




콜팔리: 비전 언어 모델과 ColBERT 임베딩 전략으로 문서 검색 기능 향상
검색 증강 생성(RAG)은 대규모 언어 모델(LLM)의 기능을 외부 지식 소스와 결합하여 응답 정확도와 관련성을 향상시키는 기술입니다. RAG의 일반적인 적용 분야는 PDF와 같은 소스에서 콘텐츠를 추출하는 것인데, 이러한 파일에는 종종 중요한 데이터가 포함되어 있지만 검색 및 색인하기가 어렵기 때문입니다. 문제는 추출에 사용되는 도구에 따라 중요한 정보가 간과될 수 있다는 사실에 있습니다. 예를 들어, 이미지에 포함된 텍스트는 추출 중에 감지되지 않아 나중에 검색이 불가능할 수 있습니다.
문서 검색 모델인 ColPali(https://arxiv.org/abs/2407.01449)는 비전 언어 모델(VLM)을 기반으로 하는 새로운 아키텍처로 이 문제를 해결합니다. 이 모델은 시각적 특징을 통해 문서를 색인하고 텍스트와 시각적 요소를 캡처합니다. 콜팔리는 텍스트와 이미지의 ColBERT 스타일의 다중 벡터 표현을 생성함으로써 문서 이미지를 통합 임베딩 공간으로 직접 인코딩하므로 기존의 텍스트 추출과 분할이 필요 없습니다.
그림: PDF 검색을 위한 표준 검색 파이프라인과 ColPali 파이프라인 비교](https://assets.zilliz.com/Co_Pali_image_2_50aa11b6d2.png)
위 이미지는 ColPali 논문에서 가져온 것으로, 저자들은 일반적인 PDF 검색 파이프라인에는 일반적으로 OCR을 사용한 텍스트 추출, 레이아웃 감지, 청킹, 임베딩 생성 등 여러 단계가 포함된다고 주장합니다. ColPali는 페이지의 스크린샷을 입력으로 사용하는 단일 비전 언어 모델(VLM)을 사용하여 이 프로세스를 간소화합니다.
ColPali는 기존 RAG 시스템 이상의 도구를 통합하므로 먼저 이러한 개념 중 일부를 이해하는 것이 중요합니다. ColPali의 세부 사항을 논의하기 전에 비전 언어 모델과 후기 상호작용 모델에 대해 알아봅시다.
비전 언어 모델(VLM)이란 무엇인가요?
비전 언어 모델(VLM)은 이미지와 텍스트를 동시에 학습하는 멀티모달 모델입니다. 이미지와 텍스트 입력을 받아 텍스트 출력을 생성하며, 생성 모델이라는 더 넓은 범주에 속합니다.
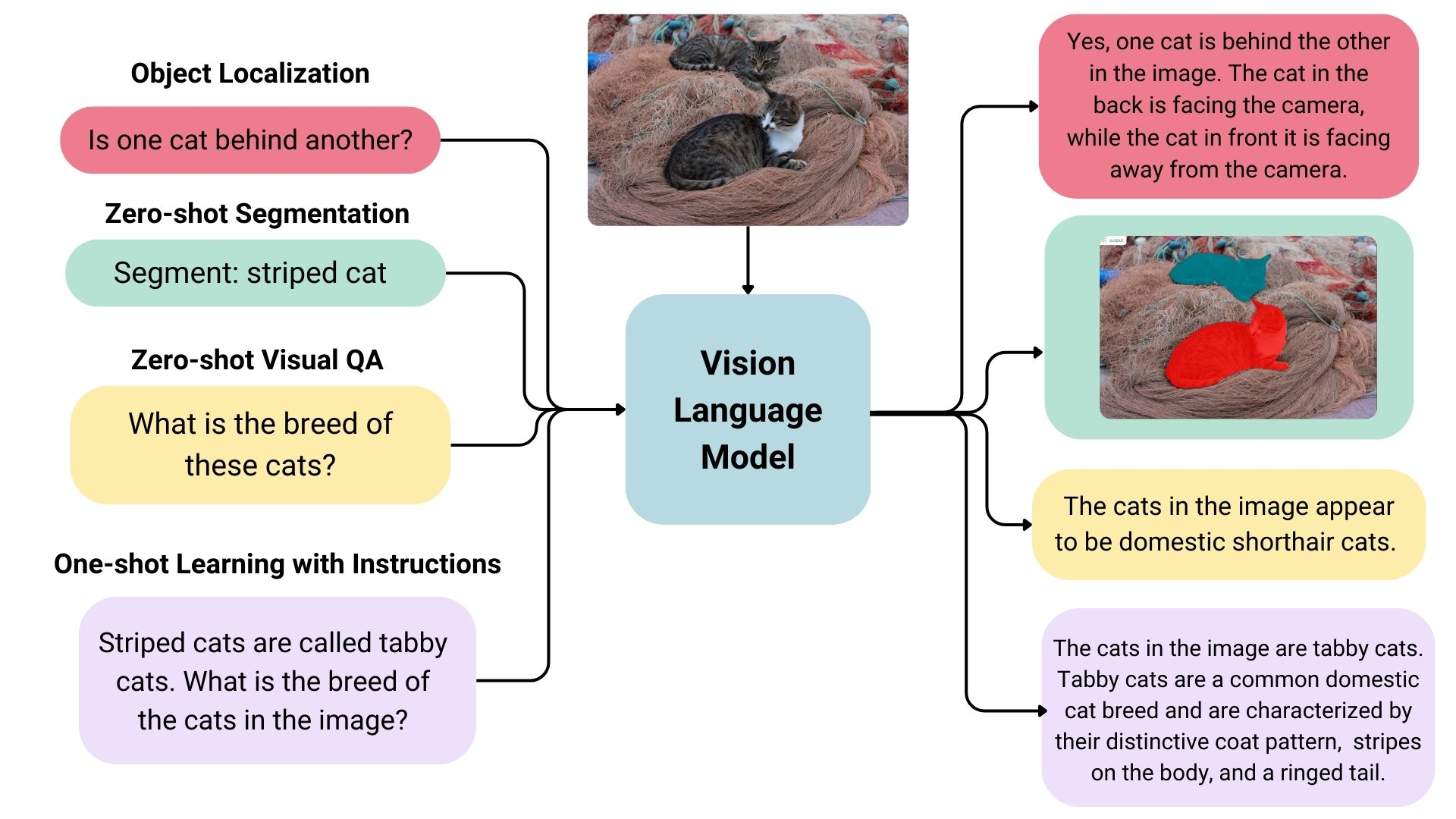 VLM의 예
