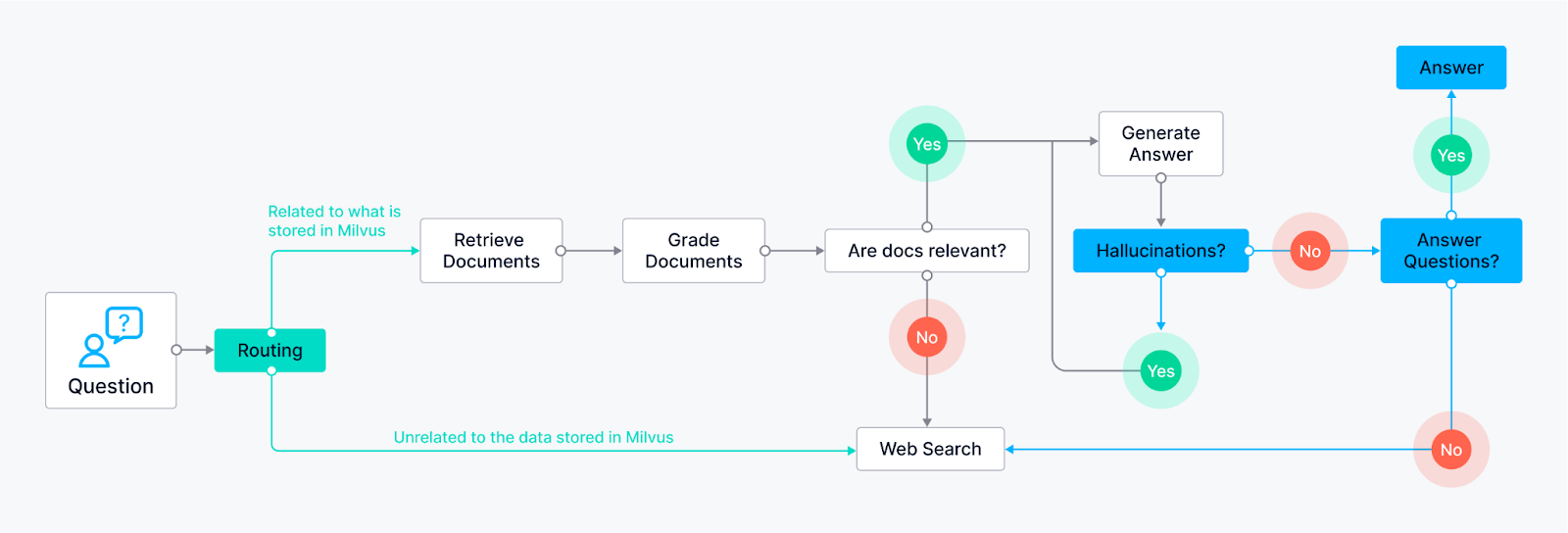
에이전트 예시
LLM 에이전트의 기능을 보여드리기 위해 두 가지 핵심 구성 요소인 '환각 채점자'와 '답변 채점자'를 살펴보겠습니다. 전체 코드는 이 게시물의 하단에서 확인할 수 있지만, 이 스니펫은 이러한 에이전트가 LangChain 프레임워크 내에서 어떻게 작동하는지 더 잘 이해할 수 있도록 도와줄 것입니다.
환각 그레이더
환각 그레이더는 모델이 그럴듯하게 들리지만 사실적 근거가 부족한 답변을 생성하는 환각이라는 LLM의 일반적인 문제를 해결하려고 합니다. 이 에이전트는 사실 확인자 역할을 수행하여 LLM의 답변이 Milvus에서 검색된 제공된 문서 세트와 일치하는지 평가합니다.
### 환각 채점자
# LLM
llm = ChatOllama(모델=local_llm, 형식="json", 온도=0)
# 프롬프트
프롬프트 = 프롬프트템플릿(
template="""귀하는 채점자입니다.
답변이 일련의 사실에 근거하거나 뒷받침되는지 평가하는 채점자입니다. '예' 또는 '아니요' 이진 점수를 부여하여 다음과 같이 표시합니다.
답변이 일련의 사실에 근거하거나 사실에 의해 뒷받침되는지 여부를 나타냅니다. 이진 점수를 JSON으로 제공하세요.
단일 키 '점수'와 서문이나 설명이 없는 JSON으로 제공합니다.
다음은 사실입니다:
{documents}
여기에 답이 있습니다:
{세대}
""",
input_변수=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
답변 채점자
환각 채점자의 뒤를 이어 다른 채점자가 개입합니다. 이 요원은 또 다른 중요한 측면, 즉 LLM의 답변이 사용자의 원래 질문에 직접적으로 부합하는지 여부를 확인합니다. 이 에이전트는 동일한 LLM을 사용하지만 질문과 답변의 관련성을 평가하기 위해 특별히 고안된 다른 프롬프트를 사용합니다.
def grade_generation_v_documents_and_question(state):
"""
문서에 근거한 세대인지 여부를 결정하고 질문에 답합니다.
Args:
상태(딕셔너리): 현재 그래프 상태
를 반환합니다:
str: 다음 호출할 노드 결정
"""
print("---환각 확인---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
grade = score['score']
# 환각 확인
grade == "yes":
print("---결정: 문서에 근거한 세대---")
# 질문-답변 확인
print("---성적 생성 대 질문---")
score = answer_grader.invoke({"question": question,"generation": generation})
grade = score['score']
if grade == "yes":
print("---결정: 세대가 질문을 해결함---")
반환 "유용"
else:
print("---결정: 세대가 질문을 해결하지 못함---")
반환 "유용하지 않음"
else:
pprint("---결정: 생성은 문서에 근거하지 않습니다, 다시 시도하세요---")
반환 "지원되지 않음"
위의 코드에서 분류기로 사용하는 LLM으로 예측을 확인하고 있음을 알 수 있습니다.