VLM의 예
콜팔리는 멀티모달 미세 조정 중에 획득한 텍스트 및 이미지 토큰의 임베딩을 정렬하기 위해 VLM을 활용합니다. 특히, PaliGemma-3B 모델의 확장 버전을 사용하여 ColBERT 스타일의 다중 벡터 표현을 생성합니다. 저자들이 이 모델을 선택한 이유는 이미지에서 텍스트를 읽기 위한 OCR을 비롯해 다양한 이미지 해상도와 작업에 맞게 미세 조정된 다양한 체크포인트가 있기 때문입니다.
ColPali는 개방형 가중치로 출시된 Google의 PaliGemma-3B 모델을 기반으로 구축되었습니다. 이 모델은 웹 크롤링된 PDF 페이지의 학술 데이터 63%와 합성 데이터 37%로 구성된 다양한 데이터 세트를 사용하여 학습되었으며, VLM에서 생성된 유사 질문으로 강화되었습니다.
후기 상호작용 모델이란 무엇인가요?
후기 상호작용 모델은 검색 작업을 위해 설계되었습니다. 이 모델은 단일 벡터 표현을 사용하는 대신 문서 간의 토큰 수준 유사성에 중점을 둡니다. 이 모델은 텍스트를 일련의 토큰 임베딩으로 표현함으로써 크로스 인코더의 디테일과 정확성을 제공하는 동시에 오프라인 문서 저장의 효율성이라는 이점을 누릴 수 있습니다.
그림 2: 신경망 IR의 쿼리-문서 매칭 패러다임을 보여주는 모식도](https://assets.zilliz.com/Figure_2_Schematic_diagrams_illustrating_query_document_matching_paradigms_in_neural_I_Rpng_3c508a2c93.png)
그림 2: 신경 IR의 쿼리-문서 매칭 패러다임을 설명하는 모식도. | 출처
이제 후기 상호작용 모델과 비전 언어 모델에 대한 이해를 바탕으로, 콜팔리가 어떻게 이러한 요소들을 결합하여 문서 검색을 향상시키는지 살펴볼 수 있습니다.
콜팔리란 무엇이며 어떻게 작동하나요?
ColPali는 문서, 특히 PDF의 시각적 특징에서 직접 정보를 색인하고 검색하도록 설계된 고급 문서 검색 모델입니다. OCR(광학 문자 인식)과 텍스트 분할에 의존하는 기존 방식과 달리, ColPali는 각 페이지의 스크린샷을 캡처하고 VLM을 사용해 전체 문서 페이지를 통합된 벡터 공간에 임베드합니다. 이러한 접근 방식을 통해 ColPali는 복잡한 추출 프로세스를 우회하여 검색 정확도와 효율성을 개선할 수 있습니다.
다음은 워크플로우의 주요 단계입니다:
문서 처리
- PDF에서 이미지 만들기: ** 텍스트를 추출하여 청크를 만든 다음 임베드하는 대신, ColPali는 PDF 페이지의 스크린샷을 벡터 표현으로 직접 임베드합니다. 이 단계는 콘텐츠를 추출하는 대신 각 페이지의 사진을 찍는 것과 같습니다.
- 이미지를 그리드로 분할**: 그런 다음 각 페이지를 패치라고 하는 균일한 조각의 격자로 나눕니다. 기본적으로 32x32 그리드로 나뉘며, 이미지당 1024개의 패치가 생성됩니다. 각 패치는 128차원 벡터로 표현됩니다. 패치를 설명하는 1024개의 "단어"가 있는 하나의 이미지라고 생각하면 됩니다.
임베딩 생성
- 이미지 패치 처리**: 콜팔리는 비전 트랜스포머(ViT)를 통해 이러한 시각적 패치를 임베딩으로 변환하고, 각 패치를 처리하여 상세한 벡터 표현을 생성합니다.
- 시각 및 텍스트 임베딩 정렬**: 시각적 정보를 검색 쿼리와 일치시키기 위해 ColPali는 쿼리 텍스트를 이미지 패치와 동일한 벡터 공간의 임베딩으로 변환합니다. 이러한 정렬을 통해 모델은 시각적 콘텐츠와 텍스트 콘텐츠를 직접 비교하고 일치시킬 수 있습니다.
- 쿼리 처리**: 모델은 쿼리를 토큰화하여 각 토큰에 128차원 벡터를 할당합니다. "이 이미지 <이미지> 설명" 같은 프롬프트를 사용하여 모델이 시각적 요소에 집중하도록 함으로써 텍스트와 시각적 데이터를 원활하게 통합할 수 있도록 합니다.
검색 메커니즘
ColPali는 후기 상호 작용 유사성 메커니즘을 사용하여 쿼리 시점에 쿼리와 문서 임베딩을 비교합니다. 이 접근 방식은 모든 이미지 그리드 셀 벡터와 쿼리 텍스트 토큰 벡터 간의 세부적인 상호 작용을 허용하여 포괄적인 비교를 보장합니다.
유사도는 "최대 유사도의 합" 접근 방식을 사용하여 계산됩니다:
- 각 쿼리 토큰과 이미지의 모든 패치 토큰 간의 유사도 점수를 계산합니다.
- 이 점수를 합산하여 각 문서에 대한 관련성 점수를 생성합니다.
- 이 점수를 관련성 측정값으로 사용하여 점수에 따라 문서를 내림차순으로 정렬합니다.
이 방법을 사용하면 ColPali가 쿼리 텍스트와 가장 잘 일치하는 이미지 패치에 초점을 맞춰 사용자 쿼리를 관련 문서와 효과적으로 일치시킬 수 있습니다. 이렇게 하면 문서에서 가장 관련성이 높은 부분을 강조 표시하여 텍스트와 시각적 콘텐츠를 결합하여 정확하게 검색할 수 있습니다.
모델 훈련 프로세스
ColPali는 Google에서 개발한 비전 언어 모델인 PaliGemma-3B 모델을 기반으로 구축되었습니다. 구현 과정에서 ColPali는 훈련 중에 모델의 가중치를 고정하여 VLM의 사전 학습된 지식을 유지하면서 문서 검색 작업의 최적화**에 집중할 수 있도록 합니다.
문서 검색을 위해 이 범용 VLM을 적용하는 데 있어 핵심은 작지만 중요한 구성 요소에 있습니다: 검색 전용 어댑터입니다. 이 어댑터는 팔리젬마-3B 모델 위에 계층화되어 있으며 검색 작업에 맞는 표현을 학습하도록 훈련됩니다.
이 어댑터의 훈련 과정은 삼중 학습 방식을 활용합니다:
- 텍스트 쿼리
- 쿼리와 관련된 페이지의 이미지
- 쿼리와 관련이 없는 페이지의 이미지 3.
이 방법을 사용하면 모델이 관련성 있는 콘텐츠와 관련성 없는 콘텐츠를 세밀하게 구분하여 검색 정확도를 높일 수 있습니다.
콜팔리의 장점
- 복잡한 전처리 제거: ColPali는 텍스트 추출, OCR, 레이아웃 감지, 청킹으로 이루어진 기존의 파이프라인을 페이지의 스크린샷을 입력으로 사용하는 단일 VLM으로 대체합니다.