LangGraph 그래프 컴파일하기
이렇게 하면 정의한 모든 에이전트가 컴파일되고 RAG 시스템에 다양한 도구를 사용할 수 있게 됩니다.
# 컴파일
app = workflow.compile()
# 테스트
pprint에서 pprint 가져오기
inputs = {"question": "프롬프트 엔지니어링이란 무엇인가요?"}
앱 스트림(입력)의 출력에 대해
for key, value in output.items():
pprint(f"실행 완료: {키}:")
pprint(value["generation"])
'실행 완료: 생성:'
('프롬프트 엔지니어링은 대규모 언어 '
'모델(LLM)과 통신하여 '
'모델 가중치를 업데이트합니다. '정렬 및 모델 조향성에 중점을 두며, '
'모델 간의 다양한 효과로 인해 실험과 휴리스틱이 필요함.
'모델. 목표는 특정 애플리케이션에 대한 '
'특정 애플리케이션에 대한 프롬프트')
결론
이 블로그 포스팅에서는 LangChain/ LangGraph, Llama 3.2, Milvus와 함께 에이전트를 사용해 RAG 시스템을 구축하는 방법을 살펴보았습니다. 이러한 에이전트를 사용하면 LLM이 계획, 메모리 및 다양한 도구 사용 기능을 보유할 수 있어 보다 강력하고 유익한 응답을 제공할 수 있습니다.
개선을 위한 다음 단계
현재 구현된 에이전트 RAG 시스템은 로컬 단일 에이전트 워크플로우에 효과적이지만, 더 많은 개선과 혁신을 위한 몇 가지 흥미로운 방향이 있습니다.
**멀티 에이전트 조정: 현재 LangGraph는 웹 검색과 같이 미리 정의된 제어 흐름 내에서 작동하는 단일 에이전트 시스템을 설계하는 데 사용됩니다. 그러나 자연스럽게 이 시스템을 확장하여 병렬로 작업하거나 조율하는 여러 에이전트를 지원할 수 있도록 확장할 수 있습니다. 작업에 전문 지식이나 여러 검색 소스가 필요한 시나리오에서 에이전트는 작업의 여러 부분을 공동으로 처리할 수 있습니다. 예를 들어 한 상담원은 사실 정보 검색에 집중하고, 다른 상담원은 창의적인 작업이나 사용자 상호작용을 처리하며, 세 번째 상담원은 결과물의 전반적인 품질을 평가할 수 있습니다. 이러한 다중 에이전트 시스템은 보다 복잡한 작업을 가능하게 하여 다양한 쿼리를 처리하는 데 있어 효율성과 정확성을 높일 수 있습니다.
실시간 데이터** 업데이트: ** 또 다른 잠재적 개선 사항은 에이전트가 데이터 소스를 실시간으로 업데이트할 수 있도록 하는 것입니다. 현재 밀버스 라이트는 정적 지식 베이스 역할을 하지만, 동적 영역에서는 정보가 빠르게 구식이 될 수 있습니다. 에이전트는 웹이나 기타 API의 새로운 데이터로 로컬 벡터 스토어를 지속적으로 모니터링하고 업데이트하여 시스템의 출력이 관련성 있고 최신 상태로 유지되도록 설계할 수 있습니다. 예를 들어 상담원에게 최신 주가나 뉴스 속보에 대한 질문을 받으면 자동으로 최신 데이터를 가져와서 빠르게 변화하는 환경에서 훨씬 더 적응력 있고 유용한 시스템을 만들 수 있습니다.
**향상된 반영 및 자기 개선: 현재의 반영 메커니즘은 유용하지만, 자기 수정 측면에서는 개선의 여지가 있습니다. 향후 버전의 에이전트에는 강화 학습이나 지속적인 학습 메커니즘과 같은 고급 기술을 통합하여 에이전트가 시간이 지남에 따라 과거의 경험과 실수로부터 학습할 수 있도록 할 수 있습니다. 에이전트 메모리 작업을 통해 반복적으로 응답 품질을 개선할 수 있게 되면 고품질 답변을 검색하고 생성할 뿐만 아니라 피드백을 기반으로 프로세스를 개선하는 시스템을 구현할 수 있습니다.
이러한 다음 단계를 통합함으로써 에이전트 RAG 시스템의 기능을 크게 향상시켜 다양한 산업 분야의 복잡한 작업을 보다 유연하고 적응력 있게, 그리고 효과적으로 해결할 수 있습니다.
밀버스 부트캠프 리포지토리](https://github.com/milvus-io/bootcamp/tree/master/bootcamp/RAG/advanced_rag)에서 제공되는 코드를 확인해 보세요.
랭그래프 에이전틱 래그를 구축하는 방법을 소개하는 이 블로그 게시물이 재미있었다면 에 별표를 달아주시고, 커뮤니티에 참여하여 여러분의 경험을 공유해 주세요.
이 글은 메타의 깃허브 리포지토리에서 영감을 얻었으며, 여기에는 라마 3 사용법이 포함되어 있습니다.

계속 읽기

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.