- 시각적 정보와 텍스트 정보를 모두 캡처**합니다: 콜팔리는 페이지 이미지로 직접 작업함으로써 문서 이해에 텍스트 콘텐츠와 시각적 레이아웃을 모두 통합할 수 있습니다.
- 시각적으로 풍부한 문서에서 효율적인 검색: 후기 상호작용 메커니즘을 통해 쿼리와 문서 콘텐츠를 세밀하게 일치시킬 수 있어 복잡하고 시각적으로 풍부한 문서에서 관련 정보를 효율적으로 검색할 수 있습니다.
- 문맥 보존**: 전체 페이지 이미지에서 작동함으로써 ColPali는 기존의 텍스트 청킹 접근 방식에서는 손실될 수 있는 문서의 전체 컨텍스트를 유지합니다.
콜팔리의 도전 과제
다른 대규모 검색 시스템과 마찬가지로 ColPali는 계산 복잡성과 스토리지 요구 사항 측면에서 상당한 도전에 직면해 있습니다.
계산 복잡성: ColPali의 컴퓨팅 요구사항은 쿼리 토큰과 패치 벡터의 수에 따라 4제곱으로 증가합니다. 즉, 쿼리의 복잡성이나 문서 이미지의 해상도가 증가함에 따라 컴퓨팅 수요가 급격히 증가합니다.
저장소 요구 사항: 콜버트와 유사한 접근 방식의 저장 비용은 각 토큰마다 벡터가 필요하기 때문에 고밀도 벡터 임베딩의 10배에서 100배에 달합니다. 시스템의 스토리지 요구량은 세 가지 요소에 따라 선형적으로 확장됩니다:
문서 수
문서당 패치 수
벡터 표현의 차원.
이러한 확장으로 인해 대규모 문서 컬렉션의 경우 상당한 스토리지 요구 사항이 발생할 수 있습니다.
최적화 전략 - 정밀도 감소
이러한 확장 문제를 해결하려면 정밀도 감소 전략을 사용하는 것이 좋습니다.
- 정밀도 감소: 정밀도가 높은 표현(예: 32비트 플로트)에서 정밀도가 낮은 형식(예: 8비트 정수)으로 전환하면 검색 품질에 미치는 영향은 최소화하면서 저장 공간 요구 사항을 크게 줄일 수 있습니다.
요약
ColPali는 RAG 시스템에서 텍스트 컨텍스트가 포함된 시각적으로 풍부한 콘텐츠를 검색하는 방식을 혁신할 수 있는 상당한 잠재력을 가지고 있습니다. 비전 언어 모델을 활용하여 텍스트뿐만 아니라 시각적 요소에 기반한 문서 검색을 가능하게 합니다.
그러나 인상적인 결과에도 불구하고 ColPali는 높은 스토리지 수요와 계산 복잡성으로 인해 광범위한 채택을 방해할 수 있는 문제에 직면해 있습니다. 향후 최적화를 통해 이러한 한계를 해결하여 더욱 실용적으로 만들 수 있습니다. RAG 방법이 계속 발전함에 따라 시각적 이해와 텍스트 이해를 통합하는 ColPali와 같은 검색 방법은 다양한 문서 유형에 걸쳐 정보 검색에서 점점 더 중요한 역할을 하게 될 것입니다.
여러분의 의견을 듣고 싶습니다!
이 블로그 게시물이 마음에 드신다면 GitHub에서 별표를 달아주시면 정말 감사하겠습니다! 또한 Discord의 Milvus 커뮤니티에 가입하여 경험을 공유할 수도 있습니다. 더 자세히 알고 싶으시다면 GitHub의 부트캠프 리포지토리 또는 노트북을 확인해 보세요. 또한 앞으로 ColPali를 사용해 보실 계획이 있으신 분들의 의견도 듣고 싶습니다!
더 읽어보기
- 콜팔리 페이퍼: [2407.01449] ColPali: 비전 언어 모델을 사용한 효율적인 문서 검색
- ColPali 깃허브: https://github.com/illuin-tech/colpali
- 콜버트: 토큰 수준 임베딩 및 랭킹 모델](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
- 콜팔리: 비전 언어 모델을 사용한 문서 검색](https://antaripasaha.notion.site/ColPali-Document-Retrieval-with-Vision-Language-Models-10f5314a5639803d94d0d7ac191bb5b1)
- RAG란 무엇인가요?
- 벡터 데이터베이스란 무엇이며 어떻게 작동하나요?

계속 읽기

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.